







相信很多朋友都看过这篇论文,在 2023 年 3 月,一支来自中国人民大学的团队,发表了一篇大模型综述《A Survey of Large Language Models》.

如果还是觉得陌生,那么你一定在各类研报、文章等渠道中看过这张图👇,而它就出自这篇综述。
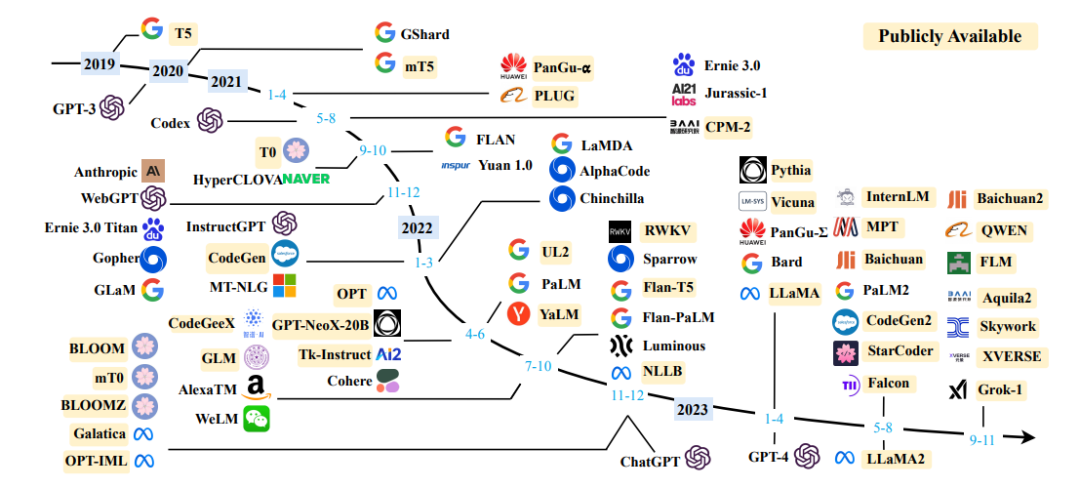

该项目发展历程:
- 综述爆火,如今更新到第 13 个版本,包含了 83 页的正文内容,并收录了 900 余篇参考文献。
论文地址:https://arxiv.org/abs/2303.18223
-
2023 年 8 月发布了该综述(v10)的中文翻译版。
-
在 2023 年 12 月底,为更好地提供大模型技术的中文参考资料,团队启动了中文书的编写工作,并且于 2024 年 4 月 15 日左右完成初稿。
项目地址:https://llmbook-zh.github.io/


该书共 391 页,参考文献共 447 篇,旨在为对大模型技术感兴趣的初学者提供全面介绍,展示整体框架和发展方向。
温馨提示:该书适合有一定深度学习知识的高年级本科生和低年级研究生阅读,可以作为入门大模型技术的首选书籍(已经推荐给身边的学弟学妹了)。

