






DoubleU-Net A Deep Convolutional Neural Network for Medical Image Segmentation–2020
摘要
语义图像分割是将图像中的每个像素标记为相应的类的过程。基于编码器-解码器的方法,如U-Net及其变体,是解决医学图像分割任务的流行策略。为了提高U-Net在各种分割任务上的性能,我们提出了一种名为DoubleU-Net的新架构,它是两个U-Net架构相互堆叠的组合。第一个U-Net使用预训练的VGG-19作为编码器,它已经从ImageNet中学习了特征,可以轻松地转移到另一个任务中。为了有效地捕获更多的语义信息,我们在底部添加了另一个U-Net。我们还采用Atrous空间金字塔池(ASPP)来捕获网络中的上下文信息。我们使用四个医学分割数据集对DoubleU-Net进行了评估,涵盖了各种成像方式,如结肠镜检查、皮肤镜检查和显微镜检查。在MICCAI 2015分割挑战、CVC ClinicDB、2018 Data Science Bowl挑战和病变边界分割数据集上的实验表明,DoubleU-Net优于U-Net和基线模型。此外,DoubleU-Net生成更准确的分割模板,特别是在CVCClinicDB和MICCAI 2015分割挑战数据集的情况下,这些数据集具有挑战性的图像,例如较小和平坦的息肉。这些结果显示了对现有U-Net模型的改进。在各种医学图像分割数据集上产生的令人鼓舞的结果表明,DoubleU-Net可以用作医学图像分割和跨数据集评估测试的强大基线,以衡量深度学习(DL)模型的通用性。
引言
医学图像分割是对医学图像中感兴趣对象的每个像素进行标记的任务。它通常是临床应用的关键任务,从用于病变检测的计算机辅助诊断(CADx)到治疗计划和指导[1]。医学图像分割可以帮助临床医生专注于疾病的特定区域,并提取详细信息以进行更准确的诊断。与医学图像分割相关的关键挑战是大量注释的不可用,缺乏用于训练的高质量标记图像[2],图像质量低,缺乏标准分割协议,以及患者之间的图像差异很大[3]。分割精度和不确定性的量化对于估计其他应用的性能至关重要[1]。这表明需要一个自动的,可推广的,高效的语义图像分割方法。
卷积神经网络(CNN)已显示出自动医学图像分割的最新性能[4]。对于语义分割任务,早期的深度学习(DL)架构之一是全卷积网络(FCN),它是端到端训练的,用于逐像素预测。U-Net [5]是另一种流行的图像分割架构,经过端到端的训练,用于逐像素预测。U-Net架构由分析路径和合成路径两部分组成,在分析路径中学习深度特征,在合成路径中基于学习的特征进行分割。此外,U-Net使用跳过连接操作。跳过连接允许将密集特征图从分析路径传播到合成部分中的对应层。通过这种方式,空间信息被应用于更深层,这显著地产生更准确的输出分割图。因此,向U-Net添加更多层将允许网络学习更多代表性特征,从而获得更好的输出分割掩码。
U-Net架构由分析路径和合成路径两部分组成,在分析路径中学习深度特征,在合成路径中基于学习的特征
进行分割。
可以这么说吗???
----那我如果把不同层级的结果都softmax一下,然后再给它上下采样或者怎样整合一下嘞???
一般化,即,模型在独立数据集中执行的能力,以及鲁棒性,即,模型在具有挑战性的图像上执行的能力是开发用于临床试验的人工智能(AI)系统的关键[6]。因此,必须设计一个强大的架构,在不同的生物医学应用中是强大的和可推广的。预训练的ImageNet [7]模型显着提高了CNN架构的性能。在ImageNet上训练的这种模型的一个例子是VGG 19 [8]。受U-Net及其变体在医学图像分割方面的成功启发,我们提出了一种在网络编码器部分使用修改后的U-Net和VGG-19的架构。因为我们在网络中使用两个UNet架构,所以我们将该架构称为DoubleU-Net。使用VGG网络的主要原因是:(1)与其他预训练模型相比,VGG-19是一个轻量级模型,(2)VGG-19的架构类似于U-Net,易于与U-Net连接,(3)它将允许更深的网络产生更好的输出分割掩码。因此,我们的目标是通过启用这种架构变化来提高网络的整体分割性能。
