






题目:MedSegDiff: Medical Image Segmentation(图像分割)with Diffusion Probabilistic Model(扩散概率模型)
论文(MIDL会议):MedSegDiff: Medical Image Segmentation with Diffusion Probabilistic Model
源码:MedSegDiff: Medical Image Segmentation with Diffusion Model (github.com)
目录
A. Dynamic Conditional Encoding ( 动态条件编码 )
C. Training and Architecture ( 训练和架构 )
一、摘要
研究背景:扩散概率模型(Diffusion probabilistic model,DPM)是近年来计算机视觉领域研究的热点之一。其图像生成应用如Imagen、Latent Diffusion Models和Stable Diffusion已经显示出令人印象深刻的生成能力,引起了社区的广泛讨论。
主要工作:受DPM成功的启发,本文提出了第一个基于DPM的通用医学图像分割任务模型,命名为 MedSegDiff 。为了增强DPM在医学图像分割中的 step-wise regional attention (逐步区域注意力),提出了动态条件编码,为每个采样步骤建立状态自适应条件。本文进一步提出特征频率分析器(Feature Frequency Parser, FF-Parser),以消除高频噪声分量在此过程中的负面影响。
实验结果:在三个具有不同图像模态的医学分割任务上验证了MedSegDiff,这些医学分割任务是眼底图像上的视神经杯分割、MRI图像上的脑肿瘤分割和超声图像上的甲状腺结节分割。实验结果表明,MedSegDiff优于SOTA方法,但性能差距较大,表明了所提模型的泛化性和有效性。
二、引言
研究背景概述(医学图像分割现实意义、作用 + 当前流行方法的概述)—> 扩散概率模型(DPM)简介(相关工作 + 应用领域) —> 受DPM成功的启发,设计了本文的主要工作:
1. 适应校准过程是获得精细结果的关键。遵循这种思维方式,本文提出动态条件编码,结合普通DPM来设计所提出的模型,称为MedSegDiff。注意,在迭代采样过程中,MedSegDiff 会将图像先验条件应用于每个步骤,以从中学习分割图。 针对自适应区域注意力,本文将在每个步骤中将当前步骤的分割图集成到图像先验编码中。 具体实现是采用多尺度方式将当前步骤的分割掩码与图像先验在特征层面进行融合(动态条件编码实现)。 这样,当前步骤掩码可以帮助动态增强条件特征,从而提高重建精度(建立状态自适应条件)。
2. 为了在该过程中消除给定掩码中的高频噪声,进一步提出了特征频率解析器(FF-Parser),以在傅里叶空间中过滤特征。 FFParser被应用于每个跳连接路径上的多尺度集成。
—> 实验结果 —> 贡献:
- 1. 首次提出了基于dpm的通用医学图像分割模型。
- 2. 针对逐步注意力提出了动态条件编码策略。特征频率解析器(FF-Parser)被提出用于消除高频分量的负面影响。
- 3. 在具有不同图像模态的三个不同医学分割任务上的SOTA性能。
三、方法
本文在扩散模型的基础上设计了本文的模型。扩散模型是由正向扩散和反向扩散两个阶段组成的生成式模型。在正向过程中,通过一系列步骤逐步向分割标签 添加高斯噪声(加噪过程)。在反向过程中,通过反向噪声过程训练神经网络来恢复原始数据(去噪过程),可以表示为:
![]()
扩散模型详解:扩散模型 (Diffusion Model) 之最全详解图解-CSDN博客
扩散模型推导过程全过程概述 + 论文总结:Denoising Diffusion Probabilistic Models 全过程概述 + 论文总结-CSDN博客
推荐课程:大白话AI | 图像生成模型DDPM | 扩散模型 | 生成模型 | 概率扩散去噪生成模型_哔哩哔哩_bilibili
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
核心:Difusion Models 由正向过程(或扩散过程)和反向过程(或逆扩散过程)组成,其中在正向过程中输入数据逐渐被噪声化,然后在反向过程中使用模型预测噪声值,推断出每一步还原图像的概率分布(这个概率分布可以看作图像和高斯噪声的混合成像。由于高斯噪声符合高斯分布,图像与高斯噪声的加性也符合高斯分布),最终实现图像的去噪。如下图所示:
原理:从根本上说,Difusion Models 的工作原理,是通过连续添加高斯噪声来破坏训练数据,然后通过反转这个过程进行去噪,来学习恢复数据。
Q:为什么要这样做?
A:这样做的好处在于,一个训练好的完备的模型可以通过逆向过程从任意的符合
高斯正态分布的纯噪声中生成图像,使得生成样本具有较高的质量和多样性。


