








Abstract
在遗传规划中,搜索算法(交叉,变异)期望产生最终计算状态的程序(期望输出)。为了达到该状态,执行程序需要遍历某些中间计算状态。一个进化搜索过程被期望能够自主发现这样的状态。这对于需要长时间程序才能解决的 nontrivial tasks 来说可能是困难的。本文提出的语义反向传播算法通过启发式地反转演化程序(heuristically inverts the execution of evolving programs)的执行来确定所需的中间计算状态。两个搜索算子,随机期望算子 (Random Desired Operator, RDO) 和近似几何语义交叉 (Approximately Geometric Semantic Crossover, AGX),使用语义反向传播确定的中间状态定义原始编程任务的子任务,然后使用穷举搜索求解。该算子在一组符号回归和布尔基准 (Boolean benchmarks) 上的表现优于标准遗传搜索算子和其他语义感知算子。该结果和本研究中进行的额外分析表明,语义反向传播有助于进化识别所需的中间计算状态,并使搜索过程更有效。
I. INTRODUCTION
自动编程任务中的目标是合成一个表现出某种期望行为的程序。期望行为通常通过将期望的程序输出指定为程序输入的函数来定义。这可以通过显式地枚举所有相关的输入输出对(或其样品)来实现,也可以通过隐式地定义程序响应必须优化的目标来实现。
除了平凡的情况 (trivial cases) 外,通过对输入数据施加单一的指令无法实现期望的输入输出行为。根据编程范式的不同,指令的组合是必要的:序列、树或图。指令(语法)的组合以复杂的方式决定程序行为(语义)。这种特性被称为适应度景观的鲁棒性 [1] 或低因果性 [2],使得很难设计出与任务复杂度相匹配的自动编程算法。
解决编程任务的一个简便的方法是将它们作为搜索问题:一个搜索算法运行程序,观察它们的行为,并使用这些信息来指导搜索过程。在遗传编程( genetic programming,GP )中,这个过程涉及到生物启发的变异和选择机制,以及一个适应度函数,它量化了实际程序输出与期望输出(下面的目标)的匹配程度。
在传统的GP中,适应度只取决于程序执行的最终效果;中间效应,如程序树的子树计算的值,或线性GP中寄存器的瞬态,均被忽略。这种选择性是被普遍接受的:最终,只有最终的结果决定了编程任务是否得到了解决。然而,这与程序员所行使的编程过程形成了鲜明对比。当面临非平凡任务 (nontrivial task) 时,程序员将其拆分为子任务,并试图独立或半独立地解决。这种策略往往被证明是有效的,因为程序员往往事先知道哪些中间执行状态是期望的,哪些不是。例如,对于一个编程任务 “设计一个算法来计算一个数字数组的中位数”,这样一个期望的中间值是按升序或降序排序的输入数组。
分解任务的能力使程序员能够在自动编程方法仍然难以解决的任务上出类拔萃。因此,我们非常希望GP算法具有类似的能力,我们在之前的研究 [3],[4],[5]中假设了这一点。
在本文中,我们提出了一种在求解给定的编程任务时确定哪些中间计算状态是可取的方法。该方法利用了程序执行可以在一定程度上反转的事实:对于任意计算状态(例如,工作记忆或其他执行环境的状态),通过执行单个指令可以实现的其他状态的数量是有限的(虽然潜在的大)。因此,可以还原对给定输出执行指令序列的影响(尽管在某些情况下模棱两可)。这种语义反向传播的过程允许我们确定一个期望的中间记忆状态(子目标),进而定义一个特定的编程子任务。求解子任务需要考虑的程序空间是原始搜索空间的一个子空间,因此可以更高效地进行搜索。
本文的主要贡献是演示了如何将这种思想(第三和第四节介绍了)用于变异和交叉算子(Sec.V)。与我们最初提出这些算子的 [6],[7] 相比,在这里我们给出了语义反向传播的一个广义版本,将搜索算子嵌入到一个通用的形式化框架中,并在广泛的基准上进行详细的检验 (Sec.VI)。
II. RELATED WORK
本文关注程序行为,反映了对语义GP的兴趣不断增长。语义GP不是专注于程序,而是专注于研究程序执行的影响,并利用这些影响的知识来设计更有效的GP搜索算法。除了 Langdon [8] 的基础分析研究外,Mc Phee 等人首次研究了交叉对程序语义和语义构建块的影响 [9]。据我们所知,最早研究了交叉对程序语义和语义构建块的影响 [9]。他们定义了在树交换交叉中形成后代的组件的语义属性,即子树和上下文(有悬挂枝的部分树木),并观察它们如何随着布尔问题 (Boolean problems) 的演化而变化。在早期的另一项研究中,Beadle 和 Johnson [10] 针对布尔问题提出了一种语义驱动的交叉算子,保证子代在语义上与父代和子代都不同。Jackson 在 [11] 中分析了初始群体的语义多样性。最近,Galvan-Lopez 等人提出了一种抑制语义重复的锦标赛选择 [12]。
Nguyen等 [13] 考虑了两种用于符号回归的语义交叉算子,一种仅当父代中待交换的子树在语义上比给定的下限(方法的一个参数)更远时才允许交叉,另一种对距离有额外的上限。后来,Nguyen 等[14] 提出了一个算子,从父代中待交换的有效子树对集合中,选择最小但超过下限距离的子树对,从而降低上限参数。这里采用的语义表示,即程序为所有训练样本(适应度案例)返回的一个数字向量,是目前语义GP中应用最广泛的一种,本文也采用了这种表示。在类似意图的驱动下,Day 和 Nandi 虽然没有明确提到程序语义,但使用二进制字符串来表征种群中的个体如何应对特定的适应度情况,并设计了利用这些信息的交配策略 [15]。
Moraglio等 [16],[17] 最近的工作采用了一种定性不同的方法。支撑他们方法的关键观察是,GP中的适应度函数通常被定义为程序语义和预定义目标语义之间的距离。这将语义集合转化为具有一定几何性质的度量空间,可以利用这些几何性质使搜索过程更加高效。作者提出了两个依赖于该原理的搜索算子,包括一个精确的几何交叉,保证产生相对于其父代语义中间的子代(即,结合他们的行为)。这是通过使用一个额外的句法结构将父程序合并成子程序来实现的。类似地,Krawiec 和 Pawlak [18] 提出了一种近似几何的交叉算子。其中一些几何算子作为控制方法在第Section VI 部分介绍.在这些研究的背景下,本文提出的方法在尝试语义层面的问题分解时保持了原创性。在第四节中,语义反向传播使用了类似于可逆计算的概念 [19],该范式假设计算的效果总是可以逆转的。在该框架中,每条指令都必须实现一个转换函数,以一对一的方式,即单射的方式将执行环境(例如,寄存器,内存)的当前状态转换到另一个状态,即内射性 (injectively)。难怪它成为量子计算中许多研究者感兴趣的领域,并且在遗传编程中也被研究。文献 [2 ] 中的 Langdon 分析了可逆程序的适应度分布,发现它是正常的。在文献 [21] 中,多表达式编程(Multi Expression Programming)[22]和 Fredkin gate 被用来解决偶宇称问题(even-parity problems)。
不幸的是,可逆计算主要是一个理论领域,因为它假定了一个强大的、内射的可逆性概念,而传统的编程语言中充斥着不可逆的指令。为此,我们在这里提出了一个更宽松的程序反转的概念,它允许指令实现多对一映射(投射)。
III. BACKGROUND ✨
A. Program semantics
正如引言中提到的,在解决一个编程任务时,我们主要对程序行为感兴趣 (程序做了什么)。在正式定义编程任务之前,必须首先明确什么是程序行为。为此,我们引入程序语义的概念。
设 p ∈ P p∈P p∈P 是一个程序,即来自给定编程语言 P 的符号序列(或其他结构)。当应用于一个输入 i n ∈ I in∈I in∈I 时,程序 p p p 产生确定的输出 p ( i n ) p(in) p(in)。这样,程序就实现了从输入集合 I I I 到输出集合 O O O 的某种映射,记为 p : I → O p:I→O p:I→O
定义 1 语义映射 (Semantic mapping) 是一个函数 s : P → S s:P→S s:P→S 将任意程序从 P P P 映射到语义空间 S S S,具有如下性质:

让我们总结一下由这个定义产生的语义的性质。首先,每个程序只有一个语义。其次,两个或多个程序可以具有相同的语义。第三,不同行为的程序 (即对一个或多个输入产生不同的输出) 具有不同的语义
语义空间 S S S 列举了程序对于所有考虑的输入的所有可能行为。映射 s s s 隐式地将程序划分为语义等价类,使得 S S S 中的每个元素一一对应于程序产生的唯一输出组合。从这个意义上说,语义 (semantics) 在捕捉关于程序行为的全部信息上是完整的,当 s ( p ) s(p) s(p) 已知时,不需要更多的判断 p p p 的行为。
定义 1 没有说明语义是如何表示的。它可以是任何满足其中规定的条件的形式对象,包括形式语言理论中使用的指称语义或操作语义。注意,程序的代码(即一个符号序列)不能被认为是它的语义,除非语义映射是双射 (这是实践中从未有过的)。
在本文中,我们采用GP中常见的约定,并假设一个编程任务是由有限个适应度案例 (fitness cases) 的训练样本指定的,每个 fitness case 是由程序输入和相应的期望程序输出组成的一对。然后,A fitness case 是 I × O I × O I×O 中的一对。我们还假设 I I I 只包含给定的 fitness cases 集合中的输入,符合机器学习中的样例学习范式,其中学习者无法访问其他(测试)示例。在这些假设下,我们可以更具体地定义语义:
补充: a fitness case 是用来衡量 GP 性能的一系列问题之一。GP产生个体过程中通常会在发现一个解决方案在 fitness case 上得分高于某个阈值时,或者当经过一定的时间步长而没有发现这样的解决方案时得出结论。如某个节点的期望语义是 {-2, 0, 0},这个期望语义即为 fitness case
定义 2 程序 p p p 的语义 s ( p ) s(p) s(p) 是在 I I I 的所有输入上运行 p p p 得到的来自 O O O 的值的向量2:


