






一、Ultra-High-Definition Low-Light Image Enhancement: A Benchmark and Transformer-Based Method
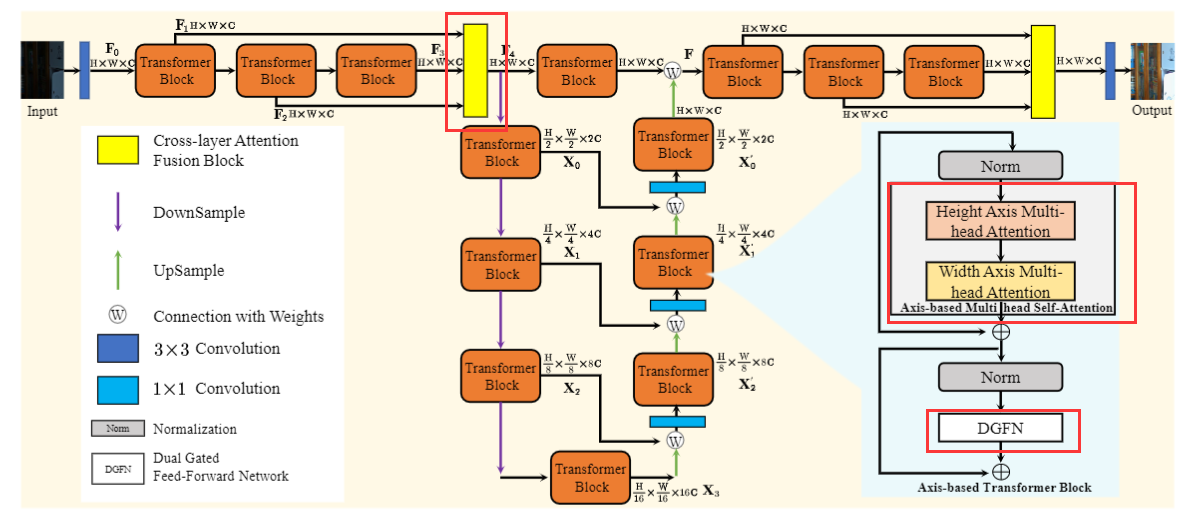
三个创新点:1、Transformer block里面修改了 attention;2、Transformer block里修改了FFN;3、添加了 cross-layer attention 。
attention
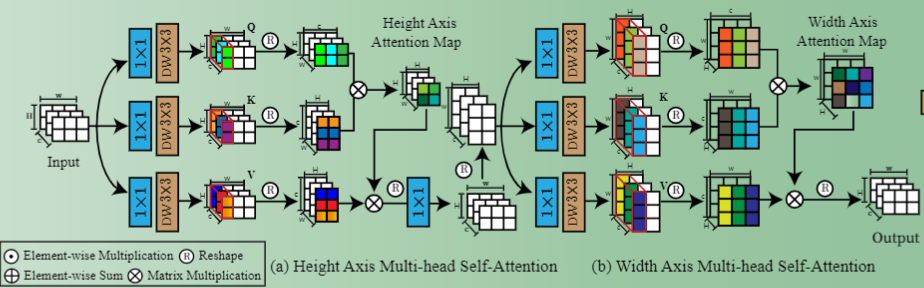
ViT在Q和K计算相似性时,对于输入为(C,H,W)的特征需要进行CHWxCHW的运算(像素维)。 Restormer在Q和K计算相似性时,对于输入为(C,H,W)的特征需要进行CxC的运算(通道维)。