本文的主要贡献是:
- 提出了一种新的语义图像分割体系结构,DoubleU-Net。所提出的架构使用两个U-Net架构的顺序,两个编码器和两个解码器。网络中使用的第一个编码器是预训练的VGG-19 [8],它是在ImageNet [7]上训练的。此外,我们使用Atrous空间金字塔池(ASPP)[9]。架构的其余部分是从头开始构建的。
- 在多个数据集上的实验是显示所提出的算法优于其他算法的先决条件。在这方面,我们已经在四个不同的医学成像数据集上进行了实验,两个不同的数据集来自结肠镜检查,一个来自皮肤镜检查,一个来自显微镜检查。与自动息肉检测数据集、CVC-ClinicDB数据集、ISIC-2018的病变边界分割挑战和2018 Data Science Bowl挑战数据集上的2015 MICCAI子挑战相比,DoubleU-Net显示出更好的分割性能。
- 在四个数据集上对DoubleU-Net进行的广泛评估显示,与U-Net相比,DoubleU-Net有了显著的改进。因此,DoubleU-Net可以作为医学图像分割任务的新基线。
相关工作
在不同的CNN架构中,像FCN [10]及其扩展U-Net [5]这样的编码器-解码器网络在2D图像的语义分割方法中非常流行。Badrinarayan等人。[11]提出了一种用于语义像素分割的深度全CNN,其参数显著减少,并产生良好的分割图。Yu等人[12]提出了一种新的卷积网络模块,特别针对密集预测问题。所提出的模块使用扩张卷积系统地聚合多尺度上下文信息,所提出的上下文模块提高了最先进的语义图像分割系统的准确性。
Chen等人。[13]提出DeepLab来解决分割问题。后来,DeeplabV 3 [9]在没有DenseCRF后处理的情况下,比之前的DeepLab版本有了显著的改进。DeepLabV 3架构使用的合成路径包含的卷积层数量较少,与FCN和UNet的合成路径不同。DeepLabV 3使用类似于U-Net架构的分析路径和合成路径之间的跳过连接。Zhao等人[14]提出了用于复杂场景理解的有效场景解析网络,其中全局金字塔特征提供了捕获额外上下文信息的机会。Zhang等人[15]提出了Deep Residual U-Net,它使用残差连接更好地输出分割图。Chen等人。[16]提出了用于医学图像分割的Dense-Res-Inception Net(DRINET),并将其结果与FCN,U-Net和ResUNet进行了比较。Ibtehaz等人。[17]修改了UNet,并提出了一种改进的MultiResUNet架构用于医学图像分割,他们在各种医学图像分割数据集上将其结果与U-Net进行了比较,并显示出比U-Net更上级的准确性。
Jha等人。[18]提出了ResUNet++,这是标准ResUNet的增强版本,通过将挤压和激发块,ASPP和注意力块等附加层集成到网络中。与Kvasir-SEG [2]和CVC-ClinicDB [19]数据集上的U-Net和ResUNet相比,所提出的架构使用骰子损失作为损失函数,并产生改进的输出分割图。Zhou等人。[20]提出了UNet++,这是一种用于语义和实例分割任务的神经网络架构。他们通过减轻未知的网络深度,重新设计跳过连接,并设计架构的修剪方案来提高UNet++的性能。
