







系列文章目录
前言与调用
从Transformer架构的出现,到GPT与BERT系列,再到GPT3.5、文心的发布,再到Llama、Qwen、gemma、deepseek等开源。
一、Hugging Face的Transformers
这是一个强大的Python库,专为简化本地运行LLM而设计。其优势在于自动模型下载、提供丰富的代码片段,以及非常适合实验和学习。然而,它要求用户对机器学习和自然语言处理有深入了解,同时还需要编码和配置技能。
二、Llama.cpp
基于C++的推理引擎,专为Apple Silicon打造,能够运行Meta的Llama2模型。它在GPU和CPU上的推理性能均得到优化。Llama.cpp的优点在于其高性能,支持在适度的硬件上运行大型模型(如Llama 7B),并提供绑定,允许您使用其他语言构建AI应用程序。其缺点是模型支持有限,且需要构建工具。
三、Llamafile
由Mozilla开发的C++工具,基于llama.cpp库,为开发人员提供了创建、加载和运行LLM模型所需的各种功能。它简化了与LLM的交互,使开发人员能够轻松实现各种复杂的应用场景。Llamafile的优点在于其速度与Llama.cpp相当,并且可以构建一个嵌入模型的单个可执行文件。然而,由于项目仍处于早期阶段,不是所有模型都受支持,只限于Llama.cpp支持的模型。
四、Ollama
作为Llama.cpp和Llamafile的用户友好替代品,Ollama提供了一个可执行文件,可在您的机器上安装一个服务。安装完成后,只需简单地在终端中运行即可。其优点在于易于安装和使用,支持llama和vicuña模型,并且运行速度极快。然而,Ollama的模型库有限,需要用户自己管理模型。
五、vLLM
这是一个高吞吐量、内存高效的大型语言模型(LLMs)推理和服务引擎。它的目标是为所有人提供简便、快捷、经济的LLM服务。vLLM的优点包括高效的服务吞吐量、支持多种模型以及内存高效。然而,为了确保其性能,用户需要确保设备具备GPU、CUDA或RoCm。
六、TGI(Text Generation Inference)
由HuggingFace推出的大模型推理部署框架,支持主流大模型和量化方案。TGI结合Rust和Python,旨在实现服务效率和业务灵活性的平衡。它具备许多特性,如简单的启动LLM、快速响应和高效的推理等。通过TGI,用户可以轻松地在本地部署和运行大型语言模型,满足各种业务需求。经过优化处理的TGI和Transformer推理代码在性能上存在差异,这些差异体现在多个层面:
并行计算能力:TGI与Transformer均支持并行计算,但TGI更进一步,通过Rust与Python的联合运用,实现了服务效率与业务灵活性的完美平衡。这使得TGI在处理大型语言模型时,能够更高效地运用计算资源,显著提升推理效率。
创新优化策略:TGI采纳了一系列先进的优化技术,如Flash Attention、Paged Attention等,这些技术极大地提升了推理的效率和性能。而传统的Transformer模型可能未能融入这些创新优化。
模型部署支持:TGI支持GPTQ模型服务的部署,使我们能在单卡上运行启用continuous batching功能的更大规模模型。传统的Transformer模型则可能缺乏此类支持。
尽管TGI在某些方面优于传统Transformer推理,但并不意味着应完全放弃Transformer推理。在特定场景下,如任务或数据与TGI优化策略不符,使用传统Transformer推理可能更合适。当前测试表明,TGI的推理速度暂时逊于vLLM。TGI推理支持以容器化方式运行,为用户提供了更为灵活和高效的部署选项。
七、DeepSpeed
微软精心打造的开源深度学习优化库,以系统优化和压缩为核心,深度优化硬件设备、操作系统和框架等多个层面,更利用模型和数据压缩技术,极大提升了大规模模型的推理和训练效率。DeepSpeed-Inference,作为DeepSpeed在推理领域的扩展,特别针对大语言模型设计。它巧妙运用模型并行、张量并行和流水线并行等技术,显著提升了推理性能并降低了延迟。
本博客尝试只使用Hugging Face的Transformers库调用模型,看看能否实现简洁的调用。
一、部署要求

二、实现步骤
1、深度学习环境
因为LLM使用的环境可能会更新更高,所以使用的基础环境如下:
NVIDIA-SMI 525.60.11
cuda 12.1.0
cudnn 8.9.2
根据cuda版本选择对应的pytorch、torchvision、python环境。
以下版本截止2024年4月29日:
直接选择最新的那一档,cuda12.1,Python3.10,PyTorch2.2.0,torchvision0.17.0。

使用anaconda安装以下内容,安装方式参考往期博文:
python 3.10
PyTorch 2.2.0
torchvision 0.17.0
1.验证pytorch版本时提示以下问题:
OSError: libmkl_intel_lp64.so: cannot open shared object file: No such file or directory

修改环境变量配置文件:
gedit ~/.bashrc
在~/.bashrc文件末尾另起一行添加:
export LD_LIBRARY_PATH=/home/xxx/anaconda3/lib:$LD_LIBRARY_PATH
更新环境变量配置文件:
source ~/.bashrc
查看是否更新成功:
echo $LD_LIBRARY_PATH
# 输出必须带有/home/xxx/anaconda3/lib才算成功
2.验证pytorch版本时提示以下问题:
OSError: libcudart.so.12: cannot open shared object file: No such file or directory
1、确认CUDA和cudnn是否正确安装,版本是否对应。
# 查看当前cuda的版本
nvcc --version
#查看cudnn版本
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
2、如果确定安装了对应版本的CUDA和cudnn,查看 ~/.bashrc环境变量是否正确包含了 对应的库文件路径。
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda/bin:$PATH
3、如果安装了CUDA和cudnn,确定版本正确,成功链接,那么移动或者重写 ~/.bashrc环境变量中的CUDA和cudnn库文件路径,然后更新。
3.有时候还会提示你有一些库没有安装,使用pip安装即可。
2、transformers库安装
1.使用pip安装
huggingface的Transformers库要求的深度学习环境版本如下:
Python 3.8+
Flax 0.4.1+ / PyTorch 1.11+ / TensorFlow 2.6+
建议尽量在anaconda虚拟环境中安装Transformers库。
首先,创建一个3.10版本的虚拟环境并激活:
conda create -n your_env_name python=3.10
source activate your_env_name
然后,在虚拟环境中安装Flax 0.4.1+或PyTorch 1.11+或TensorFlow 2.6+神经网络算法库(选择其中之一):
最后,安装Transformers库:
# transformers >= 4.43.0
pip install transformers
提示成功安装Transformers库和大部分依赖库,但有个别依赖库安装失败,比如Pillow库:


单独安装Pillow库:
pip install Pillow -i https://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn
如果还提示却别的库也是这样安装就好。
查看虚拟环境中的库:
conda list

3、模型下载

大部分模型都可以在huggingface网站下载,直接点击Clone repository选项,选择git方式下载:

git clone https://huggingface.co/meta-llama/Llama-3.2-1B
用这种方法下载不仅需要上外网,而且下载速度还会比较慢,除此之外有一些模型下载使用还需要向官方申请许可,比如:

这里使用一些取巧的方法:
使用国内阿里的大模型平台modelscope魔搭网站下载
Llama-3.2-1B模型modelscope下载地址modelscope,直接点击模型文件,点击下载模型:

它会提供一些不同的下载命令:

这里直接使用modelscope库下载:
# 先安装modelscope库
pip install modelscope
# 不加–local_dir选项,会使得模型保存在临时文件(/home/xxx/.cache/modelscope/hub)中,不方便查找
modelscope download --model LLM-Research/Llama-3.2-1B
# 加上–local_dir选项,使得模型保存在指定文件夹文件(/home/xxx/LLM-Research/Meta-Llama-3.2-1B-Instruct)中,方便查找
modelscope download --model LLM-Research/Llama-3.2-1B --local_dir /home/xxx/Llama-3.2-1B

这样在绕过许可证的同时,也能避免外网问题,快速下载。
4、模型调用
使用以下代码可以简单调用这个模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
def load_model_and_tokenizer(model_directory):
"""
从本地目录加载模型和分词器。
"""
tokenizer = AutoTokenizer.from_pretrained(model_directory)
# 添加特殊的填充令牌
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
model = AutoModelForCausalLM.from_pretrained(model_directory)
# model.half()
return model, tokenizer
def generate_text(model, tokenizer, prompt, max_new_tokens):
"""
使用提供的模型和分词器生成文本。
"""
# 编码输入提示
inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True)
input_ids = inputs['input_ids']
attention_mask = inputs['attention_mask']
# 生成文本
output = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_new_tokens=max_new_tokens,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=2,
repetition_penalty=1.5,
top_k=50,
top_p=0.95,
temperature=1.0,
do_sample=True,
num_return_sequences=1,
num_beams=2, # 设置 num_beams > 1
early_stopping=True
)
# 解码生成的文本
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
return generated_text
def chat_with_model(model, tokenizer, max_new_tokens):
"""
与模型进行聊天对话。
"""
print("Chat with the model! Type 'exit' to end the conversation.")
prompt = "You are an Intelligent Traffic Rules Q&A Assistant, and when user ask you questions, you will provide me with traffic knowledge.Next, user will ask you questions, please answer them.\n"
# once_input = input("User1:")
#
# if once_input.lower() == 'exit':
# print("Assistant: Goodbye! Stay safe on the roads!")
# exit()
#
# input_to_model = prompt + "\nUser2:" + once_input + "\nAssistant"
#
# response = generate_text(model, tokenizer, input_to_model, max_new_tokens)
print("111", prompt)
while True:
user_input = input("User3: ")
if user_input.lower() == 'exit':
print("Assistant: Goodbye! Stay safe on the roads!")
