






CPFNet_Context Pyramid Fusion Network for Medical Image Segmentation-2020
摘要
医学图像的精确自动分割是临床诊断和分析的关键步骤。基于U型结构的卷积神经网络(CNN)方法在许多不同的医学图像分割任务中取得了显着的性能。但是,这种结构存在类别不平衡、边界模糊等问题,使得单级上下文信息提取能力不足。本文提出了一种上下文金字塔融合网络(CPFNet),该网络将两个金字塔模块相结合,融合全局/多尺度上下文信息,在U型结构的基础上,在编码器和解码器之间设计了多个全局金字塔引导模块(GPG),旨在通过重构跳跃连接为解码器提供不同层次的全局上下文信息。我们进一步设计了一个scaleaware金字塔融合(SAPF)模块,动态融合多尺度上下文信息的高层次功能。这两个金字塔模块可以逐步开发和融合丰富的上下文信息。实验结果表明,该方法在皮肤病变分割、视网膜线性病变分割、胸部危险器官多类分割和视网膜水肿病变多类分割等四个具有挑战性的任务上都具有很强的竞争力.
这种结构存在类别不平衡、边界模糊等问题,使得单级上下文信息提取能力不足。
引言
医学图像的语义分割在医学图像分析中起着重要作用,例如皮肤镜图像中的皮肤病变分割[1]、[2],吲哚菁绿色血管造影(ICGA)图像中的视网膜线性病变分割[3],计算机断层扫描(CT)图像中的胸部危险器官分割[4],和光学相干断层扫描(OCT)图像中的视网膜水肿病变分割[5],[6]。准确和自动的目标分割可用于获得病理学或生物标志物的定量评估,用于后续诊断、治疗计划和疾病进展监测。
最近,许多基于卷积神经网络(CNN)的深度学习方法已被应用于医学图像分割任务,因为它们具有出色的特征提取能力[7]-[10]。
在由堆叠的卷积层和下采样层组成的CNN框架中,较深的阶段通常具有更宽的感受野范围,并且能够捕获全局上下文信息,而较浅的阶段通常具有具有更高空间分辨率特征的局部信息。在此基础上,提出了许多基于全卷积网络(FCN)的新结构用于语义分割任务[7],[11]-[13]。其中,U-Net [7]取得了令人瞩目的业绩。