






tf2使用savemodel保存之后转化为onnx适合进行om模型部署
tf保存为kears框架h5文件
前提环境是tf2.2及其版本以上的框架,模型训练结果保存为h5(也就是kears框架)
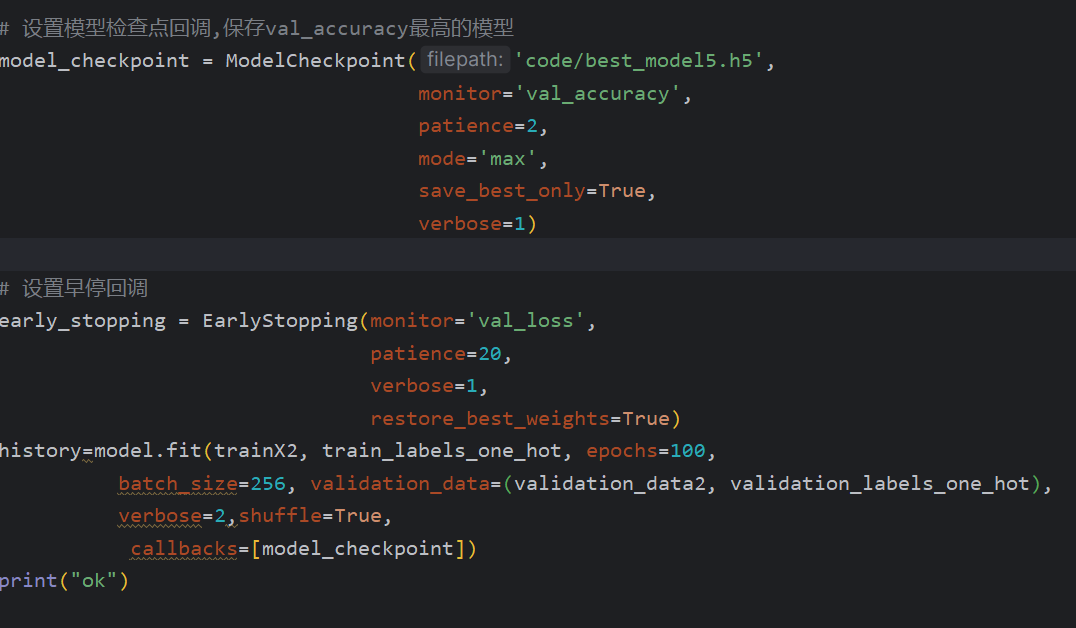
将h5转化为savemodel格式,方便部署
之后将h5文件转化为savemodel的格式
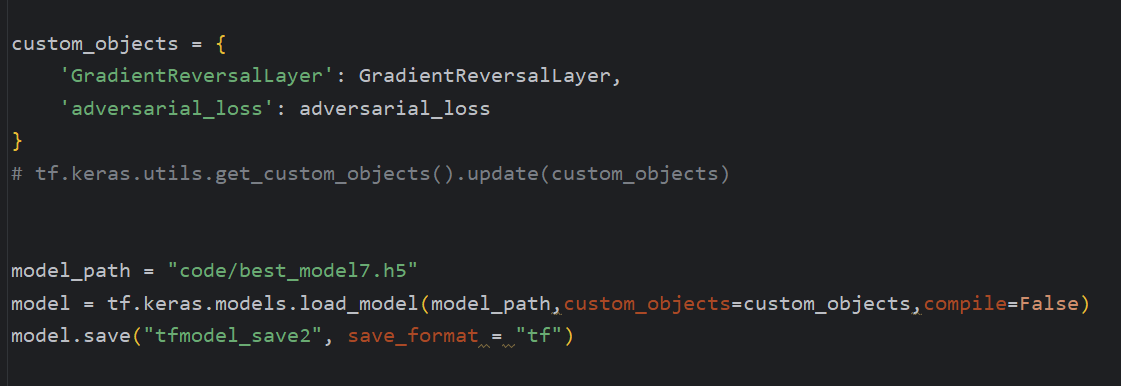
custom是在保存模型的时候需要的自定义函数,如果没有则不需要添加
保存结果如下
这个地方记得验证一下savemodel格式是否能成功搭载测试代码
import os
import pandas as pd
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM,Dense,Dropout
from keras.utils import to_categorical
import tensorflow as tf
from tensorflow.python.keras.layers import Activation
os.chdir('D:/software_project/心电信号分类/')
# 加载 SavedModel 目录
loaded_model = tf.saved_model.load('tfmodel_save')
# 获取默认的服务签名
infer = loaded_model.signatures['serving_default']
print(infer.structured_input_signature)
print(infer.structured_outputs)
# 加载CSV文件
file_path = 'data2/shuffled_merged_data.csv'
data = pd.read_csv(file_path)
from sklearn.preprocessing import StandardScaler
# 创建StandardScaler实例
scaler = StandardScaler()
features = data.iloc[0:1, :-1]
# 获取最后一列作为标签
labels = data.iloc[0:1, -1]
features1 = scaler.fit_transform(features)
