生成完整的配置文件
一般做法可以考虑继承base然后一个个实现模块,也可以先整体跑通在一个个修改,一般采用第二种 方法
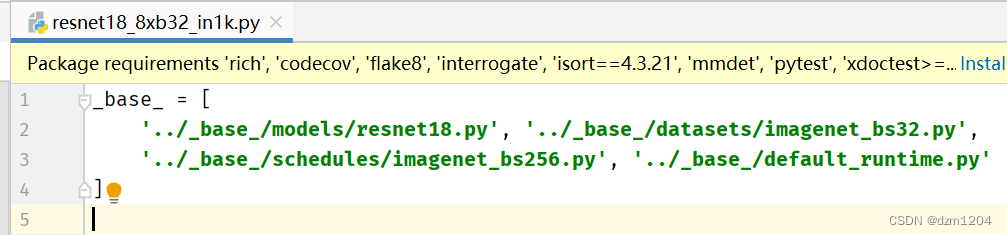
先复制resnet配置文件的绝对路径
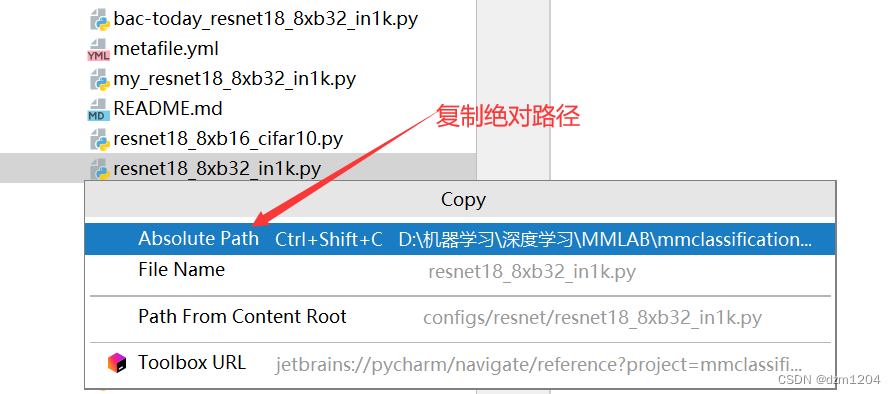
找到tools下的train.py就是入口函数
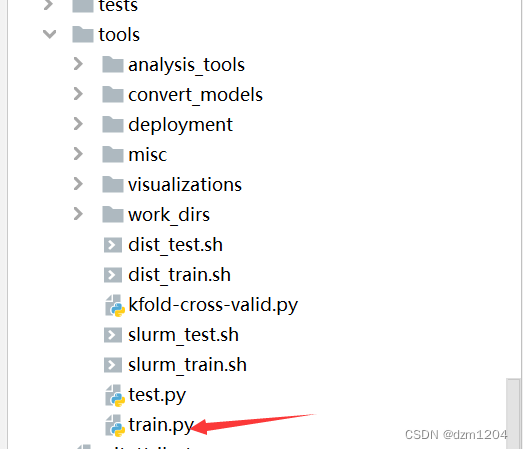
这里的路径是默认参数,所以直接给路径复制到参数设置里面去
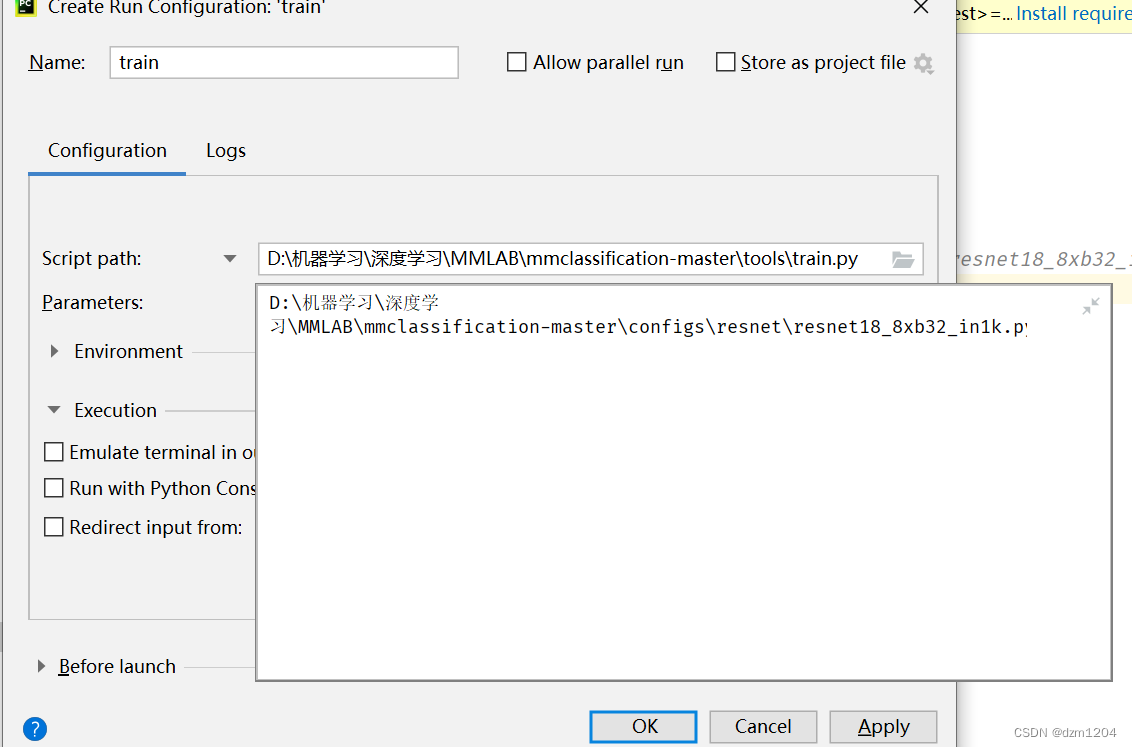
参数配置完可以先试着跑一下,虽然会报错但是也会生成一个文件如下

会生成这个配置文件,接下来就可以直接复制到pycharm中改这个配置文件
重命名后,复制到pycharm打开,里面就是生成的自己的网络结构,一开始里面都一些默认配置,我们需要修改一些配置项,最多修改的就是输出大小修改成自己分类的类别数,和指定自己训练集、验证集、测试集的文件路径,工作空间路径以及迭代多少次保存模型和日志文件。修改后一般可以直接跑通
model = dict(
type='ImageClassifier',
backbone=dict(
type='ResNet',
depth=18,
num_stages=4,
out_indices=(3, ),
style='pytorch'),
neck=dict(type='GlobalAveragePooling'),
head=dict(
type='LinearClsHead',
