







 BLIP-Diffusion模型结合了BLIP-2和Diffusion模型,通过两阶段预训练策略学习主题表示,支持零镜头和高效微调的文本驱动图像生成。该模型能够在保持主题一致性的同时生成新图像,并可用于图像编辑和结构控制。
BLIP-Diffusion模型结合了BLIP-2和Diffusion模型,通过两阶段预训练策略学习主题表示,支持零镜头和高效微调的文本驱动图像生成。该模型能够在保持主题一致性的同时生成新图像,并可用于图像编辑和结构控制。
【论文精读02】BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
论文下载连接:https://arxiv.org/pdf/2305.14720v1.pdf
源码:https://dxli94.github.io/BLIP-Diffusion-website/
文章是在2023年5月24号发布在arxiv上,因为结合了多模态领域中的BLIP-2模型,以及当下较火的Diffusion模型,所以可以趁机了解以下这篇文章的模型设计思路,同时再复习一下BLIP-2 和 Diffusion这两个模型的设计的精巧之处。截至到5月27号模型的代码尚未开源,所以如有解读不当,请批评指正!!!
领域关键词:表征学习 文本-图像生成 图像生成
文章目录
1.摘要
主题驱动的文本-图像生成模型创造出了一个基于文本提示的输入主题的新展现。现存的模型有着微调时间长、主题保存性不强的问题,基于此提出了BLIP-Diffusion模型,它支持多模态控制,并且使用主题图像和文本提示作为输入。与其他工作不同的是,它引入了一个新的、预训练好的、能提供主题嵌入的多模态编码器。我们首先follow BLIP-2来预训练 视觉编码器;接着,我们设计了一个主题表示学习任务,使扩散模型能够利用这种视觉表示生成新的主题呈现。与之前的DreamBooth等方法相比,我们的模型能够实现zero-shot的主题驱动的生成,并对定制主题进行高效的微调,速度提高了20倍。我们还证明了BLIP-Diffusion可以灵活地与现有的技术结合,以实现新的主题驱动的生成和编辑。

2.结论
本文提出了一种由BLIP-2支持的内置多模态控制能力的文本-图像扩散模型。模型预训练分为两个阶段,逐步学习多模态主题表示,这有利于高保真的零射击和高效的微调主题驱动生成。(后续内容和摘要的后半部分差不多,就不再赘述了。。。)
3.引言
(引言部分内容较多,这里只提取出了对理解模型有价值的部分进行了记录,具体的细节可参见原文)
