







 文章讨论了神经网络层量化,特别是批归一化层的集成和量化优化,以及如何在PyTorch中使用EagerMode、FXGraphMode和PyTorch2ExportQuantization进行量化。作者还强调了量化过程中需要注意的不同类型层的处理策略和实际的量化示例。
文章讨论了神经网络层量化,特别是批归一化层的集成和量化优化,以及如何在PyTorch中使用EagerMode、FXGraphMode和PyTorch2ExportQuantization进行量化。作者还强调了量化过程中需要注意的不同类型层的处理策略和实际的量化示例。
神经网络层量化
批归一化层Batch Normalization(BN层)
关于归一化的原理可以看之前的这篇blog:BatchNorm原理与应用
批归一化在推理过程中会被融合到上一层或者下一层中,这种处理方式被称为批归一化折叠。这样可以减少量化,也可以减少属于的运算和读写,提高推理速度。
例如对于全连接层
y
=
W
X
+
b
y = WX+b
y=WX+b后的批归一化层:
y
=
B
a
t
c
h
N
o
r
m
(
W
X
+
b
)
=
B
a
t
c
h
N
o
r
m
(
W
X
)
=
γ
(
W
x
−
μ
σ
2
+
ϵ
)
+
β
=
γ
W
x
σ
2
+
ϵ
+
(
β
−
γ
μ
σ
2
+
ϵ
)
=
W
~
X
+
b
~
\begin{align} y& = BatchNorm(WX+b) \\ & = BatchNorm(WX) \\ & = \gamma(\frac{Wx-\mu }{\sqrt[]{\sigma^2+\epsilon } } )+\beta \\ & = \frac{\gamma Wx}{\sqrt[]{\sigma^2+\epsilon } } +(\beta-\frac{\gamma \mu}{\sqrt[]{\sigma^2+\epsilon } }) \\ & = \widetilde{W}X+\widetilde{b} \end{align}
y=BatchNorm(WX+b)=BatchNorm(WX)=γ(σ2+ϵWx−μ)+β=σ2+ϵγWx+(β−σ2+ϵγμ)=W
X+b
从而就将BN层融入到了全连接层的参数中
W
~
k
,
:
=
γ
k
W
k
,
:
σ
k
2
+
ϵ
,
b
~
k
=
β
k
−
γ
k
μ
k
σ
k
2
+
ϵ
.
\begin{aligned} \widetilde{\mathbf{W}}_{k,:}& =\frac{\boldsymbol{\gamma}_k\mathbf{W}_{k,:}}{\sqrt{\mathbf{\sigma}_k^2+\epsilon}}, \\ \widetilde{\mathbf{b}}_{k}& =\boldsymbol{\beta}_k-\frac{\boldsymbol{\gamma}_k\boldsymbol{\mu}_k}{\sqrt{\mathbf{\sigma}_k^2+\epsilon}}. \end{aligned}
W
k,:b
k=σk2+ϵγkWk,:,=βk−σk2+ϵγkμk.
