






论文参考: Dynamic Routing Between Capsules
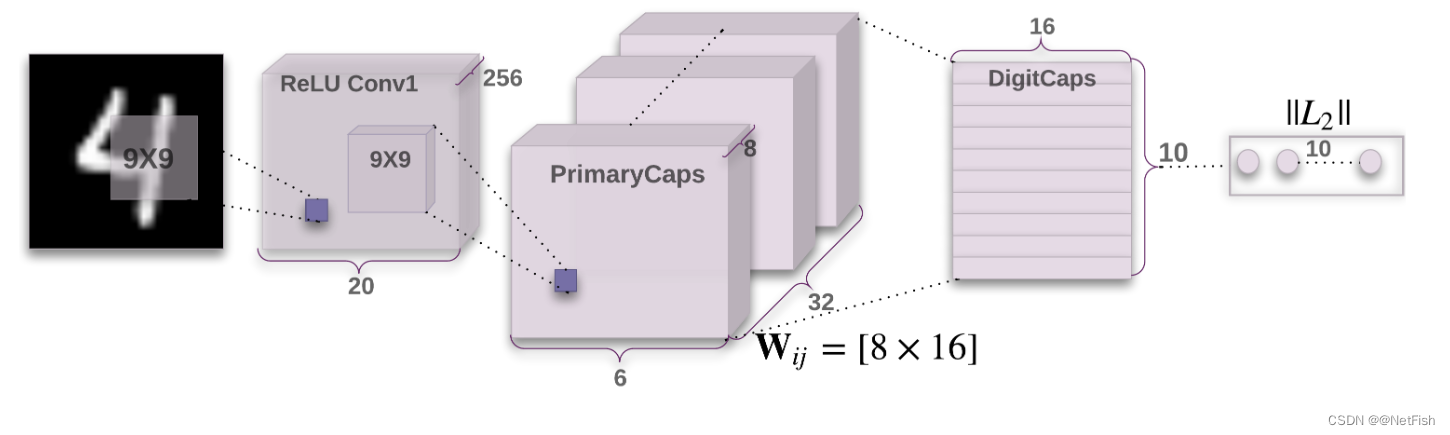
胶囊神经网络基本算法过程
网络输入图像尺寸为 28 × 28 28×28 28×28,网络第一层为卷积层,卷积核大小为 9 × 9 9×9 9×9,深度为1,步幅为1,个数为256(对应卷积后结果为256个通道),卷积结果为 256 × 20 × 20 256×20×20 256×20×20。网络第二层为Primary胶囊层,得到这一层本质上也是进行卷积操作,只是还要对卷积得到的256个通道按胶囊尺寸进行划分,从第一层到Primary胶囊层的卷积核大小为 9 × 9 9×9 9×9,深度为256,步幅为2,个数为256,卷积结果为 256 × ( 6 × 6 ) 256×(6×6) 256×(6×6),然后在根据胶囊大小进行划分,8个通道的特征图为一组,一共32组,每一组有 6 × 6 = 36 6×6=36 6×6=36个胶囊,共有 36 × 32 = 1152 36×32=1152 36×32=1152个胶囊,每个胶囊由处于同一位置不同通道的8个神经元组成。胶囊其实就是一组数据(一组神经元),构成一个向量,每个胶囊可能代表的是一个特征,向量的模长表示为原图存在该特征的概率,向量的方向表示该特征在原图的位姿信息。
从Primary层到Digit胶囊层,对于Digit层中第一个胶囊(向量)的计算,Primary层中的每个胶囊需要乘以权重W,并且再乘以系数c(c的值用一种叫动态路由的算法得到,每个胶囊的c值不共享),然后将得到的值相加,再进行squashing操作(相当于一个非线性激活),最终得到Digit层中的一个胶囊(向量),每个胶囊的权重参数不共享,对于图中的网络而言,Digit层有十个胶囊,那么Primary层中的每个胶囊都有10个权重矩阵。Digit层中10个胶囊(向量)对应于预测的十个数字,向量的长度表示是该数字的概率,胶囊网络特有的损失函数叫Margin Loss,参数c由动态路由算法(Dynamic Routing)更新,权重W用经常使用的反向传播算法更新。
胶囊神经网络中具体算法细节
符号标记定义:Primary层用i标记,Digit层用j标记。 u i u_i ui表示P层(Primary层)的第i个胶囊, W i j W_{ij} Wij表示P层中第i个胶囊到D层(Digit层)的第j个胶囊的权重系数, u ^ j ∣ i \hat{\mathbf{u}}_{j \mid i} u^j∣i表示P层第i个胶囊到D层第j个胶囊时乘以权重之后的值, c i j c_{ij} cij表示P层第i个胶囊到D层第j个胶囊时求和时的系数, b i j b_{ij} bij是计算 c i j c_{ij} cij时的中间量, s j s_j sj表示P层所有胶囊乘以权重乘以系数相加求和后得到的未经squashing操作时得到的向量(此向量对应D层的第j个向量), v j v_j vj表示最终得到的D层中的第j个向量(D层中每一层为一个胶囊向量)。