什么是主题驱动的图像生成?主题驱动的图像生成,其目的是在保留输入主题的同时使得主体呈现出新的外观。
BILP-Diffusion模型,这是第一个主题驱动的文本到图像生成模型,它具有预训练的通用主题表示,它使主题驱动的生成在zero-shot或几步的fine-tune就能完成。我们的模型建立在一个视觉语言编码器(BLIP-2 )和一个潜在的扩散模型(Stable Diffusion)之上。BLIP-2编码器将主题图像及其类别文本作为输入,它生成主题表示作为输出。然后,我们将主题表示固定在提示嵌入中,以指导潜在扩散模型的主题驱动的图像生成和编辑。
为了实现可控和高保真度的生成,我们提出了一种新的两阶段预训练策略来学习通用的主题表示。第一阶段,我们执行多模态表示学习,这将强制BLIP-2基于输入的图像生成文本对齐的视觉特征。第二阶段,我们设计了一个主题表示学习任务,其中扩散模型根据输入的视觉特征学习生成新的主题再现。为了实现这一点,我们管理了在不同背景中出现的相同主题的输入-目标图像对。具体来说,我们通过随机背景来合成输入图像。在预训练过程中,我们给BLIP-2输入合成的输入图像和主题类标签,以获得作为主题表示的多模态嵌入。然后,将主题表示与文本提示相结合,以指导目标图像的生成。
4.相关工作
原文就简单地介绍了Diffusion模型和主题驱动的文本-图像生成相关知识,篇幅较短,这里也就不再展开记录了。。。。见原文吧~
5.方法
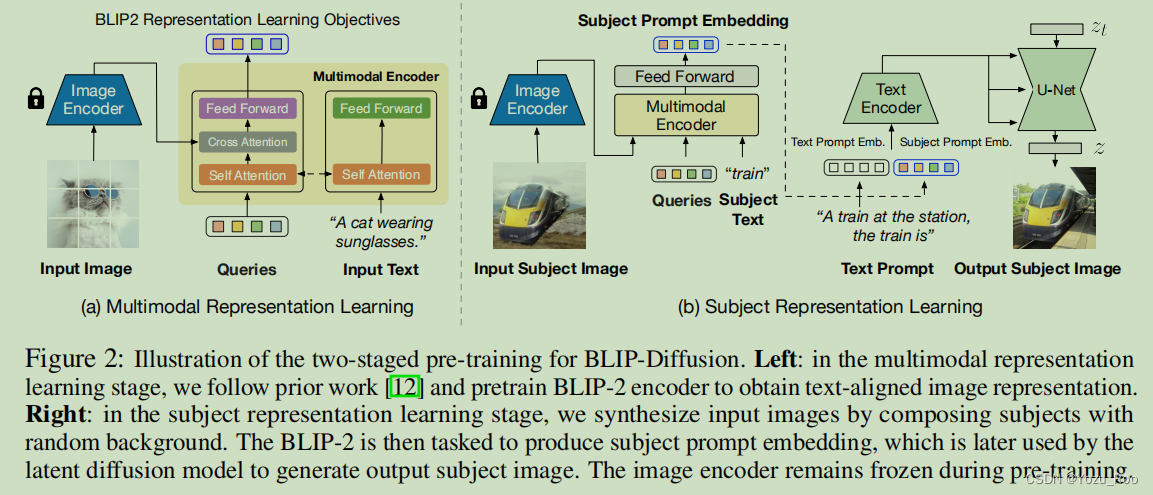
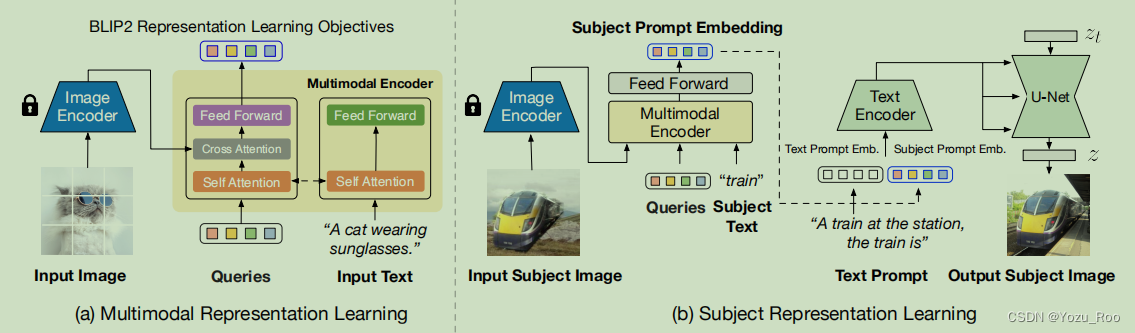
图2:BLIP-Diffusion的两阶段预训练的说明。左:在多模态表示学习阶段,我们遵循之前的工作来预训练BLIP-2编码器,以获得文本对齐的图像表示。右:在主题表征学习阶段,我们通过随机背景组合主题来合成输入图像。BLIP-2的任务是生成主题提示嵌入,接着被扩散模型用来生成输出的主题图像。图像编码器在预训练时被冻结。
我们的目标是学习主题表示,捕捉主题特定的视觉外观,同时与文本提示保持一致。为此,我们提出了一个两阶段的预训练策略。如上图所示,首先,多模态表示学习阶段产生文本对齐的通用图像表示。其次,主题表示学习阶段使用文本和主题表示来提示扩散模型进行主题驱动生成。在本节中,我们将描述模型的设计和预训练策略。
5.1 BLIP-2的多模态表示学习(第一阶段)
BLIP-2论文:https://arxiv.org/abs/2301.12597
