








Gitee 源码: https://gitee.com/futurelqh/symbolic-regression/tree/master/GP-GPPI
Abstract 摘要
问题: 在学习高维数据进行符号回归时,遗传规划通常不能很好地泛化。特征选择作为一种数据预处理方法,不仅可以提高学习算法的效率,而且可以增强泛化能力。然而,在高维符号回归遗传规划中,很少考虑学习前的特征选择问题。
我们的方法: 在这项工作中,我们提出了一种新的基于排列的特征选择方法,使用遗传编程来选择高维符号回归的特征。
我们做的还不错: 通过一组实验研究了所提出的方法在高维符号回归遗传规划的推广上的性能。回归结果证实了所提方法相对于其他特征选择方法的优越性能。进一步分析表明,所提方法演化的模型更可能只包含真正相关的特征,具有更好的可解释性。
I. INTRODUCTION 介绍
近十年来,随着数据收集技术的发展,在现实世界的机器学习任务中,数据的维度(即特征的数量)越来越高。数据的高维度往往降低了学习算法从包含所有特征的原始数据中提取有用信息的能力,因为它容易从无关特征和噪声中学习。此外,从高维数据中学习还存在一些其他问题,例如维数灾难 [1]、过拟合风险较高、计算成本较高等。
特征选择是识别描述输出变量所必需的相关特征子集的过程。当从高维数据中学习时,需要进行特征选择。在特征选择 [2],[3],[4] 方面已经有很多工作。然而,它们大多是针对分类任务提出的。用于符号回归( Symbolic Regression,SR) 的遗传程序设计( Genetic Programming,GP) [5] 很少考虑特征选择,当GP处理高维符号回归任务时更是少见。其根本原因在于GP在探索特征空间创建SR模型时具有内置的特征选择能力。然而,对于高维回归任务,内置GP的特征选择能力通常不够强。
泛化能力是指学习到的模型能够对未知数据具有良好预测性能的一种能力。一般通过模型在一组看不见的测试样本上的预测误差来衡量。虽然泛化长期以来被认为是机器学习中许多领域的一个重要方面 [6],[7] 但是在符号化回归的GP中并没有得到太多的关注。自2002年Kushchu关于GP的推广工作发表以来 [8],越来越多的关注致力于促进GP的符号回归推广 [9],[10],[11]。然而,与符号回归GP的快速发展相比,GP的泛化贡献远远落后。因此,GP的通用化仍然是一个开放的问题 [12]。
在高维特征空间中学习未知的符号回归模型时,GP的泛化能力会降低。特征选择作为一种数据预处理方法,可以去除噪声和无关特征。它具有降低过拟合风险的潜力,从而促进GP的泛化能力。然而,迄今为止,针对高维回归问题,在特征选择方面提高GP泛化性的工作还不多。
目标:这项工作的目标是提出一种新的特征选择方法,以提高GP对符号回归的泛化能力,特别是在从高维数据中学习时。本研究将涵盖以下三个研究问题:
- 特征选择如何影响GP对训练性能的学习能力
- 特征选择能否增强GP对高维回归任务的泛化能力
- 新的特征选择方法能否选择出真正相关的特征进行高维符号回归
II. BACKGROUND
A. Genetic Programming for Symbolic Regression
符号回归作为回归分析的一种,是一种模型识别过程 [5]。其任务是识别数据集中输入变量和响应变量之间的关系,并将它们的关系用符号模型表达。符号回归的主要优点在于它不需要预先指定模型的形式和大小,也不需要假设数据的任何分布。符号回归的命名是为了强调识别过程可以找到符号描述。这是与经典回归方法的显著区别,其目的是寻找预定义模型的一组系数。
解的符号性和不需要任何先验知识,使得GP非常适合符号回归。在以前的工作中 [13],[14],[15],[16],[17],[18] 已经开发了许多不同的GP变体来提高符号回归的效率和有效性。尽管GP在符号回归方面有许多成功的案例,但提高其泛化能力仍然是一个开放的问题,因为它倾向于过度拟合。
B. Feature Selection
特征选择去除不相关和冗余的特征。从而带来了数据集的维度减少。特征选择不仅可以使学习过程更加高效,还可以提高学习性能 [19] [20]。特征选择技术可以分为 3 类:filter methods 、wrapper methods 和 embedded methods [19] [21]。filter methods [22]、[23] 基于 mutual information 等多种准则选择特征子集。Yu等 [23] 提出了一种基于占优相关性测度的滤波器特征选择方法。在他们的方法中,使用对称不确定性 (SU) 度量来识别和选择主要特征。Wrapper 方法 [24]、[25]、[26] 将学习算法作为黑箱,根据学习算法的性能选择特征子集。嵌入式方法 [27]、[28]、[29] 将特征选择过程纳入学习过程。
1) Genetic Programming for Feature Selection:
由于在进化个体中出现的特征可以被视为一组被选择的特征,因此GP被认为具有内置的特征选择能力。GP 通过探索特征空间来检测重要特征的内置能力使其成为一种有价值的特征选择方法。文献 [3]、[30]、[31]、[32] 提出了许多不同的基于GP的特征选择方法。
Neshatian 等 [3] 开发了一个Pareto GP用于分类任务中的特征选择。他们设计了一个函数来衡量特征子集的相关性。保持了一个Pareto前沿归档,它由具有低基数(即子集包含的特征数)和高相关性的非支配特征子集组成。
