







论文链接:https://arxiv.org/abs/2404.07965
以往的语言模型预训练方法对所有训练 token 统一采用 next-token 预测损失。作者认为“并非语料库中的所有 token 对语言模型训练都同样重要”,这是对这一规范的挑战。作者的初步分析深入研究了语言模型的 token 级训练动态,揭示了不同 token 的不同损失模式。利用这些见解,推出了一种名为 RHO-1 的新语言模型。与学习预测语料库中 next-token 的传统 LM 不同,RHO-1 采用了选择性语言建模 (SLM),即有选择地对符合预期分布的有用 token 进行训练。这种方法包括使用参考模型对预训练 token 进行评分,然后对超额损失较高的 token 进行有针对性损失的语言模型训练。
在 15B OpenWebMath 语料库上进行持续预训练时,RHO-1 在 9 项数学任务中获得了高达 30% 的 few-shot 准确率绝对提升。经过微调后,RHO-1-1B 和 7B 在 MATH 数据集上分别取得了 40.6% 和 51.8% 的一流结果——仅用 3% 的预训练 token 就达到了 DeepSeekMath 的水平。此外,在对 80B 一般 token 进行预训练时,RHO-1 在 15 个不同任务中实现了 6.8% 的平均提升,提高了语言模型预训练的效率和性能。
OpenWebMath 是一个数据集,包含互联网上大部分高质量的数学文本。该数据集是从 Common Crawl 上超过 200B 的 HTML 文件中筛选和提取出来的,共包含 630 万个文档,总计 1470B 个词组。OpenWebMath 用于预训练和微调大型语言模型。
介绍
引入了使用新颖的选择性语言建模(SLM)目标训练的 RHO-1 模型。如图 2(右图)所示,这种方法将完整序列输入模型,并有选择性地去除不需要的 token 损失(在 LLM 的 SFT 阶段,我们往往会只训练 BOT 回复,而 instruction 和用户输入的内容不参与训练。在这篇论文中,预训练阶段也对 token 进行抉择,将一些 token 不参与 loss 计算)。
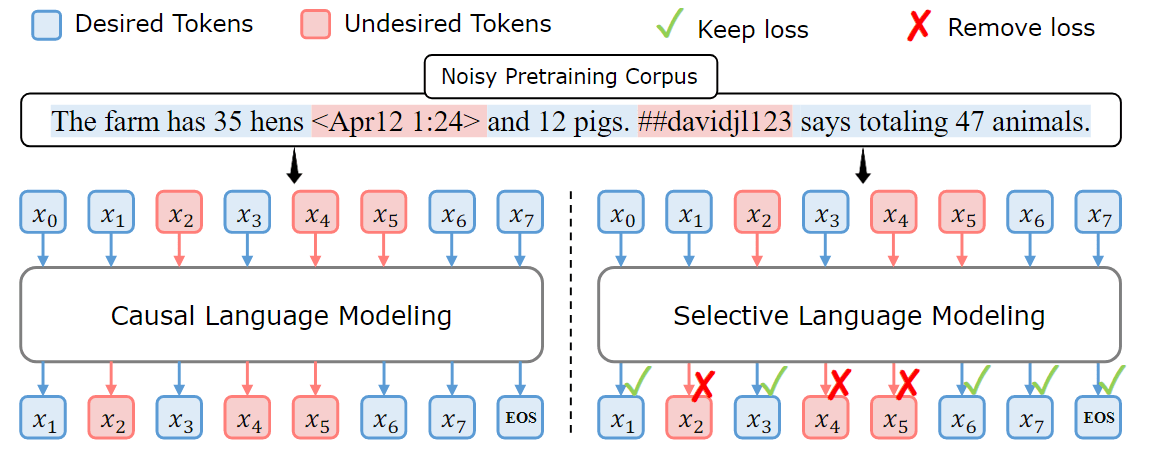
图 2:上部: 即使是经过广泛过滤的预训练语料也包含 token 级噪声。左图:之前的因果语言建模(CLM)对所有 token 进行训练。右图:作者提出的选择性语言建模 (SLM) 可选择性地对有用和干净的 token 参与损失。
方法介绍
并非所有 token 都一样:token loss 的训练动态
首先对标准预训练过程中单个 token 的损失如何演变进行了深入研究。继续使用 OpenWebMath 中的 15B token 对 Tinyllama-1B 进行预训练,每隔 1B token 保存检查点。然后,使用由大约 32 万个 token 组成的验证集来评估这些间隔(相邻检查点之间)的 token 级损失。
图 3(a) 揭示了一个惊人的模式:token 根据其损失轨迹分为四类:持续高损失(H→H),递增损失(L→H),递减损失(H→L)和持续低损失(L→L)。
在训练过程中,作者收集每个 token 在每 1B token 训练数据上训练后的损失。然后,采用线性拟合的方法,将第一个点和最后一个点的损失差值作为训练过程中损失是否减少的证据。具体来说,假设我们有一串 token 损失 l 0 , l 1 , … , l n l_0, l_1, \ldots, l_n l0,l1,…,ln。我们的目标是最小化每个数据点与其线性预测值之间差值的平方和:
f ( a , b ) = m i n i m i z e ∑ i = 0 n ( l i − ( a x i + b ) ) 2 f(a, b) = minimize \sum_{i=0}^n (l_i - (a x_i + b))^2 f(a,b)=minimizei=0∑n(li−(axi+b))2
其中 x 0 = 0 x_0 = 0 x0=0 为初始检查点, x n = n x_n = n xn=n 为最终检查点。将其代入拟合方程,可以得到拟合后开始和结束时的损失值:损失的变化可以表示为 ∆ L = L e n d − L s t a r t ∆L = L_{end} - L_{start} ∆L=Lend−Lstart。同时们用 L m e a n L_{mean} L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









