






 本文介绍了数值最优化的基础概念,包括最优化问题的数学表述、凸集与凸函数的定义及其性质,以及数值最优化中常用的数学工具如范数、Taylor展开式等。此外还讨论了最优化过程中的必要条件与充分条件。
本文介绍了数值最优化的基础概念,包括最优化问题的数学表述、凸集与凸函数的定义及其性质,以及数值最优化中常用的数学工具如范数、Taylor展开式等。此外还讨论了最优化过程中的必要条件与充分条件。
Numerical Optimization (数值最优化)系列笔记
——前置知识与无约束最优化基础
1. Mathematical Formulation
从数学上来说,最优化问题就是求一个目标函数在其自变量的约束条件下的最大值或最小值。我们用如下的表达式来表示:

这里
ε
\varepsilon
ε 和
τ
\tau
τ 分别是是等式和不等式约束条件的下标数。
学习过程中,均统一为求最小值问题,因为若想求函数f(x)的最大值,可以令g(x)= - f(x),转换成求最小值。
2. 凸集和凸函数
凸函数在最优化问题上占有比较重要的地位,凸函数定义在凸集合上,因此分别写出其概念和性质
1.凸集定义:
设集合 S
∈
\in
∈
R
n
\mathbb{R}^n
Rn,对于
∀
\forall
∀ x ,y
∈
\in
∈ S,有
α
\alpha
αx + (1-
α
\alpha
α)y
∈
\in
∈ S ,其中
α
\alpha
α
∈
\in
∈ [0,1]。
用这种冷冰冰的公式定义好像比较不容易理解,我们从几何上来理解:

这里,若x,y
∈
\in
∈ 凸集,则x,y连线上的所有点都在凸集上。
凸集关于加法、数乘和交集运算都是封闭的。
引理: 设C1,C2
∈
\in
∈
R
n
\mathbb{R}^n
Rn为凸集,
β
\beta
β
∈
\in
∈
R
\mathbb{R}
R,则
(1)C1 + C2 = { x1+ x2 | x1
∈
\in
∈ C1,x2
∈
\in
∈ C2}是凸集。
(2)
β
\beta
βC1 = {
β
\beta
βx | x
∈
\in
∈ C1} 是凸集
(3)C1
∩
\cap
∩ C2 是凸集
2.凸函数定义:
若集合 C
∈
\in
∈
R
n
\mathbb{R}^n
Rn 是非空凸集,函数 f :C
→
\to
→
R
\mathbb{R}
R,对于
∀
\forall
∀ x,y
∈
\in
∈ C,有

这里称 f 为C上的凸函数,若x
≠
\ne
= y严格成立,则称 f 是C集上的严格凸函数。同样,我们从几何上来理解凸函数这一概念:

这里,它的几何定义无非就是连接(x,f(x))和(y,f(y))两点的线段在(
α
\alpha
αx + (1-
α
\alpha
α)y)之上。
3. 范数(NORMS)

