







【论文精读03】Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold

论文下载链接:https://vcai.mpi-inf.mpg.de/projects/DragGAN/data/paper.pdf
代码地址:https://github.com/XingangPan/DragGAN
本文是近期被SIGGRAPH 2023 Conference Proceedings所接收的一篇文章,因为研究的主题比较有意思,并且代码也已经开源,因此对这篇文章做一个精读,学习一下作者模型的设计思路和技巧,如有解读不当,请批评指正。
领域关键词:计算方法;计算机视觉;GANs,交互式图像操作,点跟踪
文章目录
1. 摘要
合成满足用户需求的视觉内容通常需要对生成对象的姿态、形状、表达和布局的灵活性和可控性有着一定的要求。现有的方法是通过手动标注的训练数据或先前的三维模型来获得生成对抗网络(GANs)的可控性,这些方法往往缺乏灵活性、精度和通用性。在这项工作中,我们研究了一种强大但浅探索的控制GANs的方法,即“拖动”图像中的任何点,以用户交互的方式精确到达目标点,如图1所示。

图1。DragGAN允许用户“拖动”任何GAN生成的图像的内容。用户只需点击图像上的几个手柄点(红色)和目标点(蓝色),我们的方法将移动手柄点,精确地到达相应的目标点。用户可以选择画一个灵活的区域(更亮的区域)的掩模,保持图像的其余部分不变。这种灵活的基于点的操作可以控制许多空间属性,如姿态、形状、表达式和布局。项目页面: https://vcai.mpi-inf.mpg.de/projects/DragGAN/.
为了实现这一点,我们提出了DragGAN,它由两个主要组件组成: 1)一种基于特征的移动监督,驱动手柄点向目标位置移动;2)一种新的点跟踪方法,利用鉴别生成器特性来保持定位手柄点的位置。由于这些操作是在可学习GAN生成的图像上执行的,它们倾向于产生现实的输出,即使是在具有挑战性的场景下,如幻觉遮挡的内容和变形的形状,也会一致地遵循物体的刚性。定性和定量的比较都表明,DragGAN在图像处理和点跟踪的任务中比以前的方法具有优势。我们还展示了通过GAN反演对真实图像的操作。
在摘要部分,作者指出了目前采用手动标注数据集和三维模型来获取GAN的操控能力是缺乏灵活性的,因此提出了一种交互式的、灵活的、可操作的模型,它能够与用户交互从而达到实时编辑图像的目的。该模型包括两个组件:基于特征的移动监督方法和点跟踪方法;前者用于驱动点的移动,后者用于跟踪轨迹以便于对像素进行实时调整。最后,作者概况说明了一下DragGAN模型的优势。
2. 结论
结论这里的内容和摘要的差不多,作者先说明了模型达到了一个怎样的效果,然后说了一下模型的组成结构(两个组件),最后阐述了一下模型的优点,这里不再赘述了,详见论文
3. 引言
引言部分,这里只提炼了要点,完整内容可以看原论文。
与先前的研究相比,本文研究的问题还有两个挑战: 1)我们考虑一个点以上的控制,然而他们的方法不能很好地处理这一问题;2)我们要求操纵点能够精确到达目标点,而他们的方法没有实现这一功能。正如我们将在实验中展示的那样,用精确的位置控制来处理多个点可以实现更加多样化和精确的图像操作。
为了实现这种基于点的交互式操作,我们提出了DragGAN,它解决了两个子问题,包括:1)监督手柄点向目标移动;2)跟踪手柄点,以便在每个编辑步骤中都知道它们的位置。