break
input_to_model = prompt + user_input + "\nAssistant"
# 更新对话历史
# 生成模型的回答
response = generate_text(model, tokenizer, input_to_model, max_new_tokens)
print(response)
def main():
model_directory = "/LLM/Llama-3.2-1B/"
max_new_tokens = 100 # 生成新 token 的最大数量
# 加载模型和分词器
model, tokenizer = load_model_and_tokenizer(model_directory)
# 确保模型处于评估模式
model.eval()
# 开始聊天对话
chat_with_model(model, tokenizer, max_new_tokens)
if __name__ == "__main__":
main()
简单问答:

三、模型框架
1、LLaMA模型的发展
LLaMA 1:2023年2月首次公开发布了LLaMA 1版本,奠定了模型的基本架构和训练方法,采用了 Transformer 的解码器架构,并引入了如 RMS Norm、Swiglu 激活函数和旋转位置编码等技术,以提高模型的性能和训练稳定性。
LLaMA 2:2023年7月公开发布了LLaMA 2版本,在 LLaMA 1 的基础上进行了优化和改进,在预训练数据量、模型结构和训练方法等方面都有所提升。预训练数据量大幅增加,使得模型能够学习到更丰富的语言知识和语义信息。在模型结构上,可能对一些超参数进行了调整,如层数、头数和维度等,以进一步提高模型的性能。同时,在训练方法上,采用了更先进的优化算法和技巧,如分组查询注意力(Grouped-Query Attention)等,提高了训练效率和模型质量。
LLaMA 3:于 2024 年 4 月发布,主要在以下几个方面进行了升级: 预训练数据和语料库:预训练语料库规模相比 LLaMA 2 增加了 650%,训练数据的丰富度和多样性的提升有助于模型更好地理解和生成各种类型的文本。
上下文长度:将 8B 和 70B 模型的上下文长度从 4k 翻倍到8k,使模型能够更好地处理长文本序列,更适用于一些需要较长上下文信息的任务,如长篇文章生成、多轮对话等。
分组查询注意力:在 8B 和 70B 变体中采用了分组查询注意力机制,进一步优化了模型对长序列的处理能力和计算效率。
LLaMA 3.1:在 2024 年 7 月推出,相比 LLaMA 3 有以下改进: 参数规模和模型变体:模型参数范围从 8B 到 405B,其中 405B 参数变体是最大的密集 Transformer 模型,能够处理更复杂的任务和模式。
上下文长度扩展:将上下文窗口扩展到 128k tokens,极大地增强了模型对长文本的处理能力,更适合处理长篇小说、复杂的技术文档等。
多模态能力探索:进行了多模态实验,包括图像和语音编码器的预训练,以及视觉和语音适配器的训练,为模型未来实现多模态融合奠定了基础。
LLaMA 3.2:于 2024 年 9 月发布,主要更新包括: 轻量化和多样化的模型规模:发布了 1B 和 3B 参数的纯文本模型,以及 11B 和 90B 参数的视觉增强模型,满足了不同用户和应用场景对模型规模和性能的需求。
多模态能力的正式引入:具备了处理文本和图像的多模态能力,通过在模型中集成图像编码器和相关的适配器,实现了文本和图像的交互和融合,可应用于图像字幕生成、视觉问答等领域。
针对边缘和移动设备的优化:对模型进行了优化,使其能够在边缘和移动设备上更高效地运行,降低了对硬件资源的要求,提高了模型的可部署性和实用性。
LLaMA 3.3:于 2024 年 12月发布,主要更新包括: 优化的Transformer架构:Llama 3.3-70B模型是基于Transformer架构进行优化,对这一架构进行了改进,以提高模型的效率和性能。这种优化使得Llama3.3-70B能够在保持较小模型大小的同时,实现与更大模型(例如Llama3.1的405B模型)相媲美的性能。
分组查询注意力(GQA):Llama3.3-70B模型整合了分组查询注意力(GQA)机制,这是一种在推理期间提高可扩展性和性能的技术。GQA通过减少模型在处理时需要考虑的参数数量,从而提高了模型的运行效率,尤其是在处理大规模数据时。
长上下文窗口支持:Llama 3.3-70B模型引入了更长的上下文窗口支持,能够处理长达128k token的输入,这相当于大约400页的文本。这一功能使得模型在处理长篇内容时更加有效,为长形式内容生成和其他高级用例提供了可能。
多语言支持:Llama3.3-70B模型不仅支持英语,还支持法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语等多种语言。而且训练数据中还包含更多语言。
2、模型结构
从总体上看,LLaMa模型使用了Transformer的解码器部分。LLaMa模型与GPT模型类似,只使用了Transformer的解码器部分,这种结构被称为decoder-only结构。
在原始Transformer中,解码器中的Multi-Head Attention是用来处理编码器输出的交叉注意力,而LLaMA作为decoder-only模型,不需要这个部分。因此,LLaMA的解码器层只保留Masked Multi-Head Attention和前馈网络,没有第二个Multi-Head Attention。
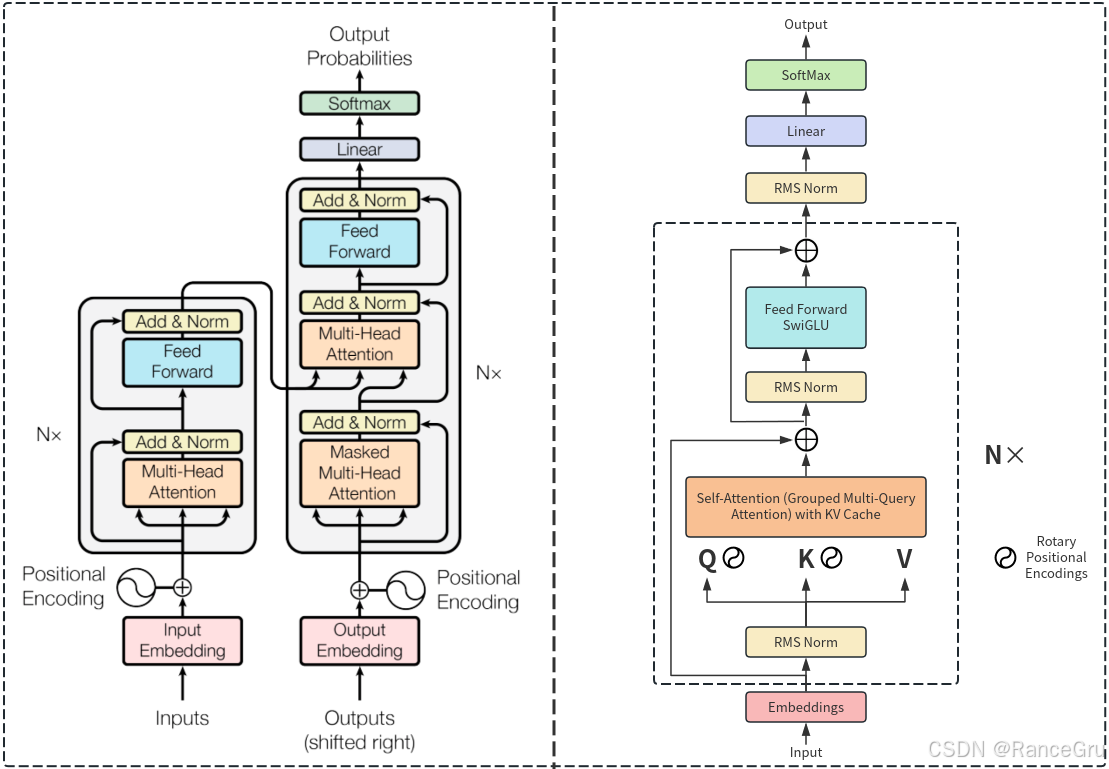
3、归一化函数
Pre-normalization预标准化:为了提高训练稳定性,LLaMa对每个Transformer子层的输入进行归一化,而不是对输出进行归一化。使用的归一化函数是RMSNorm。
归一化是常用的稳定训练的手段,CV 模型中常用 Batch Norm, NLP 模型中常用 Layer Norm,而 RMS Norm (Root Mean Square Layer Normalization,均方根归一化)是LaMMa 模型使用的标准化方法,它是 Layer Norm 的一个变体。
LayerNorm通过对每个样本的特征维度进行归一化,减少了内部协变量偏移。然而,LayerNorm需要计算输入特征的均值和方差,这增加了计算复杂度和开销。
RMSNorm消除对均值计算的依赖,仅通过输入特征的均方根(RMS) 进行归一化,简化归一化过程,降低计算复杂度,同时保持或提升模型的性能。
1.LayerNorm
(1)
μ
^
=
1
d
∑
x
i
∈
X
x
i
\hat{\mu} = \frac{1}{d} \sum_{x^i\in X}x^i
μ^=d1xi∈X∑xi
(2)
σ
^
2
=
1
d
∑
x
i
∈
X
(
x
i
−
μ
)
2
+
ϵ
\hat{\sigma}^2 = \frac{1}{d} \sum_{x^i\in X}(x^i - \mu)^2 + \epsilon
σ^2=d1xi∈X∑(xi−μ)2+ϵ
(3)
L
N
(
X
)
=
γ
⨀
X
−
μ
^
σ
^
+
β
LN(X) = \gamma \bigodot \frac{X - \hat{\mu}}{\hat{\sigma}} + \beta
LN(X)=γ⨀σ^X−μ^+β
1)
x
x
x是输入的特征向量。
2)
μ
\mu
μ是输入的均值。
3)
σ
2
\sigma^2