在以U-Net为代表的编码器-解码器结构中,采用原始的FCN作为编码器,通过堆叠卷积层和下采样层来逐渐捕获高级语义信息。设计了一个自下而上的解码器,从编码器的输出中逐级恢复空间信息。同时,在解码器和编码器之间采用多跳连接,弥补了下采样带来的精细信息损失,显著提高了性能
虽然具有U形结构的CNN在许多医学图像分割应用中取得了显着的性能并受到了很多关注[10],[14]-[16]对于每个单阶段,上下文信息提取的能力仍然不足
首先,一方面,由编码器的较深阶段捕获的全局上下文信息被逐渐传输到较浅的层,由于单个阶段的特征提取能力较弱,因此其可能被逐渐稀释。另一方面,在每个阶段中的简单的跳跃连接忽略全局信息,是一个不加选择地组合的局部信息,将引入不相关的杂波,并导致误分类的像素。最近,已经提出了一些方法来尝试解决这些问题。FastFCN [17]使用联合金字塔上采样模块来替换膨胀卷积并捕获全局上下文信息。Anatomynet [18]和DFN [19]采用通道注意机制来引导浅层学习全局特征表示。GCN [20]和MultiResUNet [2]在skip-connection中分别添加了更大的内核和更深的卷积层,将局部语义信息转换为更高级别的特征。Attention U-Net [21]利用一种新颖的注意力门(AG)模块来突出对特定任务有用的显著特征。然而,很少有方法可以同时解决这两个问题。
第二,在每个单阶段中,没有有效地提取和利用多尺度上下文信息。当处理具有复杂结构的目标时,这些信息是必要的,以便也考虑结构的周围环境,并避免模糊的决策[22]。近年来,人们提出了一些探索和整合多尺度上下文信息的方法。PSPNet [23]和PoolNet [24]采用了具有不同内核大小的多个并行池来处理高级特征映射。DeepLab v3 [25]和CE-Net [26]采用了具有不同感受野的多个卷积分支,以提高模型的多尺度信息捕获能力。然而,在他们的方法中,感受野不能动态调整以适应不同大小的目标。由于注意力机制[19]、[27]被广泛用于提高模型性能,许多基于注意力机制的尺度感知网络被提出来克服上述问题。SA[28]通过将注意力模块引入多尺度输入,学会了对每个像素的多尺度特征进行软加权。AFNet [22]和SPAP [29]采用尺度感知层来自适应地改变有效感受野的大小。SKNet [30]提出了一种动态核选择机制,将通道注意力机制应用于多个特征分支。