他们还采用了避免膨胀和过拟合的方法,使GP能够探索大的特征子集。实验结果表明,该特征选择方法能够在降低演化分类器复杂度的同时提高分类精度。然而,当期望的最佳特征子集基数较高时,所提方法可能存在一定的局限性。Muni等 [30] 提出了一种基于GP的特征选择方法来解决偏斜/不平衡的高维分类任务,该方法结合了多个最常用的特征选择度量。结果表明,该方法能够在降低维数的同时提高分类精度。Moore等 [33] 引入了非线性的基因-基因(特征-特征)相互作用将基于信息熵的测度融入到各自的 Pareto GP 系统中进行疾病的遗传分析。多个目标GP系统使用3个目标(分类精度、模型大小和交互度量)引导搜索包含疾病危险因素特征的模型。GP系统被认为能够找到精确的模型,尽管特征空间的大小和复杂性。
最近,我们在文献 [34] 中提出了一种带特征选择的遗传规划 (GPWFS) 方法。GPWFS 是一种面向高维符号回归的两阶段特征选择方法。它通过一个参数 G f G_f Gf 将GP的演化过程分为两个阶段。第一阶段的主要任务是特征选择。在这一阶段的每一代,收集了出现在前 β β β% 个体中的所有显著特征,因为这些特征被认为是重要特征的候选。在第一阶段结束时,形成了一组潜在的重要特征 F c F_c Fc。第二阶段是重新初始化的个体群体上的标准进化过程。在第二阶段的第一代,GPWFS 通过保留前 β β β% 的个体同时替换剩余的个体来重新初始化种群。替换将采取等数量随机生成个体的形式,使用由所选特征集合 F c F_c Fc 构成的新终端集合。文献 [34] 研究并证实了GPWFS对增强GP普适性的有效性。然而,GPWFS需要调优两个关键参数 G f G_f Gf 和 β β β,这两个参数具有问题依赖性,对GP的参数设置敏感,如种群规模和总代数。更多的细节可以参见[34]。
2) Random Forests and Decision Tree-based Methods for Feature Selection:
随机森林和基于决策树的特征选择方法:随机森林 (RF) [35] 是一种集成学习算法,它构建决策树森林,为分类和回归任务提供解决方案。RF 在 out-of-bag (OOB) 实例上使用了置换变量重要性的概念。OOB 实例是不暴露于决策树的观测值。对于决策树中的每个变量,OOB实例中该变量的值被置换为(在OOB实例中随机重排)。然后将每个置换后的例子传递到树中。定义回归误差的总增加量为变量重要性。数值越大,说明该变量越重要。
决策树家族如 ID3 [36]、C4.5 [37]、C5.0 [38] 等也可以应用于特征选择。在这些决策树中,变量重要性通过两种方式计算。第一种是计算变量拆分后训练样本落入所有终端节点的百分比。通常,它偏向于早期分裂节点中的特征。另一种方法是在分配重要性评分时,通过考虑变量被使用的拆分百分比来避免这种偏差。
C. Generalisation in GP for Symbolic Regression
泛化能力是一种学习到的模型能够在未知的测试数据上获得良好预测结果的能力。对于监督学习问题,泛化是其中学习算法最重要的性能指标之一,因为它证明了有效学习的存在。过拟合是与泛化相反的概念。当学习到的模型具有较低的训练误差但测试误差较高时,会出现过拟合现象。相比之下,具有良好泛化能力的模型不仅可以在训练数据上表现良好,更重要的是在未知数据上表现良好。从高维特征空间学习未知模型存在过拟合的风险并导致泛化性差。
泛化问题长期以来一直是机器学习诸多领域的重要问题 [6]。在 GP 分类中, GP 程序的泛化能力已经被研究了很长时间。过去已经有很多工作致力于改进GP在分类 [39],[40],[41],[42] 中的泛化能力,但是对于符号化回归的 GP 泛化能力的研究还不是很多。长期以来,符号回归一直被当作一种优化任务,利用所有可用的数据进行进化。近年来,GP在符号回归 [9],[16],[17],[43],[44],[45] 中的推广受到越来越多的关注。Uy等. [9]开发了新的语义感知算子来保持局部性,从而产生了更好的GP的泛化性。Haeri等[16]提出了基于方差的分层学习GP,将进化过程分解为多个层次。从低到高,这些层使用不同的训练集进行训练,从少到多。训练集的复杂度由输出值的方差来衡量。该度量也被应用于评估候选模型的复杂度。实验结果表明,分层GP可以在降低模型复杂度的同时增强GP的泛化能力。Mousavi 等在MOGP中,除了获得较低的训练误差外,衡量模型复杂度的候选模型的一阶导数被认为是另一个目标。实验结果表明,MOGP比标准GP具有更好的泛化增益。
综上所述,为了提高分类性能,基于GP的特征选择已经做了大量工作。然而,对于回归任务,尤其是高维回归,更值得关注。目前还没有这方面的工作,在高维情况下,需要通过特征选择来提高GP的回归性能和泛化能力。
III. THE PROPOSED FEATURE SELECTION METHOD 提出的特征选择方法 ✨
本文提出了一种新的特征选择方法,命名为排列重要性遗传规划 (genetic programming with permutation importance,GPPI)。它是基于我们以前的研究,即。GPWFS [34]。这两种方法都有一个共同的假设,GP可以探索搜索空间来自动检测重要特征。我们假设相关特征出现在高度拟合的GP个体中,即使这些特征并不是全部相关。这样,它们就可以形成一个候选的重要特征集进行特征选择。然而,GPPI具有显著的采用不同方式从GPWFS中确定特征的重要性的能力。此外,GPWFS是一种嵌入特征选择阶段的用于回归的GP方法,而GPPI是一种用于预处理数据的用于符号回归的GP ( GPSR )的特征选择方法。
