









论文阅读之 Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
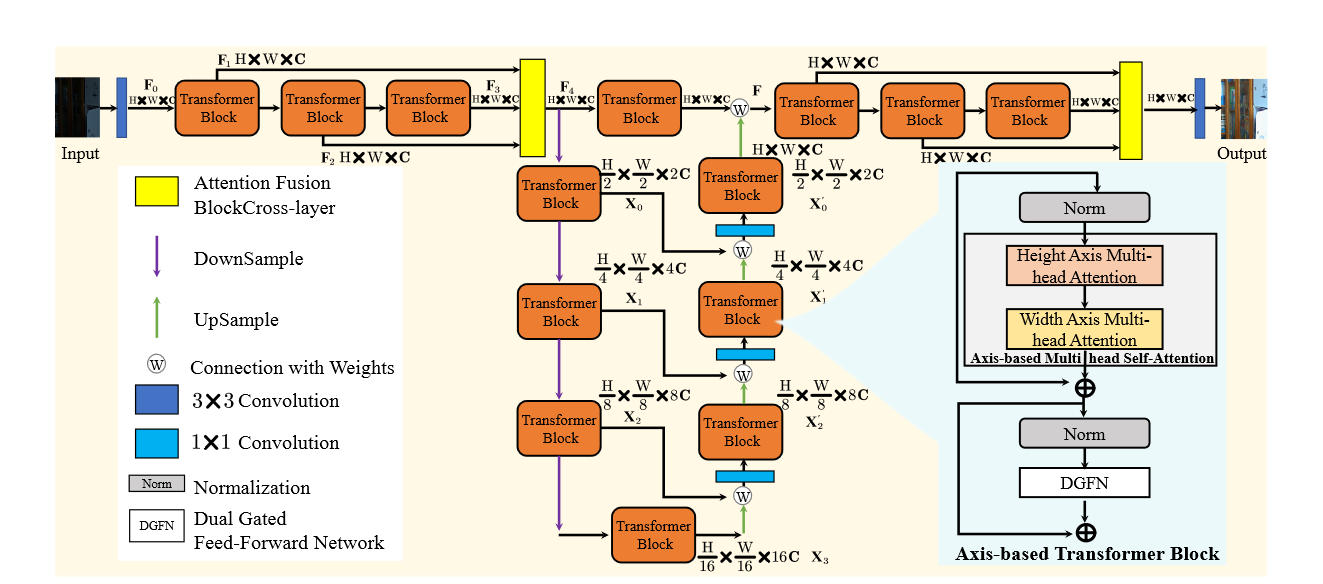
本文的创新点:
-
提出一个新的数据集(大型数据库组成的图像分辨率4 k和8 k)
-
我们进行系统的基准研究和提供一个当前LLIE算法的比较。作为第二贡献,比起我们介绍LLFormer的基于变压器光线增强方法。LLFormer的核心组件是基于axis的多头selfattention和跨层关注的融合,大大降低了线性复杂度。广泛的新的实验数据集和现有的公共数据集显示LLFormer优于最先进的方法。
-
我们还表明,利用现有LLIE方法训练对我们的基准作为预处理步骤显著提高下游任务的性能,例如,在光线暗的条件下人脸检测。源代码和pre-trained模型可在https://github.com/TaoWangzj/LLFormer上。
核心组件
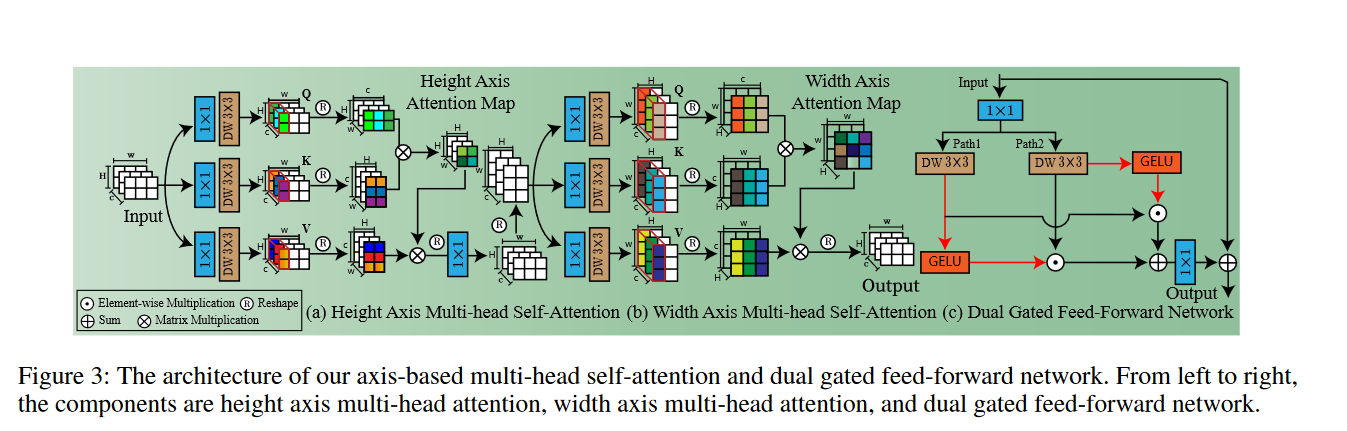
图像特征融合
python 代码实现
class NextAttentionImplZ(nn.Module):
def __init__(self, num_dims, num_heads, bias) -> None:
super().__init__()
self.num_dims = num_dims
self.num_heads = num_heads
self.q1 = nn.Conv2d(num_dims, num_dims * 3, kernel_size=1, bias=bias)
self.q2 = nn.Conv2d(num_dims * 3, num_dims * 3, kernel_size=3, padding=1, groups=num_dims * 3, bias=bias)
self.q3 = nn.Conv2d(num_dims * 3, num_dims * 3, kernel_size=3, padding=1, groups=num_dims * 3, bias=bias)
self.fac = nn.Parameter(torch.ones(1))
self.fin = nn.Conv2d(num_dims, num_dims, kernel_size=1, bias=bias)
return
def forward(self, x):
# x: [n, c, h, w]
n, c, h, w = x.size()