本文分为两个步骤,第一步相似性计算的是HxH,叫做 height-axis attention。第二步相似性计算的是 WxW,叫做 width-axis attention。
DGFN
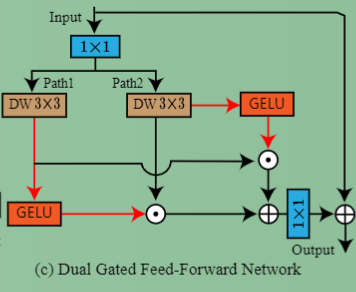
双门控:两个分支都使用GELU,并加权至另一分支。
cross-layer attention

输入N组(C,H,W)的特征,做QKV的运算,得到NxN相似性矩阵。输入的N组特征里,强调重要的、抑制不重要的。
二、ShufflfleMixer: An Effificient ConvNet for Image Super-Resolution

1、shuffle mixer layer
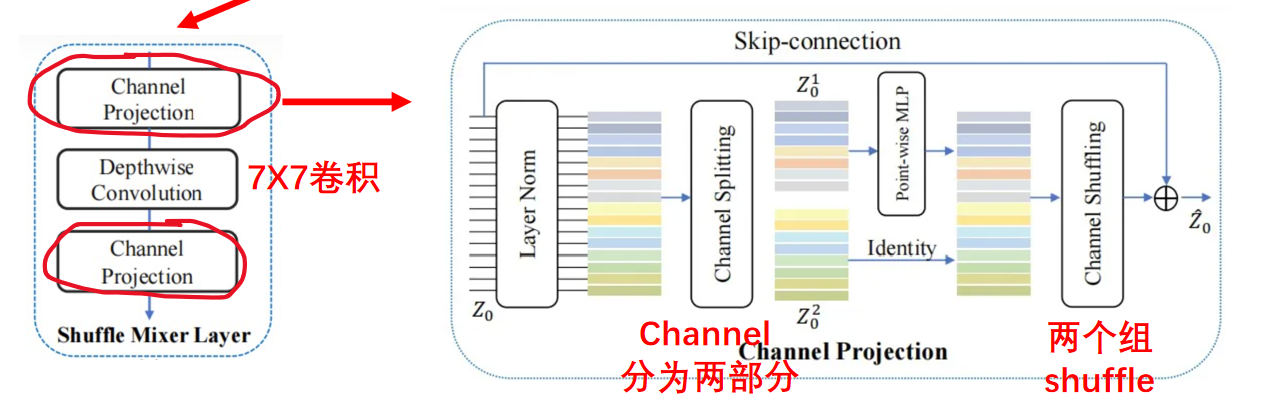
