







MambaVision:一种混合Mamba-Transformer视觉主干网络
摘要
我们提出了一种新型的混合Mamba-Transformer主干网络,命名为MambaVision,它专门为视觉应用而设计。我们的核心贡献包括重新设计Mamba公式,以提高其有效建模视觉特征的能力。此外,我们对集成视觉变换器(ViT)与Mamba的可行性进行了全面的消融研究。我们的结果表明,在Mamba架构的最后一层加入多个自注意力模块大大提高了捕获长程空间依赖性的建模能力。基于我们的发现,我们引入了一系列具有分层架构的MambaVision模型,以满足各种设计标准。在ImageNet-1K数据集上进行图像分类,MambaVision模型变种实现了新的最佳性能(SOTA),在Top-1准确性和图像吞吐量方面表现出色。在下游任务如对象检测、实例分割和语义分割方面,MambaVision在MS COCO和ADE20K数据集上超过了同等规模的基干网络,并显示出更优越的性能。代码:https://github.com/NVlabs/MambaVision。
1 引言
近年来,Transformer [1] 已经成为不同领域(包括计算机视觉、自然语言处理、语音处理和机器人技术)的实际标准架构。此外,Transformer 架构的多功能性,主要归功于其注意力机制,以及其灵活性,使其非常适合多模态学习任务,在这些任务中,整合和处理来自不同模态的信息是至关重要的。尽管具有这些优势,但注意力机制相对于序列长度的二次复杂度使得训练和部署 Transformer 计算成本高昂。最近,Mamba [2] 提出了一种新的状态空间模型(SSM),实现了线性时间复杂度,并在不同的语言建模任务中超越或匹配 Transformer [2] 的性能。Mamba 的核心贡献是一种新颖的选择机制,它能够针对长序列进行高效的输入依赖处理,并考虑硬件感知因素。
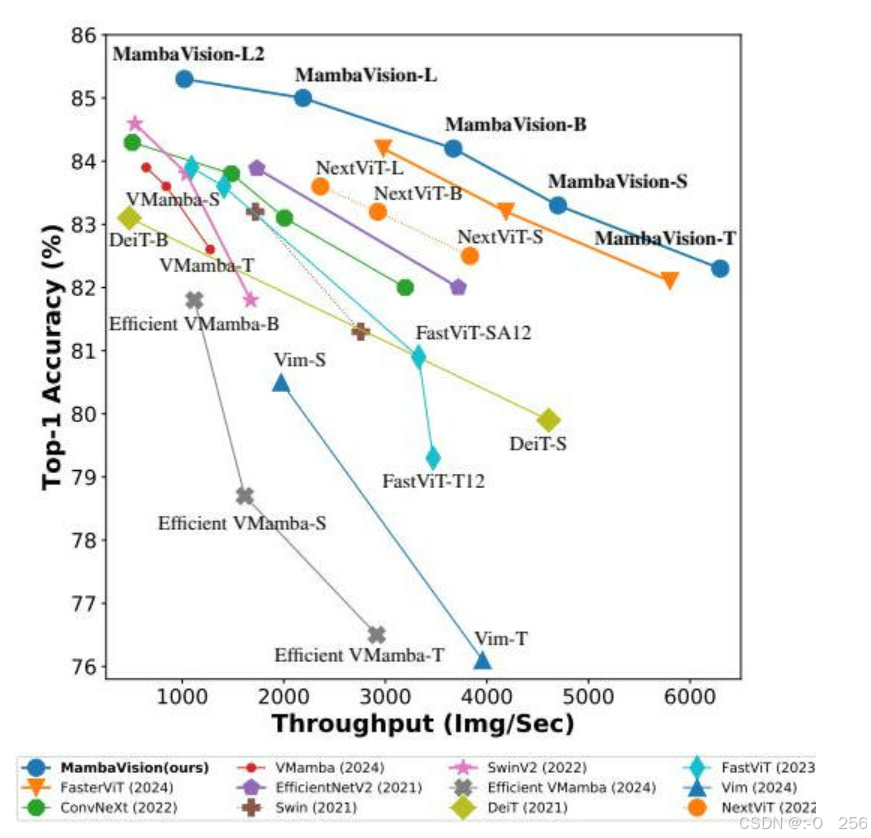
图 1 – ImageNet-1K 上的 Top-1 准确率 v s {vs} vs 和图像吞吐量。所有测量均在配备 128 批处理大小的 A100 GPU 上进行。MambaVision 实现了新的 SOTA Pareto 前沿。
最近,还提出了一些基于 Mamba 的主干网络 [3, 4],以利用其 SSM 公式在视觉任务(如图像分类和语义分割)中的优势。
然而,Mamba 的自回归公式虽然对于需要顺序数据处理的任务有效,但在从全感受野中受益的计算机视觉任务中面临局限性:(1)与顺序重要的序列不同,图像像素并没有以同样的方式具有序列依赖性。相反,空间关系通常是局部的,需要以更并行和综合的方式考虑。因此,这在处理空间数据时效率低下;(2)像 Mamba 这样的自回归模型逐步处理数据,限制了它在一次前向传递中捕捉和利用全局上下文的能力。相比之下,视觉任务通常需要理解全局上下文,以便对局部区域做出准确的预测。
Vision Mamba (Vim) [3] 和其他研究提出了诸如双向 SSM 等修改,以解决全局上下文和空间理解的缺失问题。虽然双向 SSM 有潜力捕获更全面的上下文,但由于需要处理整个序列才能进行预测,它们引入了显著的延迟。此外,复杂性的增加可能导致训练困难,过拟合的风险,且不一定总能带来更好的准确性。由于这些陷阱,基于 Vision Transformer (ViT) 和卷积神经网络 (CNN) 架构的主干网络仍然在不同的视觉任务上优于最佳的基于 Mamba 的视觉模型。