σ2是输入的方差。
4)
ϵ
\epsilon
ϵ是一个很小的正数,用于避免除零问题。
5)
γ
\gamma
γ和
β
\beta
β是可学习的缩放和偏移参数。
6)
⨂
\bigotimes
⨂ 表示逐元素乘法。
2.RMSNorm
(1)
R
M
S
(
x
)
2
=
1
d
∑
x
i
∈
X
x
i
2
+
ϵ
RMS(x)^2 = \frac{1}{d} \sum_{x^i\in X}x_i^2 + \epsilon
RMS(x)2=d1xi∈X∑xi2+ϵ
(2)
R
M
S
N
o
r
m
(
x
)
=
γ
⨀
x
R
M
S
(
x
)
RMSNorm(x) = \gamma \bigodot \frac{x}{RMS(x)}
RMSNorm(x)=γ⨀RMS(x)x
1)
x
x
x是输入的特征向量。
2)
R
M
S
(
X
)
RMS(X)
RMS(X)是输入的均方根。
3)
ϵ
\epsilon
ϵ是一个很小的正数,用于避免除零问题。
4)
γ
\gamma
γ是可学习的缩放参数。
5)
⨂
\bigotimes
⨂ 表示逐元素乘法。
比较总结:
计算复杂度:RMSNorm减少了均值的计算,降低了整体计算量。
数值稳定性:RMSNorm避免了方差接近零的情况,提升了数值稳定性。
表现性能:在某些任务中,RMSNorm可以达到或超过LayerNorm的性能。
4、激活函数
激活函数替换:LLaMa使用了SwiGLU激活函数替换传统的ReLU非线性函数,以提高性能。
1.Linear函数
Linear函数是一种仿射变换(线性变换 + 平移),在深度学习中也称为“线性函数”,神经网络中的全连接层(Dense Layer)、卷积层(Convolution Layer)等,本质都是通过线性变换(( Wx + b ))将输入映射到新的空间。
L
i
n
e
a
r
(
x
)
=
x
W
+
b
Linear(x) = xW+b
Linear(x)=xW+b
1)x是输入的特征向量。
2)W是权重,b是偏置,是可学习的参数。
单独线性函数无法解决复杂问题(多层线性叠加仍是线性的)。因此,线性层后通常接激活函数(如 ReLU、Sigmoid),引入非线性,使网络能拟合任意复杂函数。
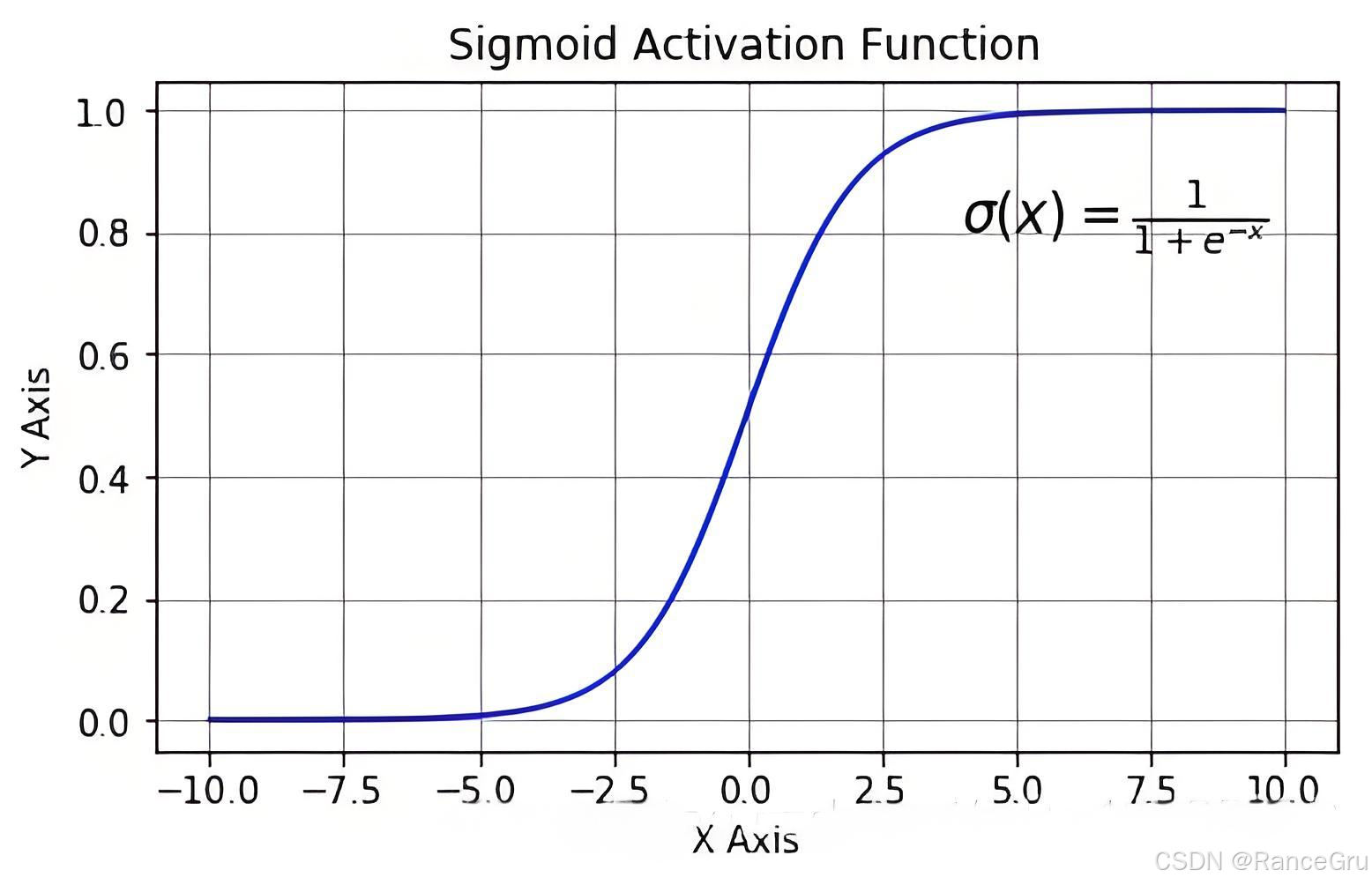
2.Sigmoid激活函数
Sigmoid激活函数应该是深度神经网络最先使用的激活函数,它的函数图形是一个S形的曲线,也被称为S曲线(S-curve),它具有以下特性:
输出界限:由于Sigmoid函数的输出范围在0到1之间,它可以被用于将任何值映射到概率空间。这使得Sigmoid函数非常适合于二分类任务的最后输出,比如在二分类问题中预测一个事件发生的概率。
非线性特性:Sigmoid函数是一个非线性函数,这意味着当我们使用它作为激活函数时,可以帮助神经网络学习到输入数据中的非线性复杂关系。如果没有非线性激活函数,无论神经网络有多少层,最终都只能学习到输入数据的线性组合。
平滑梯度:Sigmoid函数的梯度在其定义域内处处存在,这保证了在使用基于梯度的优化算法(如梯度下降)时,每一步都能够找到方向。它的平滑性质也使得模型的训练更加稳定。
σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
1)
x
x
x是输入的特征向量。
2)e 是自然对数的底数。
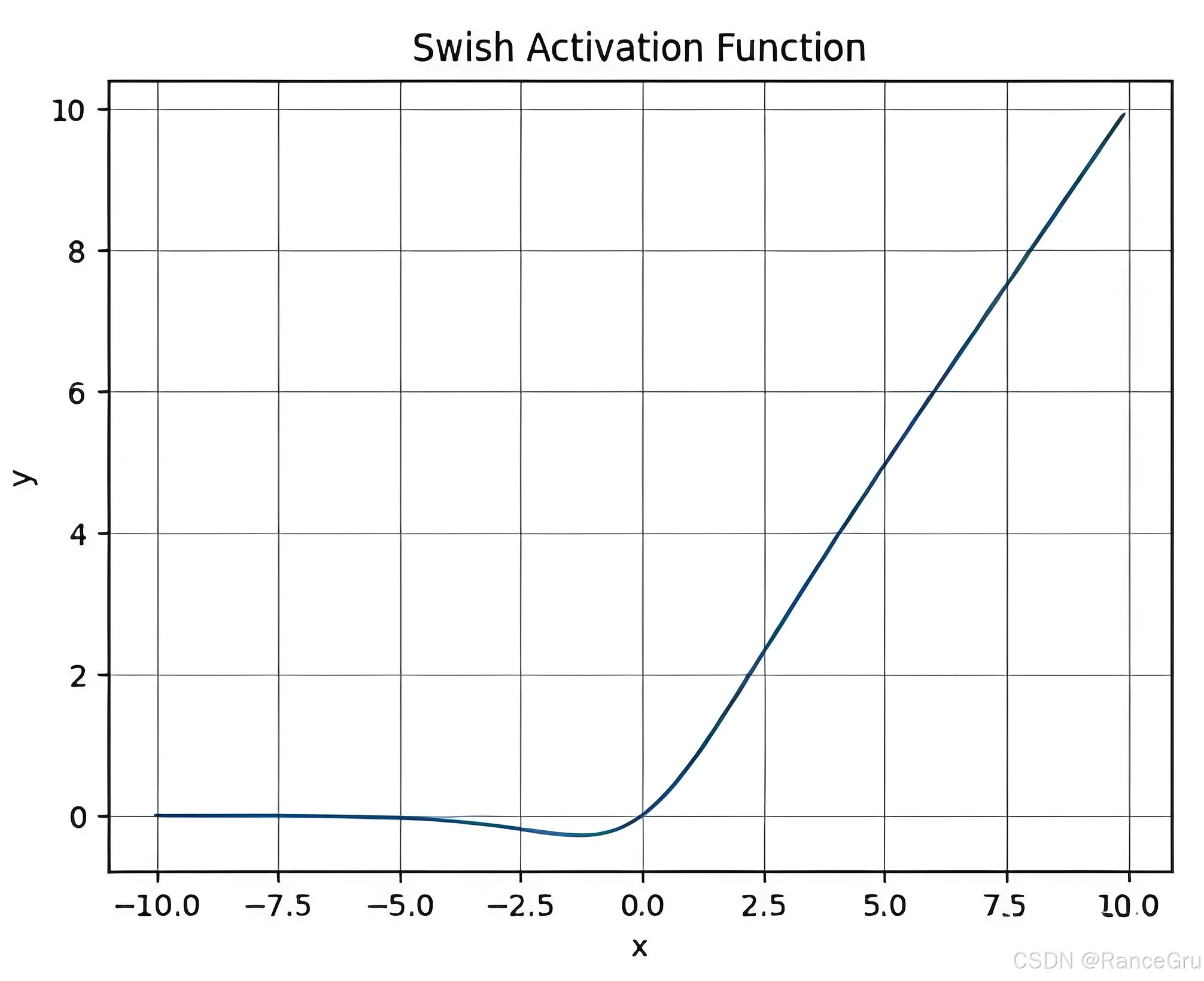
3.Swish激活函数
Swish激活函数 是一种由 Google Research 提出的非线性激活函数,Swish 激活函数的特点:
平滑且连续:Swish 是一个平滑的激活函数, 可以更平滑地引导梯度流动,从而可能减少梯度消失问题,并且对神经网络的优化更有利。
非单调函数:与 ReLU 或 Sigmoid 等激活函数不同,Swish 不是严格单调的,这意味着它在某些情况下可能更加灵活地适应数据和任务的需求。
梯度信息较好:在正区间和负区间都有较为稳定的梯度,这有助于避免梯度爆炸或梯度消失问题。
平滑梯度:Swish 能提供比 ReLU 更加平滑的梯度。
无饱和区:即使输入为负值,Swish函数也能产生非零梯度,避免了ReLU的“神经元死亡”问题。
S w i s h β ( x ) = x ⋅ σ ( β x ) Swish_\beta(x) = x\cdot\sigma(\beta x) Swishβ(x)=x⋅σ(βx)
S w i s h ( x ) = x ⋅ S i g m o i d ( x ) Swish(x) = x\cdot Sigmoid(x) Swish(x)=x⋅Sigmoid(x)
1)
x
x
x是输入的特征向量。
2)
σ
(
x
)
\sigma(x)
σ(x) 是 Sigmoid 激活函数。
3)当β趋近于0时,Swish函数趋近于线性函数
y
=
x
2
y = x^2
y=x2。
4)当β趋近于无穷大时,Swish函数趋近于ReLU函数。
5)当β取值为1时,Swish函数是光滑且非单调的,等价于SiLU激活函数。
4.GLU激活函数
SwiGLU激活函数结合了Swish和GLU两者的特点,它是GLU门控线性单元的一个变种。
了解SwiGLU必须从GLU入手,GLU提出于2016年发表的论文《nguage modeling with gated convolutional networks》中,是一种类似LSTM带有门机制的网络结构,相比于LSTM,GLU不需要复杂的门机制,不需要遗忘门,仅有一个输入门。同时它类似Transformer一样具有可堆叠性和残差连接,它的作用是完成对输入文本的表征,通过门机制控制信息通过的比例,来让模型自适应地选择哪些单词和特征对预测下一个词有帮助,通过堆叠来挖掘高阶语义,通过残差连接来缓解堆叠的梯度消失和爆炸。
G L U ( x , W , V , b , c ) = σ ( x W + b ) ⨂ ( x V + c ) GLU(x,W,V,b,c) = \sigma(xW+b)\bigotimes(xV+c) GLU(x,W,V,b,c)=σ(xW+b)⨂(xV+c)
G L U ( x ) = S i g m o i d ( L i n e a r ( x ) ) ⨂ L i n e a r ( x ) GLU ( x ) = Sigmoid(Linear (x))\bigotimes Linear (x) GLU(x)=Sigmoid(Linear(x))⨂Linear(x)
1)
x
x
x是输入的特征向量。
2)
σ
(
x
)
\sigma(x)
σ(x) 是 Sigmoid 激活函数。
3)W、V以及b、c分别是这两个线形层的两个参数。
4)
⨂
\bigotimes
⨂ 表示逐元素乘法。
5.SwiGLU激活函数
在2020年发表的论文《GLU Variants Improve Transformer》中,提出使用GLU的变种来改进Transformer的FFN层,就是将GLU中原始的Sigmoid激活函数替换为其他的激活函数,作者列举了替换为ReLU,GELU和SwiGLU的三种变体。
门控特性:可以根据输入的情况决定哪些信息应该通过、哪些信息应该被过滤,增强模型对重要特征的关注,有助于提高模型的泛化能力。在大语言模型中,这对于处理长序列、长距离依赖的文本特别有用。
提高性能:在许多基准测试中,swiGLU 已被证明比 GLU、ReLU 及其他激活函数提供更好的表现。