许多基于注意力机制的尺度感知网络---怎么说呢,也做了类似的设计,可能是由于让注意力去选择的特征太少
(有点通道注意力的意思),然后结果不是很理想
在本文中,我们引入两个新的金字塔模块到U形网络来解决上述问题。基于对第一个问题的讨论,本文设计了全局金字塔引导(GPG)模块,该模块结合多级全局上下文信息重构跳过连接,为解码器提供全局信息引导流程。具体地,每个阶段的跳过连接由来自该阶段的局部上下文信息和来自更高级别阶段的全局上下文信息组成。同时,通过引入GPG,可以抑制低层特征带来的无关背景噪声。受第二个问题和scaleaware机制的讨论的启发,我们进一步提出了一个Scale-Aware Pyramid Fusion(SAPF)模块,该模块由三个具有共享权重的并行扩张卷积滤波器和两个级联的Scale-Aware Modules(SAM)组成,用于捕获不同的尺度上下文信息。SAPF模块嵌入在主干的顶部,通过自学习,为不同尺度的目标动态选择合适的感受野,更好地融合多尺度背景信息。
[这点到底是怎么做到的???什么叫动态选择合适的感受野???]
方法
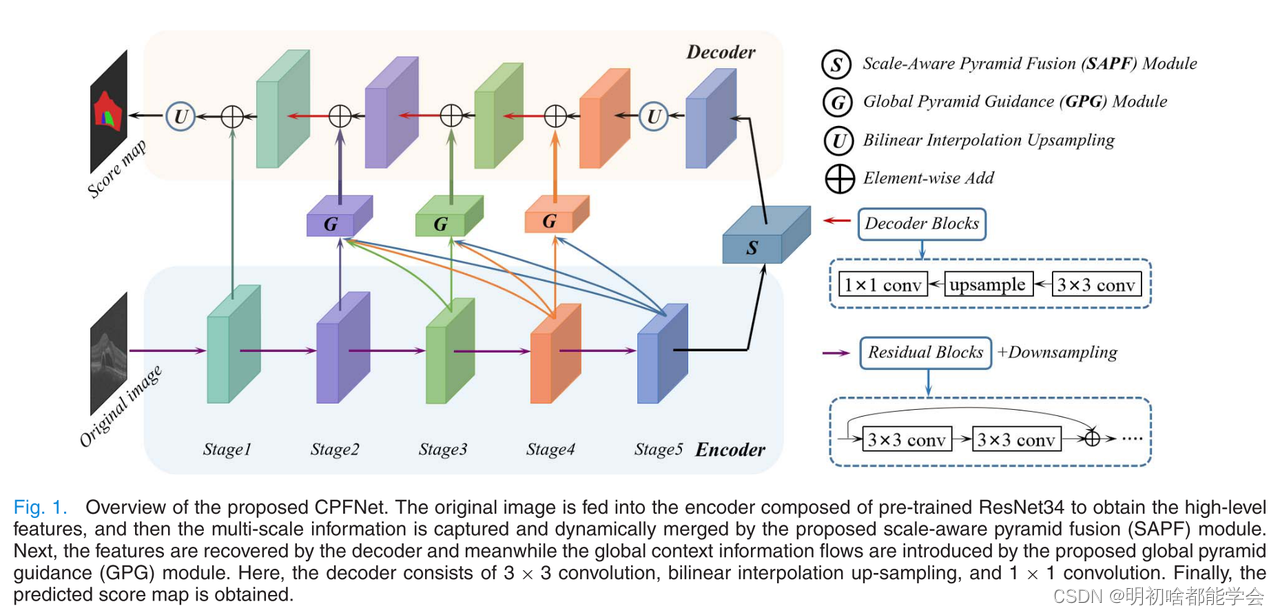
图注:拟议的森林合作伙伴关系网概览。原始图像被送入由预训练的ResNet34组成的编码器以获得高级特征,
然后通过所提出的尺度感知金字塔融合(SAPF)模块捕获多尺度信息并动态融合。接着,解码器恢复特征,
同时全局金字塔引导(GPG)模块引入全局上下文信息流。这里,解码器由3 × 3卷积、双线性插值上采样和
1 × 1卷积组成。最后,得到预测得分图。
概述