具体来说,运动监督是通过一个移动的特征块损失来实现优化潜在编码。每个优化步骤都会使得手柄点更接近目标;那么,点跟踪就会通过在特征空间中的最近邻搜索实现。重复此优化过程,直到手柄点到达目标为止。DragGAN还允许用户选择性地绘制感兴趣的区域来执行特定于区域的编辑在大多数情况下,在一个RTX 3090 GPU上只需要几秒钟。这允许实时的交互式编辑会话,其中用户可以在不同的布局上快速迭代,直到达到所需的输出。
我们的编辑是在学习的图像流形上执行的,它倾向于服从底层的对象结构例如,我们的方法可以产生幻觉、咬合的内容,比如狮子嘴里的牙齿,也可以随着物体的刚性而变形,比如马腿的弯曲。
我们还开发了一个GUI,用户可以通过简单地单击图像来交互式地执行操作。此外,我们的基于gan的点跟踪算法也优于现有的点跟踪算法,如RAFT [Teed和Deng 2020]和PIPs [Harley et al. 2022]。此外,通过结合GAN反演技术,我们的方法也可以作为一个强大的真实图像编辑工具。
4. 相关工作
略,详见论文。。。。
5. 方法
本工作旨在开发一种GANs交互式图像处理方法,用户只需要点击图像来定义一些对(手柄点,目标点),并驱动手柄点到达相应的目标点。我们的研究基于StyleGAN2体系结构[Karras等人,2020]。这里我们简要介绍这个体系结构的基础知识。
StyleGAN。在StyleGAN2架构中,一个512维的潜在码𝒛∈N(0,𝑰)通过一个映射网络被映射到一个中间的潜在码𝒘∈R 512。𝒘的空间通常被称为W,然后𝒘被发送到生成器𝐺,以生成输出图像I=𝐺(𝒘)。在这个过程中,𝒘被复制了几次,并输入到生成器𝐺的不同层,以控制不同级别的属性。或者,我们也可以对不同的层使用不同的𝒘,在这种情况下,输入将是𝒘∈R𝑙×512=W+,其中𝑙是层数。这种约束较少的W+空间更具表现力[Abdal等人,2019]。由于生成器𝐺学习了从低维潜在空间到更高维图像空间的映射,它可以看作是对图像流形的建模[Zhu et al. 2016]。
5.1 基于交互式点的操作
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0HMCPnAM-1685358106664)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\image-20230529113626155.png)]](https://img-blog.csdnimg.cn/27c22f01546248feab9b088a1ef45a1c.png)
图2。我们模型流程的概述。给定一个GAN生成的图像,用户只需要设置几个手柄点(红点)、目标点(蓝点),以及可选的一个掩码,表示编辑期间的可移动区域(亮的区域)。我们的方法迭代地执行运动监督(Sec 3.2)和点跟踪(Sec 3.3).运动监督是驱动手柄点(红点)向目标点(蓝点)移动,而点跟踪步骤是更新手柄点以跟踪图像中的对象。这个过程将一直进行,直到手柄点到达它们相应的目标点为止。
用户给定输入后,我们以一种优化的方式执行图像操作。如图2所示,**每个优化步骤由两个子步骤组成,包括:1)运动监控。2)点跟踪。**在运动监督中,一个强制处理点向目标点移动的损失被用来优化潜在代码𝒘。经过一个优化步骤后,我们得到了一个新的潜在代码𝒘‘和一个新的图像I’。该更新会导致图像中对象的轻微移动。请注意,运动监督步骤只将每个手柄点向目标移动一小的步骤,但步骤的确切长度不清楚,因为它受到复杂的优化动态,因此不同的对象和部件会不同。我们然后更新句柄点{𝒑𝑖}的位置,以跟踪对象上相应的点。**这个跟踪过程是必要的,因为如果手柄点(例如,狮子的鼻子)没有被准确地跟踪,那么在下一个运动监督步骤中,错误的点(例如,狮子的脸)将被监督,导致不希望的结果。**经过跟踪后,我们根据新的句柄点和潜在码,重复上述优化步骤。这个优化过程一直持续到手柄点{𝒑𝑖}到达目标点{𝒕𝑖}的位置,在我们的实验中,这通常需要30-200次迭代。用户还可以在任何中间步骤中停止优化。编辑完成后,用户可以输入新的句柄和目标点,并继续编辑,直到对结果满意为止。