在这项工作中,我们系统地重新设计了 Mamba 块,使其更适合视觉任务。我们提出了一种混合架构,包括我们提出的公式(即 MambaVision 混合器和 MLP)以及 Transformer 块。具体来说,我们研究了不同的集成模式,例如以等参数方式将 Transformer 块添加到早期、中期和最后几层以及每个 l l l 层。我们的分析表明,在最后阶段利用多个自注意力块可以显著增强捕获全局上下文和长距离空间依赖性的能力。如第 5 节所示,使用混合架构还比纯 Mamba 或基于 ViT 的模型具有更高的图像吞吐量。
我们介绍了MambaVision模型,该模型包含一个多分辨率架构,并利用基于CNN的残差块对较大分辨率特征进行快速特征提取。如图1所示,MambaVision在ImageNet-1K Top-1准确性和图像吞吐量方面达到了新的SOTA帕累托前沿,超过了Mamba、CNN和基于ViT的模型,有时甚至有显著的领先。在下游任务如目标检测、实例分割以及语义分割中,具有MambaVision主干网络的模型分别在MS COCO和ADE20数据集上超过了同样大小的对比模型。因此,这验证了MambaVision作为一种高效主干网络的有效性和通用性。
据我们所知,MambaVision是第一个研究并开发包含Mamba和Transformer的混合架构以应用于计算机视觉任务的尝试。我们在这项工作中的主要贡献可以概括如下:
-
我们引入了一个重新设计的视觉友好型Mamba块,提高了原始Mamba架构的准确性和图像吞吐量。
-
我们对Mamba和Transformer块的集成模式进行了系统研究,并证明在最后阶段加入自注意力块显著提高了模型捕捉全局上下文和长距离空间依赖性的能力。
-
我们介绍了MambaVision,这是一个新颖的混合Mamba Transformer模型。分层的MambaVision在ImageNet-1K数据集上达到了新的SOTA帕累托前沿,在Top-1准确性和图像吞吐量权衡方面。
2 相关工作
ViT. 视觉变换器(ViT)[5] 作为一种有前景的卷积神经网络(CNNs)替代方案出现,利用自注意力层提供扩大的感受野。然而,ViT最初缺乏卷积神经网络的一些内在优势,例如归纳偏置和平移不变性,并且它们需要大规模训练数据集才能达到有竞争力的性能。为了解决这些局限性,数据高效图像变换器(DeiT)[6] 引入了一种基于蒸馏的训练策略,即使在较小的数据集上也能显著提高分类精度。在此基础上,LeViT [7] 模型提出了一种混合方法,集成了重新设计的MLP和自注意力模块,这些模块针对快速推理进行了优化,提高了效率和性能。此外,交叉协方差图像变换器(XCiT)[8] 引入了一种转置自注意力机制,有效地建模特征通道之间的交互,提高了模型捕捉数据中复杂模式的能力。金字塔视觉变换器(PVT)[9] 采用了一种分层结构,在每个阶段的开始进行补丁嵌入和空间维度减少,从而提高了计算效率。同样,Swin 变换器 [10] 提出了一种分层架构,其中自注意力在局部窗口内计算,这些窗口移动以实现区域间的交互,平衡了局部和全局上下文。Twins 变换器 [11] 以空间可分离的自注意力为特色,显著提高了效率。此外,焦点变换器 [12] 利用焦点自注意力来捕捉长程空间交互的细粒度细节。
Mamba。自从Mamba的引入以来,已经提出了许多努力来利用其用于视觉应用的能力。特别是,Vim [3] 提出了使用双向SSM公式,与相同的Mamba公式,其中令牌在正向和反向进行处理,以捕捉更全局的上下文并提高空间理解。然而,双向编码增加了计算负担,可能会减慢训练和推理时间。此外,有效地从多个方向结合信息以形成连贯的全局理解是具有挑战性的,因为在过程中可能会丢失一些全局上下文。与Vim不同,我们提出的MambaVision使用单一的前向传递和一个重新设计的Mamba块,能够捕捉到短距离和长距离信息,并且在ImageNet Top-1准确性和吞吐量方面都显著优于它。