图1展示了所提出的CPFNet,这是一个基于编码器-解码器架构的FCN,由四个主要部分组成:特征编码器,GPG模块,SAPF模块和特征解码器。SAPF模块被插入在编码器的顶部以捕获多尺度上下文信息,而多个GPG模块被放置在编码器和解码器之间以引导全局上下文信息流和解码器路径特征的融合。
FeatureEncoder—特征编码器:
为了获得更具代表性的特征图,我们采用了预先训练的ResNet34 [31]作为特征提取器。出于兼容性目的,删除了平均池化层和全连接层。由于残差块具有快捷机制,如图1右下角所示,ResNet可以加速网络的收敛并避免梯度消失。
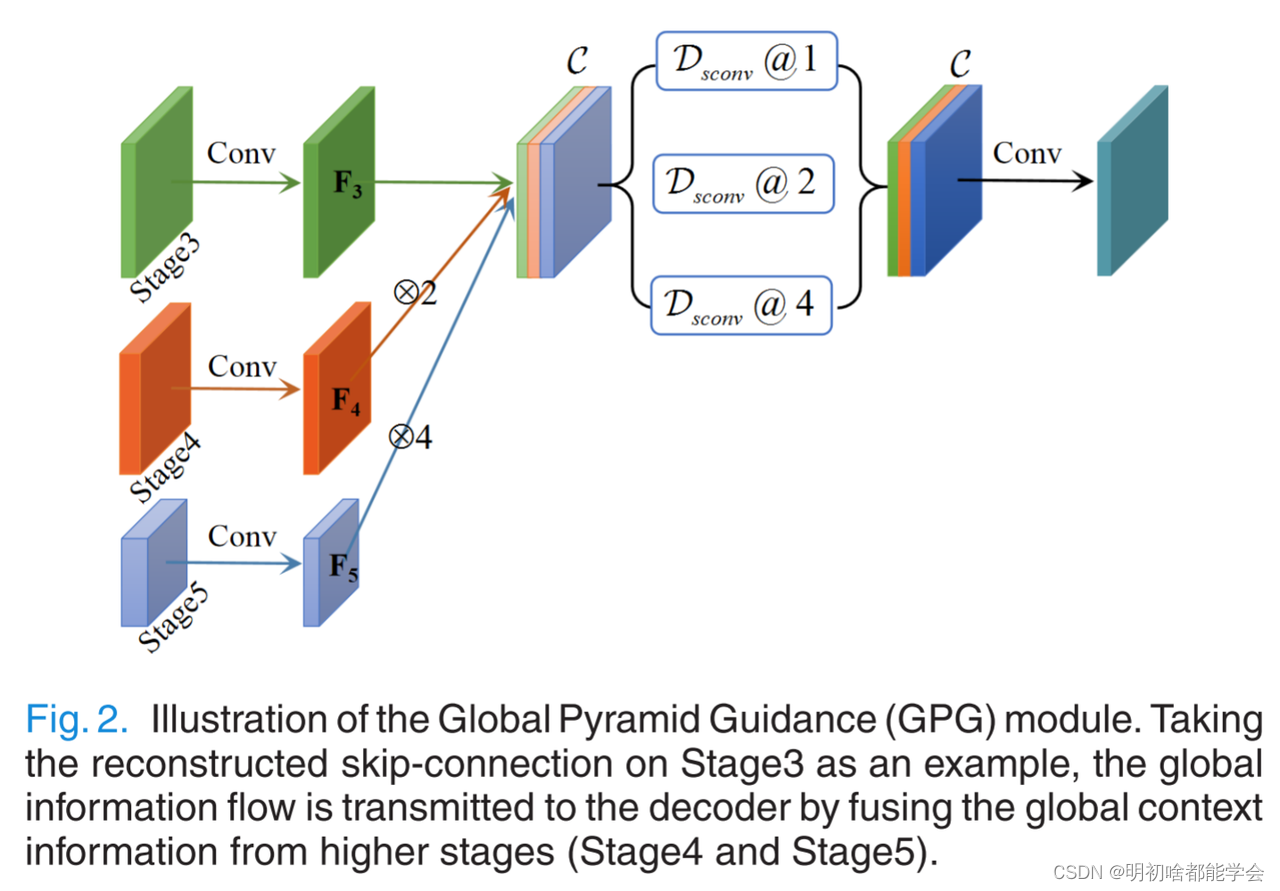
图注:GlobalPyramidGuidance(GPG)模块的图示。以在阶段3上重建的跳过连接为例,通过融合来自更高阶段(阶段4和阶段5)的全局上下文信息来将全局信息流传输到解码器。
C. Global Pyramid Guidance Module—全局金字塔引导模块
从输入图像中,编码器可以学习全局上下文信息,包括对象的周围环境和对象的类别特征[26],[32]。然而,当这些类型的信息逐渐传输到较浅的层时,它们可能会逐渐减弱[24]。此外,U型网络中原有的跳跃连接会引入不相关的杂波,并由于感受野的不匹配而产生语义空缺。在本文中,我们提出了一个全球金字塔制导(GPG)模块来解决这些问题,如图2所示。
在GPG模块中,通过将该阶段的特征图与所有更高级别阶段的特征图相结合来重建跳过连接。例如,图2示出了阶段3上的GPG模块。首先,通过常规的3 × 3卷积将所有阶段的特征映射到与阶段3相同的通道空间中。接下来,将所生成的特征图F4和F5上采样到与F3相同的大小并连接。然后,为了从不同级别的特征映射中提取全局上下文信息,并行采用具有不同膨胀率(1,2和4)的三个可分离卷积[33](Dsconv@1,Dsconv@2,Dsconv@4),其中可分离卷积用于减少模型参数。值得注意的是,平行路径的数量和膨胀率随着融合阶段的数量而变化。最后,采用标准卷积来获得最终的特征图。最重要的是,不同阶段的每个GPG模块可以总结为(为了简化公式,忽略正则卷积):
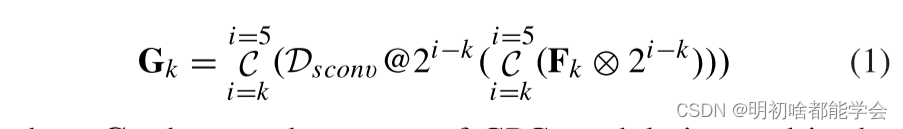