#将通道数除以头数,将通道分组
n_heads, dim_head = self.num_heads, c // self.num_heads
reshape = lambda x: einops.rearrange(x, "n (nh dh) h w -> (n nh h) w dh", nh=n_heads, dh=dim_head)
qkv = self.q3(self.q2(self.q1(x)))
#会根据提供的函数对指定序列做映射。
q, k, v = map(reshape, qkv.chunk(3, dim=1))
q = F.normalize(q, dim=-1)
k = F.normalize(k, dim=-1)
# fac = dim_head ** -0.5
res = k.transpose(-2, -1)
res = torch.matmul(q, res) * self.fac
res = torch.softmax(res, dim=-1)
res = torch.matmul(res, v)
res = einops.rearrange(res, "(n nh h) w dh -> n (nh dh) h w", nh=n_heads, dh=dim_head, n=n, h=h)
res = self.fin(res)
return res
class NextAttentionZ(nn.Module):
def __init__(self, num_dims, num_heads=1, bias=True) -> None:
super().__init__()
assert num_dims % num_heads == 0
self.num_dims = num_dims
self.num_heads = num_heads
self.row_att = NextAttentionImplZ(num_dims, num_heads, bias)
self.col_att = NextAttentionImplZ(num_dims, num_heads, bias)
return
def forward(self, x: torch.Tensor):
assert len(x.size()) == 4
x = self.row_att(x)
x = x.transpose(-2, -1)
x = self.col_att(x)
x = x.transpose(-2, -1)