EfficientVMamba [4] 提出了一个基于孔洞的选择性扫描,结合跳采样方法来有效地提取全局空间依赖。EfficientVMamba还使用了一种分层架构,由SSM和基于CNN的块组成,其中SSM用于更大的输入分辨率以更好地捕捉全局上下文,而CNN用于较低的分辨率。与EfficientV-Mamba相比,MambaVision在更高分辨率使用CNN来快速提取特征,同时在较低分辨率使用SSM和自注意力来捕捉短距离和长距离空间依赖的细微细节。我们提出的MambaVision在Top-1准确性和图像吞吐量方面也以显著优势超过了EfficientVMamba。
此外,VMamba [13] 引入了一个基于 Mamba 的通用视觉主干网络,其中包含一个交叉扫描模块(CSM),该模块能够实现具有扩大全局感受野的 1D 选择性扫描。具体来说,CSM 模块采用四向选择性扫描方法(即从左上到右下相反方向)来整合来自所有周围标记的信息并捕获更全局的上下文。另外,VMamba 进行了架构上的改变,例如使用深度卷积和分层多分辨率结构。尽管 CSM 模块的设计更适合视觉任务,但其感受野仍然受到交叉扫描路径的限制。与 VMamba 相比,我们提出的 MambaVision 混合器设计更简单,并且能够捕获短距离和长距离依赖。MambaVision 还使用基于 CNN 的层进行快速特征提取,而 VMamba 在所有阶段使用相同的块结构。此外,MambaVision 模型在具有显著更高图像吞吐量的同时,性能超过了 VMamba 对应模型。
3 方法论
3.1 宏观架构
在本节中,我们介绍了MambaVision,这是我们提出的在ImageNet-1K数据集上具有最先进性能的新型架构。如图2所示,MambaVision具有分层的架构,包括4个不同的阶段。前两个阶段由基于CNN的层组成,用于在较高的输入分辨率下快速提取特征,而第3和第4阶段包括我们提出的MambaVision和Transformer块。具体来说,给定一个大小为 H × W × 3 H \times W \times 3 H×W×3的图像,输入首先被转换为大小为 H 4 × W 4 × C \frac{H}{4} \times \frac{W}{4} \times C 4H×4W×C的重叠补丁,并通过由两个连续的 3 × 3 3 \times 3 3×3 CNN层(步长为2)组成的茎部,投影到 C C C维的嵌入空间。阶段之间的降采样器由一个步长为2的批量归一化 3 × 3 3 \times 3 3×3 CNN层组成,它将图像分辨率减半。此外,第1和第2阶段的CNN块遵循以下通用残差块公式:
z ^ = GELU ( BN ( Conv 3 × 3 ( z ) ) ) (1) \widehat{\mathbf{z}} = \operatorname{GELU}\left( {\operatorname{BN}\left( { {\operatorname{Conv}}_{3 \times 3}\left( \mathbf{z}\right) }\right) }\right) \tag{1} z =GELU(BN(Conv3×3(z)))(1)
z = BN ( Conv 3 × 3 ( z ^ ) ) + z \mathbf{z} = \operatorname{BN}\left( { {\operatorname{Conv}}_{3 \times 3}\left( \widehat{\mathbf{z}}\right) }\right) + \mathbf{z} z=BN(Conv3×3(z ))+z
