







1. labelimg制作数据集
参考机器视觉抓取(2)——Yolov5_v6.0训练自己的数据集 的前半部分,会生成新文件 ,如图

2. xml文件转yolo格式txt文件
如果数据集是多个人一起标注的,请参考labelimg制作数据集+xml文件路径批量修改
将xml中的照片路径替换成正确路径(参考文中有详细说明)
至于为什么更换,我也不清楚,也许不更换也可以,我是怕出现未知错误,就先替换了
完成路径替换后,进行xml转txt,在VOCdata文件夹里新建py文件:xml_to_txt.py
代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import glob
classes = ["bud"]
def convert(size, box):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
# 注意如果是在windows系统下那么路径里的反斜杠\应该多写一个,否则会和python的‘\’产生语义冲突
def convert_annotation(image_name):
in_file = open('E:\\Python_Learn_Source\\YOLO\\yolov5_7.0_Attention_Multiple\\VOCData\\Annotations\\' + image_name[:-3] + 'xml') # xml文件路径
out_file = open('E:\\Python_Learn_Source\\YOLO\\yolov5_7.0_Attention_Multiple\\VOCData\\labels\\' + image_name[:-3] + 'txt', 'w') # 转换后的txt文件存放路径
f = in_file
xml_text = f.read()
root = ET.fromstring(xml_text)
f.close()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if __name__ == '__main__':
filenames = os.listdir('E:\\Python_Learn_Source\\YOLO\\yolov5_7.0_Attention_Multiple\\VOCData\\Annotations\\') # xml文件路径,这样输出的txt文件和xml一一对应
print(len(filenames))
for label_path in filenames:
# print(label_path)
convert_annotation(label_path)
3. 数据集划分train、val、test
根目录下,新建文件夹datasets,如图 :datasets文件夹与VOCdata文件夹同级
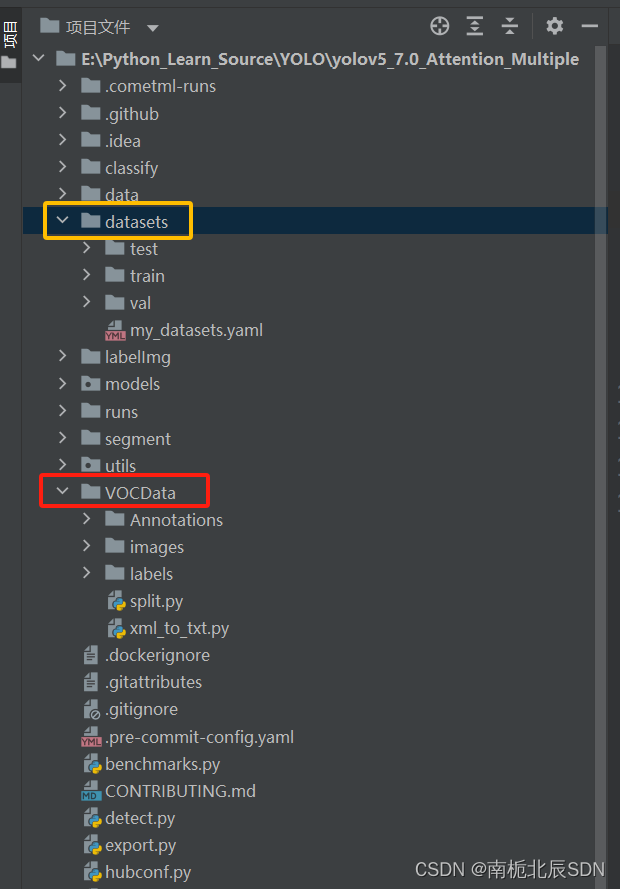
在VOCdata文件夹里新建py文件:split.py
代码如下:
import os
import shutil
import random
# 保证随机可复现
random.seed(0)
# def mk_dir(file_path):
# if os.path.exists(file_path):
# # 如果文件夹存在,则先删除原文件夹在重新创建
# shutil.rmtree(file_path)
# os.makedirs(file_path)
def split_data(file_path, new_file_path, train_rate, val_rate, test_rate):
