







1.论文介绍
Customized Segment Anything Model for Medical Image Segmentation
医学图像分割的自定义分割模型
2023年 arXiv
Paper Code
2.摘要
本文提出SAMed,医学图像分割的一般解决方案。与以往的方法不同,SAMed基于大规模图像分割模型Segment Anything Model(SAM),探索了定制大规模医学图像分割模型的新研究范式。SAMed将基于低秩(LoRA)的微调策略应用于SAM图像编码器,并将其与提示编码器和掩码解码器一起在标记的医学图像分割数据集上进行微调。本文还观察到预热微调策略和AdamW优化器导致SAMed成功收敛和降低损耗。与SAM不同,SAMed可以对医学图像进行语义分割。
Keywords:医学图像分割、SAM、微调
3.Introduction
医学图像分割的目的是根据需要指示相应组织的解剖或病理结构,以便于计算机辅助诊断和智能临床手术。与基于CNN的方法相比,Transformer块的集成使得以全局方式关注和聚合相似特征成为可能,这导致医学图像分割中前所未有的性能。然而,针对特定数据集设计这样的网络需要大量的网络工程。更重要的是,在部署和存储这些模型的特定用途的开销是不可忽略的,由于其相当大的模型大小,这对实际使用提出了巨大的挑战。
如今,人工智能研究界正在经历一场戏剧性的革命。大规模模型的激增,使研究人员能够在统一的框架中解决多种问题。部署这种大规模的模型是更有前途的工业用途的目的,因为他们显着的泛化能力。在医学图像分割领域,如果大规模CV模型,如SAM或SegGPT,可以实现非常有竞争力的性能,这将是没有必要部署一个单一的医学图像分割模型,医学图像分割的解决方案可以直接集成到大规模CV模型。此外,将不需要用于医学图像分割的网络工程的负担,并且用于医学图像分割的单个模型的部署和存储开销也可以大大节省。然而,由于医学图像数据及其相应语义标签的缺乏,大规模CV模型不能直接用于医学图像分割。首先,大规模CV模型根据强度的方差决定不同分割区域之间的边界,这在自然图像中是合理的,但在医学图像中不是,因为解剖或病理结构的分析在医学图像分割中起着关键作用。其次,大规模CV模型无法将分割区域与有意义的语义类别相关联。换句话说,它们不能对医学图像进行语义分割,这阻碍了它们在计算机辅助诊断中的使用。在此基础上,本文探讨了医学图像分割中具有代表性的大规模CV模型SAM(SegmentAnythingModel)的定制方法,并总结出了一些有效的改进策略。我们的方法,SAMed(Segment Anything Model for Medical),是建立在SAM的基础上的,在定制过程中只添加和更新一小部分参数,这意味着SAMed的部署和存储在Segment Anything系统上是微不足道的。
在技术上,我们冻结了图像编码器,并采用基于低秩的微调策略(LoRA)来近似图像编码器中参数的低秩更新,并对SAM的轻量级提示编码器和掩码解码器进行微调。在“vit_B”模式下,更新后的模型大小(18.81 M)仅占原始模型大小(358 M)的5.25%。
如果我们将LoRA应用于图像编码器和掩码解码器,模型大小将进一步减少到6.32M,但性能略有下降。在训练策略方面,我们观察到预热和AdamW优化器可以极大地稳定微调过程,从而提高分割精度。
SAMed可以看作是SAM的一个插件,与SAM完全兼容。在推理过程中,我们只需切换SAMed的更新层,使SAM具有处理医学图像的能力。我们总结了本文的贡献:
- 我们首先扩展SAM,探索其在医学图像分割与语义标签的能力。
