







1.论文介绍
2.摘要
摘要:Vision Transformer 局部建模效率较低和解码器中特征聚合不足,不利于从难以区分的背景中探测细微线索的伪装目标检测。针对这些问题,本文提出了一种新的基于transformer的特征收缩金字塔网络(FSPNet),其目的是通过渐进收缩对局部增强的相邻Transformer特征进行分层解码,以检测伪装目标。具体地,提出了一种非局部标记增强模块(NL-TEM),该模块利用非局部机制来交互相邻标记,并利用标记内基于图的高阶关系来增强变换的局部表示.此外,设计了一种具有相邻交互模块(AIM)的特征收缩解码器(FSD),该解码器通过逐层收缩金字塔渐进地聚合相邻Transformer特征,以积累尽可能多的不可察觉但有效的线索,用于目标信息解码。
3.网络结构解析
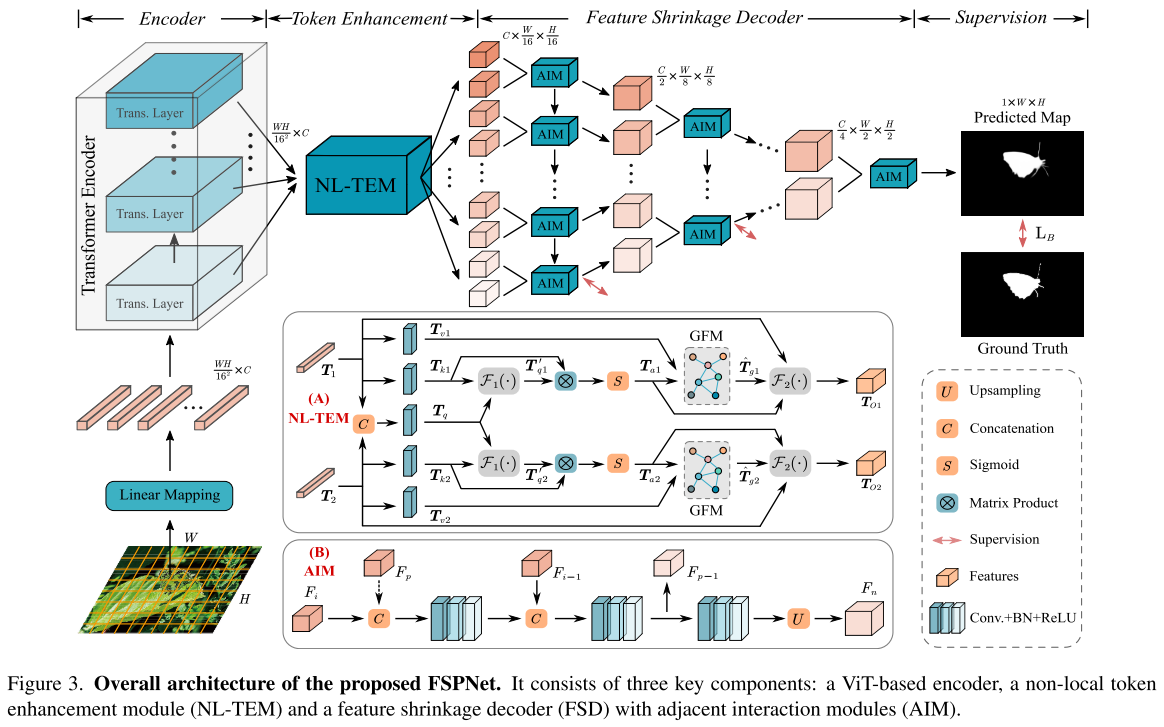
主要组件包括视觉Transformer编码器、非局部令牌增强模块(NL-TEM)和特征收缩解码器(FSD)。具体地,输入图像首先被序列化为令牌作为Transformer编码器的输入,以使用自注意机制来对全局上下文进行建模。然后,为了增强令牌内的局部特征表示,设计了非局部令牌增强模块(NL-TEM),用于令牌间和令牌内的特征交互和探索,并将增强后的令牌从编码器空间转换到解码器空间进行解码。在解码器中,为了尽可能多地合并和保留微妙但关键的线索,我们设计了一个特征收缩解码器(FSD),通过逐层收缩来逐步聚合相邻的特征,以解码对象信息。
编码器:使用vanilla vision transformer (ViT)作为编码器。Transformers带来了强大的全局上下文建模能力,但缺乏在局部区域内进行信息交换的局部机制。
非局部token增强模块NL-TEM:该模块应用于相邻标记(局部区域)以增强局部特征表示。首先采用非局部操作对相邻的相似标记进行交互,以聚集相邻的伪装线索。然后,一个图卷积网络(GCN)的操作,探索高阶语义之间的关系,不同的像素内的令牌,以发现微妙的歧视性功能。
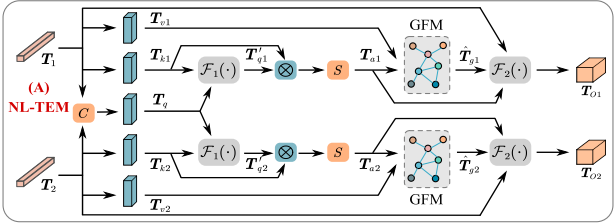
给定来自Transformer编码器的两个相邻令牌T1和T2,它们首先被归一化。以T1为例,它经过两个线性投影函数得到降维后的特征序列Tv和Tk(∈ R1 × c2)。此外,T1和T2被连接以获得集成令牌Tq,该集成令牌Tq聚合两个令牌的特征,然后被利用来与相应的输入令牌交互以进行特征增强。
具体地,对该令牌执行另一线性投影函数wq,其中降维为c/2,然后采用softmax函数来产生权重图Twq。接下来,该映射被用于通过逐元素乘法对Tk进行加权,随后是自适应平均池化操作(P(·))以降低计算成本。上述运算集合F1(·)可以表示为:
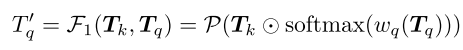
然后,将矩阵乘积应用于Tk和T′ q以探索两者之间的相关性,并且使用softmax运算来生成注意力图Ta,其表示为:
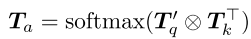
之后,类似于[39],我们将交互式令牌Ta和令牌Tv馈送到图融合模块(GFM)中。在GFM中,Tv通过注意力映射Ta投影到图域中,表示为Tg = Tv <$T a。在这个过程中,具有相似特征的像素(“区域”)的集合被投影到一个顶点,并且采用单层GCN来学习区域之间的高级语义关系,并且通过图上的跨顶点信息传播来推理非局部区域以捕获令牌内的全局表示。具体来说,顶点特征Tg被馈送到谱图卷积的一阶近似中,并且我们可以获得输出Tg:
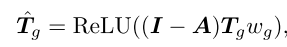
最后,使用跳过连接来将输入令牌T1与基于图的增强表示结合联合收割机,并且然后使用简化(D(·))操作来将令牌序列转换为与原始特征具有相同维度的2D图像特征以用于解码,如图所示:
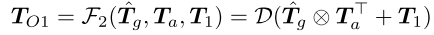
其中TO1 ∈ RC×H s ×W s是来自令牌的输出局部增强特征。同样,我们也可以得到TO2。
这里太繁琐了,甚至代码中更为繁琐。整体就是,12层encoder输出两两一对,入NL-TEM,经过同样的操作。进入后首先经过LayerNorm,再一对的结果cat到一起为Tq,然后与其进行注意力操作。经过一系列叉乘、卷积和AVG之后,进入图卷积(先卷积,然后用聚合后的节点特征减去原节点特征(类似于残差连接)再卷积),最后再残差连接一系列得到最终输出。
特征收缩解码器Feature Shrinkage Decoder:直接聚合具有显著不一致性的特征很容易引入噪声并丢失微妙但有价值的线索。这对于从不显眼的线索中识别隐藏物体的任务来说是非常不友好的。为此,我们设计了一个功能收缩解码器(FSD),逐步聚合相邻的功能对使用分层收缩金字塔架构积累更多的难以察觉的有效线索。
此外,在FSD解码器中,提出了一个相邻的交互模块(AIM),交互和合并当前相邻的功能对和聚合功能输出的前一个AIM,并通过当前聚合功能到下一层和下一个AIM。可以看出,AIM在解码器中充当相邻特征融合和信息传递(在同一层和跨层)的桥梁。