其中,Gk表示插入第k级的GPG模块的输出,Fk表示编码器中第k级的特征图,R2 i-k表示速率为2 i-k的上采样操作,C表示级联操作,Dsconv @ 2 i-k表示膨胀速率为2 i-k的可分离膨胀卷积。
为了降低计算成本,在我们的网络中只使用了三个GPG模块。通过在编码器和解码器之间引入多个GPG模块,可以将来自高级阶段的全局语义信息流逐步引导到不同的阶段。
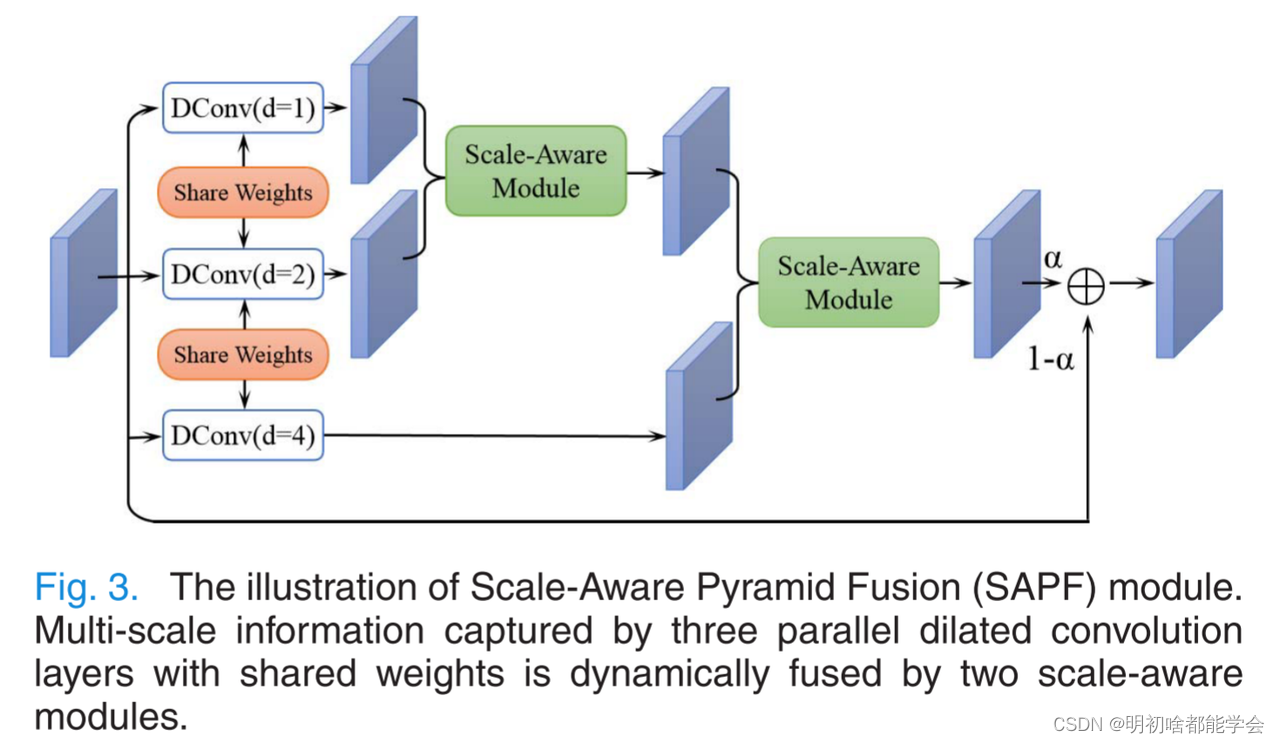
图注:Scale-Aware Pyramid Fusion(SAPF)模块。由三个具有共享权重的并行扩张卷积层捕获的多尺度信息由两个尺度感知模块动态融合。
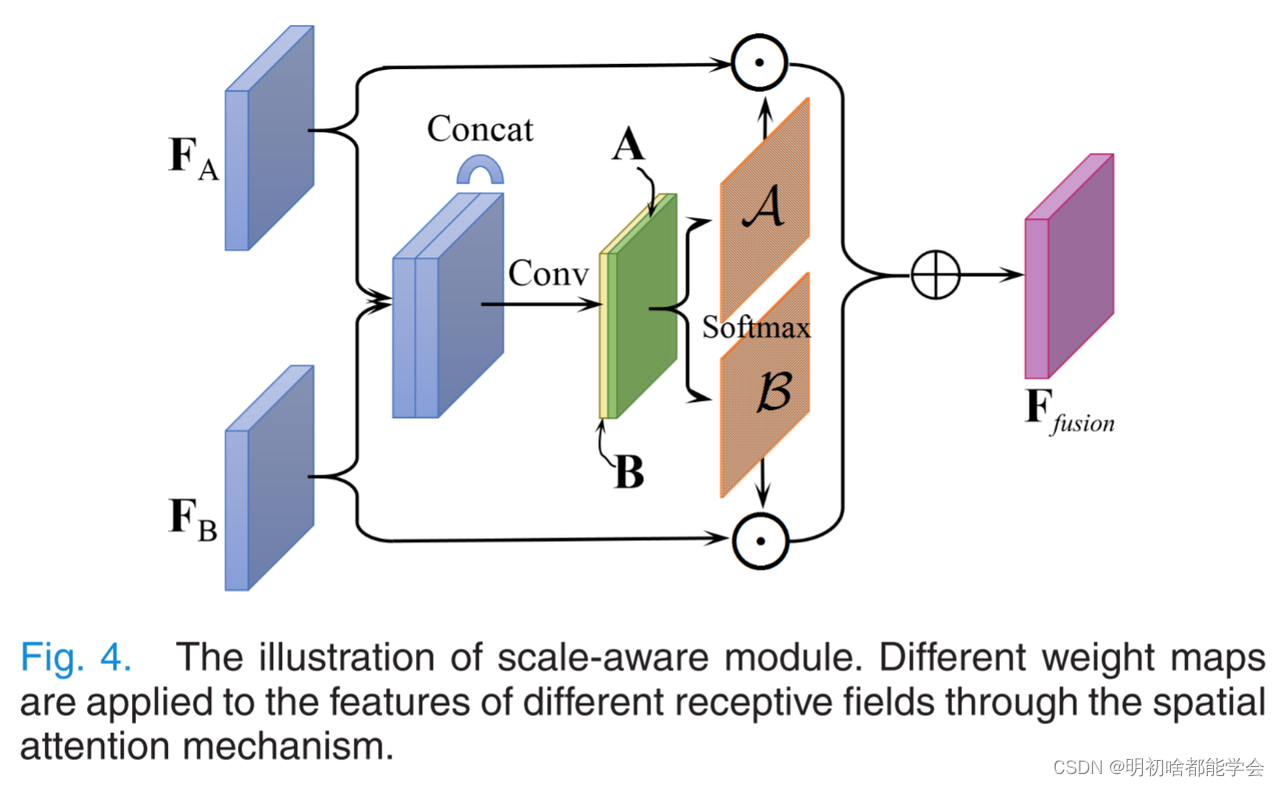
尺度感知模块的说明。通过空间注意机制,对不同感受野的特征应用不同的权重图。
D. Scale-AwarePyramidFusion Module----D.尺度感知金字塔融合模块
正如在引言中所讨论的,多尺度上下文信息可以提高语义分割任务的性能。然而,如何有效地整合这些信息是一个值得探讨的问题。受此问题的启发,我们提出了一个Scale-Aware Pyramid Fusion(SAPF)模块,如图3所示。在SAPF模块中,我们使用三个并行的膨胀卷积,分别具有不同的膨胀率1,2和4,以捕获不同的尺度信息。请注意,这些不同的扩张卷积具有共享的权重,这可以减少模型参数的数量和过拟合的风险
在此基础上,设计了尺度感知模块,实现了尺度特征的融合。如图4所示,引入空间注意机制以动态地选择适当的尺度特征并通过自学习将它们融合。具体地说,两个不同尺度的特征FA和FB经过一系列卷积,得到两个特征图A,B ∈ RH×W(H:特征图的高度,W:特征图的宽度)。然后通过softmax算子在空间方向值上生成像素方向注意力图A、B ∈ RH×W:

最后,融合特征图被获得为加权和:
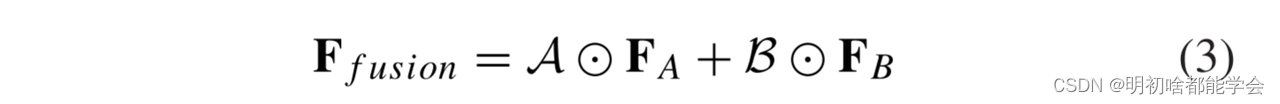
其中,逐元素乘积运算()之间的注意力图和两个尺度特征进行融合,得到融合的特征图F融合。
