






【10大专题,2.8w字详解】:从张量开始到GPT的《动手学深度学习》要点笔记
K折交叉验证
K折交叉验证是一种评估模型性能的常用方法,特别是在数据量较少的情况下。这种方法将数据集分为K个不重叠的子集,每个子集大致具有相同的大小。然后,模型会进行K次训练和验证。在每次迭代中,模型会在K-1个子集(即训练集)上进行训练,并在剩下的一个子集(即验证集)上进行验证。这样,每个子集都有一次机会作为验证集,其余次数作为训练集。
K折交叉验证的主要优点是,它允许模型在多个不同的训练和验证集上进行训练和验证,这有助于提供对模型性能更稳健的估计。此外,它还允许我们使用所有的数据进行训练和验证,这在数据量较少的情况下特别有用。
欠(过)拟合
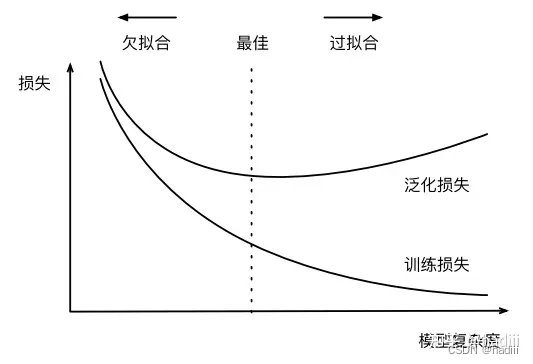
- 欠拟合(Underfitting):当模型无法充分捕获数据中的模式和关系时,我们称模型为欠拟合。
- 过拟合(Overfitting):当模型过度学习训练数据中的模式和噪声,以至于在新的、未见过的数据上表现不佳时,我们称模型为过拟合。
模型复杂性和数据集大小确实是影响模型过拟合和欠拟合的两个重要因素:
- 模型过于复杂可能导致过拟合,过于简单可能导致欠拟合。
- 数据集过小可能导致过拟合,而更大的数据集通常可以帮助模型更好地学习和泛化,减少过拟合。
模型复杂度对欠拟合和过拟合的影响
- 一般通过观察模型在训练集和验证集(或测试集)上的表现来判断模型是否出现欠拟合或过拟合。
- 如果模型在训练集和验证集上的表现都不好,那么模型可能出现了欠拟合。这意味着模型可能过于简单,无法捕获数据中的所有相关模式。
- 如果模型在训练集上表现很好,但在验证集上表现差,那么模型可能出现了过拟合。这意味着模型可能过于复杂,或者过度学习了训练数据中的噪声和异常值。
为了解决欠拟合和过拟合,我们可以尝试更换模型、调整模型复杂度、增加更多的训练数据、使用正则化技术、早停等策略。
权重衰退(weight decay)
权重衰减是一种正则化技术,用于防止模型过拟合。这种技术通过在模型的损失函数中添加一个惩罚项来实现,这个惩罚项与模型权重的平方值(L2范数)成正比。因而也被称为L2正则化。使用L2范数的一个原因是它对权重向量的大分量施加了巨大的惩罚。这使得我们的学习算法偏向于在大量特征上均匀分布权重的模型。如果使用L1惩罚则可能导致模型将权重集中在一小部分特征上,而将其他权重清除为零。
L ( w , b ) + λ 2 ∥ w ∥ 2 L(w, b) + \frac{\lambda}{2} \|w\|^2 L(w,b)+2λ∥w∥2
权重衰减的具体实现方式是在更新权重参数时,除了减去梯度之外,还要减去 λ \lambda λ乘以当前权重。这就使得权重在每次更新时都会衰减一部分,因此得名"权重衰减"。注意L2正则化回归的小批量随机梯度下降更新表达式的(1- η λ \eta\lambda ηλ)部分。
w ← ( 1 − η λ ) w − η ∣ B ∣ ∑ i ∈ B x ( i ) ( w ⊤ x ( i ) + b − y ( i ) ) w \leftarrow (1 - \eta\lambda)w - \frac{\eta}{|B|}\sum_{i \in B}x^{(i)}(w^{\top}x^{(i)} + b - y^{(i)}) w←(1−ηλ)w−∣B∣ηi∈B∑x(i)(w⊤x(i)+b−y(i))
暂退法(dropout)
暂退法的原始论文提到了一个关于有性繁殖的类比:神经网络过拟合与每一层都依赖于前一层激活值相关,称这种情况为“共适应性”。作者认为,暂退法会破坏共适应性,就像有性生殖会破坏共适应的基因一样。
Dropout是一种在深度学习中常用的正则化技术,主要用于防止过拟合。其基本思想是在训练过程中,随机丢弃一部分神经元(即设置其输出为0),在当前迭代中不参与前向传播和反向传播的过程。以减少神经元之间的复杂共适应关系,增强模型的泛化能力。
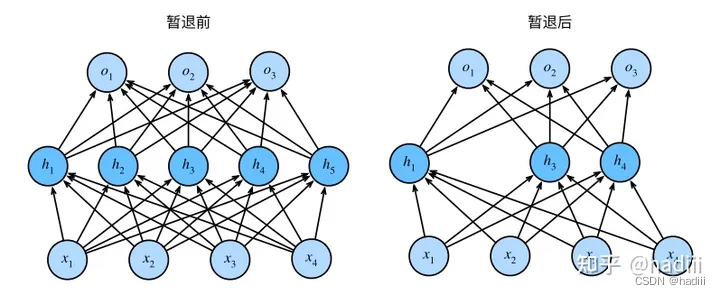
在标准dropout正则化中,通过按保留(未丢弃)的节点的分数进行规范化来消除每一层的偏差。换句话说,每个中间激活值 h h h以dropout概率 p p p由随机变量 h ′ h' h′替换,如下所示:
h ′ = { 0 概率为 p h 1 − p 其他情况 h' = \begin{cases} 0 & \text{概率为} \ p \\ \frac{h}{1-p} & \text{其他情况} \end{cases} h′={01−ph概率为 p其他情况
根据此模型的设计,其期望值保持不变,即 E [ h ′ ] = h E[h'] = h E[h′]=h。
暂退法仅在训练期间使用。在训练时,Dropout层将根据指定的暂退概率随机丢弃上一层的输出(相当于下一层的输入)。在测试时,Dropout层仅传递数据。
net = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
# 在第一个全连接层之后添加一个dropout层
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
# 在第二个全连接层之后添加一个dropout层
nn.Dropout(dropout2),
nn.Linear(256, 10)
)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