A. The Overall Structure
图 1 给出了新的GPSR系统 GP-GPPI 的数据流图,其中包括一个特征选择组件GPPI。GP系统的训练过程包括两个连续的阶段。首先,将GPPI应用于训练数据以选择重要特征子集。然后,标准GP对选出的特征对应的训练数据进行回归建模。新型GPSR系统的核心部件是GPPI。GPPI在两个方面改进了GPWFS。首先是好个体的定义,好个体是重要特征的来源。GPWFS将适应度值最高的某些顶级个体视为优秀个体。相反,GPPI从多个GP运行中收集运行最好的个体。与GPWFS中的优秀个体相比,GPPI中的优秀个体通过利用GP的自然特征选择能力得到了充分的进化并包含了重要的特征。第二个方面在于重要特征的确定。GPWFS将优秀个体中表现出的所有独特特征都收集起来作为相对重要的特征。GPPI计算这些不同特征的量化重要性值。特征选择以重要值的度量方式产生。GPPI的具体内容将在第三节介绍。Section III.C and III.D.

B. Fitness Function
在本文中,GPPI 和GPSR中的适应度函数均为常态化均方根误差(Normalised Root Mean Square Error,NRMSE ),用于评估个体进行特征选择和回归的性能。式中给出了 NRMSE 的定义:
N
R
M
S
E
=
R
M
S
E
Y
m
a
x
−
Y
m
i
n
(1)
NRMSE = \frac{RMSE}{Y_{max} - Y_{min}} \tag{1}
NRMSE=Ymax−YminRMSE(1)
其中 ( Y m a x − Y m i n ) (Y_{max}-Y_{min}) (Ymax−Ymin) 为目标变量的范围,RMSE 为均方根误差,RMSE的定义如式 (2) 所示:

其中 N N N 为实例数, f ( X i ) f(X_i) f(Xi) 为模型输出, Y i Y_i Yi 为目标输出。
C. Permutation Feature Importance
如前所述,并非所有出现在高度匹配个体中的特征都是重要的。因此,特征选择方法的关键部分是特征重要性的量化度量,它可以区分出现的特征之间的差异。特征重要性可以定义为该特征与目标特征之间的相关性,或者该特征在多大程度上有助于减少输出值与目标值之间的误差。
RF中的置换变量/特征重要性是一种广泛使用的用来衡量给定特征重要性的评分 [46]。对特征的值进行置换是指在数据集中随机重新排列特征的值。例如,一个特征的值记为 { 4,7,9 },该特征的排列可以在 { 4,9,7 },{ 7,4,9 },{ 7,9,4 },{ 9,7,4 },{ 9,4,7 } 之间取随机形式。置换重要性的潜在机制是重要特征对模型性能的影响应该更高,即对于回归问题,置换一个更重要的特征会导致更高的回归误差。基于这一假设,我们在基于排列的符号回归中度量了GP中的特征重要性。
图 2 给出了 GPPI 的主要流程。图的左边部分展示了在一次GP运行中计算置换特征重要性的过程,右边部分描述了获得一个特征的置换重要性的过程。整个过程定义为:
- 将训练数据随机拆分为子训练集和子测试集
- 执行一个标准的GP运行,得到运行最好的个体 I b I_b Ib,它在子训练集中具有最低的训练误差
- 计算 I b I_b Ib 在子测试集上的泛化误差,称为 E r r o r g ( I b ) Err_{org} (I_b) Errorg(Ib)
- 对于 I b I_b Ib 中的每个特征 X j X_j Xj,在子测试集中重排列对应的值,并得到 I b I_b Ib 在置换子测试集上的测试误差,表示为 E r r p m t ( I b ) Err_{pmt} (I_b) Errpmt(Ib)
- 计算 E r r o r g ( I b ) Err_{org} (I_b) Errorg(Ib) 和 E r r p m t ( I b ) Err_{pmt} (I_b) Errpmt(Ib) 之间的距离,并根据如下公式衡量原始特征 F I r a w ( X j ) FI_{raw}(X_j) FIraw(Xj) 的重要性:


对于运行最好的个体 I b I_b Ib 中的每个不同特征,需要执行步骤 4 和步骤 5。需要注意的是,在该GP运行中, I b I_b Ib 中缺失的特征的重要性值被定义为0。整个过程重复 n 个( n≥30)独立的GP在给定的训练数据上运行。n≥30是为了减少GP运行中使用的随机种子对重要性值的偏倚。该过程的伪代码如算法1所示

为了使根据重要性值进行的特征选择具有灵活性和问题无关性,特征的最终重要性定义为比例重要性,即原始特征重要性的标准误差归一化后的平均原始特征重要性。其给出为:

其中 n n n 为GP 运行次数, F I r a w ( X j ) ‾ \overline{FI_{raw}(X_j)} FIraw(Xj) 为 n 次 GP 运行中原始特征重要性的平均值, δ δ δ 为标准差, δ n \frac{δ}{\sqrt{n}} nδ 为标准误差。
D. Feature Selection according to Permutation Feature Importance