- 根据上下文,我们可以交换使用 “向量” 和 “元组” 这两个术语。在两种情况下,向量/元组的第 i i i 个元素都对应第 i i i 个测试 (fitness case)。
其中 l = ∣ I ∣ l = |I| l=∣I∣ 为 fitness cases 的数量
GP [23]、[16]、[13]、[18]、[7] 等早期语义研究中流行的这种语义表征符合 定义 1.特别地,它在上述意义上是完备的:因为 s ( p ) s(p) s(p) 明确列举了所有输入的程序行为,它允许我们通过简单地从向量中选择适当的元素,trivially 确定 i n ∈ I in∈I in∈I 中任何元素的程序输出。
B. Programming tasks
语义空间的性质,特别是其元素之间的关系,对于本文提出的方法至关重要。推动语义GP最近发展的关键点是,语义空间天生具有结构。这种结构是由编程任务本身施加给 S S S 的,更具体地说是由衡量实际程序行为与期望程序行为之间差异的适应度函数施加的:
定义 3 给定一组程序 P P P (由编程语言隐式定义),一个编程任务 (Task 简称任务) 包含寻找一个最小化的程序 p ∈ P p∈P p∈P

其中 t ∈ S t∈S t∈S 是描述程序期望行为的目标语义(简称目标), d : S × S → R d:S × S→\Bbb{R} d:S×S→R 是一个度量,称为语义距离。对于一个 f ( p ) = 0 f(p) = 0 f(p)=0 的程序 p p p,我们称它解决了任务 t t t。
补充: s ( p ) s(p) s(p) 为将输入带入程序并映射的一组向量,产生的实际语义, t t t 为期望的目标语义
从现在开始,我们将术语"目标"和"编程任务"互换使用,因为在其他条件相同的情况下,目标唯一地标识了编程任务。
作为例子,我们考虑一类单变量符号回归任务,其中程序是单个实自变量的实值函数,即
I
⊂
R
I \subset \Bbb{R}
I⊂R 和
O
⊂
R
O \subset \Bbb{R}
O⊂R 。任务由
I
×
O
I × O
I×O 中的
l
=
∣
I
∣
l = | I |
l=∣I∣ 适应案例 (fitness cases)
(
i
n
i
,
t
i
)
( in_i , t_i)
(ini,ti) 指定,其中
i
n
i
∈
I
in_i∈I
ini∈I 是程序输入,
t
i
t_i
ti 定义相应的期望输出3。程序
p
p
p 的语义
s
(
p
)
s(p)
s(p) 是通过将
p
p
p 应用于
I
I
I 的元素而得到的
l
l
l 个实数的向量。程序的最小适应度由程序语义与目标
t
t
t 之间的欧氏距离或曼哈顿距离
d
d
d 定义。

- 集合 I I I 只包含发生在训练集中的输入。然而,这并不妨碍演化程序适用于其他输入(由 R \Bbb{R} R \ I I I ),例如评估程序的泛化能力。
GP中考虑的大多数编程任务在适应度案例 (fitness cases) 和语义距离方面定义类似。例外是没有明确指定目标的任务,如进化控制器(例如,极点平衡、人造蚂蚁、机器人学等)。对于此类任务,适应度评估是隐式的,例如基于仿真的结果,不能直接应用涉及目标的语义方法。在本文介绍的两个算子中,一个 (RDO , Section V-B) 需要目标的知识,而另一个 (AGX , Section V-C) 不需要目标的知识,因此本文提出的方法可以适用于广泛的GP任务。
IV. INVERSION OF PROGRAM EXECUTION ✨
A. The rationale for inversion 反演的原理
编程任务 (定义 3 ) 一般很难解决,因为从组合程序空间到语义空间的映射通常非常复杂。然而,当语义是程序针对特定的适应度情况所产生的输出向量时 (公式 1 ) ,语义映射 s : P → S s:P→S s:P→S 就不再是黑盒体。在这种情况下,形成语义的向量的每个组成成分都是一个序列过程的结果,其中特定的程序指令处理其前一个指令的结果,最后一个指令的执行完成语义(对于单个 fitness case)的计算。该过程的可分解性是本文方法的关键。
我们假设任何程序 p p p 都可以分解为它的前缀 (prefix) p ( 1 ) p_{(1)} p(1) 和后缀 (suffix) p ( 2 ) p_{(2)} p(2),这里采用的反向波兰记法 (Reverse Polish Notation) 记为

对输入数据 i n in in 执行这样的复合程序涉及到将后缀 p ( 2 ) p_{(2)} p(2) 应用于前缀 p ( 1 ) p_{(1)} p(1) 产生的结果,即 p ( i n ) = p ( 2 ) ( p ( 1 ) ( i n ) ) p(in) = p_{(2)} ( p_{(1)}(in) ) p(in)=p(2)(p(1)(in))。在这个公式中,我们从程序表示中抽象出来。对于指令序列,前缀和后缀也采取序列的形式。对于无副作用的树形程序(这在本文中我们限制了关注点),前缀是程序的任意子树,后缀是删除了单个子树的程序树(在 [9] 中称为上下文)。不管表示方式如何,我们假设前缀是一个形式良好的(子)程序,可以执行。因此,每个前缀也会像定义 1 中描述的那样具有特定的语义。
如果考虑的任务 t t t 是可解的,则存在一个程序 p ∗ p^* p∗,使得 s ( p ∗ ) = t s(p^*) = t s(p∗)=t。设 p ( 1 ) ∗ p^*_{(1)} p(1)∗ 是 p ∗ p^* p∗ 的前缀, p ( 2 ) ∗ p^*_{(2)} p(2)∗ 是相应的后缀。关键的点是 p ( 1 ) ∗ p^*_{(1)} p(1)∗ 决定了 (可以作为另一个编程任务的目标的) 语义 s ( p ( 1 ) ∗ ) s(p^*_{(1)}) s(p(1)∗)。我们称 p ( 1 ) ∗ p^*_{(1)} p(1)∗ 决定一个子目标 t ′ = s ( p ( 1 ) ∗ ) t^′= s(p^*_{(1)}) t′=s(p(1)∗)。任何求解由子目标 t ′ t^′ t′ 定义的子任务的程序 p s p_s ps 都可以作为 p ∗ p^* p∗ 中 p ( 1 ) ∗ p^*_{(1)} p(1)∗ 的替代。形式上,若 s ( p s ) = t ′ s(p_s) = t^′ s(ps)=t′,则程序 [ p s p ( 2 ) ∗ ] [ p_sp^*_{( 2 )}] [psp(2)∗] 求解任务 t t t,即 s ( [ p s p ( 2 ) ∗ ] ) = t s([ p_sp^*_{( 2 )}]) = t s([psp(2)∗])=t。
类似地,后缀 p ( 2 ) ∗ p^*_{(2)} p(2)∗ 可以说决定了一组子任务,即一组这样的语义 t ′′ t^{′′} t′′, s ( [ t ′′ p ( 2 ) ∗ ] ) = t s([t^{′′}p^*_{(2)}] ) = t s([t′′p(2)∗])=t。由前缀决定的子任务 t ′ t^′ t′ 就是其中之一,但由于程序指令的多对一操作,可以有更多这样的子任务 t ′′ t^{′′} t′′。我们在 Section IV-B 中将这个概念形式化为所需的语义。
由于每个子任务的解都会形成至少一个原任务的解的前缀,并且任何(恰当的)前缀都比它所在的程序短,因此可以合理地假设一个子任务比原任务更容易求解。假设求解一个规划任务的计算成本是最短解长度的单调增函数4,求解一个子任务而不是原任务可能会带来大量的节省。