模型概述:如上图所示,按照 DPM 的标准实施,采用UNet作为学习网络。为了实现分割,本文用原始图像先验来约束步长估计函数 ϵ,可以表示为:
![]()
其中 是条件特征嵌入,在本文的例子中是原始图像嵌入,
是当前步骤的分割图特征嵌入。将两个分量相加送入 UNet 解码器D进行重构。步骤索引
与添加的嵌入和解码器特征相集成。在这些方法中,都使用共享的学习查找表进行嵌入。
A. Dynamic Conditional Encoding ( 动态条件编码 )
问题:在大多数条件DPM中,条件先验将是唯一的给定信息。然而,医学图像分割因其对象的模糊性而闻名。病变或组织通常很难与其背景区分开来。低对比度的图像模式,如MRI或超声图像,使情况更加糟糕。只给出一个静态图像I作为每个步骤的条件将很难学习。
动机:为解决这个问题,本文为每个步骤提出了一种动态条件编码。注意到,一方面,原始图像包含准确的分割目标信息,但难以与背景区分开,另一方面,当前步骤的分割图包含增强的目标区域,但不准确。这促使本文将当前步骤的分割信息 集成到原始图像编码中,以实现相互补充。
过程:具体来说,实现了特征级的集成。在原始图像编码器中,用当前步骤的编码特征增强其中间特征。将条件特征图 的每个尺度与具有相同形状的
编码特征
进行融合,k 为层的索引。融合通过类似于注意力的机制
实现。特别地,两个特征图首先应用层归一化,并相乘以得到亲和图。然后,将亲和图与条件编码特征相乘,以增强注意力区域,即:
![]()
其中,⊗ 表示元素乘法,LN 表示层归一化。
结构:该操作应用于中间的两个阶段,其中每个阶段都是按照ResNet34实现的卷积阶段。
作用:这种策略有助于MedSegDiff动态地定位和校准分割。
B. FF-Parser ( FF-解析器 )
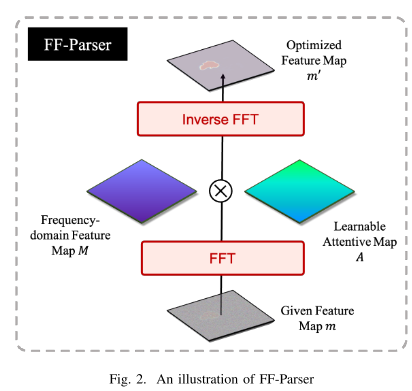
问题:虽然动态条件编码策略很有效,但另一个具体的问题是集成 嵌入会产生额外的高频噪声。为了解决这个问题,该文提出FF-Parser来约束特征中的高频成分。
位置:通过特征集成的路径连接FF-parser。
作用:它的作用是约束 特征中与噪声相关的分量。
思想:主要思想是学习一个参数化的注意力(权重)映射应用于傅里叶空间特征。
过程:给定一个解码器特征映射 ,首先沿着空间维度执行2D FFT(快速傅里叶变换),可以表示为:
![]()
其中 F[·] 表示2D FFT。然后,通过将参数化的注意力映射 乘以 M 来调制 m 的频谱:
最后,通过FFT逆变换将M'变换回空间域:
![]()
Q:快速傅里叶变换是怎么约束特征中的高频成分(高频噪声)的?
A:
C. Training and Architecture ( 训练和架构 )
损失函数:MedSegDiff按照DPM的标准流程进行训练。具体地说,(KL散度)损失可以表示为:
![]()
在每次迭代中,将对原始图像 和分割标签
的随机对进行采样以用于训练(随机种子)。迭代次数从均匀分布中采样, ϵ 从高斯分布中采样。
主要架构:MedSegDiff的主要架构是一个修改后的ResUNet,在UNet解码器之后使用ResNet编码器实现该网络。 和
由两个单独的编码器编码。编码器由三个卷积阶段组成。每个阶段包含多个残差块。每个残差块由两个卷积块组成,每个卷积块由 group-norm 和 SiLU 激活层和一个卷积层组成。残差块通过线性层、SiLU激活和另一个线性层接收时间嵌入。然后将结果添加到第一个卷积块的输出中。得到的
和
相加并发送到最后的编码阶段。最后,一个标准的卷积解码器被连接来预测最终结果。(DPM + 一个ResNet编码器)
四、实验
A. Dataset
任务类型:在三种不同的医学任务上进行了实验,分别是眼底图像中的视杯分割、MRI图像中的脑肿瘤分割和超声图像中的甲状腺结节分割。
样本数量:青光眼、甲状腺癌和黑色素瘤诊断的实验分别在分别包含1200个、2000个和8046个样本的SAURGE-2数据集、BRATS-2021数据集和DDTI数据集上进行。
简要信息:这些数据集是公开提供的,带有分段和诊断标签。训练/验证/测试集按照数据集的默认设置拆分。
B. Implementation Details
扩散步数:在实验中,使用了100个扩散步骤来进行推理,这比以前的大多数研究要小得多。
实验设备:所有的实验都是在PyTorch平台上实现的,并在4个Tesla P40 GPU上进行了训练/测试,内存为24 GB。
预处理:所有图像都被均匀地调整到224×224像素的尺寸。
优化器和批量大小:使用AdamW优化器以端到端的方式训练网络,小批量为30个。学习速率初始设置为1×10−4。
C. Main Results