GP-GPPI 不使用整个特征集,而是使用 GPPI 选择的特征子集。在 GPPI 中,选择 F I s c a ( X j ) FI_{sca}(X_j) FIsca(Xj) 为正的特征。正值表明这些特征在降低回归误差方面具有积极的作用,并且潜在的更多比具有负重要值的同行的重要性。这种选择度量的主要优点是与问题无关,特别适用于没有领域知识的回归问题。它不依赖于问题域和特征总数。期望正特征集合能够去除噪声和无关特征。因此,它可以降低过拟合的风险,并潜在地提高GP对高维符号回归的泛化性能。
IV. EXPERIMENTAL DESIGN
为了验证GPPI的特征选择能力,并考察其对GPSR泛化能力的提升效果,进行了多组实验。我们的新GPSR系统GP-GPPI和GPSR与几种不同的特征选择方法进行了比较。
A. Benchmark Methods
本文将GP-GPPI与5种基于GPSR特征选择的基准方法进行了比较。前两种基准方法是GP-Random Forests(GP-RF )和GP-C5.0 decision trees(GP-C5.0)。另外3种方法是我们之前的方法GPWFS和GPWFS的两个变体。5种基准方法的具体内容如下:
- GP-Random Forests (GP-RF) is a GPSR method using features selected by random forest (RF). The permutation feature/variable importance values in RF are obtained from 30 runs using 30 different seed numbers. This setting can reduce the influence of the random seed on the importance of features. Bootstrap samples are exposed to construct the trees, and the out-of-bag samples are used to calculate the permutation importance.
- GP-C5.0 decision trees (GP-C5.0) is a GPSR method which employs C5.0 for feature selection. The feature importances in C5.0 are also obtained from 30 runs using the same sub-training sets as GPPI. When calculating the importance of a feature, the metric, which considers the percentage of splits the feature makes, is employed.
- GPWFS is a GPSR method for simultaneous feature selection and regression. A brief description of GPWFS has been given in Section II-B1. For more details, readers are referred to [34].
- GPWFS1 is GPWFS using a different setting. GPWFS1 differs from GPWFS in the number of generations for the two stages. The first stage of GPWFS1 has the same number of generations that GPPI uses for feature selection. The number of generations in the second stage is the same as that GP-GPPI used for symbolic regression. GPWFS1 is examined to make the comparison between GP-GPPI and GPWFS close to fair.
- GPWFS2 is a variant of GPWFS. It splits GP for feature selection and GP for symbolic regression into two separate stages. At the end of the feature selection stage, GPWFS2 collects all the distinct features appearing in the best-of-run individuals of 30 GP runs. Then the regression will perform on these selected features. In fact, GPWFS2 differs from GP-GPPI only in lacking the permutation method to determine the important of features.
