







文章目录
一、linear_model.LassoCV()
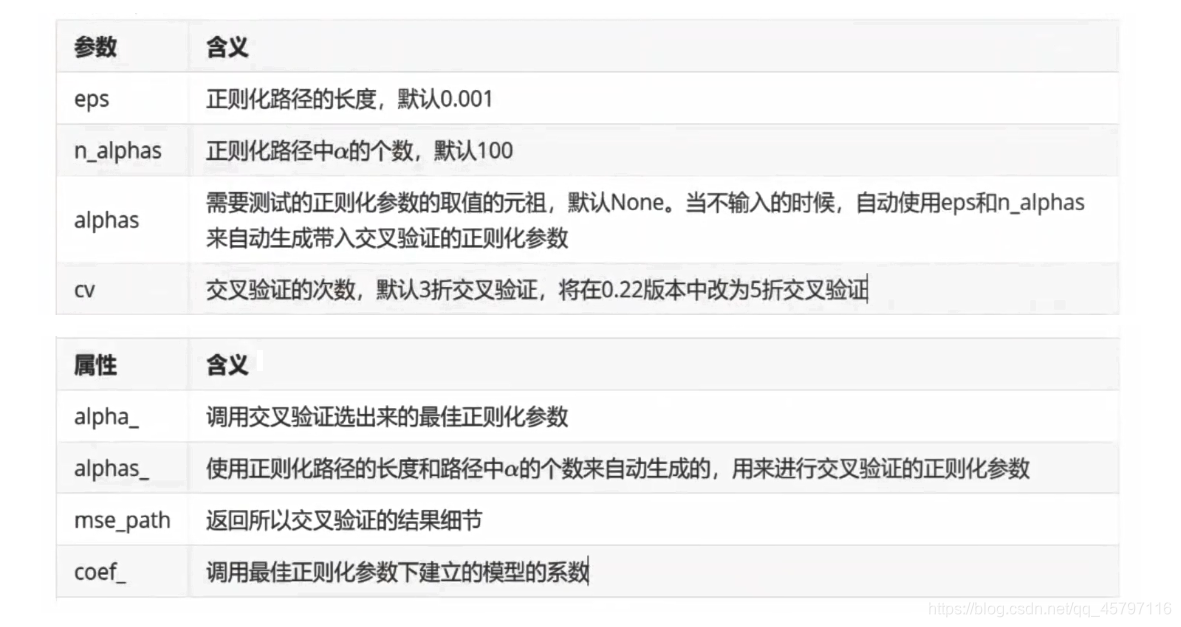
使用交叉验证的 Lasso类的参数看起来与岭回归略有不同,这是由于 Lasso对于alpha的取值更加敏感的性质决定的。之前提到过,由于 Lasso对正则化系数的变动过于敏感,因此我们往往让α在很小的空间中变动。这个小空间小到超乎人们的想象(不是0.01到0.02之间这样的空间,这个空间对 lasso而言还是太大了),因此我们设定了一个重要概念"正则化路径”,用来设定正则化系数的变动.
♦ 正则化路径 regularization path
假设我们的特征矩阵中有n个特征,则我们就有特征向量x1,x2…xn。对于每一个α的取值,我们都可以得出一组对应这个特征向量的参数向量w,其中包含了n+1个参数,分别是w0,w1,w2,...wn.这些参数可以被看作是一个n维空间中的一个点。对于不同的α取值,我们就将得到许多个在n维空间中的点,所有的这些点形成的序列,就被我们称之为是正则化路径。
我们把形成这个正则化路径的α的最小值除以α的最大值得到的量(α.min/α.max)称为正则化路径的长度(length of the path)。在 sklearn中,我们可以通过规定正则化路径的长度(即限制α的最小值和最大值之间的比例),以及路径中α的个数,来让 sklearn为我们自动生成α的取值,这就避免了我们需要自己生成非常非常小的α的取值列表来让交叉验证类使用,类Lassocv自己就可以计算了。
和岭回归的交叉验证类相似,除了进行交叉验证之外, LassoCV也会单独建立模型。它会先找出最佳的正则化参数,然后在这个参数下按照模型评估指标进行建模。需要注意的是, LassoCV的模型评估指标(交叉验证结果)选用的是均方误差,而岭回归的模型评估指标是可以自己设定的,并且默认是R2。
♦ linear_model.LassoCV类
class sklearn.linear_model.LassoCV(*, eps=0.001, n_alphas=100, alphas=None, fit_intercept=True,
normalize=False, precompute='auto', max_iter=1000, tol=0.0001,
copy_X=True, cv=None, verbose=False, n_jobs=None, positive=False,
random_state=None, selection='cyclic')[source]
① 自定义alpha范围测试
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.datasets import fetch_california_housing as fch
from sklearn.linear_model import LassoCV
from sklearn.model_selection import train_test_split
# 获取数据集
house_value = fch()
x = pd.DataFrame(house_value.data)
y = house_value.target
x.columns = ["住户收入中位数","房屋使用年代中位数","平均房间数目","平均卧室数目","街区人口","平均入住率","街区的纬度","街区的经度"]
# 划分测试集和训练集
xtrain,xtest,ytrain,ytest = train_test_split(x,y,test_size=0.3,random_state=420)
# 重置索引
for i in [xtrain,xtest]:
i.index = range(i.shape[0])
# 自己建立Lasso进行alpha选择的范围
# 形成10为底的指数函数
# 10**(-10) -10**(-2)
alpha_range = np.logspace(-10,-2,200,base=10)