- 考虑一个蛮力算法,它试图通过生成所有程序来解决编程任务,从最短的程序开始并逐渐增加它们的长度。给定两个分别具有最短解 p p p 和 [ p p ′ ] [pp^′] [pp′] 的规划任务,该算法将较早地找到前一个任务的解。从这个意义上讲,可以预期一个子任务比整个任务更容易解决。显然,对于更复杂的搜索算法如GP,这个论点并不总是成立的。
然而,上述子任务都是从给定的最优方案中派生出来的,即求解原任务的已知方案。实际问题是:我们能否定义一个任务的子任务而不首先解决后一个任务?
我们认为,即使从非最优的程序中也可以得到有用的子任务候选。考虑一个进化过程的种群(或任何其他增量搜索算法)。在这样的种群中很可能有些程序包含了发生在所寻求的最优程序中的指令子序列。特别地,一些这样的 “正确” 子序列可能构成程序的后缀。这里值得注意的是,早期关于语义GP的研究,特别是 Mc Phee 等[9]强调了识别正确程序后缀的重要性。
设 p p p 是一个具有正确后缀的程序,即一个后缀是最优程序 p ∗ p^* p∗ 的一部分,即 p = [ p ( 1 ) p ( 2 ) ∗ ] p = [p_{(1)}p^*_{(2)}] p=[p(1)p(2)∗] .假设我们可以反演 p ( 2 ) ∗ p^*_{(2)} p(2)∗ 的执行,即直接计算任意子目标5 t ′′ t^{′′} t′′ 使得 s ( [ t ′′ p ( 2 ) ∗ ] ) = t s([t^{′′}p^*_{(2)}] ) = t s([t′′p(2)∗])=t .然后, t ′′ t^{′′} t′′ 将定义一个子任务,由于上面给出的原因,该子任务更容易求解。
在下一节中提出的语义反向传播是寻找此类子任务的有效启发式。
B. Semantic backpropagation
语义反向传播算法找到给定目标的子目标和所表示一个树形程序的后缀,为了达到这个目的,它将后缀的执行反转为目标指定的期望输出。
由于一般情况下可能存在无穷多个子目标 t ′′ t^{′′} t′′,使得 s ( [ t ′′ p ( 2 ) ∗ ] ) = t s([t^{′′}p^*_{(2)}] ) = t s([t′′p(2)∗])=t,因此算法并不能保证确定所有子目标,而只能确定其中的一个子集。为了有效地表示这样的子集,我们使用期望的语义 (desired semantics)
定义 4 规划任务 t t t 和后缀 p ( 2 ) p_{(2)} p(2) 的期望语义是对应于 t t t 的特定成分的集合 D i D_i Di 的元组 D = ( D i ) D = ( D_i ) D=(Di),其中每个 D i D_i Di 包含由后缀 p ( 2 ) p_{(2)} p(2) 定义的第 i i i 个适应度情形的期望值,即:

换句话说, D i D_i Di 包含一组值 x x x,使得后缀在第 i i i 个适应度案例 (fitness case)上到达目标。这些值构成了由 p ( 2 ) p_{(2)} p(2) 定义的子目标对 t t t 的第 i i i 个 fitness case 的期望输出。 D i D_i Di 可以包含满足等式 3 的任意一组这样的输出, 不一定全部。
算法 1 给出了 SEMANTICBACKPROPAGATION 过程,该过程启发式地计算由给定后缀确定的期望语义。虽然求逆过程只需要程序后缀,但为了方便起见,我们假设程序的参数为程序树 p p p 和该树中的节点 n n n。节点 n n n 明确标识后缀(见图 1)。
- 算法 1 树型程序的语义反向传播算法。参数: t t t:目标语义, p p p:程序树, n n n:反向传播要到达的 p p p 中的节点。CHILD ( a , n ) (a , n) (a,n) 返回节点 a a a 在从 a a a 到 n n n 的路径上的子节点,POS ( a , n ) (a , n) (a,n) 返回子节点在节点 a a a 的参数列表中的位置。INVERT ( a , k , o ) (a , k , o) (a,k,o) 返回节点 a a a 的第 k k k 个参数的期望值和期望输出 o o o 的集合,如 表 I 所示。

对于给定的目标 t ,SEMANTICBACKPROPAGATION ( t , p , n ) t,\text{SEMANTICBACKPROPAGATION}( t , p , n) t,SEMANTICBACKPROPAGATION(t,p,n) 计算与由 p p p 和 n n n 决定的后缀相关的期望语义。对于每个 fitness case t i t_i ti 独立地对路径上的节点进行从 p p p 到 n n n 的遍历。它首先通过位于根节点的指令传播原始目标的第 i i i 个分量 t i t_i ti。路径上连续指令的反转由线路 5-11 中的循环进行。对于工作集 (working set) 中的每一个 o o o 的期望值 D i D_i Di,调用 INVERT 函数确定当前节点 a a a 的第 k k k 个子节点的期望值,其中该子节点为路径上的下一个节点。
我们用一个例子来说明这个过程,其中 SEMANTICBACKPROPAGATION 用 于目标 t = [ − 2 , 0 , 0 ] t=[ - 2, 0, 0] t=[−2,0,0],程序 p p p 如图 1 所示, n n n 是用蓝色标记的节点。 p p p 中子树的语义用黑框表示。考虑第一种适应度情形,期望输出为 − 2 -2 −2 .算法从根节点开始。由于 n n n 在根的右子树中,因此算法将为根指令 (‘-’) 的右参数确定集合 D 1 D_1 D1。目前,该节点计算 1 − ( − 1 ) = 2 1 - ( -1 ) = 2 1−(−1)=2。该算法试图找出正确参数 (x) 的值应该是多少才能使结果满足目标 − 2 -2 −2,即 1 − x = − 2 1 - x = - 2 1−x=−2。这可以通过反演计算得到,因此算法以 x = 1 − ( − 2 ) = 3 x = 1- ( -2 ) = 3 x=1−(−2)=3 结束。该值成为向根节点(蓝色虚线框)的右子节点传播的期望语义的第一个元素,与其余两个适应度情况独立计算的值一起。产生的期望语义 ( 3 , 2 , 3 ) ( 3,2,3) (3,2,3) 成为后续步骤反向传播 (指令 × × ×) 的起点。
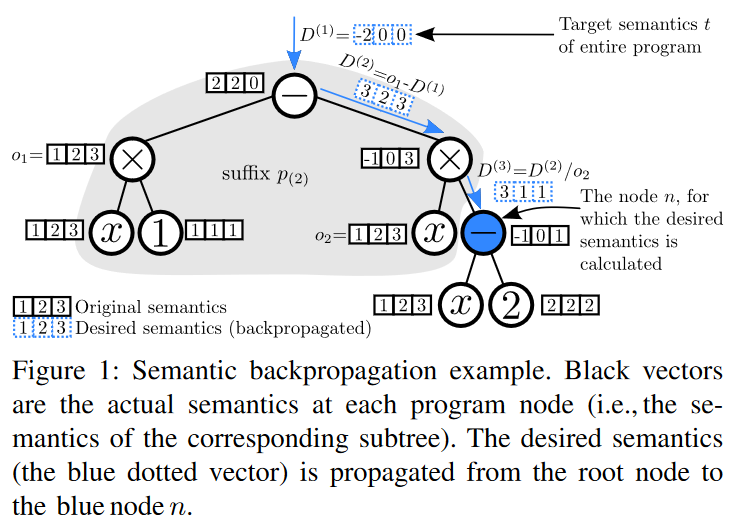
图1:语义反向传播示例。黑色向量是每个程序节点(即对应子树的语义)上的实际语义。期望的语义(蓝色点状矢量)从根节点传播到蓝色节点 n n n。
表 I 中定义的函数 INVERT 针对所有剩余参数构成的特定上下文,在子树 a a a 的根上执行单个指令关于其第 k k k 个参数的反转。如果 a a a 有两个或多个参数,INVERT 的结果不仅取决于 a a a 的输出,还取决于 a a a 的其他参数(上下文)提供的值。例如,INVERT 应用于图 1 所示的第一个适应度案例 (fitness case) 和程序的根节点,即 INVERT ( c 1 − c 2 , 2 , o ) ( c_1-c_2 , 2 , o) (c1−c2,2,o),在 c 1 = 1 c_1 = 1 c1=1 和 o = − 2 o = - 2 o=−2 上运行。根据表 I 的第二行返回 INVERT ( 1 − c 2 , 2 , − 2 ) ( 1-c_2 , 2 , -2) (1−c2,2,−2),即 c 1 − o = 1 − ( − 2 ) = 3 c_1 - o = 1- ( - 2 ) = 3 c1−o=1−(−2)=3。
表I:符号回归和布尔域实验中使用的 INVERT ( a , k , o ) ( a , k , o) (a,k,o)的定义。对于子树 a a a (具有一个或两个返回 c 1 c_1 c1 和 c 2 c_2 c2 的子节点的指令节点),在给定整个子树 a a a 的期望值的情况下,由公式确定第一个( k = 1 k = 1 k=1 ,中心柱)和第二个( k = 2 k = 2 k=2 ,右列)参数的期望值。

对于这样的双射指令,求逆是无歧义的,即 INVERT ( a , k , o ) ( a , k , o) (a,k,o) 返回单个值。否则,INVERT 在返回多个期望值时可能是模棱两可的。例如,INVERT为 l o g ∣ ⋅ ∣ log | · | log∣⋅∣ 返回两个值。周期函数可以通过无穷多种方式求逆,因此对于 sin 和 cos,我们将期望值的集合限制为两个任意选择的值。
另一种形式的歧义产生于无效代码。考虑程序 c 1 × c 2 c_1 × c_2 c1×c2,其中 c 2 = 0 c_2 = 0 c2=0. 无论我们用什么代替 c 1 c_1 c1,程序的输出都不发生变化。如果期望输出等于零,则期望值集合包含所有实数。在这种情况下,INVERT 返回特殊符号 ‘*’。
INVERT ( a , k , o ) (a , k , o) (a,k,o) 返回一个空集,如果没有作为第 k k k 个参数传递给 a a a 的值可以使其返回 o o o。例如,指数函数不能产生负值。
在这两种情况下( INVERT() = ∞ ∞ ∞ 或 {*}),进一步传播不能改变 D i D_i Di 的内容,所以 SEMANTICBACKPROPAGATION 停止对路径(算法 1 第 5 行)的遍历,算法进入下一个 fitness case。最后,该算法将每个适应度情况下计算得到的期望值集合 D i D_i Di 聚集成一个元组,并返回该元组作为期望语义。
C. Impact of program inversion on fitness landscape
从技术上讲,语义反向传播只传播从目标(即语义空间中的某些点)得到的特定期望值。然而,得到的期望语义将成为单独搜索过程的子目标,使用我们在下一节中定义的搜索算子。该搜索过程将由与子目标的语义距离驱动。因此,理解与目标的语义距离和与子目标的语义距离之间的关系是至关重要的。
为了提供这种见解,我们考虑一个单变量符号回归问题的例子,其中适应度函数 (公式 2 ) 是欧氏距离。为了简单起见,我们只考虑两种 fitness case,并假设目标 t = ( 0 , 0 ) t = ( 0,0 ) t=(0,0)。与第 III-A 节一致,这里的语义空间是 R 2 \Bbb{R}^2 R2,悬停在其上的适应度景观是一个三维的 “上下颠倒” 的欧氏锥,顶点在 ( 0 , 0 ) ( 0,0 ) (0,0) 点。这种 fitness 景观在图 2 (a) 中呈现为热力图。该热力图中每个点的坐标对应一个假想程序在两种适应度情况下返回的输出 ( y 1 , y 2 ) ( y_1,y_2) (y1,y2),点的颜色反映了程序的适应度。