GELU and BN denote Gaussian Error Linear Unit activa- tion function [14] and batch normalization [15], respectively. \begin{matrix} \text{ GELU } & \text{ and } & \text{ BN } & \text{ denote } & \text{ Gaussian } & \text{ Error } & \text{ Linear } & \text{ Unit } & \text{ activa- } \\ \text{ tion } & \text{ function } & \text{ [14] } & \text{ and } & \text{ batch } & \text{ normalization } & \text{ [15],} & \text{ respectively. } & \end{matrix} GELU tion and function BN [14] denote and Gaussian batch Error normalization Linear [15], Unit respectively. activa-
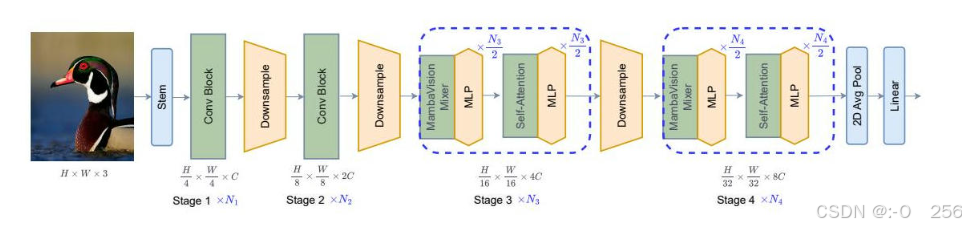
图2 - 分层MambaVision模型的架构。前两个阶段使用残差卷积块进行快速特征提取。第3和第4阶段同时使用MambaVision和Transformer块。具体来说,给定 N N N层,我们使用 N 2 \frac{N}{2} 2N个MambaVision和MLP块,之后是额外的 N 2 \frac{N}{2} 2N个Transformer和MLP块。最终层的Transformer块允许恢复丢失的全局上下文并捕获长距离的空间依赖关系。
3.2 微架构
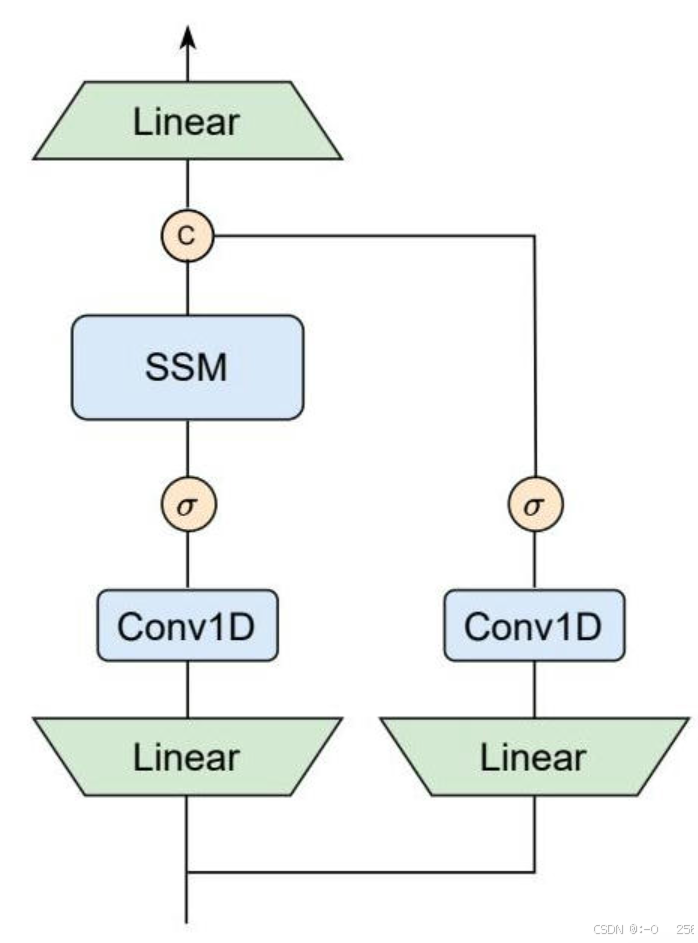
图3 - MambaVision块的架构。除了将因果卷积层替换为其常规对等物外,我们还创建了一个没有SSM的对称路径作为标记混合器,以增强对全局上下文的建模。
在本节中,我们首先回顾了Mamba和SSM的预备知识。然后,我们介绍了第3和第4阶段的架构微设计,并详细讨论了MambaVision的公式。
3.2.1 Mamba预备知识
Mamba是结构化状态空间序列模型(S4)的扩展,它能够通过可学习的隐藏状态 x ( t ) ∈ R x\left( t\right) \in \mathbb{R} x(t)∈R 将一维连续输入 y ( t ) ∈ R y\left( t\right) \in \mathbb{R} y(t)∈R 转换为 h ( t ) ∈ R M h\left( t\right) \in {\mathbb{R}}^{M} h(t)∈RM,其参数为 A ∈ R M × M , B ∈ R 1 × M \mathbf{A} \in {\mathbb{R}}^{M \times M},\mathbf{B} \in {\mathbb{R}}^{1 \times M} A∈RM×M,B∈R1×M 和 C ∈ R 1 × M \mathbf{C} \in {\mathbb{R}}^{1 \times M} C∈R
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4766
4766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