- 从性能、部署和存储开销等方面考虑,提出了图像编码器的自适应和一系列的微调策略。
- 我们的方法SAMed在DSC和HD中与以前精心设计的医学图像分割方法相比具有很强的竞争力。
4.网络结构详解
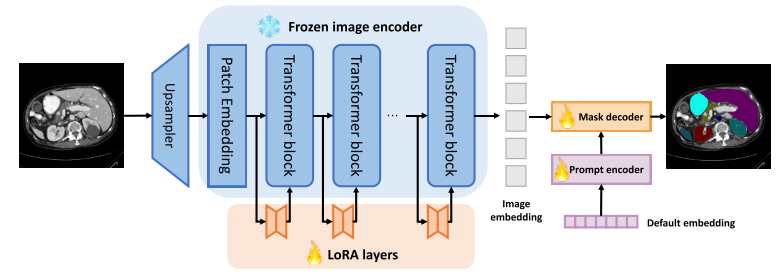
SAMed的框架与SAM一致。冻结图像编码器,并将额外的可训练LoRA层插入SAM以进行医学图像特征提取。此外,我们微调提示编码器与默认的嵌入和掩码解码器,以实现精确的医学图像的语义分割。
给定空间分辨率为H ×W且通道数分别为C的医学图像
x
∈
R
H
×
W
×
C
x ∈ R^{H×W×C}
x∈RH×W×C,我们的目标是预测其对应的具有分辨率H×W的分割图S,其中每个像素属于预定义类别列表
Y
=
y
0
,
y
1
,,
y
k
Y = {y_0,y_1,,y_k}
Y=y0,y1,,yk尽可能地接近真值图S。我们将y_0视为背景类,并且yi,i ∈ {1,.,k}作为不同器官的类别。SAMed的整体架构继承自SAM。
冻结了图像编码器中的所有参数,并为每个Transformer块设计了一个可训练的旁路。如LoRA中所示,这些旁路首先将Transformer特征压缩到低秩空间,并重新投影压缩特征以与冻结的Transformer块中的输出特征的通道对齐。
对于提示编码器,SAMed在推理过程中不需要任何提示即可进行自动分割,极大地有利于自动医疗诊断。我们注意到,如果我们剥离SAM中的所有提示,SAM将更新默认嵌入,因此SAMed也会在训练期间微调此嵌入。
SAM的掩码解码器可以大致分为轻量级Transformer解码器和分段头。在SAMed中,使用LoRA微调Transformer解码器是可选的。如果我们冻结Transformer解码器,并使用LoRA层对其进行微调,但不微调其所有参数,我们可以进一步缩小更新参数的模型大小,以便于部署,但性能会略有下降。SAM的原始分割头输出多个分割模板,解决了分割提示中的歧义问题,这在提示工程中是至关重要的。为了与SAM的原始设计保持一致,SAMed还预测多个分割掩码,但每个掩码表示Y中的一个类,因此SAMed预测k个分割掩码。在SAM之后,预测的分割logit大小h × w小于输入大小,因此我们使用双线性上采样将其与原始输入大小对齐。
图像编码器中的LoRA:
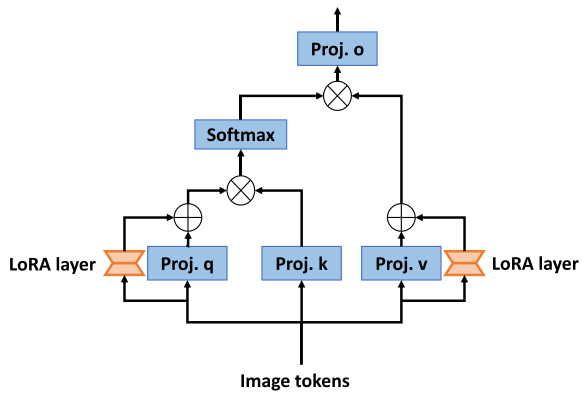
与对SAM中的所有参数进行微调相比,LoRA允许SAM在医学图像训练期间更新一小部分参数,这不仅节省了计算开销,而且在保证分割性能的同时降低了微调模型的部署和存储难度。SAMed中的LoRA策略如上图所示。给定的编码令牌序列 F ∈ R B × N × C i n F ∈ R^{B × N×C_{in}} F∈RB×N×Cin和输出令牌序列 F ∈ R B × N × C o u t F ∈ R^{B×N×C_{out}} F∈RB×N×Cout 由投影层 W ∈ R C o u t × C i n W ∈ R^{C_{out}×C_{in}} W∈RCout×Cin操作,LoRA假设W的更新应该是渐进和稳定的,因此它提出应用低秩近似来描绘这种逐渐更新。
遵循此策略,SAMed首先冻结Transformer层以保持W固定,然后添加旁路以完成低秩近似。该旁路包含两个线性层
A
∈
R
r
×
C
i
n
A ∈ R^{r×C_{in}}
A∈Rr×Cin和
B
∈
R
C
o
u
t
×
r
B ∈ R^{C_{out}×r}
B∈RCout×r,其中
r
<
<
m
i
n
{
C
i
n
,
C
o
u
t
}