- 图 2:程序 [ x s i n c o s ] [ x~ sin~ cos] [x sin cos] 对原始 fitness 景观(左)的逆变换。指令按逆序考虑: c o s − 1 cos^{-1} cos−1 (b) 和 [ c o s − 1 s i n − 1 ] [cos^{-1} sin^{-1} ] [cos−1sin−1] (c)。热图在特定的执行点上将整个程序的适应度表示为语义的函数。白色区域适合度最好,深色(红色)区域最差。十字线标记 (a) 中原始任务的目标和 (b) 中的子目标。
现在我们将演示如何通过转换期望的输出,语义反向传播也隐式地转换整个适应度景观(即,不仅图 2 (a) 中的点,而且相应的适应度值)。考虑程序后缀 c o s cos cos。对于图 2 (a) 中热图中的每一点 ( y 1 , y 2 ) ( y_1 , y_2) (y1,y2),我们可以找到所有的点 ( y 1 ′ , y 2 ′ ) ∈ R 2 ( y^′_1 , y^′_2)∈\Bbb{R}^2 (y1′,y2′)∈R2 使得 c o s ( y 1 ′ ) = y 1 cos(y^′_1) = y_1 cos(y1′)=y1 和 c o s ( y 2 ′ ) = y 2 cos(y^′_2) = y_2 cos(y2′)=y2(即进行反转求解),并将它们标记为与 ( y 1 , y 2 ) (y_1 , y_2) (y1,y2) 相同的适应度(颜色)。产生的热图,如图 2 (b) 所示,是由前缀为 c o s cos cos 的程序所看到的转换后的 fitness 景观。对于任意程序 p p p,图 2 (b) 中点 s ( p ) ∈ R 2 s(p)∈\Bbb{R}^2 s(p)∈R2的颜色反映了复合程序 [ p c o s ] [p~ cos] [p cos] 的适合度。该景观有多个子目标(以十字架标记),因为余弦是周期性的。
当 SEMANTICBACKPROPAGATION 沿着从树根到所选节点 n n n ( 算法 1)的路径前进时,适应度景观的反向误差传播网络将继续。给定如图 2 (b) 所示的热图,我们可以对指令 s i n sin sin 进行类似的计算,考虑这样的程序后缀 [sin cos]。该后缀定义的子任务的适应度图如图 2 (c ) 所示。然而,这一次子目标没有从图 2 (b) 传播到图 2 (c ):全局最优解消失,因为 ¬ ∃ y ″ : c o s ( s i n ( y ″ ) ) = 0 \neg\exists y^{″}:cos (sin(y^{″})) = 0 ¬∃y″:cos(sin(y″))=0。因此,没有一个形式为 [ p p p sin cos] 的程序,其中 p p p 是一个任意的子程序,可以作为这个编程任务的解决方案。
通过实例说明,子目标的数量可以随着后缀长度(图 2 (a) 中一个目标,图 2 (b) 中多个子目标)的增加而增加。这种增长可以是适应度案例 (fitness cases) 数量和后缀长度的指数函数。然而,期望语义通过独立存储每个 fitness case 的期望输出,可以以存储高效的方式捕获子目标;图 2 (b) 中的 16 个子目标只需要期望语义中的 8 个值: D = ( { − 3 π 2 , − π 2 , π 2 , 3 π 2 } , { − 3 π 2 , − π 2 , π 2 , 3 π 2 } ) D = ( \{\frac{-3π}{2} ,\frac{-π}{2} , \frac{π}{2} , \frac{3π}{2} \} , \{ \frac{-3π}{2} , \frac{-π}{2} , \frac{π}{2} , \frac{3π}{2} \}) D=({2−3π,2−π,2π,23π},{2−3π,2−π,2π,23π})。
从上面的例子中观察到的关键观察是语义反向传播改变了整个 fitness 景观。给定一个语义位于图 2 (b) 中某处的程序 p p p,通过修改该程序使其语义更接近于任一子目标,我们使得完整程序 [ p p p cos] 的语义接近于图 2 (a) 中的原始目标 t t t。这是设计使用语义反向传播的搜索算子的主要动机。
V. SEMANTIC BACKPROPAGATION IN SEARCH OPERATORS ✨
A. Common working principle
我们提出了两种采用语义反向传播的遗传搜索算子:一种可视为变异形式的一元随机期望算子 (RDO) 和近似几何语义交叉算子 (AGX)。两者都是从父程序 p p p 中选择一个随机节点 n n n 开始的,将 p p p 分为前缀和后缀。然后,他们调用 SEMANTICBACKPROPAGATION 来确定一个子任务。接下来,操作符试图通过对 Section V-D 中描述的程序库的穷举搜索来解决子任务。通过这种方式找到的最佳程序替换 p p p 中相应的前缀,产生子代。
RDO 和 AGX 的主要区别在于它们在反向误差传播网络过程中所设定的起始语义,即 SEMANTICBACKPROPAGATION ( t , p , n ) (t , p , n) (t,p,n) 调用中的参数 t t t。 RDO 使用任务提供的原始目标。AGX 使用 “合成” 目标,因此可以应用于原始目标不明确的任务。
B. Random Desired Operator
随机期望算子 (RDO),在 Alg.2 是我们在文献 [7] 中首次提出的,它遵循上述工作原理。在父程序 p p p 中首先选择一个随机节点 n n n。接下来, SEMANTICBACKPROPAGATION 确定与所选节点相关的期望语义 D D D。 D D D 存储一组子目标,从而定义一个编程子任务。第 4 行通过调用 Section V-D 中描述的 LIBRARYSEARCH ( L , D ) (L, D) (L,D) 来求解子任务。LIBRARYSEARCH ( L , D ) ( L,D) (L,D)从库中返回一个与所采用的度量最接近所需语义 D D D 的程序。由于库的规模有限,LIBRARYSEARCH 无法保证实际求解子问题 D D D,即在 L L L 中找到与 D D D 完全匹配的程序。

在这种情况下,RDO 不检查 D D D 是否包含空集,也会对库进行搜索。这可能看起来是徒劳的,因为没有程序(无论是否来自库)能够完美匹配这样的 D D D。但在这种情况下,LIBRARYSEARCH 将在其他 fitness case 下找到与 D D D 尽可能匹配的程序 p ′ p^{′} p′,RDO 将其粘贴到子代中。在非匹配的适合度情况下的行为有望通过后续几代的 RDO 突变来固定。
C. Approximately Geometric Semantic Crossover
RDO 以搜索过程的原始目标为期望目标, t t t。这在那些期望的程序结果作为任务制定(我们对本文的这一点进行了假设,特别是在公式 2 中。 )的一部分明确给出的领域中特别有用。符号回归和布尔函数合成的典型表述都属于这一类。
然而,存在目标不被搜索算法显式知道的任务,且适应度函数是只能针对特定程序进行查询的黑箱。例如,可能是目标包含机密信息而无法向实验者透露。
乍看之下,目前提出的推理并不适用于此类任务。事实上,RDO ( t , p , L ) ( t , p , L) (t,p,L) 不能被调用,因为 t t t 不为搜索算法所知,因此不能通过 p p p 传播回来。然而,无论算法是否知道圆锥顶点的位置,基于距离的适应度函数( 公式 2 )都会诱导出一个二次曲线的适应度景观。这样的 fitness 景观,单峰和没有 plateaus,通常很容易搜索。
特别地,几何交叉算子 [24] 已被证明在这类问题上表现特别好。一个重组算子是在度量 d d d 下的几何交叉,如果它的子代在其父代之间的 d-度量段。在语义GP中可以很容易地采用几何交叉,因为程序语义表示为一个输出向量,语义空间自然是一个向量空间。对于某些度量,几何交叉提供了吸引人的收敛性质。例如,对于欧氏度量,线段上的子代不能比父代最差的差(更详细的解释见[25])。
我们最初在文献 [6] 中提出的近似几何语义交叉 (Approximately Geometric Semantic Crossover,AGX) 是一种将语义反向传播与几何交叉相结合的算子。如算法 3 所示,AGX在连接父代语义的线段上选择一个点 m,通过对每个父代应用 RDO,尝试产生与 m 相匹配的程序,目标设置为 m。也就是说,在对真实目标不知情的情况下,AGX使用父代语义之间的一段上的点作为替代目标。