除了这些特征选择方法外,还使用了 标准的GP,它将整套特征作为输入,进行内置的特征选择。然而,它被用作比较的基线。本文的主要工作是对多种特征选择方法下的GP进行比较。在每个用于回归方法的GP中,进行了100次独立的GP运行。所有的GP方法都是在ECJ GP框架下实现的[47]。用于特征选择的RF和C5.0是在R包下实现的,RF的" randomForest " [ 48 ]和C5.0的" C50 " [ 49 ]。
为了更全面的比较,我们还将GP-GPPI与两种非符号回归方法,最小绝对收缩和选择算子(LASSO) [50]和RF进行回归进行比较。LASSO通过使用正则化1惩罚将回归模型中的部分系数收缩为0来进行特征选择。通过这种方式,LASSO可以有效地增强回归模型的预测性能。这两种方法都是在R包 ‘glmnet ’ [51]和’ randomForest’ [48]下实现的,默认设置。此外,我们还研究了计算量对GP-GPPI的影响,并在相同的计算时间下对GP和GP-GPPI进行了比较。
B. Parameters
所有GP试验的参数汇总如表1所示,GPWFS1的世代数为100 (第一阶段50代,第二阶段50代)。对于GPWFS,两个关键参数,即决定两阶段分裂点的世代数Gf和定义顶端个体比例的β,分别采用3个不同的值进行调整。由于总世代数为50,Gf取25、30、35较为合适,β取5%、10%、15%。为此,对GPWFS进行了9 (3*3)种不同的设置。对于GPWFS1,Gf的值是固定的(Gf = 50)。GPWFS1的β值在5%,10%,15%之间调节。因此,对GPWFS1进行了3种不同的设置。
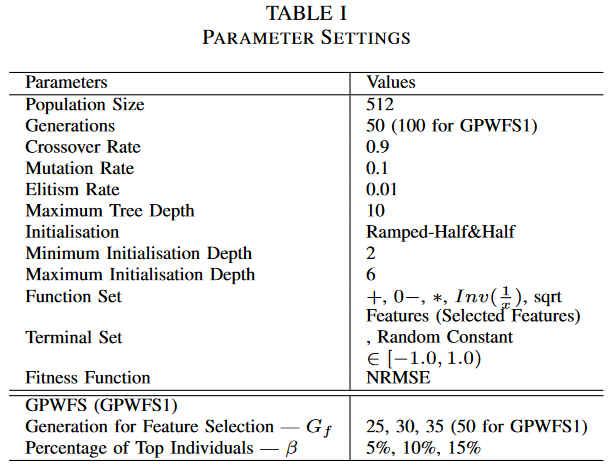
在每次进行特征选择的RF中,建立一个500棵树的森林。定义每个节点随机选择的候选特征的大小为 m/3,其中m为数据集上的特征总数。该值是回归的推荐值[35]。在RF中使用相同的设置进行回归。在C5.0中,参数"度量"被设置为"分裂",即与每个特征相关的分裂的百分比将参与计算特征重要性。其他参数采用默认值。C5.0和RF中的特征选择标准与GPPI相同,即选择重要性值为正的特征。如前所述,我们假设这些特征具有降低回归误差的潜力。因此,它们更为重要,应该加以选择。该选择标准具有与问题无关的优点。与只选择顶级特征相比,可以降低部分重要特征(特别是当顶层特征是冗余的时候)缺失的风险。
在相同的计算时间下,对GP和GP-GPPI进行了比较,同时考察了较高的计算量对GP-GPPI结果的影响。在这组实验中,GP-GPPI的种群规模增加到1024,而其他参数与表1相同。标准GP的种群规模为2048,当它使用与GP-GPPI (特征选择和回归的时间)相同的计算时间时将被终止。
C. Datasets
本文在6个高维回归数据集上进行实验。其中两个数据集是人工合成数据,另外四个数据集是真实世界的高维数据。这两个含有噪声的合成数据集中的相关特征是已知的,这使得这些数据集特别适合用来检验特征选择方法的能力[ 52 ]。两个合成数据集的功能如表II所示。F1为著名的牛顿万有引力定律,g为万有引力常数,取值为6.67408 E - 11。F2取自文献[ 53 ]。训练数据和测试数据的采样策略也在表II中给出。添加到每个数据集中的噪声由50个输入变量组成,随机值在[ 0、1 ]范围内。添加噪声的目的是检验特征选择方法是否能够消除噪声,选择出真正相关的特征。
