







一、白化
1. 相关理论
~~~~ 白化的目的是去除输入数据的冗余信息。假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的;白化的目的就是降低输入的冗余性。
~~~~ 输入数据集X,经过白化处理后,新的数据 X’ 满足两个性质:
~~~~ (1) 特征之间相关性较低;
~~~~ (2) 所有特征具有相同的方差。
2. 算法概述
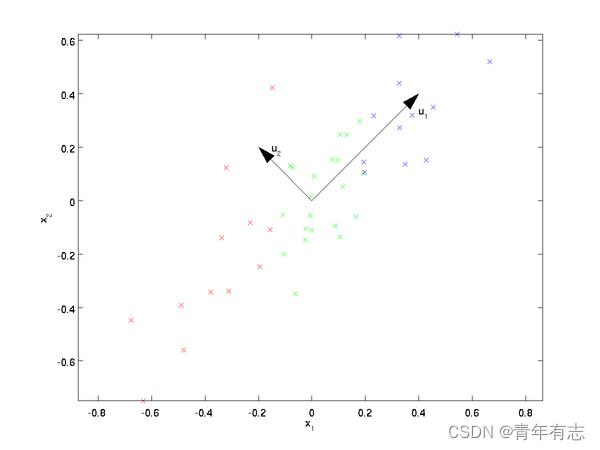
1、首先是 PCA 预处理
~~~~ 原始数据 X,经过处理通过协方差矩阵可以求得特征向量 u1、u2 (假设选取两个向量),然后把每个数据点,投影到这两个新的特征向量,得到新的坐标
~~~~ PCA 算法详讲
2、PCA 白化
~~~~ 每一维的特征做一个标准差归一化处理即可得到 PCA 白化:
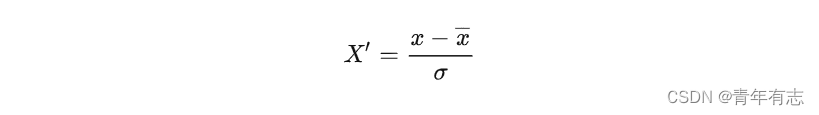
3、ZCA白化
~~~~ ZCA 白化是在 PCA 白化的基础上,又进行处理的一个操作。具体的实现是把上面PCA白化的结果,又变换到原来坐标系下的坐标:
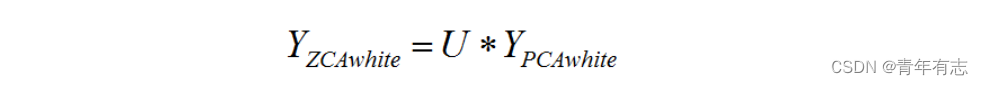
二、Internal Covariate Shift——内部变量偏移
~~~~ 深度学习这种包含很多隐层的网络结构,在训练过程中,因为各层参数不停在变化。另一方面,深度神经网络一般都是很多层的叠加,每一层的参数更新都会导致上层的输入数据在输出时分布规律发生了变化,并且这个差异会随着网络深度增大而增大——这就是 Internal Covariate Shift。它会导致:每个神经元的输入数据不再是独立同分布!