5.2 运动监督
如何监督一个GAN生成的图像的点运动之前还没有太多的探索。在这项工作中,我们提出了一个不依赖于任何附加的神经网络的运动监督损失。**关键思想是,生成器的所产生的中间特征具有区分性,一个简单的损失就足以监督运动。**具体来说,我们考虑了StyleGAN2的第6块之后的特征映射F,由于它在分辨性和区分性之间有很好的权衡,所以它在所有特征中表现最好。我们通过双线性插值调整F的大小以与最终图像相同的分辨率。
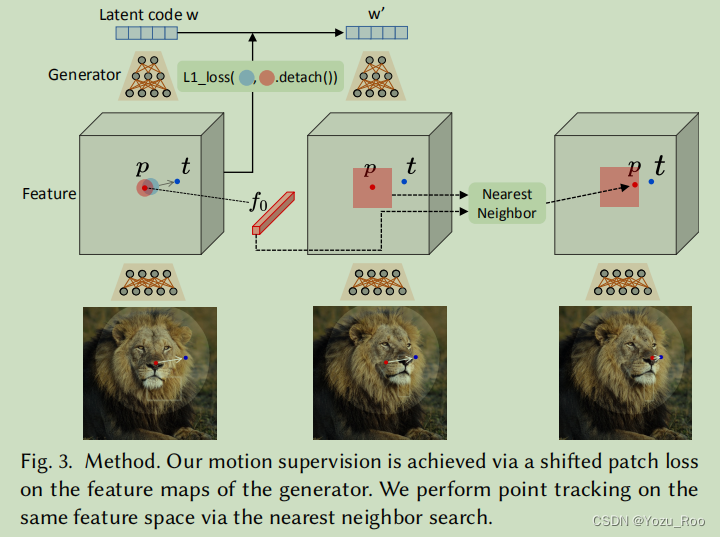
图3. 方法。我们的运动监督是通过特征图上面的移动块的损失来实现的。在同一特征空间上采用最近邻搜索进行点跟踪。
如图3所示,为了将一个手柄点𝒑𝑖移动到目标点𝒕𝑖,我们的想法是监督𝒑𝑖周围的一个小斑块(红色圆圈),通过一个小的步骤(蓝色圆圈)向𝒕𝑖移动。我们使用Ω1(𝒑𝑖,𝑟1)来表示距离𝒑𝑖小于𝑟1的像素,那么我们的运动监督损失为:
L
=
∑
i
=
0
n
∑
q
i
∈
Ω
1
(
p
i
,
r
1
)
∣
∣
F
(
q
i
)
−
F
(
q
i
+
d
i
)
∣
∣
1
+
λ
∣
∣
(
F
−
F
0
)
⋅
(
1
−
M
)
∣
∣
1
L= \sum _{i=0}^{n}\sum _{q_{i}\in \Omega _{1}(p_{i},r_{1})}||F(q_{i})-F(q_{i}+d_{i})||_{1}+ \lambda ||(F-F_{0})\cdot(1-M)||_{1}
L=i=0∑nqi∈Ω1(pi,r1)∑∣∣F(qi)−F(qi+di)∣∣1+λ∣∣(F−F0)⋅(1−M)∣∣1
其中F(𝒒)为F在像素𝒒处的特征值,
d
i
=
t
i
−
p
i
∣
∣
t
i
−
p
i
∣
∣
2
d_{i}= \frac{t_{i}-p_{i}}{||t_{i}-p_{i}||_{2}}
di=∣∣ti−pi∣∣2ti−pi为指向𝒑𝑖到𝒕𝑖的归一化向量(𝒅𝑖= 0 if𝒕𝑖=𝒑𝑖),F0为初始图像对应的特征映射。注意,第一项是对所有句柄点{𝒑𝑖}的总结。由于𝒒𝑖+𝒅𝑖的分量不是整数,我们通过双线性线性插值得到F(𝒒𝑖+𝒅𝑖)。
这个损失函数的前半部分可以理解为:让handle point沿着handle point——>target point这条直线不断靠近target point。后半部分可以理解为:让用户划分的变动范围以外的内容(即掩码)保持和初始图像不变。只有在这两部分之间trade-off,同时结合生成器的学习,最终才会产生理想的拖动效果,此时的loss也就最小。
在每个运动监控步骤中,这个损失被用于优化一步的潜在代码𝒘。𝒘可以在W空间或W+中进行优化。
在实践中,我们观察到图像的空间属性主要受前6层的𝒘的影响,而其余的空间属性只影响外观。因此,受风格混合技术的启发[Karras等人,2019年],我们只更新了前6层的𝒘,同时修复了其他层以保持外观。这种选择性的优化导致了所期望的图像内容的轻微移动。
5.3 点跟踪