主要对Primary层到Digit层作算法说明,前面就是普通的卷积操作,所以不做赘述。
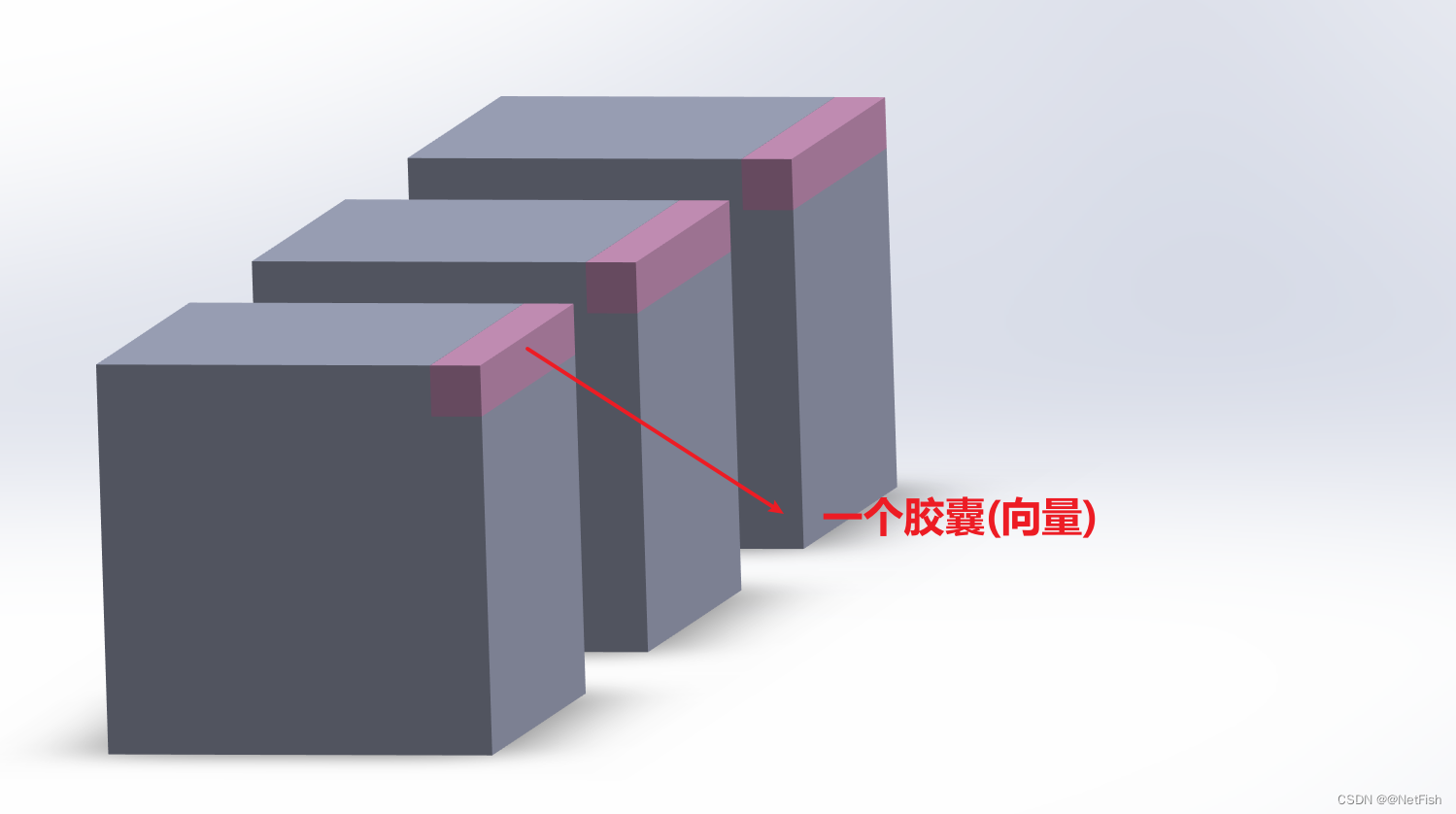
P层的得来其实就是对前面的卷积结果的256个通道进行重新划分,划分依据就是胶囊大小(论文中是1×8,其大小可以看为一个超参数)。划分完之后,
u
i
u_i
ui表示的一个胶囊(向量)如下图所示:
从P层到D层的第j个胶囊需要经过三个步骤:①P层所有胶囊
u
i
u_i
ui乘以各自的权重
W
i
j
W_{ij}
Wij得到
u
^
j
∣
i
\hat{\mathbf{u}}_{j \mid i}
u^j∣i;②
u
^
j
∣
i
\hat{\mathbf{u}}_{j \mid i}
u^j∣i乘以各自的系数
c
i
j
c_{ij}
cij,并求和得到
s
j
s_j
sj;③对
s
j
s_j
sj进行squashing操作最终得到
v
j
v_j
vj。
u
^
j
∣
i
=
W
i
j
u
i
\hat{\mathbf{u}}_{j \mid i}=\mathbf{W}_{i j} \mathbf{u}_i
u^j∣i=Wijui
s
j
=
∑
i
c
i
j
u
^
j
∣
i
\mathbf{s}_j=\sum_i c_{i j} \hat{\mathbf{u}}_{j \mid i}
sj=i∑ciju^j∣i
v
j
=
∥
s
j
∥
2
1
+
∥
s
j
∥
2
s
j
∥
s
j
∥
\mathbf{v}_j=\frac{\left\|\mathbf{s}_j\right\|^2}{1+\left\|\mathbf{s}_j\right\|^2} \frac{\mathbf{s}_j}{\left\|\mathbf{s}_j\right\|}
vj=1+∥sj∥2∥sj∥2∥sj∥sj
其中
W
i
j
W_{ij}
Wij为
m
×
n
m×n
m×n的矩阵,m对应P层胶囊向量的大小,n对应为D层胶囊的大小,因此论文中
m
=
8
,
n
=
16
m=8,n=16
m=8,n=16,计算时所有权重均不共享;系数
c
i
j
c_{ij}
cij由动态路由算法得到,并且齐大小表示该胶囊向量进去下一层的概率,相当于对P层所有向量进入D层某个向量时做了挑选,跟D层的第j个向量相关的被保留其余的被过滤,这解释了为什么胶囊神经网络能不被噪音信息干扰;squashing操作则对原始向量
s
j
s_j
sj进行了一个缩放操作使齐介于01之间,也相当于一个非线性激活;得到的$v_j$就表示了某一个数字的信息,其大小表示该数字存在的概率(因为其大小已经被映射到01了)。
系数 c i j c_{ij} cij的确定之动态路由算法