# features1 = features1.astype(np.float32)
# # 转化为numpy
# features = features.to_numpy()
trainX3 = features1.reshape((features1.shape[0], features1.shape[1], 1))
# # 将数据转换为Tensor
input_data = tf.convert_to_tensor(trainX3, dtype=tf.float32)
output = infer(conv1d_input=input_data)
output4=output['dense_3']
print(output4.numpy())
# 为了确定每个样本的预测标签,我们找到概率最高的类别的索引
predicted_indices = np.argmax(output4.numpy(), axis=1)
accuracy = accuracy_score(labels, predicted_indices)
print(accuracy)
output2=output["dense_8"]
print(output["dense_8"])
predicted_indices2= np.argmax(output2.numpy(), axis=1)
accuracy2 = accuracy_score(labels, predicted_indices2)
print(accuracy2)
output2_1=output["dense_8_1"]
print(output["dense_8_1"])
predicted_indices2= np.argmax(output2_1.numpy(), axis=1)
accuracy3 = accuracy_score(labels, predicted_indices2)
print(accuracy3)
print('nihao')
# 不可用
# print(output["StatefulPartitionedCall:0"])
查看模型架构
可以使用这个代码查看模型架构,输入输出的名字
saved_model_cli show --dir D:\software_project\心电信号分类\tfmodel_save --tag_set serve --sig
nature_def serving_default