寻找跨越父程序 p 1 p_1 p1 和 p 2 p_2 p2 语义的段的中点 m 是域依赖的。对于数值语义和欧氏度量,MIDPOINT ( s ( p 1 ) , s ( p 2 ) ) (s(p_1),s(p_2)) (s(p1),s(p2)) 返回 m = ( s ( p 1 ) + s ( p 2 ) ) / 2 m = ( s(p_1)+ s(p_2)) / 2 m=(s(p1)+s(p2))/2。对于二进制向量和汉明度量,MIDPOINT 返回一个任意选择的点 m m m,即 (i) 位于段 (即 d ( s ( p 1 ) , m ) + d ( m , s ( p 2 ) ) = d ( s ( p 1 ) , s ( p 2 ) ) ) d(s(p_1),m) + d(m , s(p_2)) = d(s(p_1),s(p_2))) d(s(p1),m)+d(m,s(p2))=d(s(p1),s(p2))) 和 (ii) 可能等距于段 (即 ∣ d ( s ( p 1 ) , m ) − d ( m , s ( p 2 ) ) ∣ ≤ 1 ) |d(s(p_1),m) - d(m , s(p_2))|≤1 ) ∣d(s(p1),m)−d(m,s(p2))∣≤1) 的端点。
D. Solving subtasks by library search
RDO和AGX使用父代个体从原始编程任务中派生出子任务。在 Section IV-A 节中,我们提供了子任务解决方案可以比原始任务解决方案更短的证据。因此,为了解决一个子任务,而不是像GP那样使用复杂的启发式方法,我们使用更简单的方法,在一组具有预计算语义的程序中执行穷举搜索,我们称之为库。这个过程隐藏在算法 2 的 LIBRARYSEARCH 调用之下。给定一个库 L L L 和一个期望的语义 D D D,LIBRARYSEARCH ( L , D ) ( L,D) (L,D) 计算 D D D 的组件与库中每个程序的语义之间的最佳匹配,即在 L L L 中找到一个最小化的程序 p p p:

当最小化该表达式时,我们从笛卡尔积中舍去所有满足 D i = ∅ D_i =\empty Di=∅ 或 ∗ ⋅ ∈ D i *⋅∈D_i ∗⋅∈Di 的集合 D i D_i Di。因此,距离 d ( y , s ( p ) ) d(y , s(p)) d(y,s(p)) 仅在语义 s ( p ) s(p) s(p) 的剩余(定义良好)成分上计算。
注意,以这种方式构造一个编程子任务不同于原始编程任务 (定义 3 ),其中搜索过程的目标是单个向量(期望输出值的组合)。在这里,寻求一个最小化到 D D D 中任意一个子目标的距离的方案。
在找到 L L L 中最小化公式 4 的程序后,我们验证一个常数语义是否会给出更好的匹配。通过这样做,我们不仅期望有时能找到一个常数来减少匹配距离 d d d,而且还能为种群提供额外的潜在有用常数( ERCs ),减少膨胀。我们通过求解公式 4 的以下特例来计算在所有适应度情况下最小化与期望值的总体散度的常数:

其中 [c] 表示一个由 l l l 个分量组成的向量,所有的集合为 c c c。与公式 4 一样,笛卡尔积只涉及恰当低定义的 D i D_i Di 分量,该表达式在问题(R表示符号回归, {0,1} 表示布尔问题)的定义域特征 c c c 变化时被最小化。如果 (5) 的值小于 (4) 的值,LIBRARYSEARCH返回 c c c,否则返回库中找到的程序。
我们通过在公式 4 的每个维度上分别最小化来解决这两个问题,由于 Minkowsky 距离的性质,可以在多项式时间内完成。具体内容见附录 6。
我们考虑库的两个程序来源。一个静态库 L L L 由达到一定高度7限制的所有程序树填充,在进化搜索过程中不发生变化。一个动态库包含了从当前种群中所有个体收集的所有子树,因此在搜索过程中会发生变化。
一个库,无论是静态的还是动态的,都只存储语义唯一的程序。如果两个候选程序具有相同的语义,则库中只包含较短的程序。需要注意的是,语义唯一性的验证是在没有任何阈值8 的情况下完成的,其目的是保持库的大小,减少程序膨胀。尽管如此,这是库生成的主要计算成本。因此,维护一个动态库通常比较耗时。

- 如果没有阈值,候选程序的语义唯一性可以在 O ( 1 ) O(1) O(1) 时间内确定,例如使用哈希表。相反的阈值迫使我们考虑已经存在于库中的程序的语义分布。这样就可以在 O ( l o g ∣ L ∣ ) O (log |L|) O(log∣L∣) 时间内用二叉树等方式完成,其中 ∣ L ∣ |L| ∣L∣ 是库的大小。
VII. DISCUSSION
实验表明,RDO操作符合预期的 ( Sec.VI~F),在所考虑的两个域 (domains) 中都优于所有其他算子,而 AGX 只在回归域 (regression domain) (Sec.VI-B) 中证明有用。造成这些差异的原因是什么?
RDO的表现源于明确使用了问题描述中最具信息含量的部分:目标。通过使用目标作为语义反向传播的目标,RDO旨在直接解决问题,即没有逐渐接近目标的"意图"。幸运的是,它可以从初始种群中已有的程序中选择合适的后缀,并在库中找到一个完美匹配的程序,从而在第一代中解决问题。对于 AGX 来说,要发生类似的事情,MIDPOINT 确定的替代目标必须与真实目标重合,这是不可能的,特别是在连续语义空间。因此,AGX在设计上无法比RDO更快地收敛。
那么,AGX在符号回归域中的表现如何?第二节中提到的语义空间的几何性质。这里 V-C 起关键作用。对于连续的语义空间和欧氏度量 d,适应度景观 (fitness landscape) 形成一个欧氏锥体悬停在语义空间 (其实例如图 2a 所示)上。语义空间中一个点的适应度可以通过将其投影到圆锥上并测量到该投影(图 2a 中用颜色描绘的 “高度”) 的距离得到。对于一对父代语义 s ( p 1 ) s(p_1) s(p1) 和 s ( p 2 ) s(p_2) s(p2),MIDPOINT程序指定AGX的代理目标为 s ( p 1 ) s(p_1) s(p1) 和 s ( p 2 ) s(p_2) s(p2) 之间的分段中点 m (算法 3 )。根据圆锥的定义,m 投影在圆锥上的像不能高于 s ( p 1 ) s(p_1) s(p1) 和 s ( p 2 ) s(p_2) s(p2) 投影的高度。因此,如果 AGX 能够产生一个与 m 匹配的程序 (由于程序反演和库检索的不完善性,这是不保证的),那么该程序不能比父代程序差。尤其是,当 s ( p 1 ) s(p_1) s(p1) 和 s ( p 2 ) s(p_2) s(p2) 恰好位于原目标 t 的对边时(因而它们在圆锥体的对面斜面上的像),子代可以比父代更适合(其图像在锥体上较低)。

这种几何性质导致符号回归基准中 AGX 比 GPX 和 LGX 收敛得更快。然而,在布尔域 (Boolean domain) 中AGX的表现更差 (图4 )。可能的原因是这里的语义空间和适应度景观的结构与连续符号回归域的结构有本质的不同。虽然分段在汉明空间 (Hamming space) 中定义良好,但分段的中点一般不唯一:对于两个相差 n n n 位的布尔语义 (Boolean semantics),大约有 ( n / 2 − n ) (n/2 - n) (n/2−n) 个这样的中点。与欧几里得空间相反,这样的中点可以比双亲更少的拟合 (fit)。,AGX 可以指定一个替代目标 m m m,使搜索远离原始目标 t t t。