print(alpha_range) # 200个自定义的alpha值
# LassoCV
lasso_ = LassoCV(alphas=alpha_range,cv=5).fit(xtrain,ytrain)
# 查看最佳正则化系数
best_alpha = lasso_.alpha_ # 0.0020729217795953697
# 调用所有的交叉验证结果:均方误差 --- 每个alpha对应的五折交叉验证结果(200,5)
each_five_alpha = lasso_.mse_path_
#[[0.52454913 0.49856261 0.55984312 0.50526576 0.55262557]
# [0.52361933 0.49748809 0.55887637 0.50429373 0.55283734]
# [0.52281927 0.49655113 0.55803797 0.5034594 0.55320522]
# [0.52213811 0.49574741 0.55731858 0.50274517 0.55367515]
# [0.52155715 0.49505688 0.55669995 0.50213252 0.55421553]
mean = lasso_.mse_path_.mean(axis=1)#有注意到在岭回归中我们的轴向是axis=0吗?
print(mean.shape)
# (200,)
#在岭回归当中,我们是留一验证,因此我们的交叉验证结果返回的是,每一个样本在每个 alpha下的交叉验证结果
#因此我们要求每个alpha下的交叉验证均值,就是axis=,跨行求均值
#而在这里,我们返回的是,每一个 alpha取值下,每一折交叉验证的结果
#因此我们要求每个 alpha下的交叉验证均值,就是axis=1,跨列求均值
# 最佳正则化系数下获得的模型的系数结果
w = lasso_.coef_
# [ 4.29867301e-01 1.03623683e-02 -9.32648616e-02 5.51755252e-01, 1.14732262e-06 -3.31941716e-03 -4.10451223e-01 -4.22410330e-01]
# 获取R2指数
r2_score = lasso_.score(xtest,ytest) # 0.6038982670571436
② LassoCV默认参数配置测试
# 使用LassoCV自带正则化路径长度和路径中的alpha个数来自动建立alpha选择的范围
ls_ = LassoCV(eps=0.0001,n_alphas=300,cv=5).fit(xtrain,ytrain)
# 查看最佳alpha
b_alpha = ls_.alpha_ # 0.0029405973698326477
# 查看是否有自动生成的alpha取值
new_alpha = ls_.alphas_
print(ls_.alphas_.shape) # (300,)
# 查看R2指数
r2 = ls_.score(xtest,ytest) # 0.6036135609816554
# 查看特征系数
W = ls_.coef_
# [ 4.26722427e-01 1.04253992e-02 -8.71648975e-02 5.20444027e-01, 1.40841579e-06 -3.30718197e-03 -4.09361522e-01 -4.20836139e-01]
可以看出来通过自定义alpha或LassoCV自带的正则化路径进行测试,最终的结果都相差不大,所以按照本数据而言,最佳正则化系数约为0.002-0.003之间,此时的模型训练最佳。



















 656
656

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