结构如下
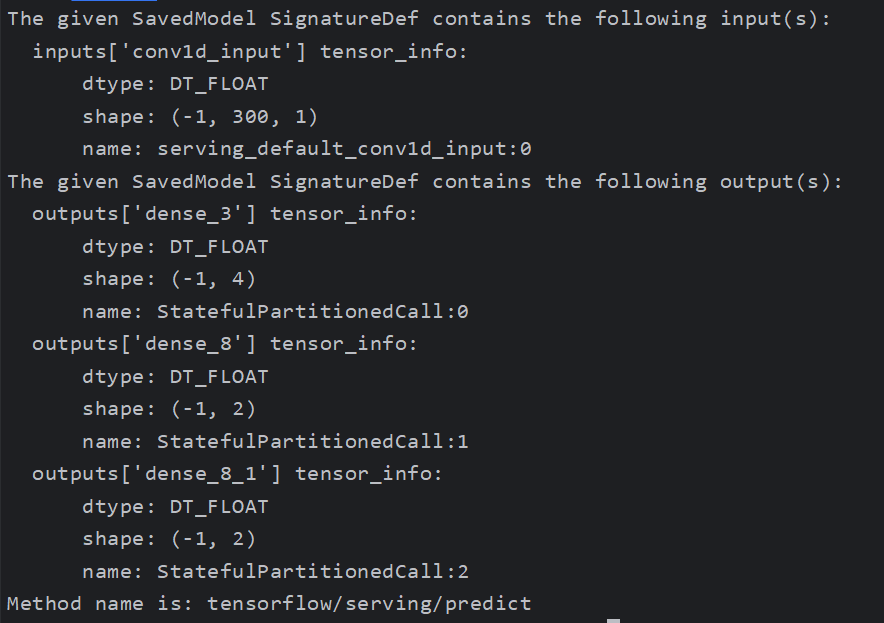
如果可以用咱们继续进行下一步
将savemodel转化为onnx格式
之后将保存的savemodel格式转化为onnx格式
这里直接上大佬博客
在Atlas 200 DK中部署深度学习模型
基本把每个步骤过一遍即可
注意安装tensorflowgpu的版本是很高的

转换指令
python -m tf2onnx.convert --saved-model tensorflow-model-path --output model.onnx
使用netron
把模型放入到netron中
Netron
导出的onnx模型如下
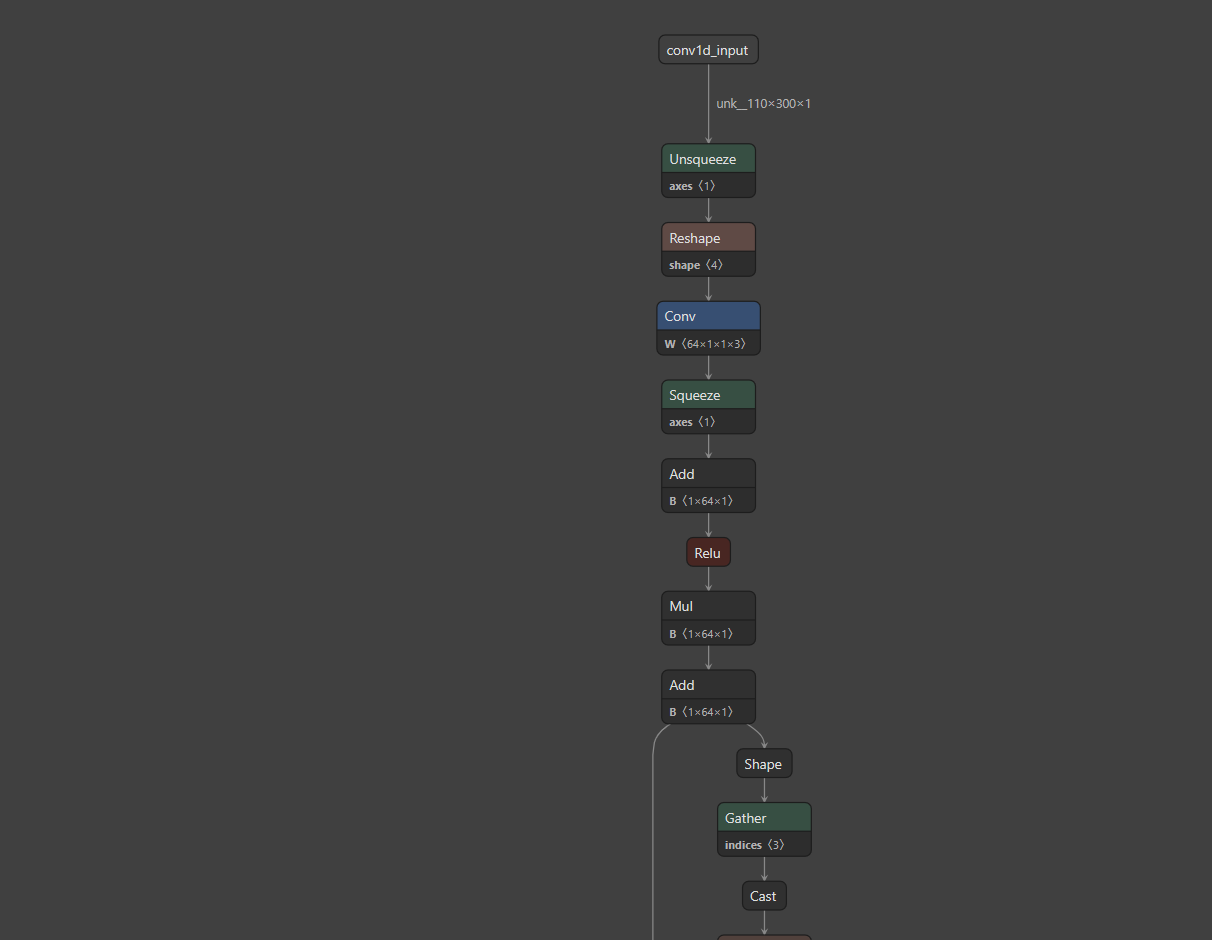
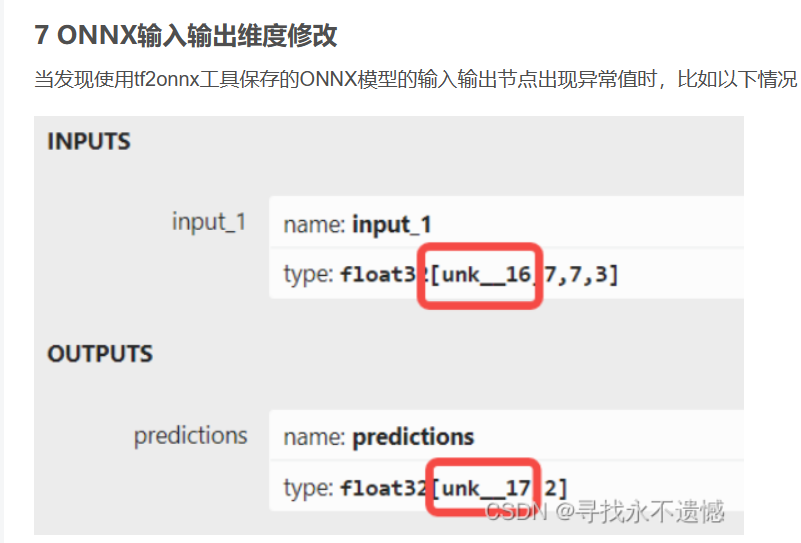
onnx模型细微处理
获得的onnx模型放入netron中进行查看,发现有些未知输出量需要修改
【tensorflow onnx】TensorFlow2导出ONNX及模型可视化教程_tf2onnx-CSDN博客
主要是这种未知量
代码转化为om以及推理代码,要么使用midstudio
之后即可使用代码进行模型的转化为om
转化成功之后,放到atlks200dk板子中进行模型的推理
代码
import numpy as np
import acllite_utils as utils
import constants as const
from acllite_model import AclLiteModel
from acllite_resource import AclLiteResource
import time
import csv
import numpy as np
class Reasoning(object):
"""
class for reasoning """ def __init__(self, model_path):
self._model_path = model_path
self.device_id = 0
self._model = None
def init(self):
"""
Initialize """
# Load model
self._model = AclLiteModel(self._model_path)
return const.SUCCESS
def inference(self, one_dim_data):
"""
model inference """ return self._model.execute(one_dim_data)
def main():
model_path = 'model_dim_replace.om'
# 打开 CSV 文件
with open('shuffled_merged_data.csv', newline='') as csvfile:
# 创建 CSV 读取器对象
csvreader = csv.reader(csvfile, delimiter=',')
# 跳过第一行(标题行)
next(csvreader)
# 读取第二行数据
second_row = next(csvreader)
# 移除最后一个数据
second_row_without_last = second_row[:-1]
# 将数据转换为 NumPy 数组
np_array = np.array(second_row_without_last, dtype=np.float32)
print(np_array.dtype)
# 输出转换后的 NumPy 数组
acl_resource = AclLiteResource()
acl_resource.init()
reasoning = Reasoning(model_path)
# init
ret = reasoning.init()
utils.check_ret("Reasoning.init ", ret)
start_time = time.time()
# 假设你有一个名为 input_data 的 NumPy 数组,它包含模型的输入数据
input_data = np.array([np_array]) # 替换为你的输入数据
result_class = reasoning.inference(input_data)
end_time = time.time()
execution_time = end_time - start_time
print(result_class)
if __name__ == '__main__':
main()















 1582
1582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