r << min\{C_{in},C_{out}\}
r<<min{Cin,Cout}。因此,更新后的层W的处理可以描述为:
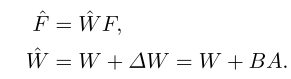
由于多头自注意机制以余弦相似度确定要关注的区域,因此将LoRA应用于查询、键或值的投影层以影响注意力分数是明智的。我们观察到,当我们将LoRA应用于查询和值投影层时,SAMed可以获得更好的性能,因此多头自注意的处理策略将变为:
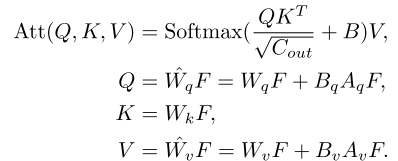
其中Wq、Wk和Wv是来自SAM的冻结投影层,Aq、Bq、Av和Bv是可训练LoRA参数。
LoRA 策略试图通过降低投影层的秩来实现对模型参数的渐进更新,以确保模型更新的稳定性和渐进性。这样可以降低模型参数更新的复杂度,使模型更容易训练和优化。就是在冻结了image encoder,在每个transformer块旁增加LoRA旁路,它就是两个线性层,第一个线性层输出的特征通道数会小于输入的特征和第二个线性层输出的特征,在transformer的query和value上增加。
提示编码器和掩码解码器:
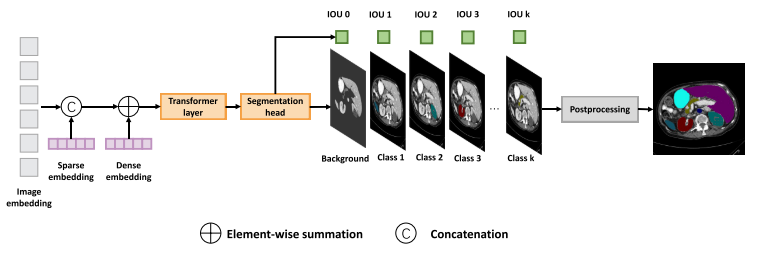
SAMed将稀疏和密集嵌入集成到编码图像嵌入中。经过Transformer层处理后,分别生成每个类的分割图及其IOU。我们采用后处理来聚合这些分割图到最终的分割结果。
为了追求快速和自动化的医疗诊断,SAMed在推理过程中不需要任何提示。由于SAM中的提示编码器在没有提供提示时使用默认嵌入,因此SAMed保留此默认嵌入并使其在微调过程中可训练。SAM中的掩码解码器由一个轻量级的Transformer层和一个分段头组成。可以选择将LoRA应用于这个轻量级的Transformer层,并直接微调分割头或微调掩码解码器中的所有参数。这两种策略在训练和部署开销方面都是可以接受的,后者可能导致更小的模型大小,更容易部署,但性能较低。SAMed对SAM的分割头进行了一些修改,以定制Y中每个语义类的输出。与SAM的歧义预测不同,SAMed以确定性的方式预测Y的每个语义类别。假设有k个用于分割的类,包括1个背景类和对应于每个有意义的医学组织的k-1个类。SAMed的掩码解码器同时预测对应于每个语义标签的k个语义掩码S l ∈ Rh×w×k。最后,预测的分割图被生成为:
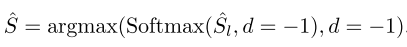
其中d = −1表示Softmax和argmax操作在最后一个维度(通道维度)上执行。
损失函数:
SAMed采用交叉熵和骰子损失来监督微调过程。损失函数可以描述为

其中CE和Dice分别表示交叉熵损失和Dice损失。D表示下采样操作,以使真值图的分辨率与来自SAMed的输出的分辨率相同,因为其空间分辨率低得多。λ1和λ2表示用于平衡这两个损失项之间的影响的损失权重。
Warmup:
SAMed利用指数学习率衰减使训练过程逐渐收敛。学习率调整策略可以描述为:
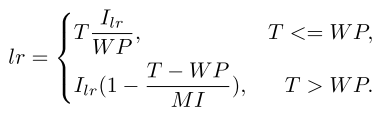
其中Ilr表示初始学习率。T、WP和MI分别表示训练迭代、预热周期和最大迭代。
AdamW优化器。在实验过程中,我们观察到AdamW 优化器与SAMed中的SGD相比导致性能提高。我们将此现象归因于SAM与其医学图像改进版SAMed优化方案的一致性。














 1575
1575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