我们使用两个级联的尺度感知模块来获得三个分支的最终融合特征。然后,利用带有可学习参数α的残差连接来获得整个SAPF模块的输出。
E. FeatureDecoder—E.解码器
为了快速高效地恢复高分辨率特征图,解码器路径中使用了多个简单的解码器块。解码器利用SAPF模块生成的高级特征恢复空间信息,并通过3 × 3卷积逐步融合GPG模块引导的全局上下文信息,如图1所示。在3 × 3卷积之后,使用双线性插值对融合特征图进行上采样,这可以减少模型的参数和棋盘伪影[34]。解码器块的输出在1×1卷积之后获得。注意,在最后一个解码器块之后,特征图被直接上采样到与原始输入图像相同的大小。
F. LossFunction
医学图像分割中的一个主要挑战是类别分布不平衡。为了进一步优化我们的模型,我们采用由Dice损失LDice和交叉熵损失LCE组成的联合损失Ltotal来执行所有分割任务。公式如下,
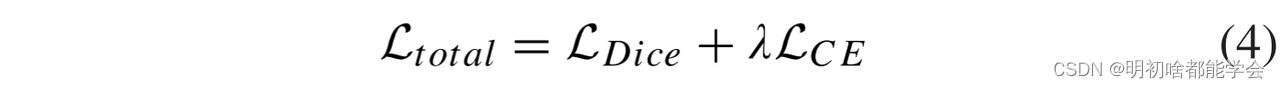
其中λ是骰子损失和交叉熵损失之间的权衡,并且在我们所有的实验中设置为1。为了公平比较,我们实验中的所有方法在每个单独的任务中使用相同的损失函数。
G. Implementation Details----G.实施细节
我们提出的模型的编码器基于预先训练的ResNet34。CPFNet的实现基于公共平台PyTorch和NVIDIA Tesla K40 GPU,内存为12GB。我们使用“poly”学习率策略,其中lr = baselr×(1− iter total_iter)power,基本学习率baselr设置为0.01,power设置为0.9。批量大小和迭代次数根据数据集而异。此外,采用随机梯度下降(SGD)优化我们的模型,其中动量和权重衰减分别设置为0.9和0.0001。我们将在Github上发布代码。

















 4602
4602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