考虑到这一点,AGX是否有任何其他优点,使其具有潜在的有用性,因为RDO的性能要好得多?我们声称是这样的,因为正如第五节所示,RDO和AGX的应用领域在一定程度上是互补的。RDO的优点在于它不要求语义距离 d d d 是一个范数: d d d 是一个度量就足够了。AGX则相反,要求语义空间是赋范向量空间,因为它需要在父代语义之间构造一个中点。然而,AGX提供了对搜索目标不了解的优势;它不需要明确知道什么是期望的程序输出。得益于此,它能够以适应度值作为唯一信息(除了编程语言之外)对所要解决的问题进行搜索。这使得当目标不能明确地显示给搜索算法时,例如由于机密性问题,或者当目标完全不知道时,这是一种方便的选择方法,这在控制问题(如人造蚂蚁或极点平衡)中就是如此。我们假设AGX在后一种情况下也能表现良好,尽管这类任务一般不是单峰的(即可能有不止一个目标)。在更广泛的视角下,值得注意的是,这里引入的期望语义概念可以作为多模态任务的目标泛化。这里介绍的算法将目标等同于向量,主要是由于GP中广泛存在的约定;在给定任务所需语义作为输入的情况下,其中许多(特别是 SEMANTICBACKPROPAGATION 和 RDO )也能正常工作。
在本文中,我们考虑到程序反转 (inversion) 的模糊性和一对多的性质是一个挑战,因为它可能导致从原始目标(甚至对于 sin 这样的周期函数有无穷多个子目标)衍生出指数级的许多子目标。然而,这个问题存在着另一面。子任务的理想解是从期望的语义返回任意期望输出组合的程序11 ,一般来说,找到这样的程序比找到一个产生特定输出组合的程序要容易,这在解决具有单一原始目标的原始问题时是如此。这是语义反向传播的一个有趣的方面,值得未来的研究。
更一般地说,语义反向传播使用种群中程序的后缀生成一个不同的任务,该任务预期比原始编程任务更容易解决。为了解决派生的子任务,我们在这里使用了一个库中的穷举搜索,主要是因为它在概念上是简单和合理的快速,特别是对于小型库。其他搜索算法,如GP,也可用于此目的。考虑到GP的搜索空间远大于所考虑库的规模,GP有可能找到比 LIBRARYSEARCH 更好的程序。
然而,将大量的计算精力投入到求解任一子任务上都存在一定的风险。一个子任务可以但不能保证比原始任务更容易解决。在最坏的情况下,它可能在所考虑的搜索空间中没有解。因此,本文提出的算法不是指定单个子任务(或其小样本)并投入大量的搜索精力进行求解,而是尝试在有限的库中通过穷举搜索的方式求解大量子任务(每个由 RDO/AGX 应用于父代个体产生 (s) )。考虑的子任务数量和致力于解决它们的计算工作量之间的权衡类似于著名的多臂强盗范式 (multi-armed bandit paradigm),是一个有趣的未来研究课题。
当应用于程序时,RDO临时冻结其后缀并操作其前缀,使修改后的前缀尽可能接近后缀的"期望" (期望的语义)。一个假想的替代搜索算子可以交换前缀和后缀的角色,并在操作后缀的同时冻结前缀。然而,这至少有一个实际的缺点:必须执行整个修改后的程序来计算其适应度。在RDO中,库中的程序可以被预先计算,因为它们的行为只依赖于由适应度案例提供的程序输入,而适应度案例随编程任务而来并保持不变。
RDO和AGX的总体计算成本高于常规GP算子。主要原因是库的搜索,这可能需要大量的时间,特别是当应用于大型库。在我们之前的研究中 [18],我们使用 kd-tree [35] 来加速搜索。然而,这种索引结构只能在所寻求的对象是单个数字向量(一个点)的情况下使用,而我们想要的语义一般代表一组点。为了满足这一要求,需要对传统的索引技术进行扩展,使这些搜索算子更加高效。其次,影响RDO和AGX计算成本的次要因素是树的大小。与标准GP类似,由RDO和AGX构建的程序往往随着进化时间的推移而增长,我们在第VI-E 节中报告了这一点。我们假设这个问题可以通过使用通用的膨胀预防技术来解决,例如那些采用空间种群结构 (spatial population structure) [36]
VI. THE EXPERIMENT
A. Setup
为了评估语义反向传播的好处,我们将RDO(Sec。V-B)和AGX(Sec。V-C)与以下参考搜索算法的性能进行了比较:
- GPX: GP using standard subtree crossover (90%) and subtree mutation (10%) by Koza [26]. Standard crossover produces offspring by swapping two randomly selected subtrees in parent programs. Mutation replaces a randomly selected subtree in the parent with a randomly generated one. We use mutation to improve GPX’s results and make it a more challenging opponent (GP without mutation achieved notably worse results in a preliminary series of runs).
- LGX: GP using only the Locally Geometric Semantic Crossover [18]. Given two parent trees, LGX draws a crossover locus only from their structurally homologous region, like the one-point crossover by Langdon [27]. Next, it calculates the midpoint of the segment connecting the semantics of the subtrees rooted at the chosen locus in both parents. Then it calls LIBRARYSEARCH to find the program that is semantically most similar to the midpoint, and pastes that program into parents at the selected locus (see [18] for more details). We chose LGX as a control approach because its design is motivated by the same geometric properties that found AGX, and it also uses a library of programs. Moreover, in [18] we compared LGX with Semantic Aware Crossover and Semantic Similarity Crossover by Nguyen et al. [13], so by using LGX as a reference we can also indirectly compare RDO and AGX to those operators.
我们将这两种控制设置和运行RDO和AGX的GP应用于18个常用的基准测试程序,这些基准测试程序代表了两组:符号回归任务和布尔函数合成任务(表II )。符号回归基准来自[ 26 ],[ 28 ],而布尔基准来自[ 26 ],[ 29 ] .
符号回归和布尔基准中使用的指令集如表III所示。对于GPX,符号回归中的ERC是取自区间[ - 1、1]的随机常数。对于RDO,AGX和LGX,常量由算法LIBRARYSEARCH在第V - D节中描述。另一方面,对于布尔基准程序,为了保持与符号回归设置的一致性,我们允许程序进行使用常数的真与假。
RDO、AGX和LGX使用相同的程序库。我们考虑静态库和基于种群的(动态)库(第V - D部分)。一个静态库包含了所有高度为h的程序树。这个极限用一个下标来标示,例如. RDO3是指h = 3时的静态库,而RDOp是指基于种群的(动态)库。
程序语义是所有回归基准的长度为20的向量,因为这是训练集中可用的适应度案例的数量(表II )。由于只有一个终端符号x,程序数量随树高适度增长。这使得我们可以考虑回归问题的两个库,一个小的( h = 3 )和一个大的( h = 4 ),它们分别包含289和111458个语义唯一的程序。下文中,"小"和"大"仅指静态库。
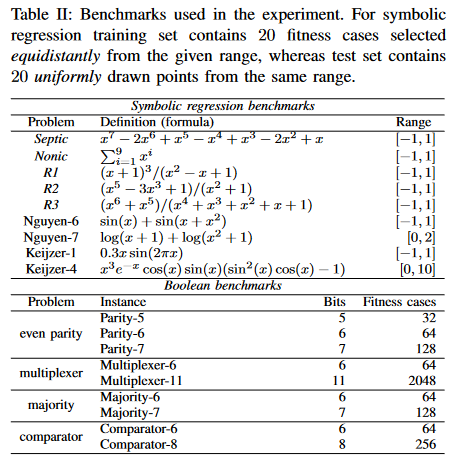
对于布尔问题,训练集包含所有的输入组合,因此语义的长度甚至可以比回归问题(见表II最后一列)大两个数量级。同时,根据基准,有5 ~ 11个输入终端。这使得大的( h = 4 )静态库在技术上是不可行的,所以我们只使用小的库用于布尔域。表IV给出了布尔任务中使用的静态库的大小。

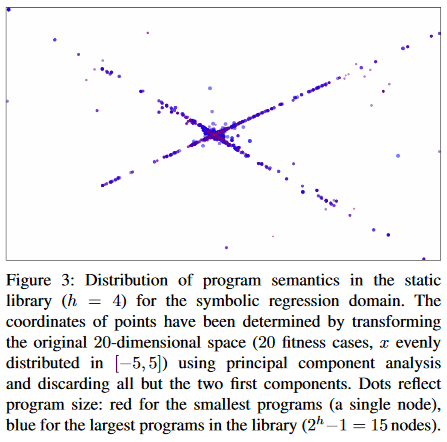
更大规模的库是可取的,因为它们提供了更丰富的语义多样性。程序语义的分布随着程序规模的增长收敛到一个强非均匀分布的(关于布尔域的证明见 , )。然而,在这里所考虑的库中的小程序,我们还远远没有达到那种收敛,我们进行了实验验证。图3可视化了大库中程序语义的两个第一主成分(符号回归),并用颜色标记程序大小。小程序明显地围绕着坐标系的原点进行分组,而大程序则从坐标系的原点向外扩展。因此,回归领域的大型库在语义上更加多样化。然而,为了获得更大的语义多样性所付出的代价是图书馆的规模,从而导致更高的图书馆搜索成本。
进化算法的其他参数见表III。其中是所有方法观测的树高上限( 17 )。对于RDO,AGX和LGX,这意味着LIBRARYSEARCH收到了一个额外的参数,它规定了在父程序(例如,如果位置在深度7 ,那论点是10)的选定位置可以插入的程序的最大高度。LIBRARYSEARCH忽略了库中可能违反该约束的程序。
我们实现语义反向传播、RDO、AGX、LGX和GPX的Java源代码可在www.cs.put.poznan.pl/tpawlak/link/?IEEESemanticBackprop.上获得。
B. Performance of the operators
图4给出了符号回归和布尔基准下最优世代个体的平均(最小化)适应度。曲线以0.95的置信区间对每个方法30次运行的平均值作图。
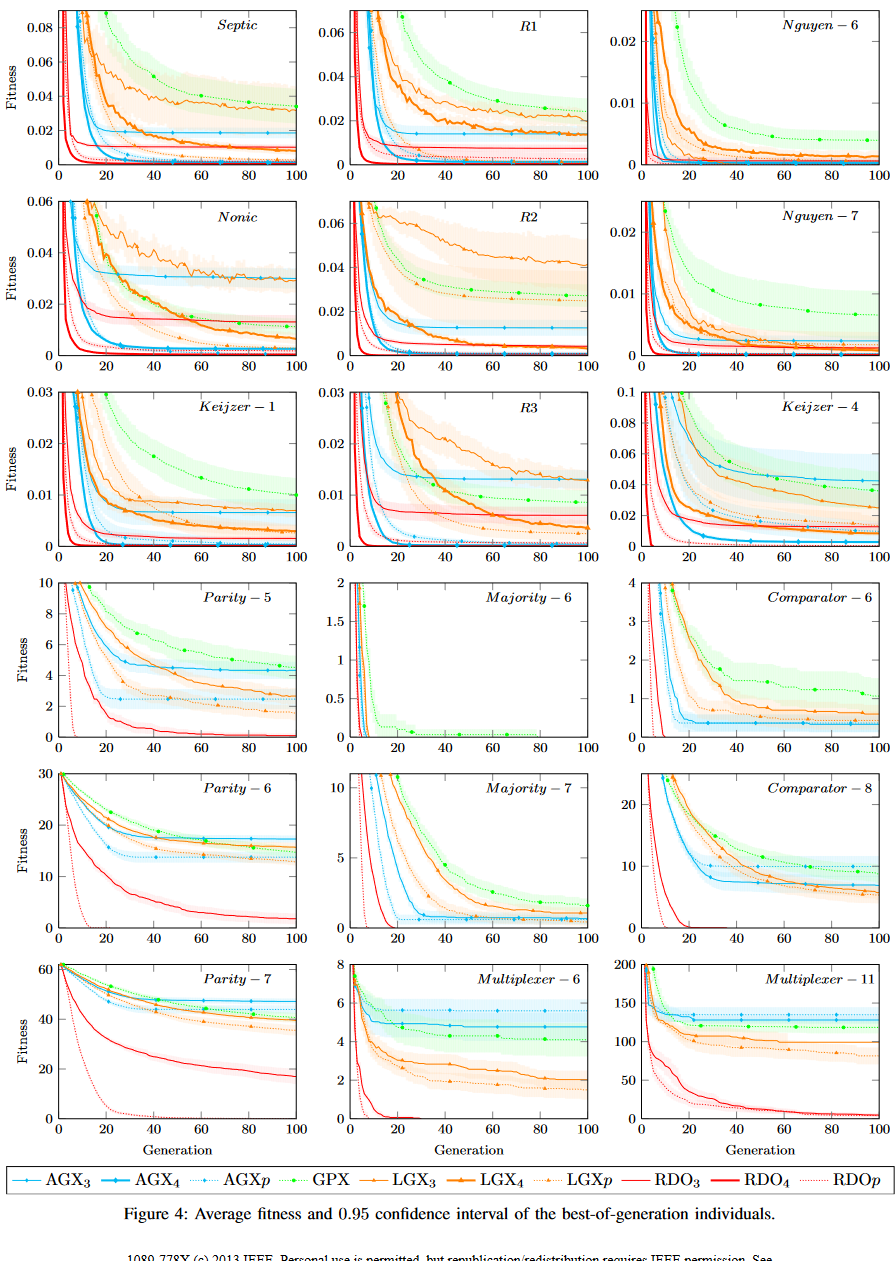
C. Generalization