平滑梯度:Swish 函数的平滑性使得反向传播的梯度更新更稳定,减轻梯度消失的问题。
计算效率:尽管引入了额外的非线性激活函数,swiGLU 的计算开销相对较小,适合大型模型。
S w i G L U ( x , W , V , b , c , β ) = S w i s h β ( x W + b ) ⨂ ( x V + c ) SwiGLU(x, W, V, b, c, \beta) = Swish_\beta(xW+b)\bigotimes(xV+c) SwiGLU(x,W,V,b,c,β)=Swishβ(xW+b)⨂(xV+c)
S w i G L U ( x ) = S w i s h ( L i n e a r ( x ) ) ⨂ L i n e a r ( x ) SwiGLU(x) = Swish(Linear(x))\bigotimes Linear(x) SwiGLU(x)=Swish(Linear(x))⨂Linear(x)
1)
x
x
x是输入的特征向量。
2)W, V是线性变换的权重矩阵,将输入投影到不同空间。
3)b, c是偏置项,调整线性变换的偏移。
4)
β
\beta
β是Swish 的形状参数,通常设为1或可学习。
5、位置编码
位置嵌入:LLaMa删除了绝对位置嵌入,而是使用了旋转位置嵌入(RoPE),这种改进有助于模型在处理语言任务时更加灵活。
在Transformer出现以前,NLP任务大多是以RNN、LSTM为代表的循环处理方式,即一个token一个token的输入到模型当中。模型本身是一种顺序结构,天生就包含了token在序列中的位置信息。但是这种模型有很多天生的缺陷,比如:
1.会出现“遗忘”的现象,无法支持长时间序列,虽然LSTM在一定程度上缓解了这种现象,但是这种缺陷仍然存在;
2.句子越靠后的token对结果的影响越大;
3.只能利用上文信息,不能获取下文信息;
4.计算的时间复杂度比较高,循环网络是一个token一个token的输入的,也就是句子有多长就要循环多少遍;
Transformer模型中,位置编码(Positional Encoding) 是为了解决自注意力机制(Self-Attention)无法直接感知输入序列中词的位置顺序的问题而引入的技术。由于自注意力机制是“无序的”(它对输入词的位置不敏感),模型需要通过位置编码来显式地注入序列的位置信息。
自注意力通过计算词与词之间的关系来捕捉上下文,但它默认将所有词视为“无序集合”,无法区分像“猫吃鱼”和“鱼吃猫”这样的位置差异。但是自然语言中词的顺序对语义至关重要,所以需要位置编码帮助模型理解词在序列中的相对或绝对位置,如果没有位置编码的信息,模型会丧失序列的顺序信息,导致模型退化成一个简单的“词袋模型”(Bag of Words model)。
1.绝对位置编码
即将每个位置编号,从而每个编号对应一个向量,用来标记token的前后顺序,最终通过结合位置向量和词向量,作为输入embedding,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。
绝对位置编码就是为序列中的每个位置分配一个唯一的编码,这种编码直接反映了元素在序列中的绝对位置。最简单的想法就是从1开始向后排列,但是这种方式存在很大的问题,句子越长token越多,后面的值越大,而且这样的方式也无法凸显每个位置的真实的权重,所以这种方式基本没有人用。
**基于正弦和余弦函数的编码:**由Transformer模型提出,使用正弦和余弦函数的不同频率来为序列中的每个位置生成唯一的编码。这种方法的优点是能够支持到任意长度的序列,并且模型可以从编码中推断出位置信息。通过sin函数和cos函数交替来创建 positional encoding。
P E ( p o s , 2 i ) = s i n ( p o s 1000 0 2 i d m o d e l ) PE_{(pos,2i)} = sin\left(\frac{pos}{10000^{\frac{2i}{d_model}}} \right) PE(pos,2i)=sin(10000dmodel2ipos)
P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i d m o d e l ) PE_{(pos,2i+1)} = cos\left(\frac{pos}{10000^{\frac{2i}{d_model}}} \right) PE(pos,2i+1)=cos(10000dmodel2ipos)
1)pos(位置索引):表示序列中某个词的位置(从0开始计数)。不同位置的词通过不同的 pos 值生成唯一的位置编码。比如对于句子 “I love you”,“I” 的 pos=0,“love” 的 pos=1,“you” 的 pos=2。
2)i(维度索引):表示位置编码向量的维度(从0开始计数)。控制位置编码的频率衰减模式。偶数维度( 2i)使用正弦函数,奇数维度( 2i+1)使用余弦函数,交替生成编码。取值范围是i ∈ [0, d_model/2 - 1](例如,若 d_model=512,则 i 从0到255)。
3)d_model(模型维度):Transformer模型的隐藏层维度,即位置编码向量的长度。决定位置编码的总维度数,需与词嵌入(Token Embedding)的维度一致。BERT-base的 d_model=768,原始Transformer论文中 d_model=512。
4)10000(频率基数):一个预设的超参数,控制位置编码的频率衰减速度决定最大波长(即最低频率)当 i=0 时,波长最大为 1000 0 0 10000^{0} 100000 = 1,对应高频;当 i=d_model/2-1 时,波长最小为 1000 0 ( d m o d e l − 2 ) / d m o d e l 10000^{(d_model-2)/d_model} 10000(dmodel−2)/dmodel,对应低频。通过指数衰减覆盖不同尺度的位置信息(局部细节和全局结构)。
维度交替:偶数维用正弦,奇数维用余弦,确保每个位置编码唯一且不同位置的编码可通过线性变换对齐。
波长控制: 1000 0 2 i d m o d e l 10000^{\frac{2i}{d_model}} 10000dmodel2i使波长随维度增加呈指数增长,高频(小波长)编码局部信息,低频(大波长)编码全局信息。
绝对位置编码的优势在于其简单且具有良好的可解释性。 它能够有效地为序列中的每个位置分配独特的编码,从而帮助模型捕捉序列的顺序信息。然而它也有一定的局限性,尤其是在处理变长序列或长距离依赖时,绝对位置编码可能无法充分表达复杂的位置信息。
- 长度外推性差
问题:绝对位置编码在训练时通常预设了最大序列长度(如 512),当测试时遇到更长的序列时,模型无法直接处理超出预定义长度的位置信息。
影响:强行截断或简单复制位置编码会导致性能下降,例如长文本生成或文档级任务中表现不佳。
示例:若模型在训练时仅见过 512 长度的文本,面对 1024 长度的输入时,位置编码可能失效。 - 难以建模相对位置关系
问题:绝对位置编码主要强调每个位置的“绝对坐标”,但自然语言中更依赖词与词之间的相对距离(如相邻词、跨句依赖)。
影响:模型需额外学习相对位置规律(如注意力机制中的局部窗口),增加了隐式学习负担。
示例:句子中“动词”与“宾语”的位置偏移可能比绝对位置更重要,但绝对编码无法直接表达这种偏移。 - 位置敏感任务中的泛化能力受限