我们使用BLIP-2中的两个主要模块来学习多模态表示:一个冻结的预训练好的图像编码器来提取通用的图像特征,一个用于图像-文本对齐的多模态编码器(即Q-Former)。多模态编码器是一个Transformer,它接受固定数量的可学习的query和一个输入文本。query通过自注意层与文本交互,通过cross-attention层与冻结的图像特征交互,并生成与文本对齐的图像特征作为输出。输出的token数目和query的相同。根据经验,我们发现,输出的特征的个数为32时,超过了CLIP文本嵌入的特征个数。因此,我们选择输出16个特征。
与BLIP-2的预训练相同,我们选择三个损失函数,分别是:图像-文本对比学习损失(ITC)、图像-真实文本生成损失(ITG)和图像-文本匹配损失(ITM)
5.2 Stable Diffusion的主题表示学习(第二阶段)
主题表征学习阶段旨在使扩散模型能够利用前一阶段得到的图像特征,并在与文本prompt相结合来生成不同的主题再现,当主题表示注入到扩散模型中时,我们有两个期望:第一,我们期望主题表示与文本提示很好地协调,以便实现文本引导的主题驱动生成;第二,理想情况下应该保持底层扩散模型的行为。这使得主题驱动的生成模型能够动态地利在该模型基础之上的技术,如图像编辑和结构控制的生成。
模型结构 所提出的模型架构如图2b所示。我们将BLIP-2多模态编码器的输出与扩散模型的文本编码器的输入连接起来。在预训练过程中,多模态编码器以一个主题图像和一个主题类别的文本作为输入,生成一个具有类别感知的主题视觉表示。然后,我们使用一个由两个线性层组成的前馈层来转换主题表示。映射后的特征作为软视觉主题提示附加到文本提示标记嵌入中。具体来说,当组合文本标记和主题嵌入时,我们使用模板“[文本提示],[主题文本]是[主题提示]”。最后,将组合后的文本和主题嵌入通过CLIP文本编码器,指导扩散模型的图像生成过程。软视觉提示对底层扩散模型进行了最小的架构更改,提供了注入主题表示的有效解决方案,同时在很大程度上继承了底层扩散模型的建模能力。
具有提示上下文生成的主题通用预训练 我们的目标是预训练模型,使它从输入图像中学习表示通用的主题。另一方面,另一方面,虽然可以在不同的背景下收集同一主题的多个图像,从而使用不同的图像作为输入和目标,但这种方法要扩展到通用主题是很费力的。
这里我感觉可以理解为这样:如果将一张狗的图片、主题类别描述(‘dog’)和prompt逐一与狗游泳、狗吃饭、狗奔跑这些图片组成input-target来预训练,显然这样做是费力的。
