







 我们将从本篇博客开始,揭秘学术界和工业界解决混合动作空间的种种黑魔法。本篇将介绍,基于Q函数的强化学习混合动作空间算法。
我们将从本篇博客开始,揭秘学术界和工业界解决混合动作空间的种种黑魔法。本篇将介绍,基于Q函数的强化学习混合动作空间算法。
在前两篇博客中,我们介绍了深度强化学习的动作空间定义和常见的预处理方法。
混合动作空间 | 创造人工智能的黑魔法(1)_面向连续-离散混合决策的游戏ai智能体强化学习方法_OpenDILab开源决策智能平台的博客-CSDN博客
混合动作空间|揭秘创造人工智能的黑魔法(2)_OpenDILab开源决策智能平台的博客-CSDN博客
过去的强化学习研究大部分都关注离散动作和连续动作问题,但由于混合动作空间在诸多真实世界问题例如游戏AI、自动驾驶等领域有着广泛应用,近些年也涌现出一系列解决混合动作空间问题的方法。
因此我们将从本篇博客开始,揭秘学术界和工业界解决混合动作空间的种种黑魔法。
本篇将介绍,基于Q函数的强化学习混合动作空间算法。
关于Parametrized Action Space
首先我们来回顾一下 Parametrized Action Space 的定义。
Parameterized Action Space 的概念最早在这篇15年的paper “Deep reinforcement learning in parameterized action space” 中被提出,其核心构成如下:
paper 链接:https://arxiv.org/abs/1511.04143
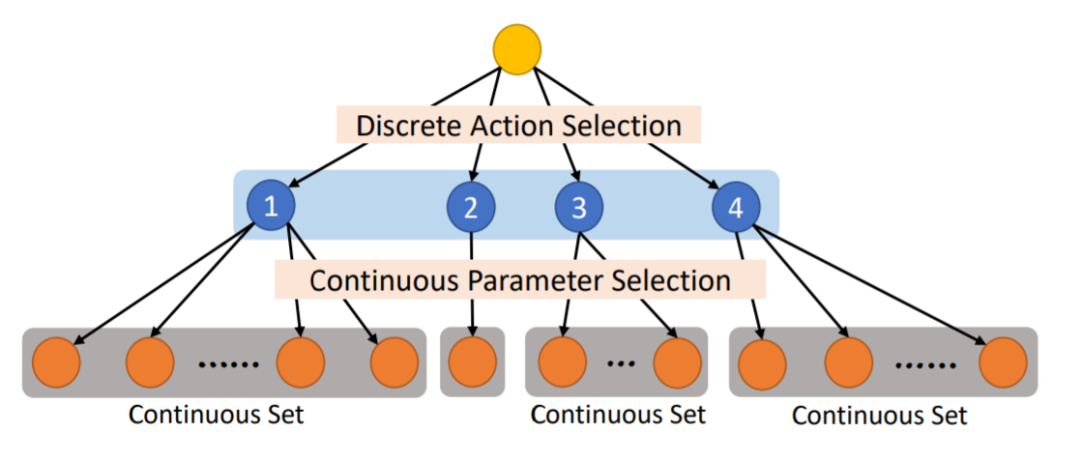
- 首先,定义一个离散动作空间
={
},一般记作action type
-
对于每一个离散动作
,都有
个连续参数{
}
和它相对应,一般记作action args
也就是说, 每一个动作由这样的tuple来表示:()
这样,动作空间就可以表示为, 图示如下,(引自 Fan, 19)。
传统解法
-
连续动作离散
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2170
2170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