在通道维split为:z1,z2。z1经过point-wise MLP后与z2 concat。然后shuffle。
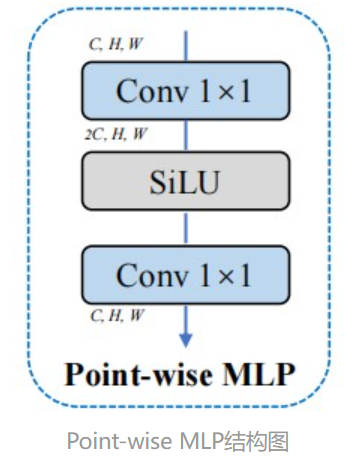
Point-wise MLP处理。为啥叫逐点MLP呢,其实就是把linear替换成1×1Conv,激活函数用SiLU。
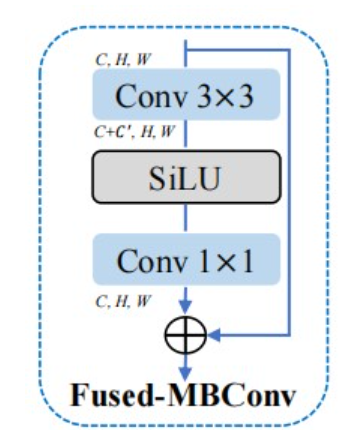
2.FMBConv
三、【ARXIV2212】A Close Look at Spatial Modeling: From Attention to Convolution

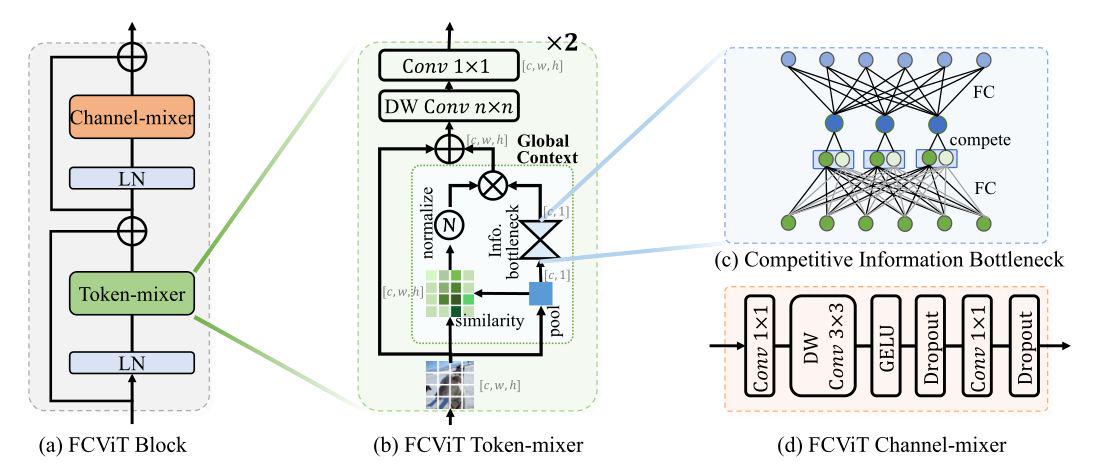
CHW特征矩阵 和 池化后的小矩阵 相乘,得到相似性矩阵,而不是通过QK的计算得到。