return x
# Dual Gated Feed-Forward Network.
class FeedForward(nn.Module):
def __init__(self, dim, ffn_expansion_factor, bias):
super(FeedForward, self).__init__()
hidden_features = int(dim*ffn_expansion_factor)
self.project_in = nn.Conv2d(dim, hidden_features*2, kernel_size=1, bias=bias)
self.dwconv = nn.Conv2d(hidden_features*2, hidden_features*2, kernel_size=3, stride=1, padding=1, groups=hidden_features*2, bias=bias)
self.project_out = nn.Conv2d(hidden_features, dim, kernel_size=1, bias=bias)
def forward(self, x):
x = self.project_in(x)
x1, x2 = self.dwconv(x).chunk(2, dim=1)
x = F.gelu(x2)*x1 + F.gelu(x1)*x2
x = self.project_out(x)
return x
#本文提出的主要核心模块
class TransformerBlock(nn.Module):
def __init__(self, dim, num_heads=1, ffn_expansion_factor=2.66, bias=True, LayerNorm_type='WithBias'):
super(TransformerBlock, self).__init__()
self.norm1 = LayerNorm(dim, LayerNorm_type)
self.attn = NextAttentionZ(dim, num_heads)
self.norm2 = LayerNorm(dim, LayerNorm_type)
self.ffn = FeedForward(dim, ffn_expansion_factor, bias)
def forward(self, x):
x = x + self.attn(self.norm1(x))
x = x + self.ffn(self.norm2(x))
return x
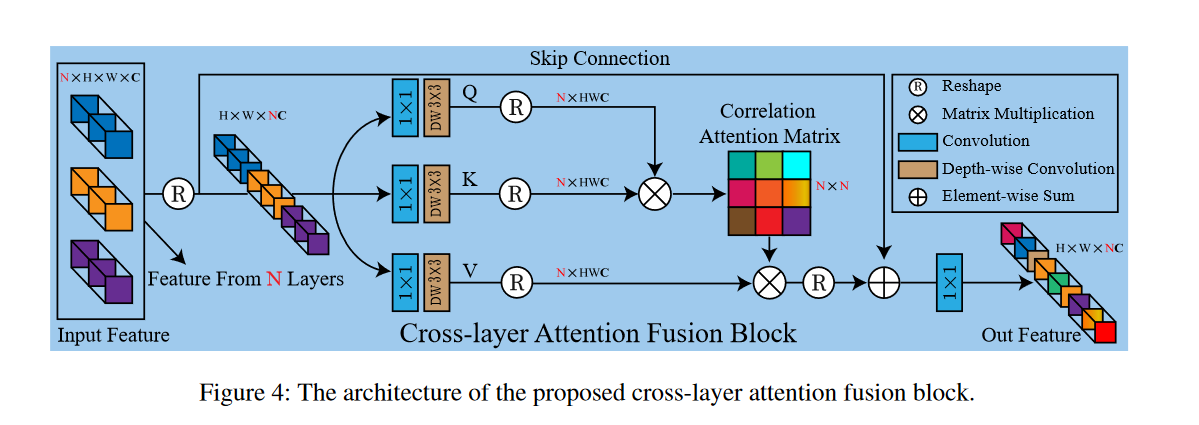
#### Cross-layer Attention Fusion Block
class LAM_Module_v2(nn.Module):
""" Layer attention module"""
def __init__(self, in_dim,bias=True):
super(LAM_Module_v2, self).__init__()
self.chanel_in = in_dim
self.temperature = nn.Parameter(torch.ones(1))
self.qkv = nn.Conv2d( self.chanel_in , self.chanel_in *3, kernel_size=1, bias=bias)
self.qkv_dwconv = nn.Conv2d(self.chanel_in*3, self.chanel_in*3, kernel_size=3, stride=1, padding=1, groups=self.chanel_in*3, bias=bias)
self.project_out = nn.Conv2d(self.chanel_in, self.chanel_in, kernel_size=1, bias=bias)
def forward(self,x):
"""
inputs :
x : input feature maps( B X N X C X H X W)
returns :
out : attention value + input feature
attention: B X N X N
"""
m_batchsize, N, C, height, width = x.size()
x_input = x.view(m_batchsize,N*C, height, width)
qkv = self.qkv_dwconv(self.qkv(x_input))
q, k, v = qkv.chunk(3, dim=1)
q = q.view(m_batchsize, N, -1)
k = k.view(m_batchsize, N, -1)
v = v.view(m_batchsize, N, -1)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
out_1 = (attn @ v)
out_1 = out_1.view(m_batchsize, -1, height, width)
out_1 = self.project_out(out_1)
out_1 = out_1.view(m_batchsize, N, C, height, width)
out = out_1+x
out = out.view(m_batchsize, -1, height, width)
return out
整个网络进行不同尺度融合的时候都使用可学习的权重进行加权融合
#加权融合
self.coefficient_1_0 = nn.Parameter(torch.Tensor(np.ones((2, int(int(dim))))), requires_grad=attention)
out = self.coefficient_1_0[0, :][None, :, None, None] * out_fusion_123 + self.coefficient_1_0[1, :][None, :, None, None] * out_enc_level1_1
















 485
485











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