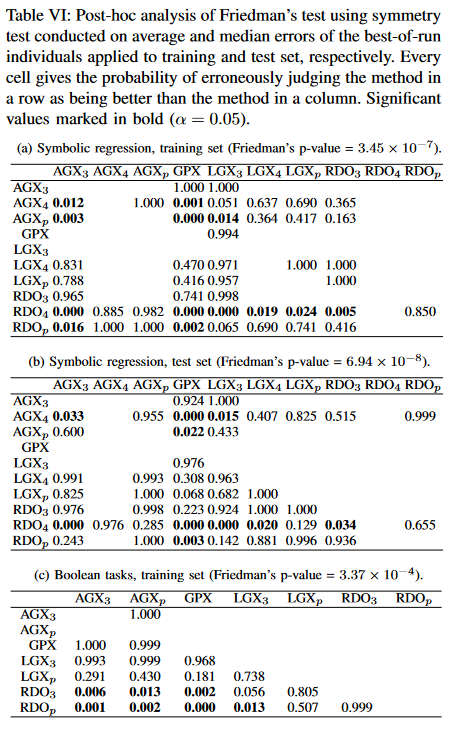
D. Statistical significance

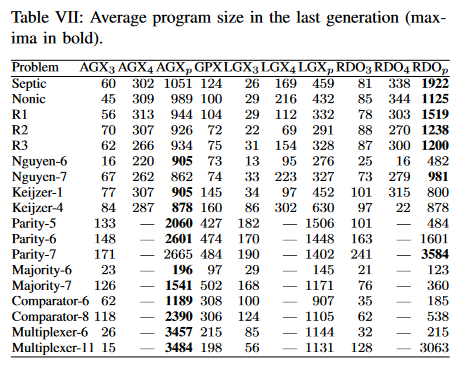
E. Bloat analysis
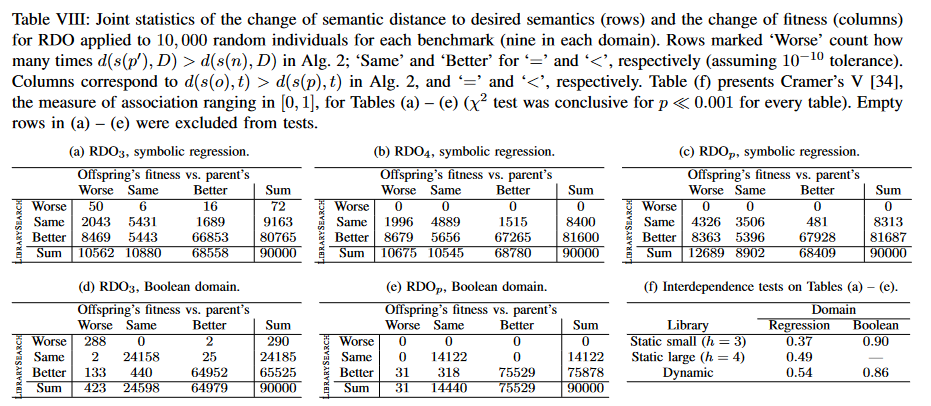
F. Analysis of RDO
VIII. CONCLUSIONS
我们证明了程序执行的反转 (inversion) 可以从原始的编程任务中生成子任务,并且这些子任务可以在受约束的程序集(库)中使用穷举搜索来解决。尽管由于指令的多对一操作,程序反转本质上是不完美的,但使用这种方法的两个GP搜索算子优于标准GP和其他语义感知算子。从概念上讲,这种工作原理可以应用在其他领域和编程语言中。因此,程序反演是使包括GP算法在内的自动编程算法具备问题分解能力的可行途径
Reference
Pawlak T P, Wieloch B, Krawiec K. Semantic backpropagation for designing search operators in genetic programming[J]. IEEE Transactions on Evolutionary Computation, 2014, 19(3): 326-340.
算法原理梳理
语义反向传播,SB
算法 1 中函数和参数说明:
SEMANTICBACKPROPAGATION ( t , p , n ) (t, p, n) (t,p,n): 用于计算从程序树 p p p 到节点 n n n 的期望语义
- t t t:表示所有期望语义的集合。
- p p p:整个程序树
- n n n:求从程序树 p p p 的根节点到目标节点 n n n 的期望语义
- t i t_i ti:第 i i i 个 fitness case 的期望语义.
- D i D_i Di:第 i i i 个期望语义的集合,如图 1 的根节点 D 1 = { − 2 , 0 , 0 } D_1 = \{-2, 0, 0\} D1={−2,0,0}
Pos ( a , n ) (a, n) (a,n): 返回子程序树 a a a 从根节点到节点 n n n 路径中, a a a 根节点所对应的参数的个数 k k k
- a a a:子程序树,通过 CHILD ( a , n ) (a, n) (a,n) 可以不断寻找从当前子树 a a a 的根节点到节点 n n n 的下一个新子树。
INVERT ( a , k , o ) (a, k, o) (a,k,o): 通过程序树 a a a 的根节点运算符,以及期望语义 o o o, 和参数个数 k k k,进行反转计算
CHILD ( a , n ) (a, n) (a,n): 返回从当前子树 a a a 的根节点到节点 n n n 路径的下一个新子树。
通过图 1 对算法 1 中的原理进行介绍:
首先执行算法将第一个
t
i
t_i
ti 赋值给
D
i
D_i
Di, 即
D
1
=
{
−
2
,
0
,
0
}
D_1 = \{-2, 0, 0\}
D1={−2,0,0},并将程序树
p
p
p 赋值给
a
a
a, 通过 while 循环,计算从程序树
a
a
a 的根节点到节点
n
n
n 路径上所有节点的期望语义,首先通过 Pos
(
a
,
n
)
(a, n)
(a,n) 返回
a
a
a 的根节点运算符对应的参数个数给
k
k
k,并初始化
D
′
D^{'}
D′ 为空,用于存储待计算节点的期望语义,for 循环通过遍历
D
i
D_i
Di 中的目标语义,从而反转计算目标节点的期望语义。比如:开始时
D
1
D_1
D1 中提取期望语义的第一个元素 -2, 此时根节点为 ‘-’,即按照二叉树的 GP ,为左右两颗子树的语义进行相减从而计算出当前根节点沿路径下一个节点的期望语义,计算完成后,将语义存储到
D
′
D^{'}
D′ 中,并赋值给
D
i
D_i
Di, 使得计算出的期望语义对应的节点成为一个新的根节点,通过 CHILD
(
a
,
n
)
(a, n)
(a,n),更新子树
a
a
a, 再以当前根节点计算下一个节点的期望语义,如图 1 中的 “第二个根节点” 运算符为 ‘×’,左子树乘以右子树等于根节点的期望语义,同理已知左子树语义,根节点语义,可以反求出右子树语义。
我们用一个例子来说明反演这个过程,其中 SEMANTICBACKPROPAGATION 用于目标 t = [ − 2 , 0 , 0 ] t=[ - 2, 0, 0] t=[−2,0,0],程序 p p p 如图 1 所示, n n n 是用蓝色标记的节点。 p p p 中子树的语义用黑框表示。首先考虑 t t t 中的第一个元素 (即 fitness case 的第一个位置元素),期望输出为 − 2 -2 −2 . 算法从根节点开始。由于待计算的目标节点 n n n 在根的右子树中,因此算法将为根指令 (‘-’) 的右参数确定集合 D 1 D_1 D1。利用 INVERT 计算根节点右子树第一个节点的期望值,图 1 所示, INVERT ( c 1 − c 2 , 2 , o ) ( c_1-c_2 , 2 , o) (c1−c2,2,o),其中 c 1 c_1 c1 表示当前根节点左子树目标语义的第一个元素值, c 2 c_2 c2 表示当前根节点右子树目标语义的第一个元素值,目标是为了求出 c 2 c_2 c2, 而存在关系 c 1 − c 2 = o c_1 - c_2 = o c1−c2=o, 在图 1 中 c 1 = 1 c_1 = 1 c1=1 和 o = − 2 o = - 2 o=−2 上运行。根据表 I 的第二行返回 INVERT ( 1 − c 2 , 2 , − 2 ) ( 1-c_2 , 2 , -2) (1−c2,2,−2),即 c 2 = c 1 − o = 1 − ( − 2 ) = 3 c_2 = c_1 - o = 1- ( - 2 ) = 3 c2=c1−o=1−(−2)=3。该算法试图找出正确参数 (x) 的值应该是多少才能使结果满足目标 − 2 -2 −2,即 1 − x = − 2 1 - x = - 2 1−x=−2。这可以通过反演计算得到,因此算法以 x = 1 − ( − 2 ) = 3 x = 1- ( -2 ) = 3 x=1−(−2)=3 结束。该值成为向根节点(蓝色虚线框)的右子节点传播的期望语义的第一个元素,与其余两个适应度情况独立计算的值一起。产生的期望语义 ( 3 , 2 , 3 ) ( 3,2,3) (3,2,3) 成为后续步骤反向传播 (指令 × × ×) 的起点。
Random Desired Operator,RDO
在父程序 p p p 中首先选择一个随机节点 n n n。接下来, SEMANTICBACKPROPAGATION 确定与所选节点相关的期望语义 D D D。 D D D 存储一组子目标,从而定义一个编程子任务。第 4 行通过调用 Section V-D 中描述的 LIBRARYSEARCH ( L , D ) (L, D) (L,D) 来求解子任务。LIBRARYSEARCH ( L , D ) ( L,D) (L,D) 从库中返回一个与所采用的度量最接近所需语义 D D D 的程序。由于库的规模有限,LIBRARYSEARCH 无法保证实际求解子问题 D D D,即在 L L L 中找到与 D D D 完全匹配的程序。
在这种情况下,RDO 不检查 D D D 是否包含空集,也会对库进行搜索。这可能看起来是徒劳的,因为没有程序(无论是否来自库)能够完美匹配这样的 D D D。但在这种情况下,LIBRARYSEARCH 将在其他 fitness case 下找到与 D D D 尽可能匹配的程序 p ′ p^{′} p′,RDO 将其粘贴到子代中。在非匹配的适合度情况下的行为有望通过后续几代的 RDO 突变来固定。