作者引入了一个 Competitive Information Bottleneck 结构:中间层引入了“竞争”机制,6个节点分别连接到2个3节点层,然后选较大的节点。
四、DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention
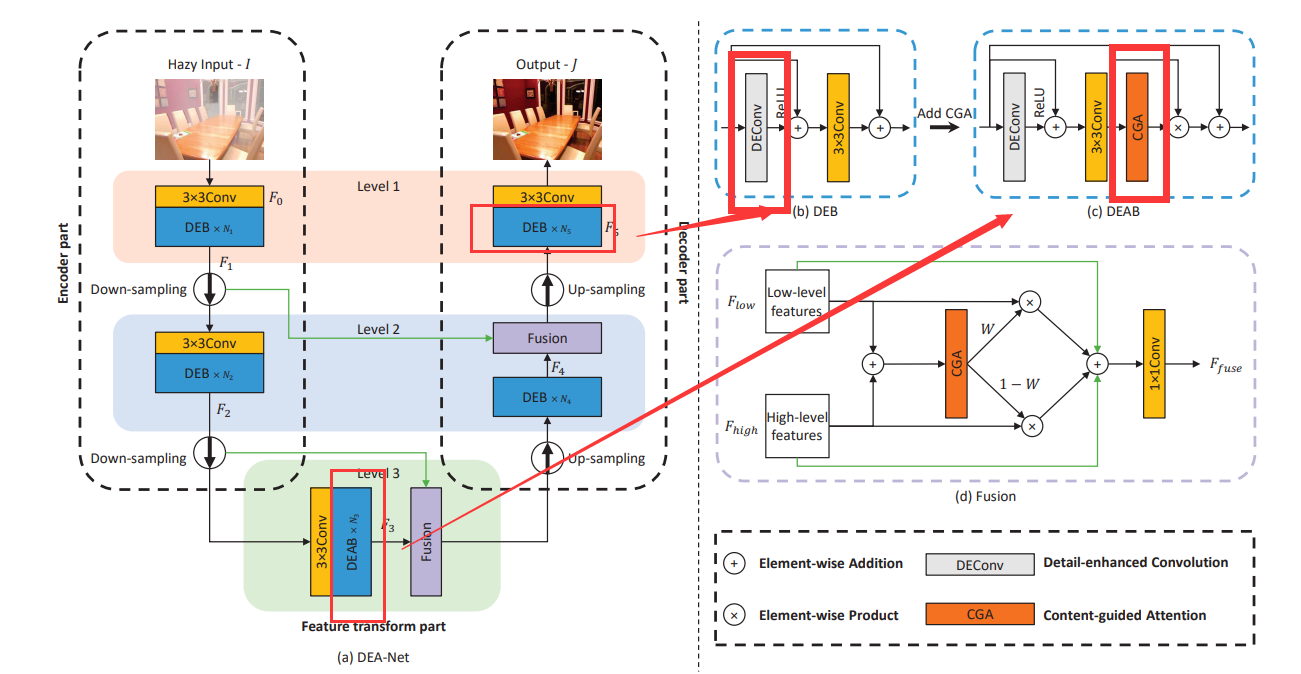
应用了DEConv:Detail-enhanced conv它包含五个平行部署的卷积层。
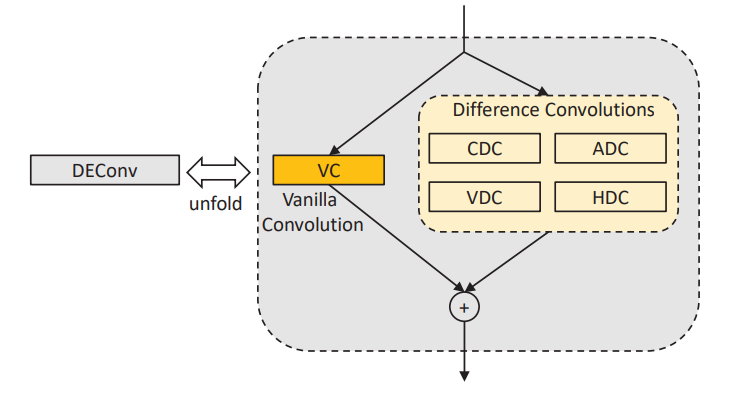
DEAB添加了CGA:content-guided attention
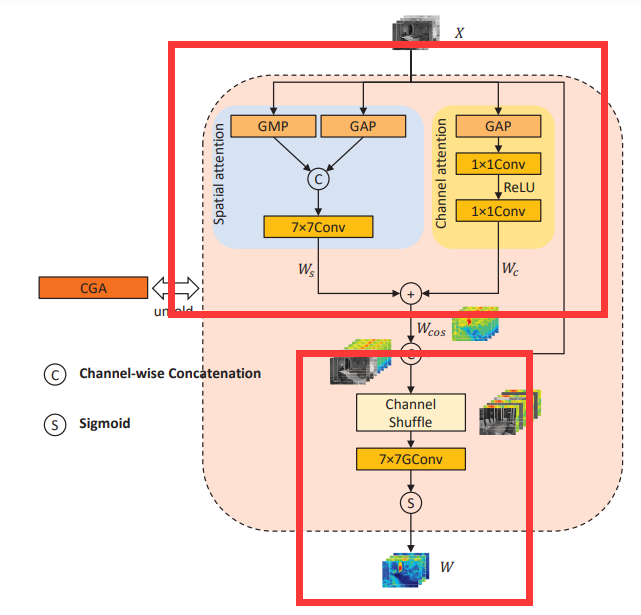
Content-guided attention 本质是CBAM和 channel shuffle(特征分了两组,进行 channel shuffle) 的结合