为了解决上述问题,我们提出了一种新的学习主题通用表示的预训练任务,称为提示的背景生成任务。其中,我们通过在随机背景下合成的图像来管理输入-目标训练对。该模型以合成的图像作为输入,并根据文本提示生成原始的图像作为输出。具体来说,给定一个包含主题的图像,我们首先将图像和类别文本输入到具有置信阈值的文本提示分割模型CLIPSeg。然后将置信度较高的分割图作为已知前景,置信度较低的作为不确定区域,其余作为已知背景,构建成trimap。对于给定的trimap,我们使用封闭形式的匹配[24,25]来提取前景,即主题。然后,我们通过alpha混合将提取的主题组合到一个随机的背景图像上。最后,我们使用合成的图像作为输入,而原始的主体图像作为输出,作为一个训练图像对。
如图3所示,这种合成对有效地分离了前景主体和背景上下文,防止了与主题无关的信息被编码在主题提示中。这样,我们鼓励扩散模型共同考虑主题提示和文本提示来生成,从而得到一个可以忠实地、灵活地由主题图像和文本提示控制的预训练模型。

图3:左:随机背景的训练图像对、目标图像(上)和输入图像(下)。图像来自开放图像数据集[22]。右图:我们的模型的主题驱动的图像生成(上),和从DALLE·2[4](下)的图像变化之间的比较。我们用文本提示“一只狗”和主题表示来提示我们的模型,同时将输入的图像输入到DALLE·2中进行变异生成。我们的模型以最小的背景信息编码来学习主题表示,这使得在与文本提示一起使用时能够进行忠实和灵活的控制。
在预训练过程中,我们冻结了图像编码器,并联合训练了BLIP-2多模态编码器以及潜在扩散模型的文本编码器和U-Net。为了更好地保留原始文本到图像的生成能力,我们发现以15%的文本提示的概率随机删除主题提示,而只使用文本提示来指导扩散是有益的。
5.3 微调和可控推断
预训练的主题表示能够实现zero-shot生成和对定制主题的高效微调。
特定于主题的微调和推理 给定一些主题图像和主题类别文本,我们首先使用多模态编码器来分别获得主题表示,然后,我们使用所有主题图像的平均主题表示来初始化主题提示嵌入。通过这种方式,我们在微调过程中缓存主题提示符嵌入,而不需要多模态编码器的向前传递。1通过考虑文本提示嵌入和平均主体嵌入,对扩散模型进行微调,生成主体图像作为目标。我们还冻结了扩散模型的文本编码器,我们发现这有助于避免过拟合。我们使用batchsize=3、lr=5e-5和AdamW [26]优化器,通常在40-120个epoch后观察到良好的结果,在单个A100 GPU上需要20-40秒才能完成。