之前的运动监督产生了一个新的潜在代码𝒘‘,新的特征映射F’,和一个新的图像I‘。由于运动监督步骤不容易提供手柄点的精确新位置,**在这里我们的目标是更新每个手柄点𝒑𝑖,使它跟踪对象上的相应点。**点跟踪通常通过光流估计模型或粒子视频方法来执行[Harley et al. 2022]。同样,这些额外的模型可能会显著损害效率,并可能遭受累积错误,特别是在GANs中存在伪影的情况下。因此,我们提出了一种新的点跟踪方法。结果表明,GANs的判别性特征可以很好地捕获密集的对应关系,从而通过在特征块中的最近邻搜索来有效地进行跟踪。
具体来说,我们将初始句柄点的特征表示为𝒇𝑖=F0(𝒑𝑖)。我们将𝒑𝑖周围构成的块表示为
Ω
2
(
p
i
,
r
2
)
=
{
(
x
,
y
)
∣
∣
x
−
x
p
,
i
∣
<
r
2
,
∣
y
−
y
p
,
i
∣
<
r
2
}
\Omega_{2}(p_{i},r_{2})= \left\{(x,y)||x-x_{p,i}|<r_{2},|y-y_{p,i}|<r_{2}\right\}
Ω2(pi,r2)={(x,y)∣∣x−xp,i∣<r2,∣y−yp,i∣<r2}然后在Ω2(𝒑𝑖,𝑟2)中搜索𝑓𝑖的最近邻,得到跟踪点:
p
i
:
=
a
r
g
min
q
i
∈
Ω
2
(
p
i
,
r
2
)
∣
∣
F
′
(
q
i
)
−
f
i
∣
∣
1
.
p_{i}:= \quad arg\min_{q_i \in \Omega _{2}(p_{i},r_{2})} ||F^{\prime}(q_{i})-f_{i}||_{1}.
pi:=argqi∈Ω2(pi,r2)min∣∣F′(qi)−fi∣∣1.
这个公式可以这么理解:前面我们handle point 已经向 target point移动了,现在需要找到在这移动过程中handle point的每个中间状态(轨迹点),我们知道handle point的初始特征在整个移动过程中基本是不会改变的,因此我们只需要找到在移动的过程中有哪些点和fi最相似(也就是公式中要min的东西,它这里使用距离公式衡量相似度),那么这个点就是我们寻找的轨迹点,也就实现了点跟踪。
**通过这种方式,𝒑𝑖将被更新为跟踪该对象。对于多个句柄点,我们对每个点应用相同的过程。**注意,这里我们也在考虑StyleGAN2的第6个块之后的特征映射F‘。
5.4 实现细节
我们基于PyTorch实现了我们的方法。我们使用Adam优化器来优化,数据集为FFHQ [Karras等人2019]、AFHQCat [Choi等人2020]和LSUN Car [Yu等人2015]的学习率设置为2e-3,其他数据集为1e-3。超参数被设置为𝜆= 20、𝑟1=3、𝑟2=12。在我们的实现中,当所有的柄点距离它们对应的目标点不超过𝑑像素时,我们停止优化过程,其中不超过5个柄点的𝑑设置为1,否则设置为2。我们还开发了一个GUI来支持交互式图像操作。由于我们的方法的计算效率,用户每次编辑只需要等待几秒钟,并且可以继续编辑,直到满意为止。我们强烈推荐读者参考补充视频来获取互动会议的现场录音。
6. 实验
数据集 我们评估我们的方法基于StyleGAN2[卡拉斯等2020]预训练在以下数据集(预训练的解决方案风格2见括号):FFHQ(512)[卡拉斯等2019],AFHQCat(512)(崔等2020],SHHQ(512)(傅等2022],LSUN汽车(512)[余等2015],LSUN Cat(256)[余等2015],Landscapes HQ (256)[斯科罗霍多夫等2021],microscope(512) [Pinkney 2020]。以及来自[Mokady et al. 2022]的自馏数据集,包括Lion (512), Dog (1024), and Elephant (512).