~~~~ 上层参数需要不断适应新的输入数据分布,降低学习速度,下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区。反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因 — 梯度消失。
~~~~ BN 把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布。这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。经过BN后,目前大部分Activation 的值落入非线性函数的线性区内,其对应的导数远离导数饱和区,这样来加速训练收敛过程。
这就是在深度学习中使用BN的一个原因和动机,当然使用LN也是同样的以不同的方式来达到相似的效果。
总结:
~~~~ 1、BN层让损失函数更平滑
~~~~ 2、BN更有利于梯度下降,使得梯度不会出现过大或者过小的梯度值。
三、BN 和 LN 原理
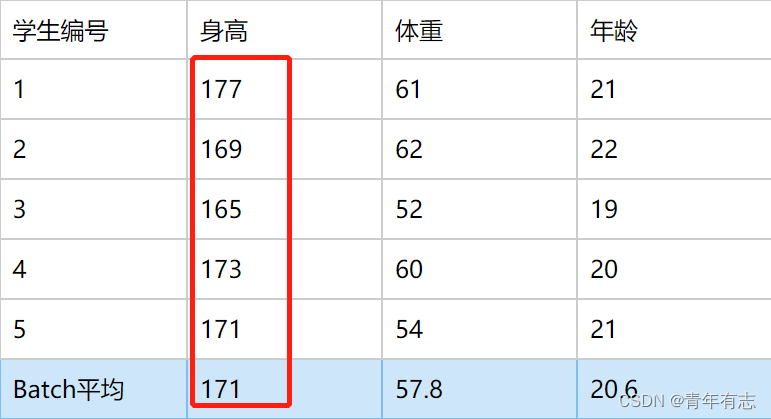
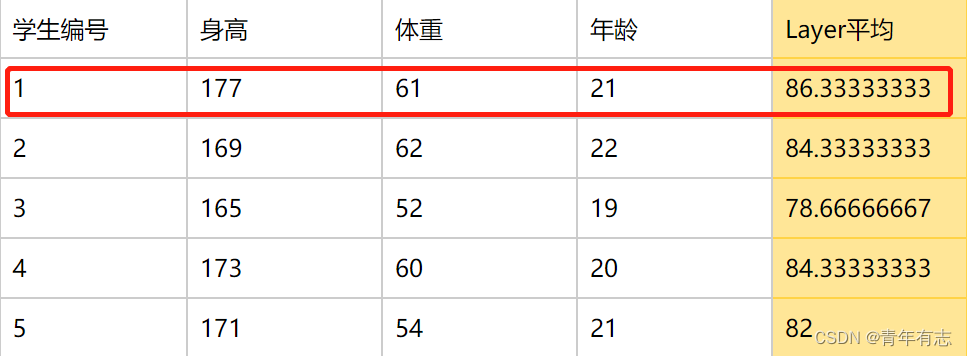
BatchNorm 有两个过程,Standardization 和 scale and shift,计算每行的均值方差
一、直观理解:【深度学习】batch normalization和 layer normalization 区别
① Batch normalization 是对一批样本的同一纬度特征做归一化。如下图对每个维度进行标准化:
② layer normalization: 对单个样本的所有维度特征做归一化
③ 两者的区别~~~~ 从操作上看:BN 是对同一个 batch 内的所有数据的同一个特征数据进行操作;而 LN 是对同一个样本进行操作。