采用ControlNet的结构控制生成 我们的模型引入了一种多模态的主体控制调节机制。图4说明了这种集成,我们将预训练的ControlNet通过残差连接附加到扩散模型的U-Net上。通过这种方式,该模型除了考虑主题线索外,还考虑了输入结构条件,如边缘图和深度图。
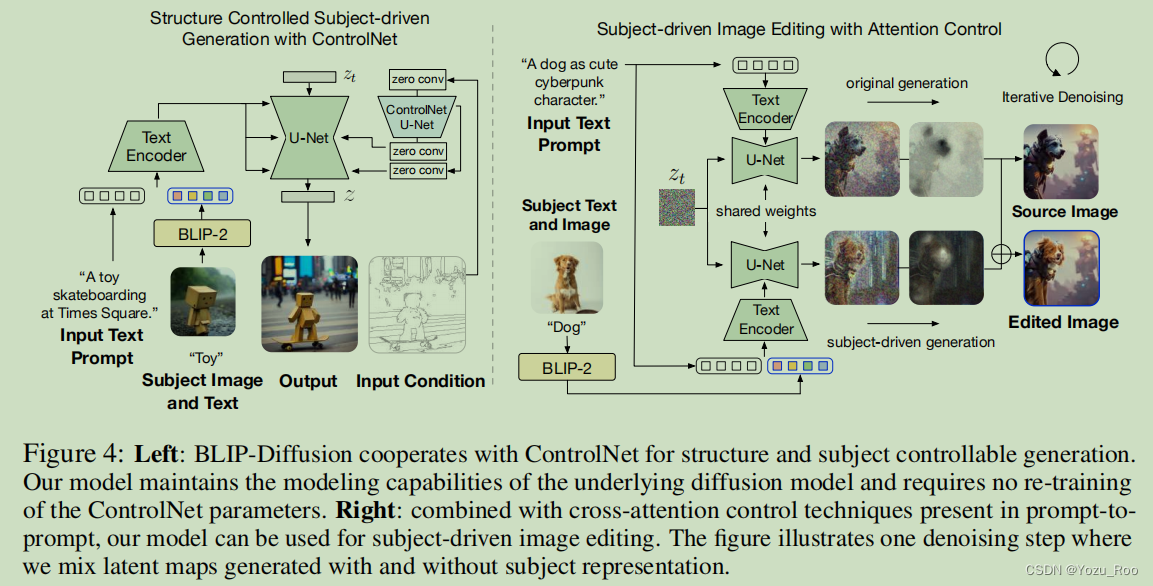
图4:左:BLIP-Diffusion模型与ControlNet配合进行结构和主体可控生成。我们的模型维护了底层扩散模型的建模能力,并且不需要对ControlNet参数进行再训练。右图:结合提示到提示中出现的交叉注意控制技术,我们的模型可以用于主题驱动的图像编辑。该图说明了一个去噪步骤,其中我们混合了有和没有主题表示生成的潜在映射。
基于注意力控制的主题驱动的编辑 我们的模型通过操作prompt tokens的交叉注意映射来实现主题驱动的图像编辑。在图4中,我们展示了这种功能,模型使用特定的视觉效果编辑原始图像。为此,我们假设原始图像的生成过程是已知的,或者可以通过对真实图像的反演[13,27]得到。要编辑图像,我们首先指定要编辑的文本标记,例如标记“dog”。接下来,我们使用指定标记的交叉注意映射自动提取要编辑的区域。为了在未经编辑的区域中保留布局和语义,我们在为插入的主题嵌入生成新的注意力映射时,保留了原始的注意力映射。我们根据提取的待编辑的掩码,混合每一步的去噪延迟。也就是说,未被编辑区域来自原始图像,而被编辑区域来自主题驱动的图像。通过这种方式,我们获得了具有特定主题视觉效果的编辑图像,同时也保留了未编辑的区域。
6.实验
这一部分作者设置了大量的对比实验来说明自己模型的优点,展示了许多实验图片效果,本部分只对较为重要的几个实验结果进行阐述,详见原文。
6.1预训练数据集和细节
对于多模态表示学习,我们遵循BLIP-2,并在129M的图像-文本对上进行预训练,包括来自LAION的115M图像-文本对,具有CapFilt标题、COCO、Visual Genome和概念标题。我们使用EVA-CLIP中的ViT-g/14作为图像编码器,并用BERTbase [35]初始化Q-Former。如前所述,我们使用16个查询来学习主题表示。其他训练超参数遵循[29]。
对于主题表示学习,我们使用来自OpenImage-V6 [22]的292K图像的子集,每个图像包含一个显著的主题。我们还删除了与人类相关的主题的图像。我们使用BLIP-2 OPT6.7B来生成作为文本提示的标题。我们从网络上获得了一组59K的背景图像来合成受试者的输入。我们使用稳定扩散v1-5作为基础扩散模型。我们使用AdamW [26]优化器使用总批大小16,500K步,在16张100 40GB GPU需要6天时间完成。关于超参数和数据过滤过程的更多细节见附录,以供参考。