Baseline 我们的主要基线是UserControllableLT[Endo2022],它与我们的方法有最接近的设置。UserControllableLT不支持掩码输入,但允许用户定义一些固定点。因此,对于使用掩码输入的测试用例,我们在图像上采样一个常规的16×16网格,并使用掩码外的点作为UserControllableLT的固定点。此外,我们还与RAFT [Teed和Deng 2020]和pip[Harleyetal.2022]进行了点跟踪比较。为此,我们创建了我们的方法的两种变体,其中点跟踪部分(第3.3节)被这两种跟踪方法所取代。
6.1 定性评估
图4显示了我们的方法与UserControllableLT之间的定性比较。

图4。我们的UserControllableLT的方法[Endo 2022]对将手柄点(红点)移动到目标点(蓝点)的任务的定性比较。我们的方法在各种数据集上取得了更自然和更优越的结果。图10提供了更多的例子。
图6提供了我们使用pip和RAFT的方法之间的比较。我们的方法可以准确地跟踪狮子鼻子上方的手柄点,从而成功地将其驱动到目标上

图6。我们对RAFT方法[Teed和Deng 2020]、pip方法[Harley et al. 2022]和无跟踪方法的定性跟踪比较。我们的方法比基线更准确地跟踪句柄点,从而产生更精确的编辑。
这里受篇幅限制,只展示了部分定性实验效果图,详细的实验图像可以看原论文,总的比较来看这个模型的效果还是蛮惊艳的。
6.2 定量评估
我们定量评估了我们的方法在两种设置下,包括人脸标记操作和配对图像重建。
人脸标记
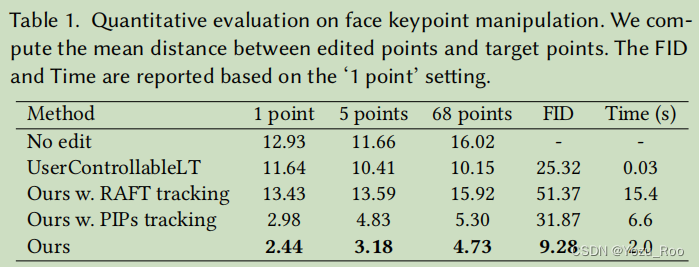
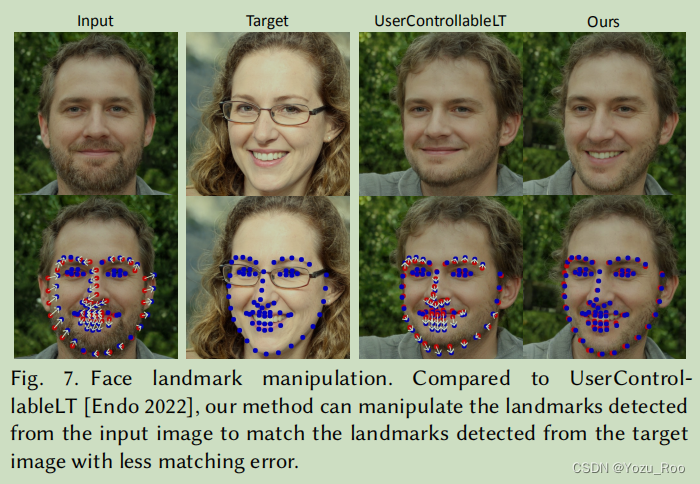
图7。面部地标性操作。与UserControllableLT[Endo2022]相比,我们的方法可以操纵从输入图像中检测到的地标,以匹配从目标图像中检测到的地标,匹配误差更小。
配对图像重建
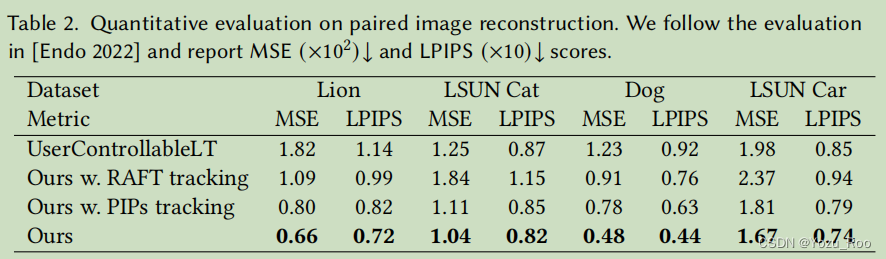
.在这个评估中,我们遵循与UserControllableLT相同的设置[Endo 2022]。具体来说,我们对一个潜在代码𝒘1进行采样,并以与[Endo 2022]中相同的方式随机干扰它以得到𝒘2。设I1和I2是由这两个潜在码生成的StyleGAN图像。然后,我们计算I1和I2之间的光流,并从流场中随机抽取32个像素作为用户输入U。目标是从I1和U重建I2。我们报告了MSE和LPIPS [Zhang等人,2018],并对超过1000个样本的结果进行了平均。在我们的方法及其变体中,最大优化步骤被设置为100。如表2所示,我们的方法在不同的对象类别中都优于所有的基线,这与之前的结果一致。