~~~~ 从特征维度上看:BN中,特征维度数 = 均值 or 方差的个数;LN 中,一个 batch 中有batch_size 个均值和方差。
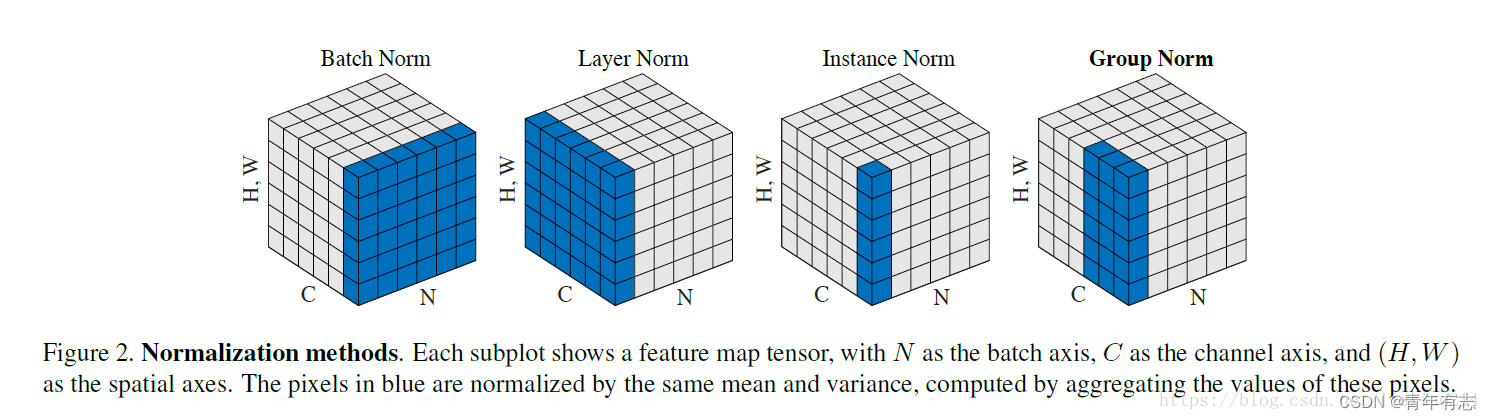
③ 如在NLP中上图的 C、N、H, W 含义:
N:N 句话,即 batchsize;
C:一句话的长度,即seqlen;
H, W:词向量维度 embedding dim。
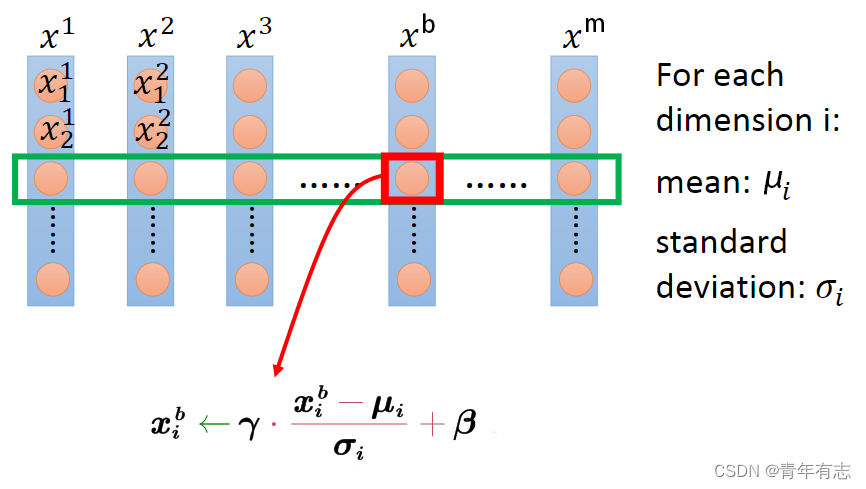
二、神经网络中使用 BN: Batch Normalization详解
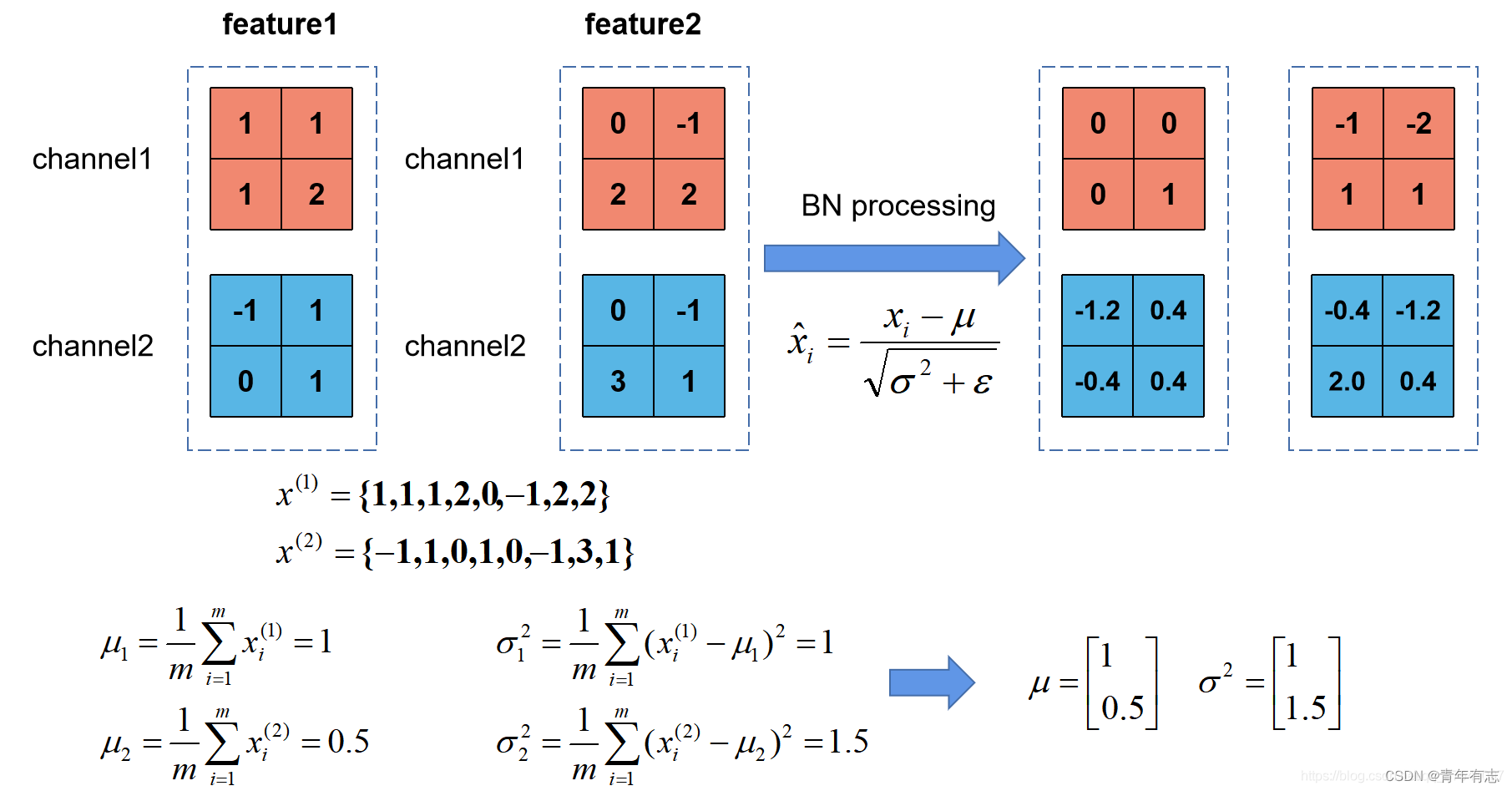
三、下图是当 batch size 为 2 时卷积后得到的两个 feature map,然后使用中使用 BN:Batch
Normalization详解以及pytorch实验
序列模型中,LN 是对每个词做Norm。第一个原因是因为 torch 官网的实现方式就是这样,第二个原因是,如果是对句子进行 norm,每个句子的长度又不一样,需要进行padding。这样,句子长度为10和句子长度为100的,很明显长度为10的句子的norm的效果,被 padding embeding 减弱了很多。Layer Normalization解析
三、BN 和 LN 的优点和不足
BN 具有的优点:
a、加快神经网络的训练时间。BN 强行拉平了数据分布,它可以让收敛速度更快。使得总的训练时间更短。
b、容忍更高的学习率(learning rate)和初始化权重更容易。对于深层网络来说,权重的初始化要求是很高的,而BN能够动态的调整数据分布,因此初始化的要求就不像以前那么严格了。
c、可以支持更多的损失函数。有些损失函数在一定的业务场景下表现的很差,就是因为输入落入了激活函数的死亡区域——饱和区域。而BN的本质作用就是可以重新拉正数据分布,避免输入落入饱和区域,从而减缓梯度消失的问题。