对比网络:ResUet和Beal用于视盘/杯分割,TransBTS 和 EnSemDiff 用于脑肿瘤分割,MTSeg 和 UltraUNet 用于甲状腺结节分割,CENet、MRNet、SegNet、NUNet和TransUNet用于普通医学图像分割。
评价指标:通过Dice评分和IOU来评估分割性能。
定量对比结果:可以看到MedSegDiff在三个不同的任务上都优于所有其他方法,这表明它对不同的医学分割任务和不同的图像形态具有普适性。与同样采用DPM的脑肿瘤分割方法相比,DICE的分割效率提高了2.3%,IOU的分割效率提高了2.4%,表明了本文所采用的动态条件化技术和FF-Parser技术的有效性。

定性对比分析:目标病变/组织在图像上都是模糊的,因此很难被人眼识别。与其他方法相比,显然该方法生成的分割图比其他方法更准确,尤其是对于模糊区域。
D. Ablation Study

评价指标:dice分数(%)来评估所有三个任务的性能。
从该表中,可以看到DyCond比Vanilla DPM有了相当大的改进。在区域定位比较重要的情况下,如视杯分割,提高了2.1%。对于图像对比度较低的情况,如脑肿瘤和甲状腺结节分割,分别提高了1.6%和1.8%。这表明Dy-Cond对于这两种情况都是一种总体上有效的DPM策略。建立在Dy-Cond上的FF-Parser算法有效地抑制了高频噪声,从而进一步优化了分割结果。它帮助MedSegDiff进一步提高近1%的性能,并在所有三项任务中实现最佳。
五、结论
主要工作:本文提出了一种将DPM方法应用于一般医学图像分割任务的方案—MedSegDiff。提出了两种新的模型:
- 1. 动态条件编码
- 2. FF-Parser
实验效果:对三种不同图像形态的医学图像分割任务进行了对比实验,结果表明该模型的分割效果优于SOTA算法。
展望:作为DPM在普通医学图像分割中的第一个应用,我们相信MedSegDiff将成为未来研究的重要基准。
















 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