四个现实世界的回归数据集取自UCI [ 54 ]和以前的文献关于符号回归的GP的推广[ 55 ],[ 56 ]。它们是具有数百到数千个特征的高维回归数据集。对于这些数据集,特征选择比具有较少特征数的数据集更为重要。第一个数据集LD50是关于药代动力学的,它的任务是预测药代动力学参数的值-半数致死量(以LD50表示)。最近许多关于广义多项式推广的工作都用到了广义多项式[ 55 ],[ 56 ],[ 57 ]。第二个数据集为弥漫大B细胞淋巴瘤(以DLBCL为代表),该数据集来自罗森瓦尔德等[ 58 ]。其任务是预测接受化疗的弥漫大B细胞淋巴瘤患者的生存时间。其余两个数据集取自UCI [ 54 ]。它们分别是关于美国境内的社区和犯罪、社区和犯罪非正常化数据集( CCUN )和社区和犯罪正常化数据集( CCN )。两者都是为了预测人均犯罪量。我们舍弃了有缺失值的实例,因此本文使用的CCUN和CCN中的实例数量比原始数据少
D. The Training Sets and the Test Sets
在这项工作中,每个数据集被分成训练集和测试集,以研究GP中的演化模型在未知数据上的泛化性能。6个数据集(包括两个合成数据集)的特征数、训练实例数和测试实例数如表III所示。将6个数据集(除DLBCL和F2外)中的4个进行拆分,从数据集中随机选取70 %的实例进行训练,另外30%的实例组成测试集。这是机器学习中一种被广泛接受的数据集分割方式[ 11 ],[ 56 ]。训练集和测试集均在DLBCL中提供。训练数据点和测试数据点的数量在F2 [ 53 ]中给出。
在特征选择过程中,所有特征选择方法可利用的数据仅为训练集。在特征选择和模型训练过程中,保持每个任务的测试集不可见,以便能够公平地比较特征选择方法对GP泛化的影响。在每个用于特征选择的GP中,进一步拆分训练集,其中随机选择的70 %的实例组成子训练集,另外30 %的实例组成子测试集,以获得特征重要性。在C5.0中使用相同的子训练集。RF使用辅助程序的全部训练集和(即子训练集)的若干样本构造树,获得特征在袋外样本上的排列重要性
V. COMPARING GP-GPPI WITH GP-C5.0 AND GP-RF
本部分将对GP-C5.0、GP-RF和GP-GPPI进行比较。采用标准GP作为基线进行比较。3种特征选择方法(C5.0、RF和GPPI)对GP进行符号回归的能力和泛化能力学习的影响比较
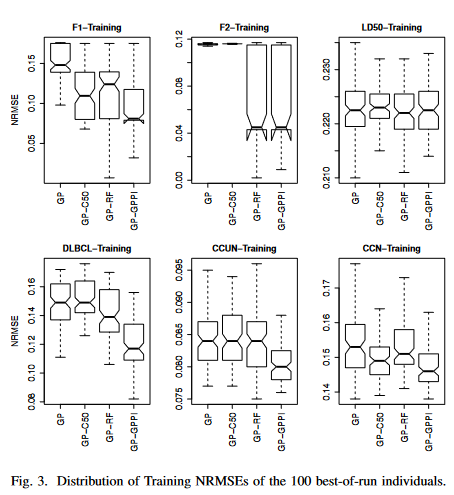
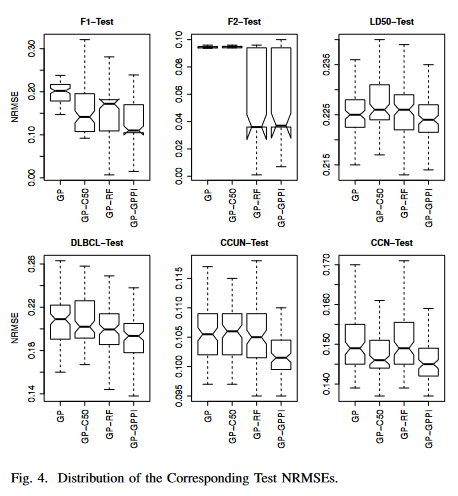
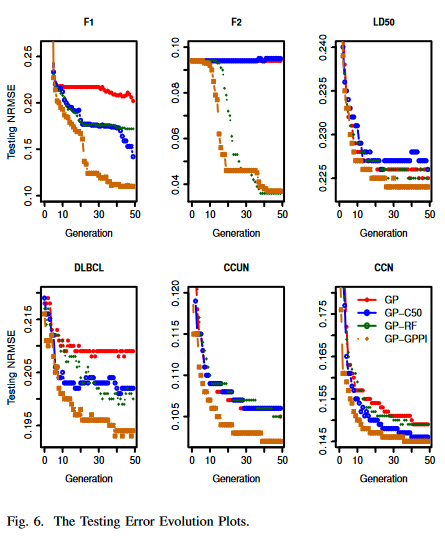
图3给出了在6个数据集的训练数据上,从100个GP回归运行的100个最佳个体的训练NRMSEs的分布,而图4给出了它们相应的测试NRMSEs的分布。每个箱线图由4种GP方法的4个须盒组成,分别为(在F2上, GP - RF和GPGPPI的陷窝箱线图看起来与其他结果不同,这是因为第一四分位数过于接近结果的中位数)。
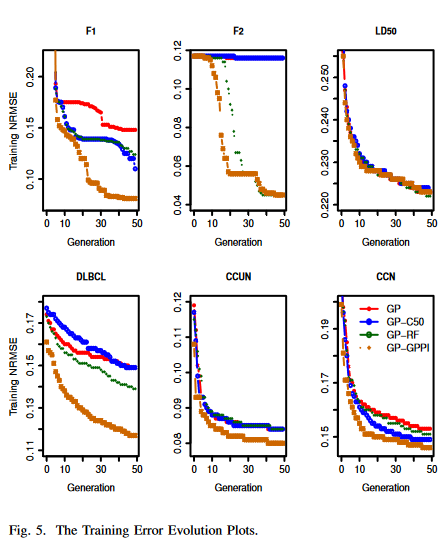
图5和图6给出了数据集的演化图。在每一代上,记录训练集上最低的NRMSEs,同时也得到个体对应的测试NRMSEs (试验误差用于检验概化的进化,但在进化过程中从未考虑过)。对于100次GP运行,每代收集100个最低训练NRMSEs和测试NRMSEs。由于中位值被认为对异常值更鲁棒[ 11 ],在这项工作中,它比平均值更受欢迎。使用100个NRMSEs的中值绘制了演化图。采用非参数统计显著性检验- - Wilcoxon检验比较100个训练NRMSEs和100个最佳运行模型的检验NRMSEs。对GP-GGPI与其他3种方法及GP与GP-RF ( GP采用GP - C5.0)进行Wilcoxon秩和检验。显著性水平为0.05。