b i j b_{ij} bij是计算 c i j c_{ij} cij时的中间量,迭代r次,这里 l l l层指的是P层, l + 1 l+1 l+1层指的使D层。算法示例是用P层所有的胶囊向量,计算D层中第j个向量时的过程(这里j可看作是一个固定值)。
首先初始化
b
i
j
b_{ij}
bij都为0,然后进行r次迭代更新。用
s
o
f
t
m
a
x
(
b
i
)
softmax(b_{i})
softmax(bi)得到
c
i
c_i
ci(这里脚标没有j是因为j在这里是固定值),使用softmax操作保证所有
c
i
c_i
ci之和为1,那么
c
i
c_i
ci就可代表为P层中第i个向量进入下一层时的概率,将对D层第j个向量有用的向量挑选出来,并非将P层所有向量都送入下一层。
c
i
j
=
exp
(
b
i
j
)
∑
k
exp
(
b
i
k
)
c_{i j}=\frac{\exp \left(b_{i j}\right)}{\sum_k \exp \left(b_{i k}\right)}
cij=∑kexp(bik)exp(bij)
更新操作
b
i
j
←
b
i
j
+
u
^
j
∣
i
⋅
v
j
b_{i j} \leftarrow b_{i j}+\hat{\mathbf{u}}_{j \mid i} \cdot \mathbf{v}_j
bij←bij+u^j∣i⋅vj中向量乘法
u
^
j
∣
i
⋅
v
j
=
∥
u
^
j
∣
i
∥
⋅
∥
v
j
∥
⋅
cos
θ
\hat{\mathbf{u}}_{j \mid i} \cdot \mathbf{v}_j=\left \| \hat{\mathbf{u}}_{j \mid i} \right \| \cdot \left \| \mathbf{v}_j \right \| \cdot \cos \theta
u^j∣i⋅vj=
u^j∣i
⋅∥vj∥⋅cosθ 可理解为与最终的和向量
v
j
v_j
vj越接近的
u
^
j
∣
i
\hat{\mathbf{u}}_{j \mid i}
u^j∣i(大小、方向),其乘积后的值也就越大(反之就越小),那么下次迭代时
b
i
j
b_{ij}
bij越大,相应
c
i
c_i
ci也就越大,那么其进入下一层的概率也就越大,也就是说
u
i
u_i
ui这个向量被挑选出来。根据此规则在训练一个epoch时迭代r次更新
c
i
c_i
ci。
W i j W_{ij} Wij训练时的损失函数之Margin Loss
边界损失函数:设有一个阈值,超过阈值有损失,低于阈值无损失(或相反)
L
k
=
T
k
max
(
0
,
m
+
−
∥
v
k
∥
)
2
+
λ
(
1
−
T
k
)
max
(
0
,
∥
v
k
∥
−
m
−
)
2