# yolov5训练自己数据集时 准备了images图片文件夹和txt标签文件夹;但是
# 需要分割训练集、验证集、测试集3个文件夹,每个文件夹有images和labels
# 2个文件夹;此方法可以把imags和labels总文件夹,分割成3个文件夹;
# file_path ='images 文件夹'
# xmlpath= 'txt文件夹'
# new_file_path='保存的新地址'
eachclass_image = []
for image in os.listdir(file_path):
eachclass_image.append(image)
total = len(eachclass_image)
random.shuffle(eachclass_image)
train_images = eachclass_image[0:int(train_rate * total)] # 注意左闭右开
val_images = eachclass_image[int(train_rate * total):int((train_rate + val_rate) * total)] # 注意左闭右开
test_images = eachclass_image[int((train_rate + val_rate) * total):]
#训练集
for image in train_images:
print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
# print(new_path)
shutil.copy(old_path, new_path)
new_name = os.listdir(new_file_path + '/' + 'train' + '/' + 'images')
# print(new_name[1][:-4])
for im in new_name:
old_xmlpath = xmlpath + '/' + im[:-3] + 'txt'
print('old',old_xmlpath)
new_xmlpath1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_xmlpath1):
os.makedirs(new_xmlpath1)
new_xmlpath = new_xmlpath1 + '/' + im[:-3] + 'txt'
print('xml name',new_xmlpath)
if not os.path.exists(f'{old_xmlpath}'):
open(f'{old_xmlpath}', 'w')
shutil.copy(old_xmlpath, new_xmlpath)
#验证集
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
new_name = os.listdir(new_file_path + '/' + 'val' + '/' + 'images')
for im in new_name:
old_xmlpath = xmlpath + '/' + im[:-3] + 'txt'
new_xmlpath1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_xmlpath1):
os.makedirs(new_xmlpath1)
new_xmlpath = new_xmlpath1 + '/' + im[:-3] + 'txt'
if not os.path.exists(f'{old_xmlpath}'):
open(f'{old_xmlpath}', 'w')
shutil.copy(old_xmlpath, new_xmlpath)
#测试集