具体来说,假设Fi和Fi-1是当前图层的相邻要素对,Fp是输出聚集的特征,AIM可以公式化为:
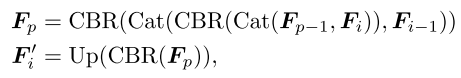
其中Fp是传递到下一个AIM的特征,F′i是当前AIM用于下一层的输出特征。CBR(·)由卷积、批量归一化和ReLU操作组成。Cat(·)和Up(·)分别是级联和2倍上采样操作。
一次聚合操作大概是卷积一个,cat卷积后的和另一个,再卷积。得到结果和特殊上采样版的(卷积、pixelshuffle等等)。
请注意,FSD总共包含4层收缩金字塔和12个AIM。整个FSD过程在补充材料的算法1中进行了总结。
看得我好累。所以FSD有四层金字塔,一共12个AIM,分别是6、3、2、1个。第一层是聚合12个经过处理后的encoder输入,但是在第二个开始就会先把第一个输入cat上一层的结果(不是上采样的),然后得到六对输出。第二层把上采样的那6个聚合了,第二个开始cat上一层的结果(不是上采样的),得到三对输出。第三层同理,只不过少一个,所以第二层cat的还是第一个,得到两对输出。第四层再同理,得到最终结果。
来自最后一个AIM的输出特征在S形和上采样操作之后由地面实况(G)监督,以用于图像对象预测。我们还使用二进制交叉熵损失(Lbce)来监督FSD每一层的输出预测(Pi),并将较小的权重分配给检测精度较低的浅层输出。最后,总损失函数为:
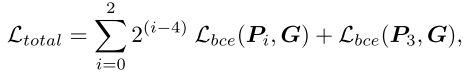
其中,i表示FSD的第i层,P3表示输出预测的最后一层。

















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