总结: 2. 2014,TEVC,Semantic backpropagation for designing search operators in genetic programming
原文见: https://blog.csdn.net/qq_46450354/article/details/128683758
概述: 提出的语义反向传播算法通过启发式地反转演化程序的执行来确定所需的中间计算状态。两个搜索算子,随机期望算子 (Random Desired Operator, RDO) 和近似几何语义交叉 (Approximately Geometric Semantic Crossover, AGX),使用语义反向传播确定的中间状态定义原始编程任务的子任务,然后使用穷举搜索求解。该算子在一组符号回归和布尔基准 (Boolean benchmarks) 上的表现优于标准遗传搜索算子和其他语义感知算子。
研究点提取: 利用语义进行交叉和变异操作
算法原理梳理
语义反向传播,SB
算法 1 中函数和参数说明:
SEMANTICBACKPROPAGATION ( t , p , n ) (t, p, n) (t,p,n): 用于计算从程序树 p p p 到节点 n n n 的期望语义
- t t t:表示所有期望语义的集合。
- p p p:整个程序树
- n n n:求从程序树 p p p 的根节点到目标节点 n n n 的期望语义
- t i t_i ti:第 i i i 个 fitness case 的期望语义.
- D i D_i Di:第 i i i 个期望语义的集合,如图 1 的根节点 D 1 = { − 2 , 0 , 0 } D_1 = \{-2, 0, 0\} D1={−2,0,0}
Pos ( a , n ) (a, n) (a,n): 返回子程序树 a a a 从根节点到节点 n n n 路径中, a a a 根节点所对应的参数的个数 k k k
- a a a:子程序树,通过 CHILD ( a , n ) (a, n) (a,n) 可以不断寻找从当前子树 a a a 的根节点到节点 n n n 的下一个新子树。
INVERT ( a , k , o ) (a, k, o) (a,k,o): 通过程序树 a a a 的根节点运算符,以及期望语义 o o o, 和参数个数 k k k,进行反转计算
CHILD ( a , n ) (a, n) (a,n): 返回从当前子树 a a a 的根节点到节点 n n n 路径的下一个新子树。
通过图 1 对算法 1 中的原理进行介绍:
首先执行算法将第一个
t
i
t_i
ti 赋值给
D
i
D_i
Di, 即
D
1
=
{
−
2
,
0
,
0
}
D_1 = \{-2, 0, 0\}
D1={−2,0,0},并将程序树
p
p
p 赋值给
a
a
a, 通过 while 循环,计算从程序树
a
a
a 的根节点到节点
n
n
n 路径上所有节点的期望语义,首先通过 Pos
(
a
,
n
)
(a, n)
(a,n) 返回
a
a
a 的根节点运算符对应的参数个数给
k
k
k,并初始化
D
′
D^{'}
D′ 为空,用于存储待计算节点的期望语义,for 循环通过遍历
D
i
D_i
Di 中的目标语义,从而反转计算目标节点的期望语义。比如:开始时
D
1
D_1
D1 中提取期望语义的第一个元素 -2, 此时根节点为 ‘-’,即按照二叉树的 GP ,为左右两颗子树的语义进行相减从而计算出当前根节点沿路径下一个节点的期望语义,计算完成后,将语义存储到
D
′
D^{'}
D′ 中,并赋值给
D
i
D_i
Di, 使得计算出的期望语义对应的节点成为一个新的根节点,通过 CHILD
(
a
,
n
)
(a, n)
(a,n),更新子树
a
a
a, 再以当前根节点计算下一个节点的期望语义,如图 1 中的 “第二个根节点” 运算符为 ‘×’,左子树乘以右子树等于根节点的期望语义,同理已知左子树语义,根节点语义,可以反求出右子树语义。
我们用一个例子来说明反演这个过程,其中 SEMANTICBACKPROPAGATION 用于目标 t = [ − 2 , 0 , 0 ] t=[ - 2, 0, 0] t=[−2,0,0],程序 p p p 如图 1 所示, n n n 是用蓝色标记的节点。 p p p 中子树的语义用黑框表示。首先考虑 t t t 中的第一个元素 (即 fitness case 的第一个位置元素),期望输出为 − 2 -2 −2 . 算法从根节点开始。由于待计算的目标节点 n n n 在根的右子树中,因此算法将为根指令 (‘-’) 的右参数确定集合 D 1 D_1 D1。利用 INVERT 计算根节点右子树第一个节点的期望值,图 1 所示, INVERT ( c 1 − c 2 , 2 , o ) ( c_1-c_2 , 2 , o) (c1−c2,2,o),其中 c 1 c_1 c1 表示当前根节点左子树目标语义的第一个元素值, c 2 c_2 c2 表示当前根节点右子树目标语义的第一个元素值,目标是为了求出 c 2 c_2 c2, 而存在关系 c 1 − c 2 = o c_1 - c_2 = o c1−c2=o, 在图 1 中 c 1 = 1 c_1 = 1 c1=1 和 o = − 2 o = - 2 o=−2 上运行。根据表 I 的第二行返回 INVERT ( 1 − c 2 , 2 , − 2 ) ( 1-c_2 , 2 , -2) (1−c2,2,−2),即 c 2 = c 1 − o = 1 − ( − 2 ) = 3 c_2 = c_1 - o = 1- ( - 2 ) = 3 c2=c1−o=1−(−2)=3。该算法试图找出正确参数 (x) 的值应该是多少才能使结果满足目标 − 2 -2 −2,即 1 − x = − 2 1 - x = - 2 1−x=−2。这可以通过反演计算得到,因此算法以 x = 1 − ( − 2 ) = 3 x = 1- ( -2 ) = 3 x=1−(−2)=3 结束。该值成为向根节点(蓝色虚线框)的右子节点传播的期望语义的第一个元素,与其余两个适应度情况独立计算的值一起。产生的期望语义 ( 3 , 2 , 3 ) ( 3,2,3) (3,2,3) 成为后续步骤反向传播 (指令 × × ×) 的起点。
Random Desired Operator,RDO
在父程序 p p p 中首先选择一个随机节点 n n n。接下来, SEMANTICBACKPROPAGATION 确定与所选节点相关的期望语义 D D D。 D D D 存储一组子目标,从而定义一个编程子任务。第 4 行通过调用 Section V-D 中描述的 LIBRARYSEARCH ( L , D ) (L, D) (L,D) 来求解子任务。LIBRARYSEARCH ( L , D ) ( L,D) (L,D) 从库中返回一个与所采用的度量最接近所需语义 D D D 的程序。由于库的规模有限,LIBRARYSEARCH 无法保证实际求解子问题 D D D,即在 L L L 中找到与 D D D 完全匹配的程序。
在这种情况下,RDO 不检查 D D D 是否包含空集,也会对库进行搜索。这可能看起来是徒劳的,因为没有程序(无论是否来自库)能够完美匹配这样的 D D D。但在这种情况下,LIBRARYSEARCH 将在其他 fitness case 下找到与 D D D 尽可能匹配的程序 p ′ p^{′} p′,RDO 将其粘贴到子代中。在非匹配的适合度情况下的行为有望通过后续几代的 RDO 突变来固定。















 6121
6121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