激活函数层
一般线性层之后都会跟一个激活函数层,从底层的角度考虑,如果在线性层计算完后将数据从寄存器放回内存,再取出来进行非线性层计算,这种方法需要进行读取,非常浪费时间,那么是否能考虑把激活函数层也进行量化,让其可以和量化过的线性层同用定点运算,这样就可以不用放回再取出了,可以直接接着运行。激活函数的种类有很多,像ReLU这种比较简单的激活函数,很容易量化,但是像sigmoid这种激活函数就很难量化,需要复杂的支持。如果不能量化,我们需要在激活函数前后各加一个量化器,这样对精度的影响非常大,很多新的激活函数带来的精度提升在量化后会降低很多。
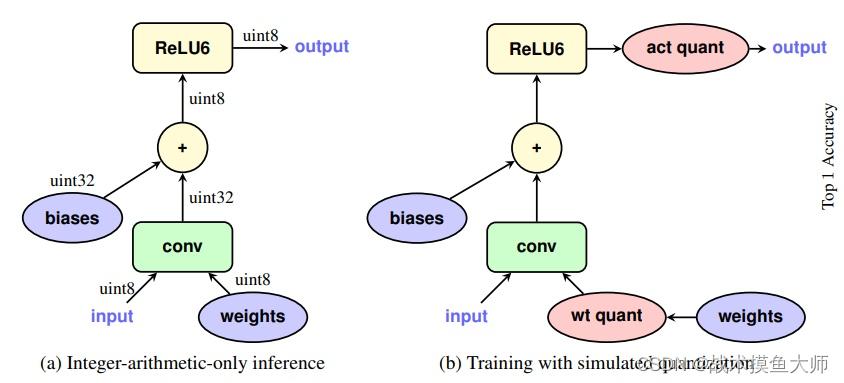
池化层
不同的池化层,量化方法也不同。
对于最大池化,输出就来自输入中的最大值,所以对于activation不需要进行量化。
但是对于平均池化,计算出的平均值不一定是一个整数,所以要对activation进行量化,但是输入和输出的范围是差不多的,所以可以公用一个量化器。
实现
pytorch对于量化提供了三种方案:
- Eager Mode quantization:自己选择量化,自己选择融合
- FX Graph Mode Quantization:提供了自动量化,自动评估,但是跟nn.Module的兼容性需要用户自己负责,比第一种方案自动化程度高一些
- PyTorch 2 Export Quantization:pytorch2.1新引入的量化方案,自动化程度更高,也是pytorch官方推荐新手用的方案。
相关介绍的链接:pytorch官方文档
一个简单训练后静态量化的demo:
import torch
# define a floating point model where some layers could be statically quantized
class M(torch.nn.Module):
def __init__(self):
super().__init__()
# QuantStub 将float tensor转化为量化表示
self.quant = torch.ao.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
self.relu = torch.nn.ReLU()
# DeQuantStub 将量化表示转化为float tensor
self.dequant = torch.ao.quantization.DeQuantStub()
def forward(self, x):
# 自己手动指定量化模型中的量化点
x = self.quant(x)
x = self.conv(x)
x = self.relu(x)
# 自己决定何时将量化表示转化为float tensor
x = self.dequant(x)
return x
model_fp32 = M()
# 模型必须设置为eval模式,以便在量化过程中,模型的行为和量化后的行为一致
model_fp32.eval()
# 模型量化配置,里面包括了默认的量化配置,可以通过`torch.ao.quantization.get_default_qconfig('x86')`获取
# 对于PC端的量化,推荐使用`x86`,对于移动端的量化,推荐使用`qnnpack`
# 其他的量化配置,比如选择对称量化还是非对称量化,以及MinMax还是L2Norm校准技术,都可以在这里指定
model_fp32.qconfig = torch.ao.quantization.get_default_qconfig('x86')
# 手动进行融合,将一些常见的操作融合在一起,以便后续的量化
# 常见的融合包括`conv + relu`和`conv + batchnorm + relu`
model_fp32_fused = torch.ao.quantization.fuse_modules(model_fp32, [['conv', 'relu']])
# 准备模型,插入观察者,观察激活张量,观察者用于校准量化参数
model_fp32_prepared = torch.ao.quantization.prepare(model_fp32_fused)
# 进行校准,这里输入需要使用代表性的数据,以便观察者能够观察到激活张量的分布,从而计算出量化参数
input_fp32 = torch.randn(4, 1, 4, 4)
model_fp32_prepared(input_fp32)
# 将模型转化为量化模型,这里会将权重量化,计算并存储每个激活张量的scale和bias值,以及用量化实现替换关键操作
model_int8 = torch.ao.quantization.convert(model_fp32_prepared)
# 运行量化模型,这里的计算都是在int8上进行的
res = model_int8(input_fp32)
得益于pytorch,onnxruntime,tensorrt等工具,模型量化以及部署已经变得非常简单,但是有些知识我们还是要学,就如闫令琪老师说的:工具的发展可以简化我们工作流程,但是不能简化我们学习的知识,API是API,知识是知识。
觉得有帮助,请点赞+收藏,thanks















 2024
2024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