从上述相关工作中,我们可以观察到,人们已经做出了大量努力来开发用于自然和医学图像分割的深度CNN架构。最近,更多的工作集中在开发可推广的模型上,这就是为什么大多数研究人员在不同的数据集上测试他们的算法[17],[18],[20]。现在,自然成像[13]和医学成像[17],[18],[20]的准确度都很高。然而,医疗领域的AI仍然是一个新兴领域。医疗领域的一个重大挑战是缺乏测试数据集。此外,获得的数据集往往是不平衡的。在某种程度上,我们可以说,在自然图像的情况下,性能是可以接受的。在医学成像中,有许多具有挑战性的图像(例如,结肠镜检查中的扁平息肉),这些图像通常在结肠镜检查期间被遗漏,如果不进行早期检测,则可能发展为癌症。因此,需要一种更精确的医学图像分割方法来处理具有挑战性的图像。为了满足这一需求,我们提出了DoubleU-Net架构,该架构可以使用具有挑战性的图像生成高效的输出分割掩码。
方法
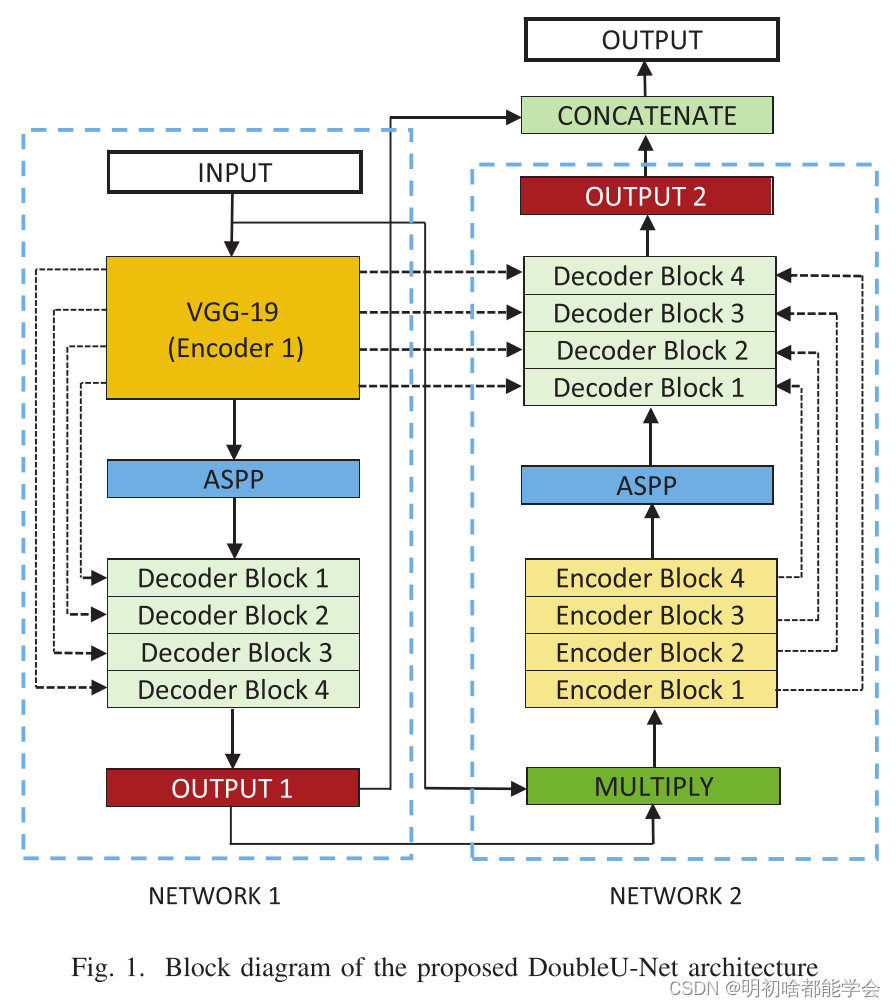
图1显示了建议的架构的概述。如图所示,DoubleU-Net以VGG-19作为编码器子网络开始,然后是解码器子网络。
在第一个网络(网络1)中,DoubleU-Net与U-Net的区别在于使用黄色标记的VGG-19、蓝色标记的ASPP和浅绿
色标记的解码器块。挤压和激励块[21]用于NETWORK 1的编码器以及NETWORK 1和NETWORK 2的解码器块。
在NETWORK 1的输出与同一网络的输入之间执行逐元素乘法。第二个网络(网络2)中DoubleU-Net和U-Net之
间的区别仅在于使用了ASPP和挤压和激励块。所有其他组件保持不变。
拟议的DoubleU-Net架构框图
在NETWORK 1中,输入图像被馈送到修改的U-Net,其生成预测掩码(Output 1)。然后,我们将输入图像与生成的掩码(Output 1)相乘,它作为第二个修改后的U-Net的输入,生成另一个掩码(Output 2)。最后,我们将两个掩码(Output 1和Output 2)连接起来,以查看中间掩码(Output 1)和最终预测掩码(Output 2)之间的定性差异。
我们假设从NETWORK 1产生的输出特征图仍然可以通过再次获取输入图像及其相应的掩码来改进,并且与Output 2连接将产生比前一个更好的分割掩码。这是在所提出的架构中使用两个U-Net架构的主要动机。在所提出的网络中的挤压和激励块减少了冗余信息,并通过最相关的信息。ASPP是现代分割架构的热门选择,因为它有助于提取高分辨率特征图,从而获得上级性能[18]。
A. Encoder Explanation—A.编码器说明
DoubleU-Net中的第一个编码器(编码器1)使用预训练的VGG-19,而第二个编码器(编码器2)则是从头开始构建的。每个编码器试图对输入图像中包含的信息进行编码。encoder 2中的每个编码器块执行两个3×3卷积运算,每个卷积运算之后是批量归一化。批量归一化减少了内部协变移位,也使模型正则化。应用整流线性单元(ReLU)激活函数,其将非线性引入模型中。这之后是一个挤压和激励块,这提高了特征图的质量。之后,使用2 × 2窗口和步幅2执行最大池化,以减少特征图的空间维度。
B. Decoder ExplanationB。解码器说明如图1所示,我们在整个网络中使用两个解码器,与原始U-Net相比,解码器有很小的修改。解码器中的每个块对输入特征执行2 × 2双线性上采样,这使输入特征图的维度加倍。现在,我们将适当的跳过连接特征映射从编码器连接到输出特征映射。在第一个解码器中,我们只使用来自第一个编码器的跳过连接,但在第二个解码器中,我们使用来自两个编码器的跳过连接,这保持了空间分辨率并提高了输出特征图的质量。在连接之后,我们再次执行两个3 × 3卷积运算,每个运算之后都是批量归一化,然后是ReLU激活函数。之后,我们使用挤压和激发块。最后,我们应用了一个具有sigmoid激活函数的卷积层,该函数用于生成相应修改后的U-Net的掩码。















 2221
2221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