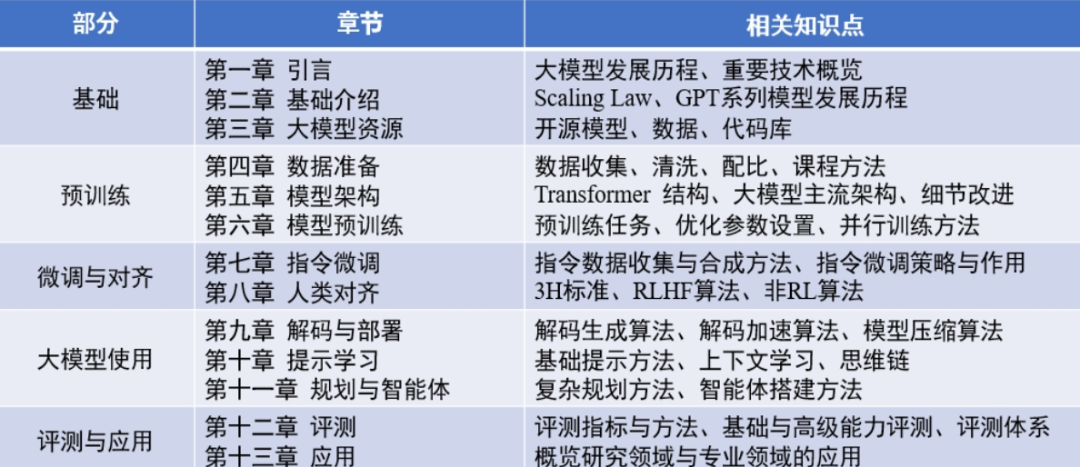
该书一共五大部分,包括大模型基础、大模型预训练、大模型微调、提示词、智能体、大模型在研究/专业领域的应用等。
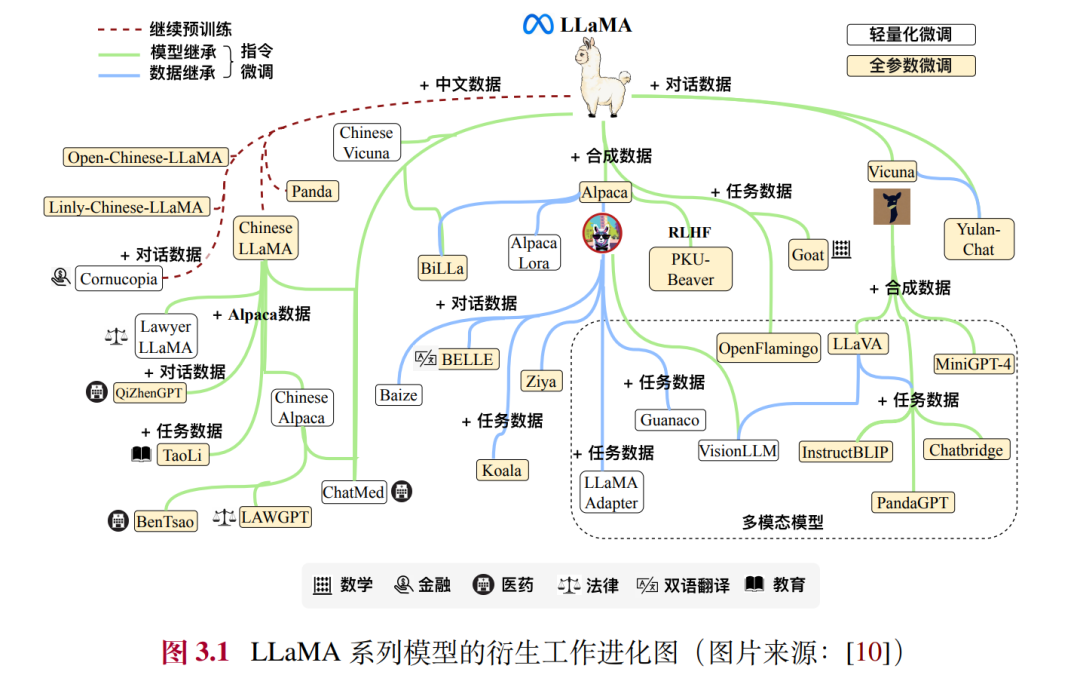
里面有非常多精彩的解读与数据整理,比如 LLaMA 系列模型衍生工作进化图。
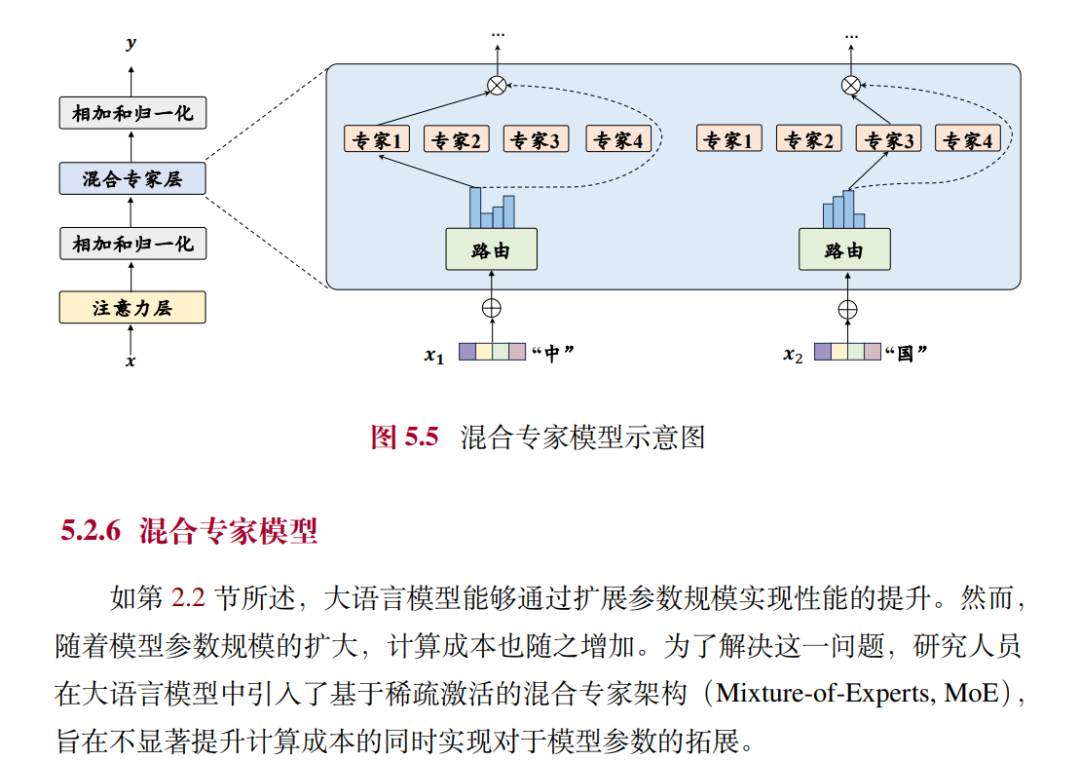
比如混合专家模型的介绍。
也有当下热门的智能体(Agent)相关介绍。

再比如各专业领域内代表性的大语言模型与数据资源。


为了更好地整理和传播大模型的最新进展与技术体系,官方也为读者提供了以下相关资源👇
LLMBox
LLMBox 是一个全面的代码工具库,专门用于开发和实现大语言模型,其基于统一化的训练流程和全面的模型评估框架。LLMBox 旨在成为训练和利用大语言模型的一站式解决方案,其内部集成了大量实用的功能,实现了训练和利用阶段高度的灵活性和效率。
YuLan 大模型
YuLan 系列模型是中国人民大学高瓴人工智能学院师生共同开发的支持聊天的大语言模型(名字”玉兰”取自中国人民大学校花)。最新版本从头完成了整个预训练过程,并采用课程学习技术基于中英文双语数据进行有监督微调,包括高质量指令和人类偏好数据。
希望通过阅读本书,大家能够深入了解大模型技术的现状和未来趋势,为自己的研究和实践提供指导和启发。















 3536
3536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