五、DAE-Former: Dual Attention-guided Efficient Transformer for Medical Image Segmentation
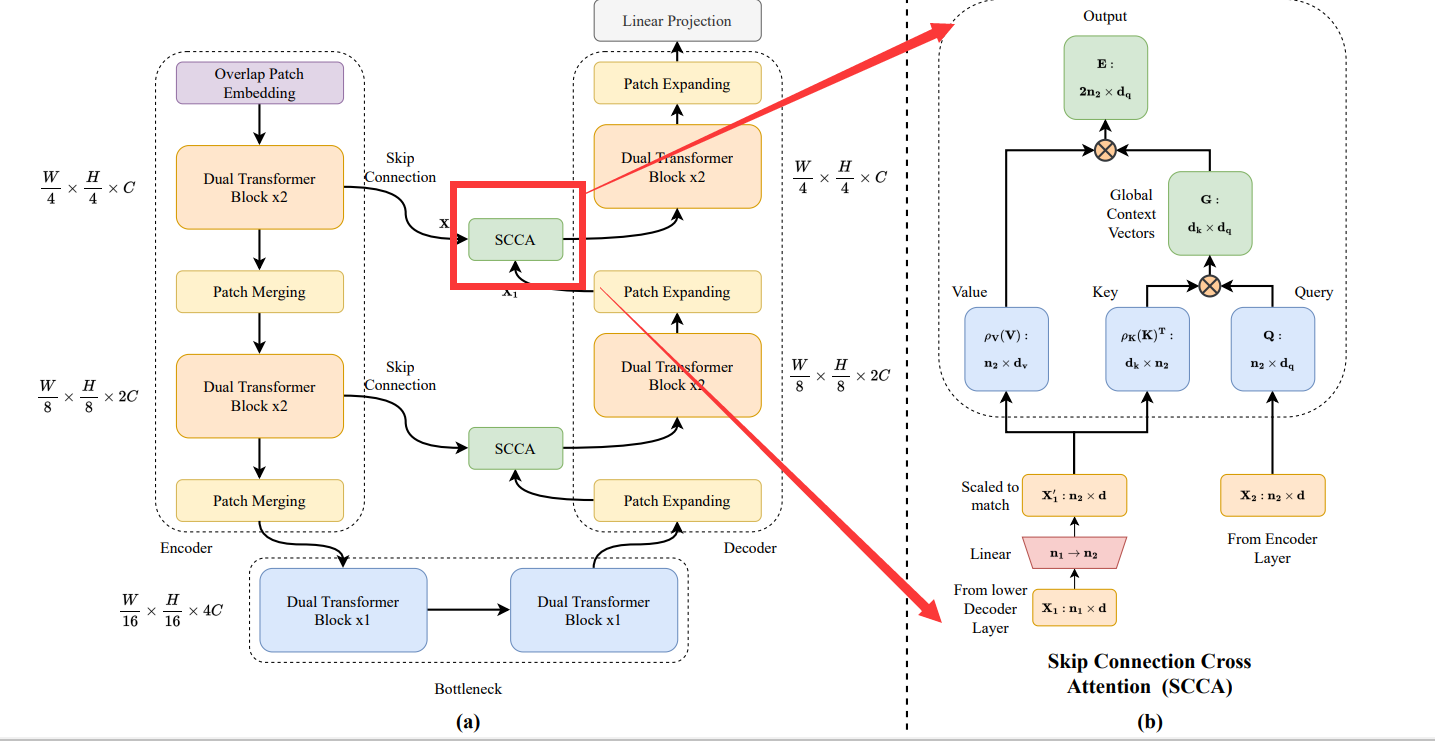
典型的 UNet 结构,中间的SCCA是Dual attention,由两部分组成:
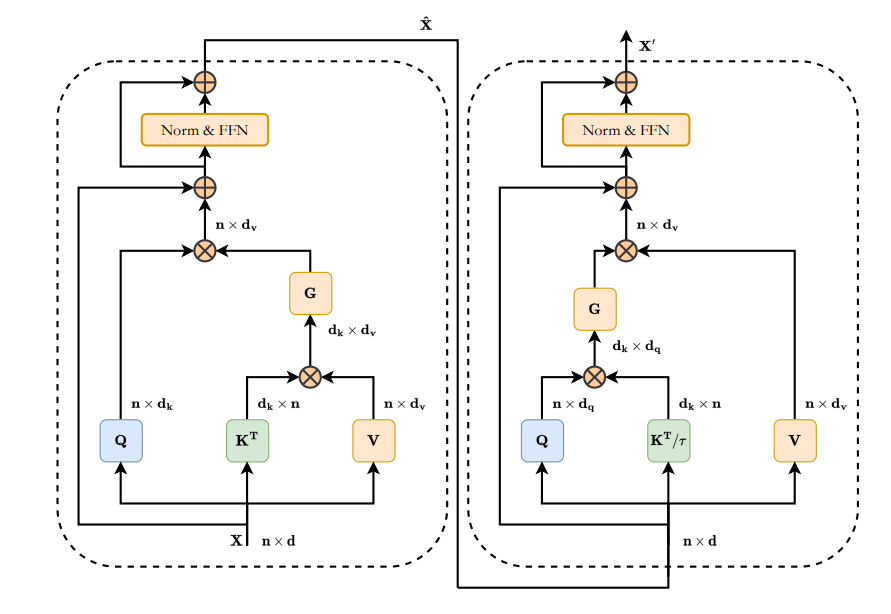
1) Efficient attention(Restormer计算 CxC 的矩阵是完全一样的)
2) Channel attention















 331
331











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