6.2实验结果
6.2.1主要的定性实验结果
该实验结果在原文中是图5、图6,由于篇幅有限,这里就不再展示,可以去看原文。
6.2.2在DreamBooth数据集上的对比
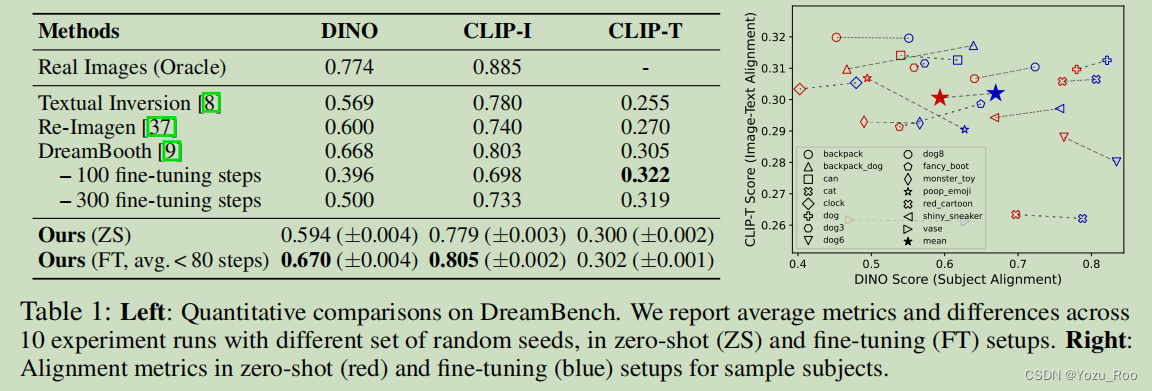
表1:左:DreamBench的定量比较。我们报告了在zero-shot(ZS)和fine-tune(FT)设置下,10次实验运行的平均指标和差异。右图:在零镜头(红色)和微调(蓝色)设置中的对齐指标。
6.2.3消融实验结果
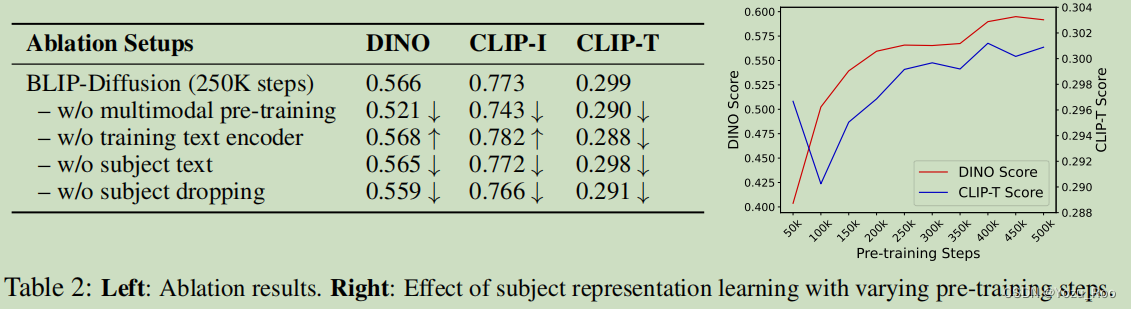
我们的研究结果是: (i)进行多模态表示学习是至关重要的(原文第3.1节),它弥补了主题嵌入和文本提示嵌入之间的表示差距。(ii)扩散模型的冻结文本编码器恶化了主体嵌入和文本嵌入之间的交互作用。这将导致生成过程会复制主题输入,而不在乎文本提示。尽管导致了更高的主题对齐分数,但它不允许文本控制,伪造了文本到图像生成的任务。(iii)将主题文本交给多模态编码器有助于注入特定主题的视觉先验,从而导致度量标准上的适度提升。(iv)随机drop的预训练有助于更好地保持扩散模型的生成能力,从而有利于结果。我们进一步证明了主体表征学习的效果。图(右)显示,图像-文本对齐和主题对齐都随着主题表示学习的训练前步骤的增加而改善。
除此之外,作者也做了主题表示法可视化、zero-shot的主题驱动的图像处理(主题驱动的样式传输、主题插值)等实验,相关定性结果也在原文中进行了展示,具体可见原论文。
7.限制和失败样例
我们的模型存在主题驱动的生成模型的常见失败,如不正确的上下文合成、训练集的过拟合,如[9]所述。此外,它还继承了底层扩散模型的一些弱点,即可能无法理解文本提示和细粒度的组合关系。我们在图10中展示了一些这样的失败示例。尽管有这些局限性,但所提出的技术是通用的,以收获未来的扩散模型的发展。

这里我理解的应该是一个主题prompt对应了多张主题图片的情况,为了避免计算复杂度,就直接平均化了主题表示并缓存了promp embs ↩︎


















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