d、提供了一点正则化的作用,可能使得结果更好。BN在一定的程度上起到了dropout的作用,因此在适用BN的网络中可以不用dropout来实现。
e、可以将 bias 置为0,因为Batch Normalization的Standardization过程会移除直流分量,所以不再需要bias。BN 的不足:
a、BN 对于 batch_size 的大小还是比较敏感的,batch_size 很小的时候,其梯度不够稳定,效果反而不好。
b、BN 对于序列网络,RNN、LSTM 等模型的效果并不好针对以上 BN 的不足,主要是 BN 应用到 RNN、LSTM 等网络上效果不好的缺点,研究人员提出了LN。在继承了 BN 的优点上,还有另外 2 个优点:
1、LN 能够很好的应用在 RNN、LSTM 等类似的网络上。
2、LN 是针对一层网络所有的神经元做数据归一化,因此对 batch_size 的大小并不敏感。
四、Reference
(1)https://blog.csdn.net/HUSTHY/article/details/106665809
(2)https://blog.csdn.net/hjimce/article/details/50864602
(3)https://zhuanlan.zhihu.com/p/77151308
(4)https://www.cnblogs.com/shine-lee/p/11989612.html
(5)https://blog.csdn.net/qq_37541097/article/details/104434557
(6)https://blog.csdn.net/qq_37541097/article/details/117653177















 1639
1639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