num_classes=1000,
in_channels=512,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
topk=(1, 5)))
dataset_type = 'ImageNet'
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', size=224),
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]
data = dict(
samples_per_gpu=32,
workers_per_gpu=2,
train=dict(
type='ImageNet',
data_prefix='../mmcls/data/flower_data/train',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='RandomResizedCrop', size=224),
dict(type='RandomFlip', flip_prob=0.5, direction='horizontal'),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='ToTensor', keys=['gt_label']),
dict(type='Collect', keys=['img', 'gt_label'])
]),
val=dict(
type='ImageNet',
data_prefix='../mmcls/data/flower_data/vaild',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]),
test=dict(
type='ImageNet',
data_prefix='../mmcls/data/flower_data/vaild',
pipeline=[
dict(type='LoadImageFromFile'),
dict(type='Resize', size=(256, -1)),
dict(type='CenterCrop', crop_size=224),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
to_rgb=True),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img'])
]))
evaluation = dict(interval=1, metric='accuracy')
optimizer = dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=None)
lr_config = dict(policy='step', step=[30, 60, 90])
runner = dict(type='EpochBasedRunner', max_epochs=100)
checkpoint_config = dict(interval=50)
log_config = dict(interval=100, hooks=[dict(type='TextLoggerHook')])
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
work_dir = './work_dirs/resnet18_8xb32_in1k'
gpu_ids = [0]
构建自己的数据集
用的方式二,所有的数据集都在一个文件夹没有分类。这时候就需要用标签来区分。标签格式: 图片名字 :图片标签
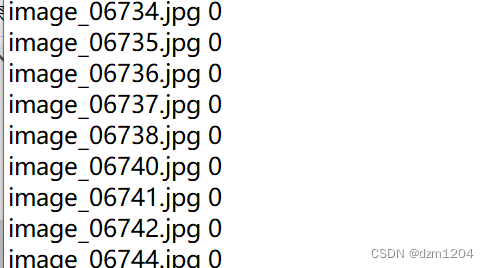
生成了这样的标签格式后,就需要再写一个数据处理文件,位置在mmcls/datasets下新建一个文件,这里是my_filelist.py
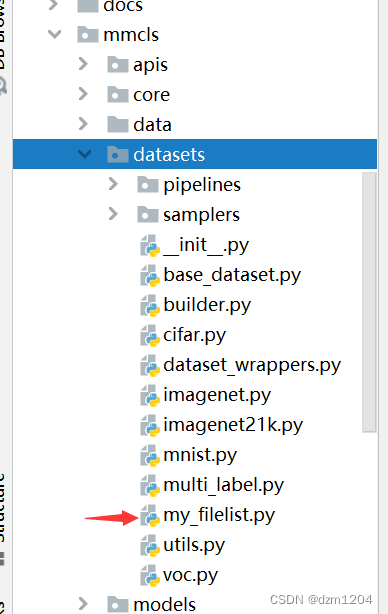
这里仿照imagenet.py,主要重写下面这个类,写入自己的类
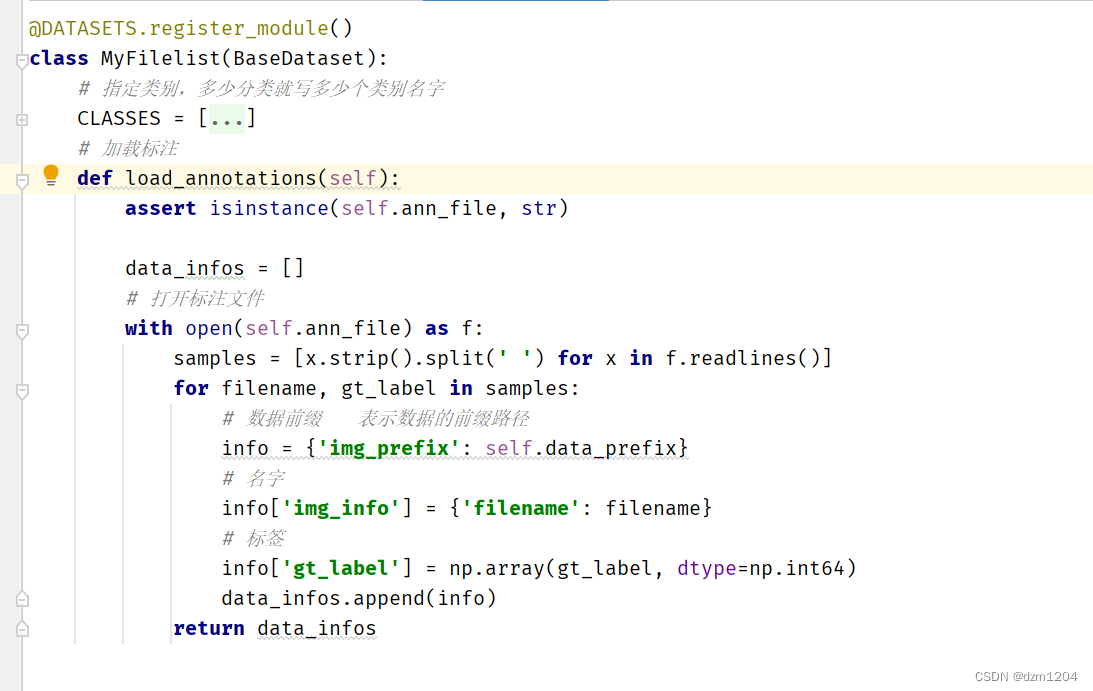
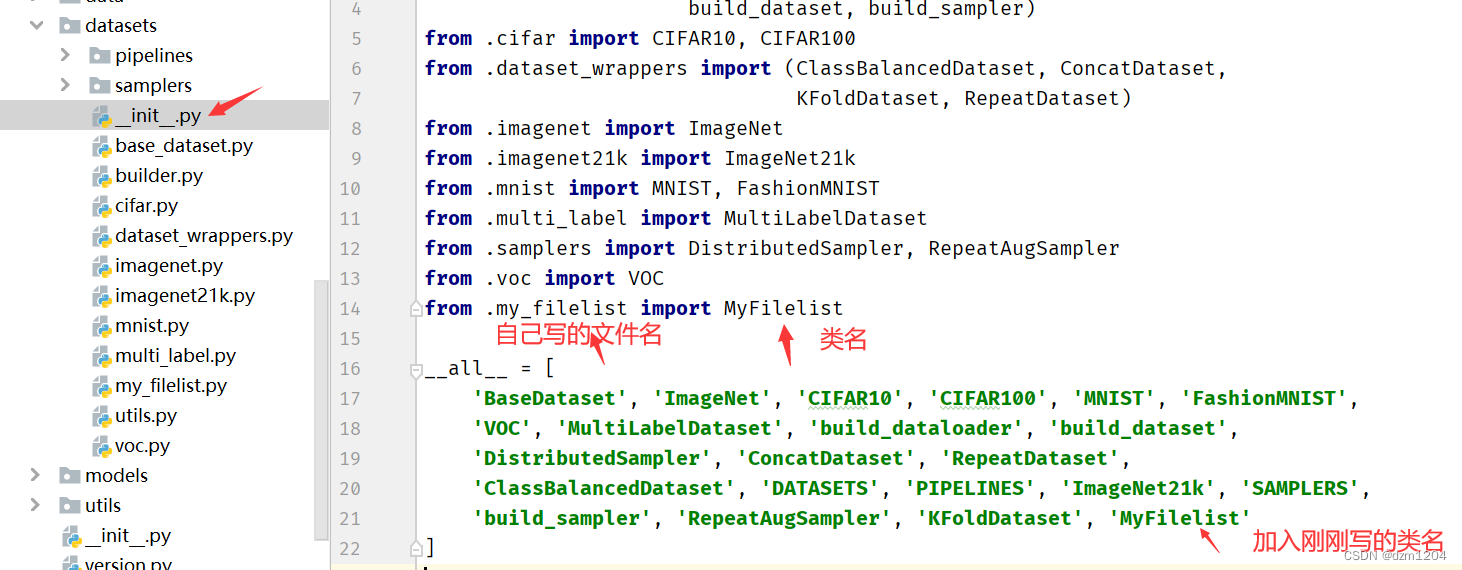
下一步需要在_init_.py导入自己刚刚写的类
再去配置文件中去改
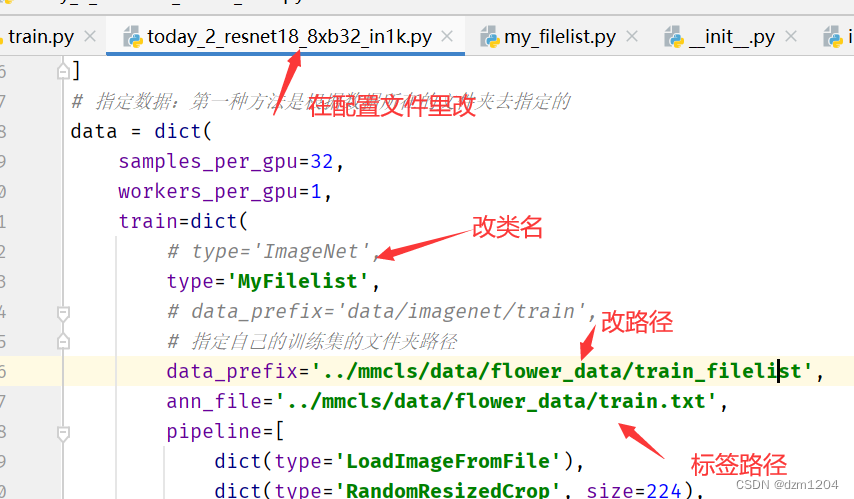
val做同样修改

修改后就可以开始跑自己的任务了
























 1352
1352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