问题:绝对位置编码可能导致模型过度依赖具体位置(如“句首位置总出现某些词”),而非语义逻辑。
影响:在需要动态位置适应的任务(如文本重组、翻译对齐)中表现僵硬。
示例:若训练数据中“时间状语”总出现在句首,模型可能错误关联位置而非语义。 - 计算与存储开销
问题:可学习的绝对位置嵌入需要为每个位置存储独立参数,长序列场景下占用显存。
影响:对超长序列(如书籍生成)不友好,且参数利用率低(不同序列共享同一位置编码表)。 - 跨模态适配困难
问题:绝对位置编码在不同模态(如图像、语音)中需重新设计,难以统一。
影响:多模态任务中需为每种模态单独设计位置编码,增加复杂性。
2.相对位置编码
“Self-Attention with Relative Position Representations”论文
与绝对位置编码不同,相对位置编码(Relative Positional Encoding)并不直接为每个位置分配一个唯一的编码,而是关注序列中各元素之间的相对位置。 相对位置编码的核心思想是通过计算序列中元素之间的距离,来表示它们之间的相对关系。这种方法尤其适合处理需要捕捉长距离依赖关系的任务,因为它能够更加灵活地表示序列中的结构信息。
相对位置编码可以通过多种方式实现,其中最常用的方法之一是将位置差值与注意力权重相结合,即在计算自注意力时,不仅考虑内容,还考虑位置差异。这样模型能够根据元素之间的距离调整它们之间的交互强度。
其核心思想是:将相对位置信息作为可学习的偏置项,直接融入注意力权重和值的计算中,而非像绝对位置编码那样直接添加到输入嵌入。
标准注意力机制公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V Attention(Q,K,V)=softmax(dkQKT)V
1)Query(Q):表示当前需要计算注意力的目标位置(例如当前处理的词)。
2)Key(K):表示输入序列中所有位置的“标识符”,用于与 Query 匹配相似度。
3)Value(V):表示每个位置实际携带的信息,最终通过注意力权重加权聚合。通过 Query 与 Key 的匹配程度,决定从哪些 Value 中提取信息。
4)
d
k
d_k
dk表示Key 向量的维度(通常与 Query 的维度相同)。对点积
Q
K
T
{QK^T}
QKT进行缩放,缩放后使梯度更稳定,训练更高效。
5)
Q
=
x
W
q
,
K
=
x
W
k
,
V
=
x
W
v
Q = xW_q, K = xW_k, V = xW_v
Q=xWq,K=xWk,V=xWv,W为可学习的权重矩阵。
6)T表示转置矩阵。
S o f t m a x = e x i Σ i = 1 n e x i = e x p ( x i ) Σ i = 1 n e x p ( x i ) ∈ ( 0 , 1 ) Softmax = \frac{e^{x_i}}{{\Sigma_{i=1}^n}e^{x_i}} = \frac{exp(x_i)}{{\Sigma_{i=1}^n}exp(x_i)}\in(0,1) Softmax=Σi=1nexiexi=Σi=1nexp(xi)exp(xi)∈(0,1)
标准注意力机制公式转换后的注意力机制公式:
e i j = ( x i W Q ) ( x j W K ) T d z = Q K T d k e_{ij} = \frac{(x_iW^Q)(x_jW^K)^T}{\sqrt{d_z}} = \frac{QK^T}{\sqrt{d_k}} eij=dz(xiWQ)(xjWK)T=dkQKT
1)
e
i
j
e_{ij}
eij是注意力分数的具体计算,缩放因子
d
k
\sqrt{d_k}
dk用于防止点积值过大导致 softmax 梯度消失。
2)
Q
=
x
W
Q
,
K
=
x
W
K
,
V
=
x
W
V
Q = xW^Q, K = xW^K, V = xW^V
Q=xWQ,K=xWK,V=xWV三者分别是输入x通过不同权重矩阵变换得到的查询、键、值矩阵。
α i j = e x p ( e i j ) Σ k = 1 n e x p ( e i k ) \alpha_{ij} = \frac{exp(e_{ij})}{{\Sigma_{k=1}^n}exp(e_{ik})} αij=Σk=1nexp(eik)exp(eij)
z i = ∑ j = 1 n α i j ( x j W V ) z_i = \sum_{j=1}^n \alpha_{ij}(x_jW^V) zi=j=1∑nαij(xjWV)
1)
x
j
W
V
x_jW^V
xjWV是输入
x
j
x_j
xj通过值权重矩阵
W
V
W^V
WV变换后的值向量(即
V
j
V_j
Vj)。
2)
α
i
j
\alpha_{ij}
αij是位置i对位置j的注意力权重。
3)
Q
=
x
W
Q
,
K
=
x
W
K
,
V
=
x
W
V
Q = xW^Q, K = xW^K, V = xW^V
Q=xWQ,K=xWK,V=xWV三者分别是输入x通过不同权重矩阵变换得到的查询、键、值矩阵。
4)
α
i
j
=
s
o
f
t
m
a
x
(
e
i
j
)
\alpha_{ij} = softmax(e_{ij})
αij=softmax(eij),对所有的
e
i
j
e_{ij}
eij进行
softmax
\text{softmax}
softmax,就会得到注意力权重矩阵
α
i
j
\alpha_{ij}
αij,softmax 输出就是
α
i
j
\alpha_{ij}
αij,由查询向量Q和键向量K的点积计算得出。
5)
x
j
W
V
=
V
j
x_jW^V = V_j
xjWV=Vj,
x
j
W
V
x_jW^V
xjWV就是
V
j
V_j
Vj,就是值向量V。
相对位置与注意力权重相结合后的注意力机制公式:
a
i
j
K
=
w
c
l
i
p
(
j
−
i
,
k
)
K
a_{ij}^K = w_{clip(j-i,k)}^K
aijK=wclip(j−i,k)K
a
i
j
V
=
w
c
l
i
p
(
j
−
i
,
k
)
V
a_{ij}^V = w_{clip(j-i,k)}^V
aijV=wclip(j−i,k)V
c
l
i
p
(
x
,
k
)
=
m
a
x
(
−
k
,
m
i
n
(
k
,
x
)
)
clip(x,k) = max(-k,min(k,x))
clip(x,k)=max(−k,min(k,x))
1)
a
i
j
K
a_{ij}^K
aijK在位置 i 和 j 之间,键(Key)的注意力权重由相对位置差 j-i 决定,但该差值会被截断(clip)到范围 [-k, k]。
w
K
w^K
wK 是一个可学习的参数,根据截断后的差值索引对应的权重。
2)
a
i
j
V
a_{ij}^V
aijV在位置 i 和 j 之间,值(Value)的注意力权重由相对位置差 j-i 决定,但该差值会被截断(clip)到范围 [-k, k]。
w
V
w^V
wV 是一个可学习的参数,根据截断后的差值索引对应的权重。
3)clip将任意实数 x 限制在区间 [-k, k] 内。长距离的词汇关联可能较弱,截断到 [-k, k] 可以减少参数量,只需学习 2k+1 种位置编码(从 -k 到 k),而非所有可能的位置差,还能增强泛化,避免模型对极端位置差过拟合。
4)键(Key)和值(Value)在注意力机制中功能不同(Key 用于计算注意力权重,Value 用于生成输出),因此允许它们使用独立的相对位置编码参数