A. Results on the Training Sets — Learning Ability
To investigate and demonstrate the effect of the feature selection methods on the learning ability of GP for highdimensional regression tasks, the regression performance regarding the training NRMSEs are reported here.
图 3 和图 5
B. Results on the Test Sets — Generalisation Ability
图 4 和 图 6
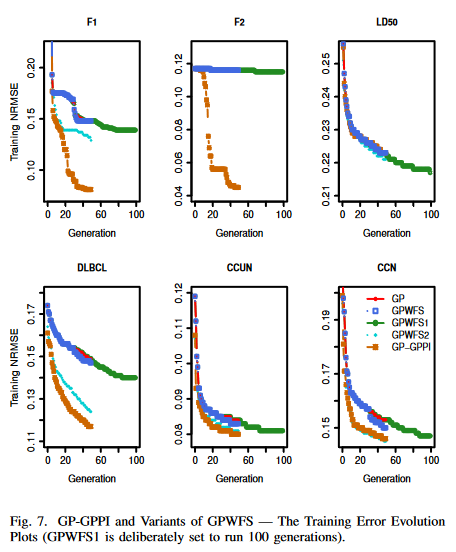
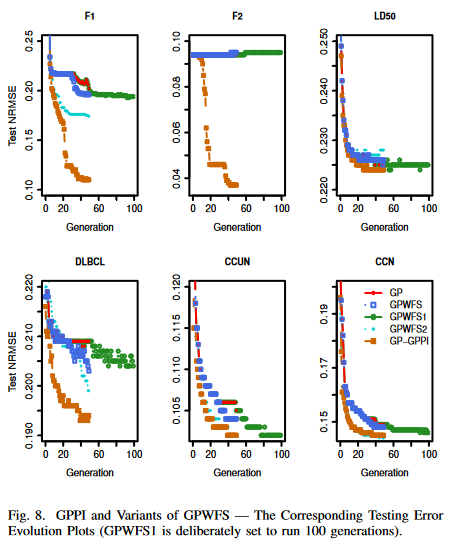
VI. COMPARISONS BETWEEN GP-GPPI AND VARIANTS OF GPWFS
图 7 和 图 8
VIII. CONCLUSIONS AND FUTURE WORK
总结: 本文提出了一种面向高维符号回归的GP特征选择新方法GPPI。GPPI收集出现在多个运行最好的GP个体中的特征,并使用排列测度获得特征的重要性。特征选择是基于重要性值的。特征选择结果表明,与RF在发现重要特征的同时存在冗余特征相比,GPPI能更有效地识别真正相关的特征。采用不同特征选择方法的GP的回归结果表明,GPPI不仅在提高GP的学习性能方面优于RF和C5.0,而且在GP的推广方面也取得了更好的效果。GP-GPPI在提高GP的学习性能和泛化能力方面也优于GPWFS。对演化模型的进一步分析表明,GP-GPPI 在仅包含真正相关特征的演化模型上优于其他方法。一般而言,这些模型更容易理解。
未来展望: 在不久的将来可以进一步研究几个有趣的方向。GPPI 识别真正相关特征的能力仅在本文的两个合成数据集上得到证实。我们希望找到更多的真实数据集,其中真正相关的特征是事先知道的,以进一步调查和更有信心的GPPI的特征选择能力。同时,由于本工作的重点是特征选择作为提高GP通用性的一种方法,因此主要比较了不同的特征选择方法。
GP-GPPI与其他一些先进的提升GP泛化性能的方法,如将模型复杂度作为GP的第二个目标的 Pareto GP [13] [17],以及通过操作训练样本来提升GP泛化性能 [60] [61] 的比较也将在不久的将来进行研究。此外,我们打算研究GPPI是否能促进RF的回归/分类性能。RF中基于排列重要性和 Gini 重要性的特征选择对增强回归/分类树的预测能力的效果也值得探究。
Reference
Chen Q, Zhang M, Xue B. Feature selection to improve generalization of genetic programming for high-dimensional symbolic regression[J]. IEEE Transactions on Evolutionary Computation, 2017.