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
new_name = os.listdir(new_file_path + '/' + 'test' + '/' + 'images')
for im in new_name:
old_xmlpath = xmlpath + '/' + im[:-3] + 'txt'
new_xmlpath1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_xmlpath1):
os.makedirs(new_xmlpath1)
new_xmlpath = new_xmlpath1 + '/' + im[:-3] + 'txt'
if not os.path.exists(f'{old_xmlpath}'):
open(f'{old_xmlpath}', 'w')
shutil.copy(old_xmlpath, new_xmlpath)
print('ok')
if __name__ == '__main__':
file_path = r"E:\Python_Learn_Source\YOLO\yolov5_7.0_Attention_Multiple\VOCData\images"
xmlpath = r'E:\Python_Learn_Source\YOLO\yolov5_7.0_Attention_Multiple\VOCData\labels'
new_file_path = r"E:\Python_Learn_Source\YOLO\yolov5_7.0_Attention_Multiple\datasets"
split_data(file_path, new_file_path, train_rate=0.8, val_rate=0.1, test_rate=0.1)
运行后: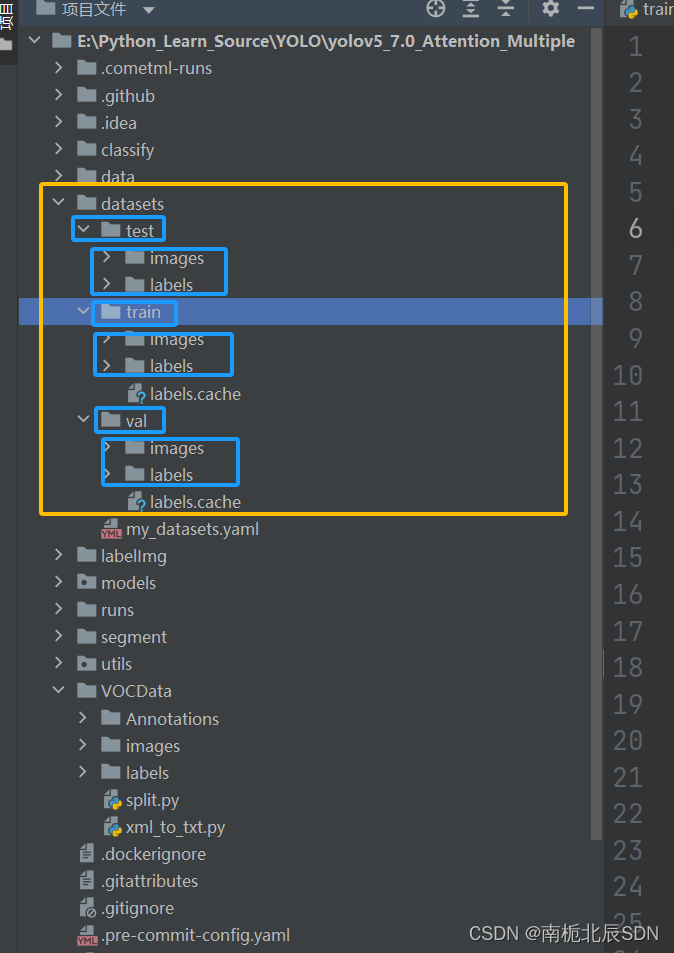
4. 修改数据集yaml文件(易出错)
首先从data文件夹里复制coco128.yaml文件
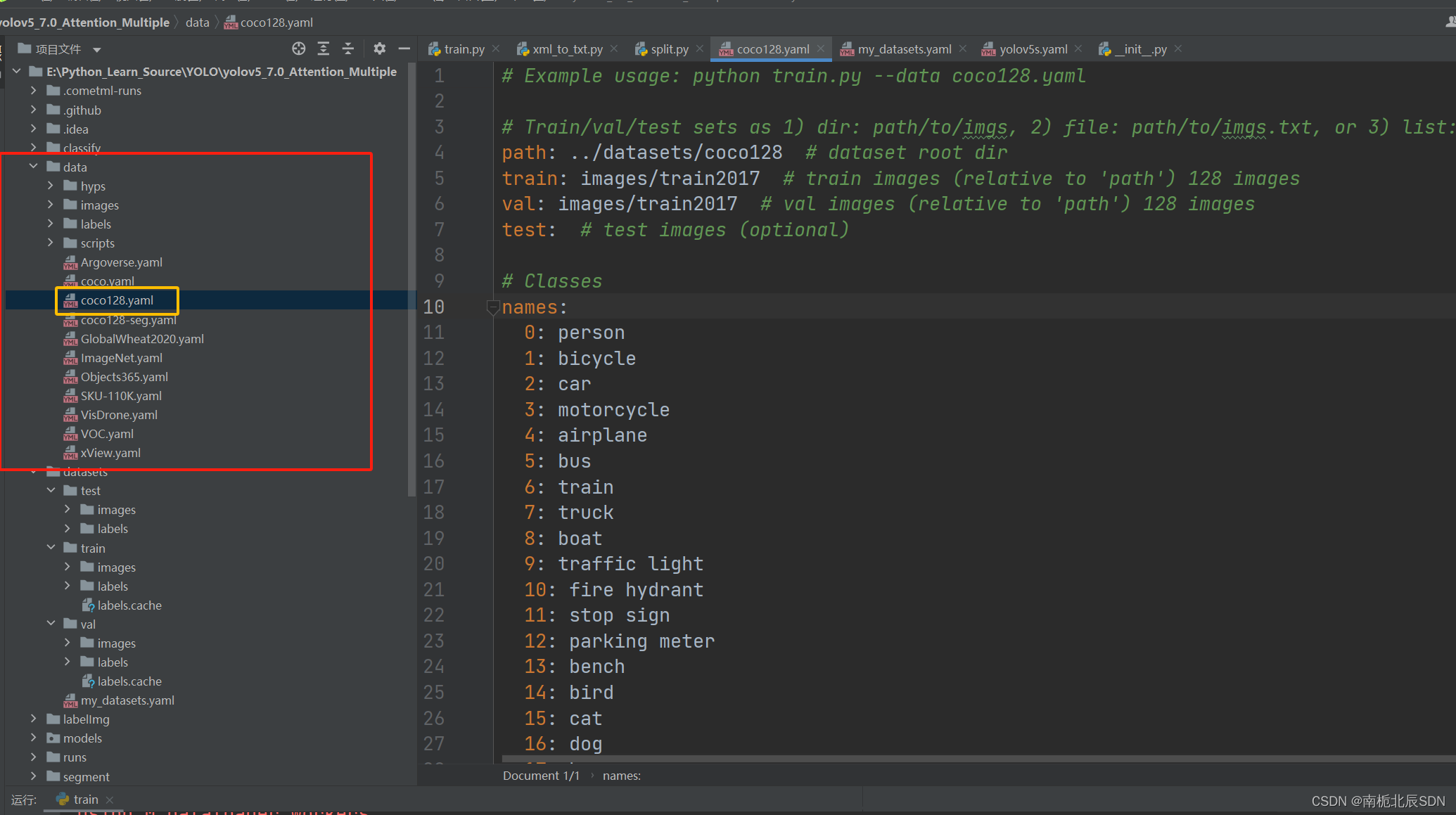
再粘贴到datasets文件夹里,重命名为my_datasets.yaml
修改my_datasets.yaml文件内容(大坑)
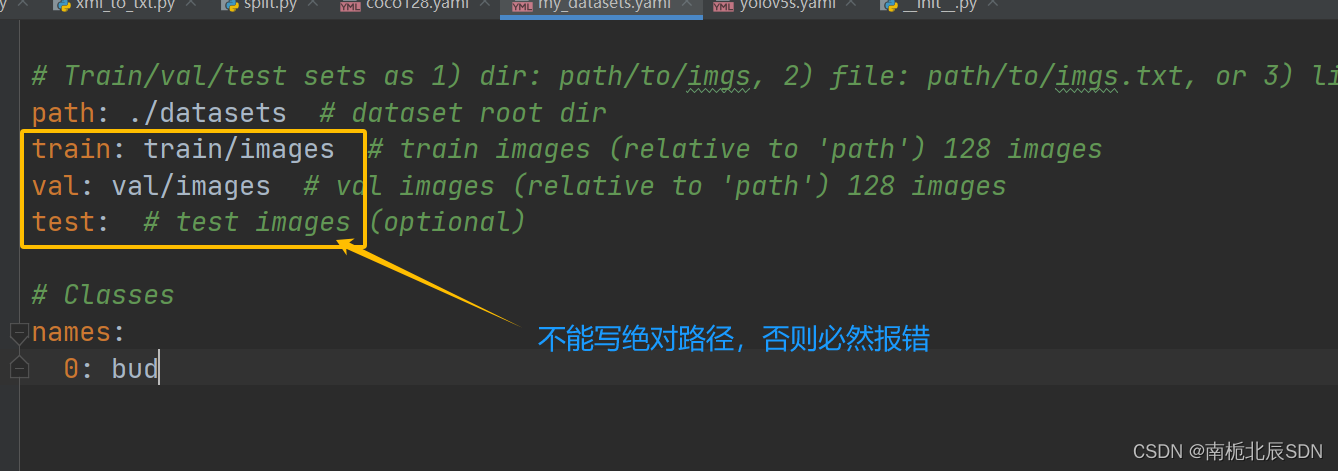
path:数据集文件datasets的跟目录
./表示datasets当前目录 …/表示datasets的父目录
train、val、test 不能写绝对路径,会找不到对应依附的labels而报错
5. 修改模型的yaml文件
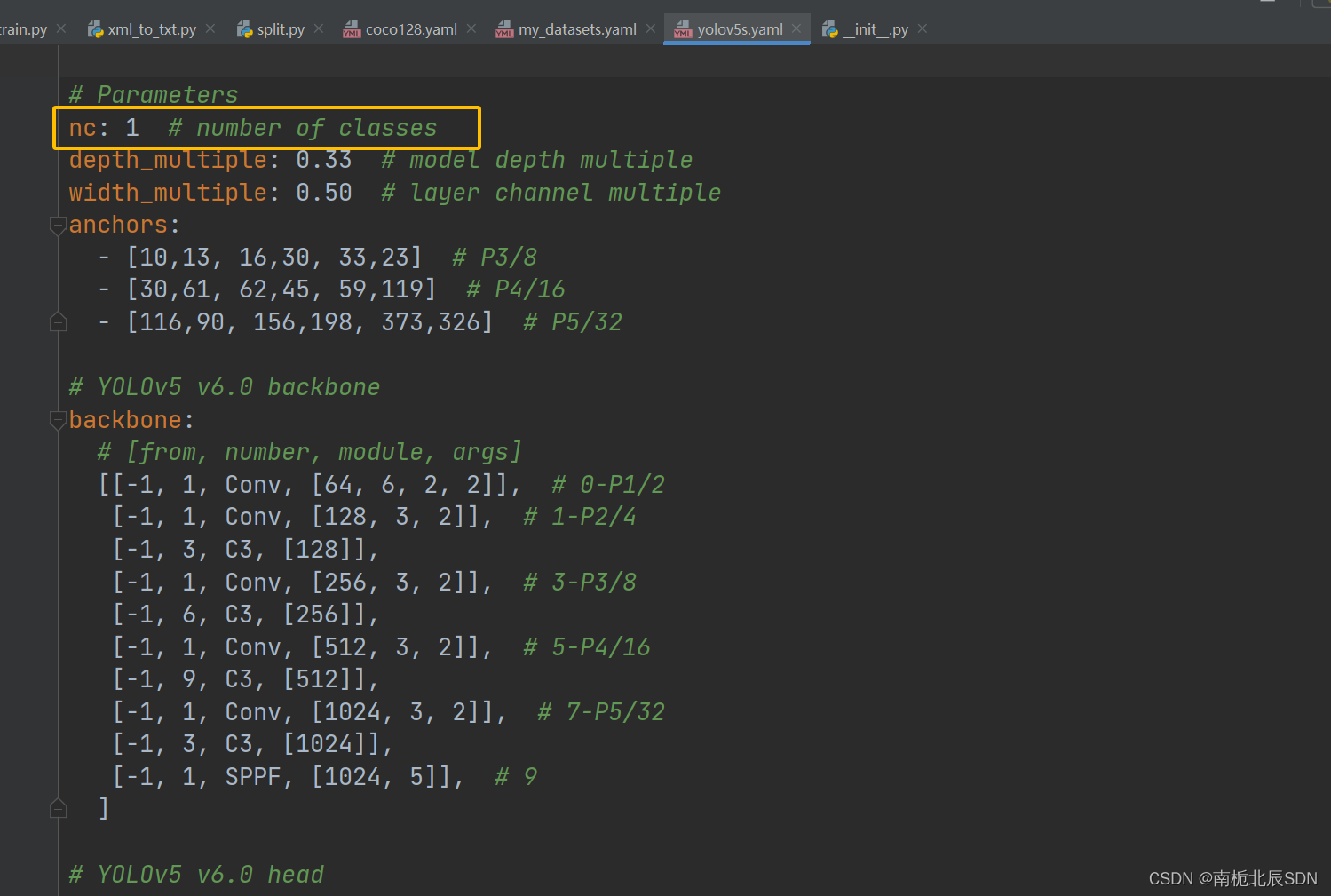
主要修改classes的数量为自己的分类数
6. 修改train.py文件
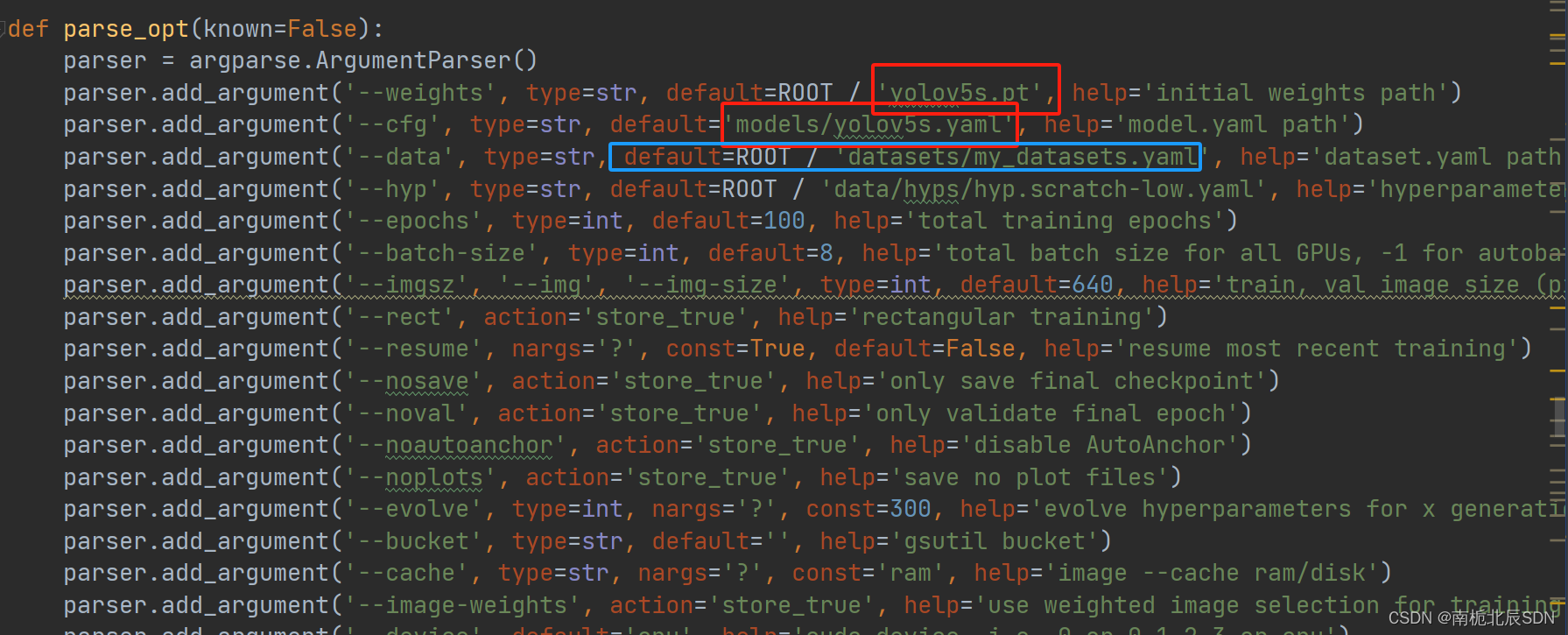
主要替换三个路径:
–weights 权重文件(一般不替换也可)
–cfg 模型框架配置文件(不同改进模型对应不同文件)
–data 数据集的配置文件(包含种类,照片、标签路径)

–name 训练保存模型的文件名(默认exp,建议跟cfg对应)
可以明确每次改进的训练结果,对比不同改进,如图所示。
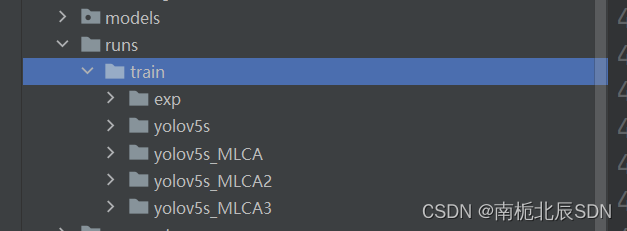
如何进行对比,参考YOLOv5训练损失、精度、mAP绘图功能 | 支持多模型对比,多结果绘在一个图片(消融实验、科研必备)
至此 ,结束,三联哦~~~~~~~

















 6191
6191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