w
K
w^K
wK 和
w
V
w^V
wV。
通过截断的相对位置差,为注意力机制中的键和值引入了轻量化的位置感知能力,平衡了长距离依赖建模与计算效率。
e i j = x i W Q ( x j W K + a i j K ) T d z = x i W Q ( x j W K ) T + x i W Q ( a i j K ) T d z e_{ij} = \frac{x_iW^Q(x_jW^K + a_{ij}^K)^T}{\sqrt{d_z}} = \frac{x_iW^Q(x_jW^K)^T + x_iW^Q(a_{ij}^K)^T}{\sqrt{d_z}} eij=dzxiWQ(xjWK+aijK)T=dzxiWQ(xjWK)T+xiWQ(aijK)T
1)
Q
=
x
W
Q
,
K
=
x
W
K
,
V
=
x
W
V
Q = xW^Q, K = xW^K, V = xW^V
Q=xWQ,K=xWK,V=xWV三者分别是输入x通过不同权重矩阵变换得到的查询、键、值矩阵,是对应向量的投影。
2)
a
i
j
K
a_{ij}^K
aijK在位置 i 和 j 之间,键(Key)的注意力权重由相对位置差 j-i 决定,但该差值会被截断(clip)到范围 [-k, k]。
w
K
w^K
wK 是一个可学习的参数,根据截断后的差值索引对应的权重,用于在键向量中引入相对位置信息。
z i = ∑ j = 1 n α i j ( x j W V + a i j V ) z_i = \sum_{j=1}^n \alpha_{ij}(x_jW^V + a_{ij}^V) zi=j=1∑nαij(xjWV+aijV)
1)
α
i
j
=
s
o
f
t
m
a
x
(
e
i
j
)
\alpha_{ij} = softmax(e_{ij})
αij=softmax(eij),对所有的
e
i
j
e_{ij}
eij进行
softmax
\text{softmax}
softmax,就会得到注意力权重矩阵
α
i
j
\alpha_{ij}
αij,softmax 输出就是
α
i
j
\alpha_{ij}
αij,由查询向量Q和键向量K的点积计算得出。
2)
a
i
j
V
a_{ij}^V
aijV在位置 i 和 j 之间,值(Value)的注意力权重由相对位置差 j-i 决定,但该差值会被截断(clip)到范围 [-k, k]。
w
V
w^V
wV 是一个可学习的参数,根据截断后的差值索引对应的权重,用于在值向量中引入相对位置信息。
两者的区别在于:
a
i
j
K
a_{ij}^K
aijK是键(Key)部分的相对位置编码,用于调整注意力得分
e
i
j
e_{ij}
eij,直接影响注意力权重
α
i
j
\alpha_{ij}
αij。
a
i
j
V
a_{ij}^V
aijV则是值(Value)部分的相对位置编码,直接影响聚合后的输出
z
i
z_i
zi。
a
i
j
K
a_{ij}^K
aijK影响“哪些位置需要关注”(注意力权重),
a
i
j
V
a_{ij}^V
aijV影响“如何利用被关注的位置信息”(值向量的调整)。
Transformer-XL
“Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”论文
Transformer-XL提出了片段级循环机制和相对位置编码新机制,其中它将长文本分割为固定长度的片段(segments)后,引入了循环机制,在训练时缓存前一片段的隐藏状态(hidden states),并在处理当前片段时将其作为额外输入。通过这种方式,模型能够跨片段传递信息,理论上可建模的依赖长度随层数线性增长(如层数为N,依赖长度可达N倍片段长度)。突破了固定上下文的限制,显著提升长程依赖建模能力。推理时也无需重复计算历史信息,提升效率。
对于片段级循环机制,这里就不展开了,主要了解Transformer-XL的相对位置编码机制。
Transformer绝对位置编码的注意力得分公式:
Q
=
W
q
(
E
+
U
)
Q = W_q(E + U)
Q=Wq(E+U)
K
=
W
k
(
E
+
U
)
K = W_k(E + U)
K=Wk(E+U)
在原始 Transformer 中,位置信息通过绝对位置编码直接添加到输入词嵌入中,即: E x i + U i E_{x_i} + U_i Exi+Ui,其中 ( E x i ) (E_{x_i}) (Exi) 是词嵌入, ( U i ) (U_i) (Ui) 是位置嵌入。此时注意力得分隐含了绝对位置信息。
A i , j a b s = Q K T = ( W q ( E + U ) ) ( W k ( E + U ) T ) = E x i T W q T W k E x j ⏟ ( a ) + E x i T W q T W k U j ⏟ ( b ) + U i T W q T W k E x j ⏟ ( c ) + U i T W q T W k U j ⏟ ( d ) . A_{i,j}^{abs} = QK^T = (W_q(E + U))(W_k(E + U)^T) = \underbrace{E_{x_i}^TW_q^TW_kE_{x_j}}_{(a)} + \underbrace{E_{x_i}^TW_q^TW_kU_j}_{(b)} + \underbrace{U_i^TW_q^TW_kE_{x_j}}_{(c)} + \underbrace{U_i^TW_q^TW_kU_j}_{(d)}. Ai,jabs=QKT=(Wq(E+U))(Wk(E+U)T)=(a) ExiTWqTWkExj+(b) ExiTWqTWkUj+(c) UiTWqTWkExj+(d) UiTWqTWkUj.
1)
E
x
i
,
E
x
j
E_{x_i}, E_{x_j}
Exi,Exj词嵌入向量(内容嵌入)。
2)
U
i
,
U
j
U_i, U_j
Ui,Uj绝对位置编码向量。
3)
W
q
,
W
k
W_q, W_k
Wq,Wk查询(Query)和键(Key)的权重矩阵。
4)a 内容-内容交互,纯粹的词嵌入之间的相关性,反映两个词本身的内容关联性。
5)b 内容-位置交互,当前词的内容与目标位置编码的交互,捕捉位置对内容的影响。
6)c 位置-内容交互,当前位置编码与目标词内容的交互,类似(b)但方向相反。
7)d 位置-位置交互,位置编码之间的相关性,反映位置本身的相对关系。
Transformer-XL相对位置编码的注意力得分公式:
A i , j r e l = E x i T W q T W k , E E x j ⏟ ( a ) + E x i T W q T W k , R R i − j ⏟ ( b ) + u T W k , E E x j ⏟ ( c ) + v T W k , R R i − j ⏟ ( d ) . A_{i,j}^{rel} = \underbrace{E_{x_i}^TW_q^TW_{k,E}E_{x_j}}_{(a)} + \underbrace{E_{x_i}^TW_q^TW_{k,R}R_{i-j}}_{(b)} + \underbrace{u^TW_{k,E}E_{x_j}}_{(c)} + \underbrace{v^TW_{k,R}R_{i-j}}_{(d)}. Ai,jrel=(a) ExiTWqTWk,EExj+(b) ExiTWqTWk,RRi−j+(c) uTWk,EExj+(d) vTWk,RRi−j.
