






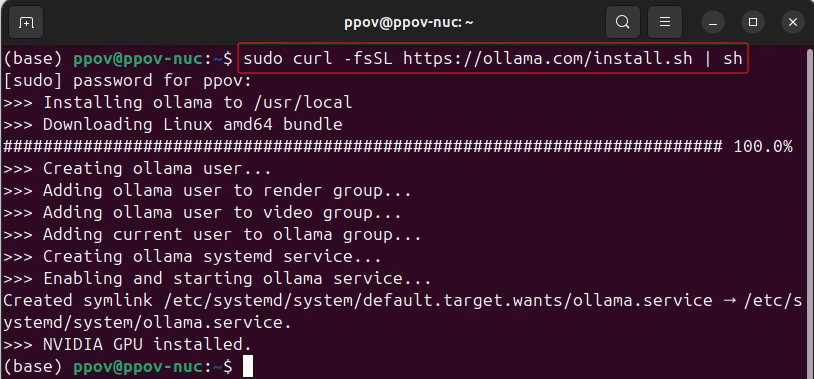
Ollama 是一个开源的大语言模型服务工具,它的核心目的是简化大语言模型(LLMs)的本地部署和运行过程,请参考《Gemma 2+Ollama在算力魔方上帮你在LeetCode解题》,一条命令完成Ollama的安装。
一,Llama3.2 Vision简介
Llama 3.2 Vision是一个多模态大型语言模型(LLMs)的集合,它包括预训练和指令调整的图像推理生成模型,有两种参数规模:11B(110亿参数)和90B(900亿参数)。
Llama 3.2 Vision在视觉识别、图像推理、字幕以及回答有关图像的通用问题方面进行了优化,在常见的行业基准上优于许多可用的开源和封闭多模式模型。

二,在算力魔方4060版上完成部署
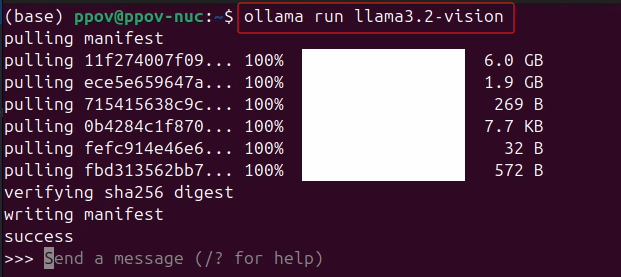
算力魔方4060版是一款包含4060 8G显卡的迷你主机,运行:
ollama run llama3.2-vision完成Llama 3.2 Vision 11B模型下载和部署。
三,Llama 3.2实现图片识别
将图片输入Llama3.2-Vision,然后直接输入问题,即可获得图片信息,如下面视频所示:
PX22_GPU
四,总结
在算力魔方上4060版上,用Ollama轻松搞定Llama 3.2 Vision模型本地部署。
更多精彩请持续关注!

















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