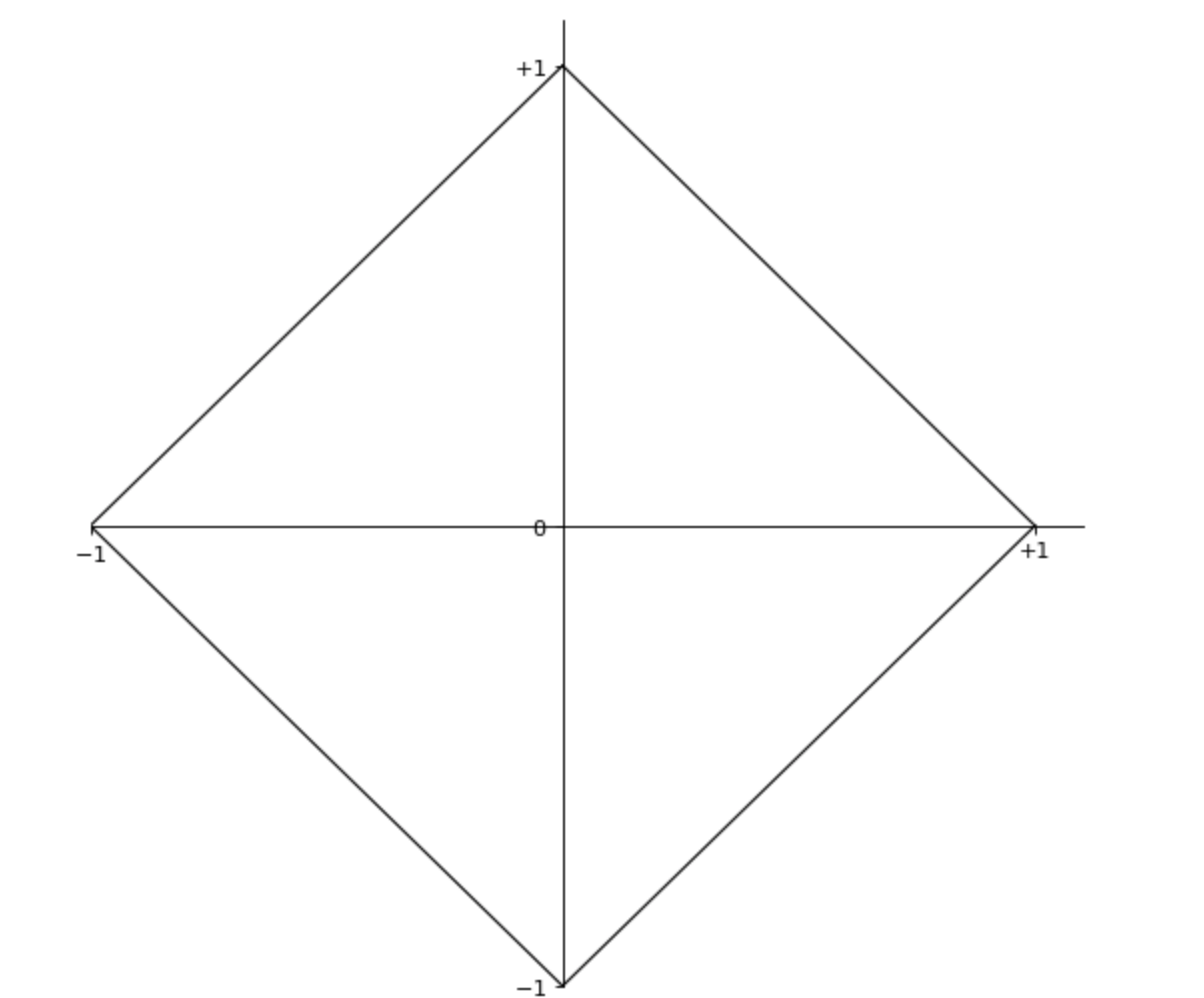
L1,1范数,也称曼哈顿范数,二维空间,范数恰好为1时
L2,2范数,也称欧几里得范数,用来衡量两点的欧氏距离。同理二维空间,范数恰好为1时

4.Taylor展开式
泰勒定理是学习光滑函数时分析数值最优化问题的数学工具,因此尤为重要:

这里给出的是泰勒定理的二阶展开形式。当然这里的前提条件:(1) f 是二次可微的。(2)p
∈
\in
∈
R
n
\mathbb{R^n}
Rn。
倘若你说你把Taylor给忘得差不多了,恭喜解锁以下剧情:

这里给出一篇博客链接:https://blog.csdn.net/qq_38646027/article/details/88014692
假设x*是一个局部最优解,从中我们可以得到最优性的必要条件:
- 第一必要条件:

- 第二必要条件:

即二阶导(Hesse矩阵半正定)。
3. 第二充分条件:

即二阶导(Hesse矩阵正定)。
5.半正定、正定及海瑟矩阵概念
1.Hessian Matrix
是一个自变量位向量的实值函数的二阶偏导组成的方块矩阵。
这里直接援引维基百科的定义:

和百度中的性质:

2.半正定和正定
正定矩阵定义:A是n阶方阵,如果对任何非零向量x,都有
x
T
x^T
xTA x >0,其中
x
T
x^T
xT 表示x的转置,就称A正定矩阵。
正定矩阵具有两个非常重要的性质:1. 行列式恒为正。 2. 特征值均为正。
半定矩阵定义:设A是实对称矩阵。如果对任意的实非零列向量 x 有
x
T
x^T
xTA x≥0,就称A为半正定矩阵。
其对应的两条重要性质:1.半正定矩阵的行列式非负。 2. 半正定矩阵的所有特征值非负。
为了便于理解,这里同样贴出一篇写的较好的博客供大家学习:
https://blog.csdn.net/asd136912/article/details/79146151

















 2649
2649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