1)
R
i
−
j
R_{i-j}
Ri−j相对位置编码(如位置差为 (i-j) 的向量)。
2)
W
k
,
E
,
W
k
,
R
W_{k,E}, W_{k,R}
Wk,E,Wk,R键矩阵拆分为内容相关((E))和位置相关(®)的两部分。
3)
u
,
v
u, v
u,v可学习的全局偏置向量。
4)a 内容-内容交互,词嵌入之间的直接相关性,与绝对位置编码的(a)类似。
5)b 内容-相对位置交互,当前词内容与相对位置的交互,捕捉内容如何随相对位置变化。
6)c 全局内容偏置,通过向量 (u) 为目标词内容添加全局偏置,独立于当前位置。
7)d 相对位置偏置,通过向量 (v) 为相对位置添加全局偏置,独立于具体内容。
3.RoPE旋转位置嵌入
“RoFormer: Enhanced Transformer with Rotary Position Embedding论文”
公式推理:
假设有一个长度为N的输入,比如“大模型”,可以将这个输入记作以下序列公式:
S
N
=
{
w
i
}
i
=
1
N
S_N = \lbrace w_i\rbrace _{i=1}^N
SN={wi}i=1N
这段文字序列也不是直接就可以作为输入传入模型的,模型无法直接理解文字这种高维数据。需要使用Embedding将这种离散的、非结构化的数据(如文字、图像、音频等)转换映射为连续的、低维的数值向量(即一组数字),可以根据以上公式表达为:
E
N
=
{
w
i
}
i
=
1
N
E_N = \lbrace w_i\rbrace _{i=1}^N
EN={wi}i=1N
假设
f
f
f是一个位置函数,那么可以对
E
N
E_N
EN表达为:
E
N
=
{
f
(
x
i
,
i
)
}
i
=
1
N
E_N = \lbrace f(x_i,i)\rbrace _{i=1}^N
EN={f(xi,i)}i=1N
根据
E
N
E_N
EN来表达QKV公式:
q
m
=
f
q
(
x
m
,
m
)
q_m = f_q(x_m,m)
qm=fq(xm,m)
k
n
=
f
k
(
x
n
,
n
)
k_n = f_k(x_n,n)
kn=fk(xn,n)
v
n
=
f
v
(
x
n
,
n
)
v_n = f_v(x_n,n)
vn=fv(xn,n)
1)
q
m
q_m
qm表示的是目标位置m上的Q,用于计算与所有源位置n上的KV的相关性,类似你提出的第m个问题。
2)
k
n
,
v
n
k_n,v_n
kn,vn表示源位置n上的KV,用于与目标位置m上的Q计算注意力分数和相关内容,类似答案集中的第n个答案与这第n个答案中的实际内容。
结合上述的标准注意力机制公式转换后的注意力机制公式,可以得到:
a
m
,
n
=
e
x
p
(
q
m
T
k
n
d
)
Σ
j
=
1
N
e
x
p
(
q
m
T
k
j
d
)
a_{m,n} = \frac{exp(\frac{q_m^Tk_n}{\sqrt{d}})}{{\Sigma_{j=1}^N}exp(\frac{q_m^Tk_j}{\sqrt{d}})}
am,n=Σj=1Nexp(dqmTkj)exp(dqmTkn)
o
m
=
Σ
n
=
1
N
a
m
,
n
v
n
o_m = \Sigma_{n=1}^N a_{m,n}v_n
om=Σn=1Nam,nvn
为了包含相对位置信息,假设有一个函数g,用来表示Q q m q_m qmK k n k_n kn的内积,且该函数g只将词嵌入 x m , x n x_m,x_n xm,xn及其相对位置m−n作为输入变量:
q m k n = ⟨ f q ( x m , m ) , f k ( x n , n ) ⟩ = g ( x m , x n , m − n ) q_mk_n = \left\langle f_q(x_m,m),f_k(x_n,n) \right\rangle = g(x_m,x_n,m-n) qmkn=⟨fq(xm,m),fk(xn,n)⟩=g(xm,xn,m−n)
Attention公式中的QKV可以表达为输入的x与W矩阵的映射值:
Q = x W q , K = x W k , V = x W v Q = xW_q, K = xW_k, V = xW_v Q=xWq,K=xWk,V=xWv
根据以上内容实现查询Q和键K的旋转函数:
f
q
(
x
m
,
m
)
=
(
W
q
x
m
)
e
i
m
θ
f_q(x_m,m) = (W_qx_m)e^{im\theta}
fq(xm,m)=(Wqxm)eimθ
f
k
(
x
n
,
n
)
=
(
W
k
x
n
)
e
i
n
θ
f_k(x_n,n) = (W_kx_n)e^{in\theta}
fk(xn,n)=(Wkxn)einθ
g
(
x
m
,
x
n
,
m
−
n
)
=
R
e
[
(
W
q
x
m
)
(
W
k
x
n
)
∗
e
i
(
m
−
n
)
θ
]
=
R
e
[
q
m
k
n
∗
e
i
(
m
−
n
)
θ
]
g(x_m,x_n,m-n) = Re[(W_qx_m)(W_kx_n)^*e^{i(m-n)\theta}] = Re[q_mk_n^*e^{i(m-n)\theta}]
g(xm,xn,m−n)=Re[(Wqxm)(Wkxn)∗ei(m−n)θ]=Re[qmkn∗ei(m−n)θ]
1)
x
m
,
x
n
x_m,xn
xm,xn表示序列中位置m和n的向量
2)
m
,
n
m,n
m,n表示绝对位置索引。
3)
θ
\theta
θ表示预设的非零常数,表示角度参数,用于控制旋转频率,与维度相关。
4)
e
i
m
θ
,
e
i
n
θ
e^{im\theta},e^{in\theta}
eimθ,einθ复数域旋转,将绝对位置信息编码到QK中。
5)旋转操作保证向量模长不变,仅改变方向。
6)Re表示内积转换为复数乘法,然后只取实部。
7)注意力分数仅依赖相对位置差m-n,而不是绝对位置m或n。
8)
e
i
(
m
−
n
)
θ
e^{i(m-n)\theta}
ei(m−n)θ编码相对位置关系。
9)
(
W
k
x
n
)
∗
(W_kx_n)^*
(Wkxn)∗是
(
W
k
x
n
)
(W_kx_n)
(Wkxn)的共轭复数
结合共轭复数公式:
z = a + b i , z ∗ = a − b i z = a + bi, z^* = a - bi z=a+bi,z∗=a−bi
q m = q m 1 + i q m 2 , k n ∗ = k n 1 − i k n 2 q_m = q_m^1 + i q_m^2, k_n^* = k_n^1 - i k_n^2 qm=qm1+iqm2,kn∗=kn1−ikn2
结合傅里叶变换中的欧拉公式:
e
i
θ
=
c
o
s
θ
+
i
∗
s
i
n
θ
e^{i\theta} = cos\theta + i*sin\theta
eiθ=cosθ+i∗sinθ
e i ( m − n ) θ = c o s ( ( m − n ) θ ) + i s i n ( ( m − n ) θ ) e^{i(m-n)\theta} = cos((m-n)\theta) + isin((m-n)\theta) ei(m−n)θ=cos((m−n)θ)+isin((m−n)θ)
结合以上公式,整理可得:
g
(
x
m
,
x
n
,
m
−
n
)
=
R
e
[
(
q
m
1
+
i
q
m
2
)
(
k
n
1
−
i
k
n
2
)
(
c
o
s
(
(
m
−
n
)
θ
)
+
i
s
i
n
(
(
m
−
n
)
θ
)
)
]
g(x_m,x_n,m-n) = Re[(q_m^1 + i q_m^2)(k_n^1 - i k_n^2)(cos((m-n)\theta) + isin((m-n)\theta))]
g(xm,xn,m−n)=Re[(qm1+iqm2)(kn1−ikn2)(cos((m−n)θ)+isin((m−n)θ))]
展开计算公式,然后根据Re只取实部的特点(去除带有i的公式),可整理得到以下公式:
g
(
x
m
,
x
n
,
m
−
n
)
=
(
q
m
1
k
n
1
+
q
m
2
k
n
2
)
c
o
s
(
(
m
−
n
)
θ
)
−
(
q
m
2
k
n
1
−
q
m
1
k
n
2
)
s
i
n
(
(
m
−
n
)
θ
)
g(x_m,x_n,m-n) = (q_m^1k_n^1 + q_m^2k_n^2)cos((m-n)\theta) - (q_m^2k_n^1 - q_m^1k_n^2)sin((m-n)\theta)
g(xm,xn,m−n)=(qm1kn1+qm2kn2)cos((m−n)θ)−(qm2kn1−qm1kn2)sin((m−n)θ)
经过转换可得:
g
(
x
m
,
x
n
,
m
−
n
)
=
(
q
m
1
q
m
2
)
(
c
o
s
(
(
m
−
n
)
θ
)
−
s
i
n
(
(
m
−
n
)
θ
)
s
i
n
(
(
m
−
n
)
θ
)
c
o
s
(
(
m
−
n
)
θ
)
)
(
k
n
1
k
n
2
)
g(x_m,x_n,m-n) = (q_m^1q_m^2)\begin{pmatrix} cos((m-n)\theta) & -sin((m-n)\theta) \\ sin((m-n)\theta) & cos((m-n)\theta) \\ \end{pmatrix} \begin{pmatrix} k_n^1 \\ k_n^2 \\ \end{pmatrix}
g(xm,xn,m−n)=(qm1qm2)(cos((m−n)θ)sin((m−n)θ)−sin((m−n)θ)cos((m−n)θ))(kn1kn2)
f q ( x m , m ) = ( c o s ( m θ ) − s i n ( m θ ) s i n ( m θ ) c o s ( m θ ) ) ( q m 1 q m 2 ) f_q(x_m,m) = \begin{pmatrix} cos(m\theta) & -sin(m\theta) \\ sin(m\theta) & cos(m\theta) \\ \end{pmatrix} \begin{pmatrix} q_m^1 \\ q_m^2 \\ \end{pmatrix} fq(xm,m)=(cos(mθ)sin(mθ)−sin(mθ)cos(mθ))(qm1qm2)
f k ( x n , n ) = ( q m 1 q m 2 ) ( c o s ( n θ ) − s i n ( n θ ) s i n ( n θ ) c o s ( n θ ) ) ( k n 1 k n 2 ) f_k(x_n,n) = (q_m^1q_m^2)\begin{pmatrix} cos(n\theta) & -sin(n\theta) \\ sin(n\theta) & cos(n\theta) \\ \end{pmatrix} \begin{pmatrix} k_n^1 \\ k_n^2 \\ \end{pmatrix} fk(xn,n)=(qm1qm2)(cos(nθ)sin(nθ)−sin(nθ)cos(nθ))(kn1kn2)
将RoPE应用于自我注意,可得:
q
m
T
k
n
=
(
R
Θ
,
m
d
W
q
x
m
)
T
(
R
Θ
,
n
d
W
k
x
n
)
=
x
T
W
q
R
Θ
,
(
n
−
m
)
d
W
k
x
n
q_m^Tk_n = (R_{\Theta,m}^dW_qx_m)^T(R_{\Theta,n}^dW_kx_n) = x^TW_qR_{\Theta,(n-m)}^dW_kx_n
qmTkn=(RΘ,mdWqxm)T(RΘ,ndWkxn)=xTWqRΘ,(n−m)dWkxn
1)
R
Θ
,
(
n
−
m
)
d
W
k
x
n
=
(
R
Θ
,
m
d
)
T
R
Θ
,
n
d
R_{\Theta,(n-m)}^dW_kx_n = (R_{\Theta,m}^d)^TR_{\Theta,n}^d
RΘ,(n−m)dWkxn=(RΘ,md)TRΘ,nd
2)
R
Θ
d
R_\Theta^d
RΘd表示一个正交矩阵,用于保证编码位置信息过程中的稳定性,但是具有稀疏性。
注意力公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V = Σ n = 1 N e x p ( q m T k n d ) v n Σ n = 1 N e x p ( q m T k j d ) \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d_k}} \right)V = \frac{{\Sigma_{n=1}^N}exp(\frac{q_m^Tk_n}{\sqrt{d}})v_n}{{\Sigma_{n=1}^N}exp(\frac{q_m^Tk_j}{\sqrt{d}})} Attention(Q,K,V)=softmax(dkQKT)V=Σn=1Nexp(dqmTkj)Σn=1Nexp(dqmTkn)vn
ϕ ( q m ) = e x p ( q m d ) , φ ( k n ) = e x p ( k n d ) \phi(q_m) = exp(\frac{q_m}{\sqrt{d}}),\varphi(k_n) = exp(\frac{k_n}{\sqrt{d}}) ϕ(qm)=exp(dqm),φ(kn)=exp(dkn)
结合以上正交矩阵公式,可得:
Attention ( Q , K , V ) m = ∑ n = 1 m ( R Θ , m d ϕ ( q m ) ) T ( R Θ , n d φ ( k n ) ) v n ∑ n = 1 N ϕ ( q m ) T φ ( k n ) \text{Attention}(Q, K, V)_m = \frac{\sum_{n=1}^m(R_{\Theta,m}^d\phi(q_m))^T(R_{\Theta,n}^d\varphi(k_n))v_n}{\sum_{n=1}^N \phi(q_m)^T\varphi(k_n)} Attention(Q,K,V)m=∑n=1Nϕ(qm)Tφ(kn)∑n=1m(RΘ,mdϕ(qm))T(RΘ,ndφ(kn))vn
从二维扩展到多维:
( c o s ( m θ 0 ) − s i n ( m θ 0 ) 0 0 . . . 0 0 s i n ( m θ 0 ) c o s ( m θ 0 ) 0 0 . . . 0 0 0 0 c o s ( m θ 1 ) − s i n ( m θ 1 ) . . . 0 0 0 0 s i n ( m θ 1 ) c o s ( m θ 1 ) . . . 0 0 ⋮ ⋮ ⋮ ⋮ ⋱ ⋮ ⋮ 0 0 . . . 0 0 c o s ( m θ d − 1 ) − s i n ( m θ d − 1 ) 0 0 . . . 0 0 s i n ( m θ d − 1 ) c o s ( m θ d − 1 ) ) ( q 0 q 1 ⋮ ⋮ ⋮ q d − 1 ) \begin{pmatrix} cos(m\theta_0) & -sin(m\theta_0) & 0 & 0 & ... & 0 & 0 \\ sin(m\theta_0) & cos(m\theta_0) & 0 & 0 & ... & 0 & 0 \\ 0 & 0 & cos(m\theta_1) & -sin(m\theta_1) & ... & 0 & 0 \\ 0 & 0 & sin(m\theta_1) & cos(m\theta_1) & ... & 0 & 0 \\ \vdots & \vdots & \vdots & \vdots & \ddots & \vdots & \vdots \\ 0 & 0 & ... & 0 & 0 & cos(m\theta_{d-1}) & -sin(m\theta_{d-1}) \\ 0 & 0 & ... & 0 & 0 & sin(m\theta_{d-1}) & cos(m\theta_{d-1}) \\ \end{pmatrix} \begin{pmatrix} q_0 \\ q_1 \\ \vdots \\ \vdots \\ \vdots \\ q_{d-1} \end{pmatrix} cos(mθ0)sin(mθ0)00⋮00−sin(mθ0)cos(mθ0)00⋮0000cos(mθ1)sin(mθ1)⋮......00−sin(mθ1)cos(mθ1)⋮00............⋱000000⋮cos(mθd−1)sin(mθd−1)0000⋮−sin(mθd−1)cos(mθd−1) q0q1⋮⋮⋮qd−1
实现计算高效旋转矩阵乘法:
R Θ , m d x = ( x 1 x 2 x 3 x 4 ⋮ x d − 1 x d ) ⨂ ( c o s m θ 1 c o s m θ 1 c o s m θ 2 c o s m θ 2 ⋮ c o s m θ d / 2 c o s m θ d / 2 ) + ( − x 2 x 1 − x 4 x 3 ⋮ − x d x d − 1 ) ⨂ ( s i n m θ 1 s i n m θ 1 s i n m θ 2 s i n m θ 2 ⋮ s i n m θ d / 2 s i n m θ d / 2 ) R_{\Theta,m}^dx = \begin{pmatrix} x_1 \\ x_2 \\ x_3 \\ x_4 \\ \vdots \\ x_{d-1} \\ x_d \end{pmatrix} \bigotimes \begin{pmatrix} cos \text{ } m\theta_1 \\ cos \text{ } m\theta_1 \\ cos \text{ } m\theta_2 \\ cos \text{ } m\theta_2 \\ \vdots \\ cos \text{ } m\theta_{d/2} \\ cos \text{ } m\theta_{d/2} \end{pmatrix} + \begin{pmatrix} -x_2 \\ x_1 \\ -x_4 \\ x_3 \\ \vdots \\ -x_d \\ x_{d-1} \end{pmatrix} \bigotimes \begin{pmatrix} sin \text{ } m\theta_1 \\ sin \text{ } m\theta_1 \\ sin \text{ } m\theta_2 \\ sin \text{ } m\theta_2 \\ \vdots \\ sin \text{ } m\theta_{d/2} \\ sin \text{ } m\theta_{d/2} \end{pmatrix} RΘ,mdx= x1x2x3x4⋮xd−1xd ⨂ cos mθ1cos mθ1cos mθ2cos mθ2⋮cos mθd/2cos mθd/2 + −x2x1−x4x3⋮−xdxd−1 ⨂ sin mθ1sin mθ1sin mθ2sin mθ2⋮sin mθd/2sin mθd/2
6、Attention注意力机制
“GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”论文
1.多头注意力Multi-Head Attention(MHA)
特点:
高质量:每个 Query 都有专属的 Key 和 Value,用多个头同时去关注不同的内容。
计算量大,速度慢:因为每个 Query 都要单独计算。
类比:
想象你在图书馆做研究,所有学生(Query)都有各自的私人导师(Key 和 Value),导师会针对学生的需求去解答问题:
好处:每个学生得到的帮助都非常精准。
坏处:需要很多导师,每个导师只能关注一个学生,效率低下,图书馆的成本非常高。
总结: 多头注意力模型提供高质量的输出,但代价是计算速度慢。
2.多查询注意力Multi-Query Attention(MQA)
特点:
速度快:所有 Query 共用同一组 Key 和 Value,计算量最小。
质量下降:因为不同 Query 使用相同的 Key 和 Value,不能很好地区分个体需求。
类比:
想象同样的图书馆,所有学生(Query)只能共享一个导师(Key 和 Value):
好处:节省资源,每个人得到答案的速度非常快。
坏处:导师无法根据每个学生的需求单独解答,回答内容会非常通用,可能不够准确。
总结: 这种方法牺牲了质量来换取速度。
3.分组多查询注意力Grouped Multi-Query Attention(GQA)
特点:
折中方案:将 Query 分成若干组,每组共享一组 Key 和 Value。
质量与速度平衡:比 Multi-Query 更灵活,比 Multi-Head 更高效。
类比:
回到图书馆,这次把学生分成小组(Grouped Query),每组有一个导师(共享 Key 和 Value):
好处:同组的学生有类似需求,导师能给出更准确的答案,同时减少了需要的导师数量,效率提高了。
坏处:如果组内的需求差异较大,答案可能仍然不够精准。
总结: 分组注意力机制在计算效率和结果质量之间找到了一个平衡点,设置的组一定要能够被注意力头数整除。
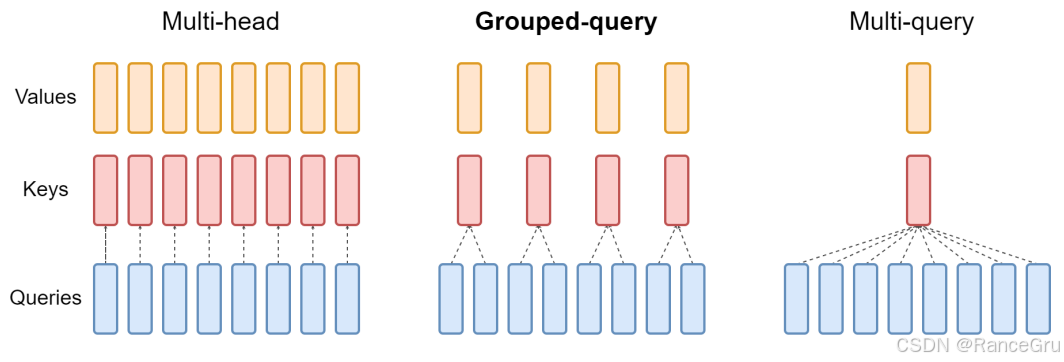
Multi-Head Attention:精准但慢(贵)。
Multi-Query Attention:快但质量差(便宜)。
Grouped Multi-Query Attention:速度快、质量也能接受(性价比高)。
四、总结
一方面Meta-Llama-3.2-1B太小,很多回答都是胡言乱语,另一方面对模型的调用只依靠了一个Hugging Face的Transformers库,实际的使用体验相当不好,想要更好的体验可能需要在更工程化的框架下去调用模型,比如ollama等。
这篇博客记录于2024年,Meta-Llama-3.2发布不久,看见有1B的模型就心血来潮测试了一下,测试完后因为工作忙碌就忘记发布了,直到24年年末的deepseekV3以及今年过年时的R1如此出圈爆火,打算年后回来测试一下,才发现这篇博客被遗忘了。
后续有时间会继续更新学习有关llama的模型结构。

















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