消融研究
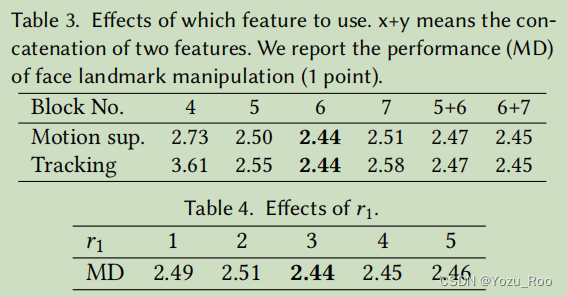
本文研究了哪些特征在运动监督和点跟踪中的影响。我们报告了使用不同特征的人脸地标操作的性能(MD)。如表3所示,在运动监督和点跟踪中,StyleGAN第6块后的特征图表现最好,分辨率和辨别性之间的平衡最好。我们还在表4中提供了𝑟1的影响。可以看出,性能对𝑟1的选择不是很敏感,而𝑟1=3的表现稍好一些。
7.讨论
掩码的影响 我们的方法允许用户输入一个表示可移动区域的二进制掩模。我们在图8中显示了其效果。当给狗的头上加上掩码时,其他区域几乎固定不变,只有头部移动。如果没有掩码,这个操作会移动整个狗的身体。这也表明,基于点的操作通常有多种可能的解,而GAN将倾向于在从训练数据中学习到的图像流形中找到最接近的解。掩模功能可以帮助减少歧义,并保持某些区域的固定。

分布外的操作 到目前为止,我们所展示的基于点的操作是“分布内”操作,也就是说,在训练数据集的图像分布内的自然图像可以满足操作要求。在这里,我们在图9中展示了一些分布外的操作。可以看出,我们的方法有一些外推能力,在训练图像分布之外创建图像,例如,一个非常张大的嘴和一个大轮子。在某些情况下,用户可能希望始终在训练分布中保留图像,并防止它达到这种分布外的操作。实现这一目标的一个潜在方法是在潜在代码𝒘中添加额外的正则化,而这并不是本文的主要重点。

限制 尽管有一些外推能力,但我们的编辑质量仍然受到训练数据的多样性的影响。如图14 (a)所示,创建一个偏离训练分布的人体姿势可能会导致伪影。此外,在无纹理区域中的处理点有时会在跟踪过程中遭受更多的漂移,如图14 (b)©.所示因此,如果可能的话,我们建议选择纹理丰富的处理点。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zss4cZLP-1685358106665)(C:\Users\hp\AppData\Roaming\Typora\typora-user-images\image-20230529185902007.png)]](https://img-blog.csdnimg.cn/bd6336733a2f40e2aa477dc232f3285f.png)
社会影响 由于我们的方法可以改变图像的空间属性,因此它可能会被误用于创建一个具有假的姿态、表情或形状的真实人物的图像。因此,任何使用我们的方法的应用程序或研究都必须严格尊重人格权利和隐私规定。
















 506
506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