L_k=T_k \max \left(0, m^{+}-\left\|\mathbf{v}_k\right\|\right)^2+\lambda\left(1-T_k\right) \max \left(0,\left\|\mathbf{v}_k\right\|-m^{-}\right)^2
Lk=Tkmax(0,m+−∥vk∥)2+λ(1−Tk)max(0,∥vk∥−m−)2
L
k
L_k
Lk表示D层第k个向量的损失,
T
k
T_k
Tk为当前D层中第k个向量对应的标签(比如输入图片为4时,那么D层第5个胶囊的标签为1,其余为0);
λ
\lambda
λ为计算系数(超参数);
m
+
m^{+}
m+和
m
−
m^{-}
m−为设置的阈值(超参数),文中
m
+
=
0.9
,
m
−
=
0.1
m^{+}=0.9,m^{-}=0.1
m+=0.9,m−=0.1;设输入图片为4,
k
=
5
k=5
k=5时,那么
T
k
=
1
T_k=1
Tk=1,按照公式后半部分为0,只剩
L
k
=
max
(
0
,
m
+
−
∥
v
k
∥
)
2
L_k=\max \left(0, m^{+}-\left\|\mathbf{v}_k\right\|\right)^2
Lk=max(0,m+−∥vk∥)2,当
∥
v
k
∥
>
0.9
\left\|\mathbf{v}_k\right\|>0.9
∥vk∥>0.9时,则
L
k
=
0
L_k=0
Lk=0,不计算损失,当
∥
v
k
∥
<
0.9
\left\|\mathbf{v}_k\right\|<0.9
∥vk∥<0.9时,
L
k
>
0
L_k>0
Lk>0,计算损失,意义为:使D层预测对应数字的向量模长大于0.9;当
k
≠
5
k≠5
k=5时,那么
T
k
=
0
T_k=0
Tk=0,按照公式前半部分为0,只剩
L
k
=
λ
(
1
−
T
k
)
max
(
0
,
∥
v
k
∥
−
m
−
)
2
L_k=\lambda\left(1-T_k\right) \max \left(0,\left\|\mathbf{v}_k\right\|-m^{-}\right)^2
Lk=λ(1−Tk)max(0,∥vk∥−m−)2,当
∥
v
k
∥
>
0.1
\left\|\mathbf{v}_k\right\|>0.1
∥vk∥>0.1时,则
L
k
>
0
L_k>0
Lk>0,计算损失,当
∥
v
k
∥
<
0.1
\left\|\mathbf{v}_k\right\|<0.1
∥vk∥<0.1时,
L
k
=
0
L_k=0
Lk=0,不计算损失,意义为:使D层与预测数字不对应的向量的模长小于0.1;经过迭代后,输入数字时,D层与其对应的向量的模长大于0.9(即概率大于0.9),于其不对应的向量的模长小于0.1(概率小于0.1),从而可以正确识别输入数字。














 7039
7039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