算法原理梳理
Randomly Split 将数据集划分为训练集和测试集。
Sub-training Data 对训练集运行 GP 算法,并选出误差最低的个体(函数表达式)
I
b
I_b
Ib
在测试集 (Sub-test Data) 上计算个体
I
b
I_b
Ib 的误差
E
r
r
o
r
g
(
I
b
)
Err_{org} (I_b)
Errorg(Ib)。
接下来通过全排列计算个体
I
b
I_b
Ib 中特征的重要性,详细计算如下:
(1)提取个体
I
b
I_b
Ib 的所有特征
(2)衡量某个特征重要性的方式,通过随机打乱或全排列某列 (即某个特征下) 的数据,其他列不变,在测试集上计算当前的误差
E
r
r
p
m
t
(
I
b
)
Err_{pmt} (I_b)
Errpmt(Ib)
(3)计算
E
r
r
o
r
g
(
I
b
)
Err_{org} (I_b)
Errorg(Ib) 和
E
r
r
p
m
t
(
I
b
)
Err_{pmt} (I_b)
Errpmt(Ib) 之间的距离,并根据如下公式衡量原始特征
F
I
r
a
w
(
X
j
)
FI_{raw}(X_j)
FIraw(Xj) 的重要性:(到这里并未结束)
为了使根据重要性值进行的特征选择具有灵活性和问题无关性,特征的最终重要性定义为比例重要性,即原始特征重要性的标准误差归一化后的平均原始特征重要性。其给出为:
其中 n n n 为 GP 运行次数, F I r a w ( X j ) ‾ \overline{FI_{raw}(X_j)} FIraw(Xj) 为 n 次 GP 运行中原始特征重要性的平均值, δ δ δ 为标准差, δ n \frac{δ}{\sqrt{n}} nδ 为标准误差。
总结:1. 2017,TEVC,Feature Selection to Improve Generalisation of Genetic Programming for High-Dimensional SR
原文见: https://blog.csdn.net/qq_46450354/article/details/128653975 (实验部分未加入)
概述: 高维数据进行符号回归时,遗传规划通常不能很好地泛化,本文提出了一种新的基于排列的特征选择方法,使用遗传编程来选择高维符号回归的特征。
未来展望: 特征提取能力仅在两个合成数据集上得到证实,可以通过更多真实数据集证实其特征选择能力
研究点提取: 高维数据在进行 SR 之前,首先进行有效的特征选择。文章提出的特征选择是作为一种数据预处理,还可将特征选择嵌入到算法执行过程中。
算法原理
Randomly Split 将数据集划分为训练集和测试集。
Sub-training Data 对训练集运行 GP 算法,并选出误差最低的个体(函数表达式)
I
b
I_b
Ib
在测试集 (Sub-test Data) 上计算个体
I
b
I_b
Ib 的误差
E
r
r
o
r
g
(
I
b
)
Err_{org} (I_b)
Errorg(Ib)。
接下来通过全排列计算个体
I
b
I_b
Ib 中特征的重要性,详细计算如下:
(1)提取个体
I
b
I_b
Ib 的所有特征
(2)衡量某个特征重要性的方式,通过随机打乱或全排列某列 (即某个特征下) 的数据,其他列不变,在测试集上计算当前的误差
E
r
r
p
m
t
(
I
b
)
Err_{pmt} (I_b)
Errpmt(Ib)
(3)计算
E
r
r
o
r
g
(
I
b
)
Err_{org} (I_b)
Errorg(Ib) 和
E
r
r
p
m
t
(
I
b
)
Err_{pmt} (I_b)
Errpmt(Ib) 之间的距离,并根据如下公式衡量原始特征
F
I
r
a
w
(
X
j
)
FI_{raw}(X_j)
FIraw(Xj) 的重要性:
详细原理见原文中: III. THE PROPOSED FEATURE SELECTION METHOD














 234
234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









