








ABSTRACT
选择机制对遗传程序设计 (Genetic Programming,GP) 的性能起着非常重要的作用。在几种选择技术中,锦标赛选择往往被认为是最受欢迎的。标准锦标赛选择从种群中随机选择一组个体,选择适应度值最好的个体作为获胜者。然而,由于标准方法忽略了 GP 程序执行过程中可以收集的更细粒度的语义,因此存在增强锦标赛选择的机会。在符号回归问题的情况下,训练适应度案例上的误差向量可以用于更详细的定量比较。在本文中,我们将统计检验的方法引入到 GP 锦标赛选择中,该方法利用了来自个体误差向量的信息,并提出了三种选择策略。我们在 25 个回归问题及其噪声变体上测试了这些方法。实验结果表明,与标准锦标赛选择、类似的选择技术和最先进的膨胀控制方法相比,所提出的方法在减少 GP 代码增长和改善 GP 解决方案的泛化行为方面的优势。
1. Introduction
遗传程序设计(Genetic Programming,GP)是一种受生物启发的方法,它使用计算机以计算机程序的形式来进化问题[24、37]的解决方案。为了使用GP系统解决一个问题,首先初始化一个由个体组成的种群。然后,通过应用遗传算子,在基于适应度的选择下,通过若干世代对种群进行进化。当找到期望解或超过最大代数时,进化过程终止。
对于一个给定的问题,有几个因素会影响GP的性能。这些因素包括种群的规模、个体的适合度评价、繁殖的选择机制和修饰个体的遗传算子。其中,选择在GP性能中起着至关重要的作用[4]。迄今为止,已经有许多选择方案被提出[23],在GP中应用最广泛的选择是锦标赛选择[11]。
锦标赛选择比较采样个体的适应度值。然后选择适应度最好的个体作为获胜者。这种实现方式简单,其有效性已被广泛证实[11]。然而,标准方法只使用了适应度值,而忽略了所有适应度情况下个体的误差向量信息。因此,一些对GP搜索潜在有用的信息可能会丢失。最近的研究表明,利用GP个体(e.g . , [21,22,28,31,35])的语义信息可以获得显著的收益。对交叉和变异的遗传搜索算子进行修改,可以提高搜索[9、30、34]的语义局部性。此外,保持语义多样性是进化GP种群避免局部最优[5、12]的一个可取特征,因此,在选择过程中使用个体在适应度案例上的误差向量是否可以提高GP性能也是很有吸引力的。
在我们的前期研究中[6],我们提出了两种基于个体错误向量统计分析的语义锦标赛选择形式。在一组GP基准问题上的实验结果表明了所提方法的有效性[6]。在本文中,我们扩展了这项研究,本文的主要贡献是:
- 我们介绍了利用GP误差向量的统计分析来创建新的锦标赛选择形式。基于Wilcoxon符号秩检验,提出了3种锦标赛选择的变体,以利用语义多样性,并探索该方法控制程序膨胀的潜力。
- 在使用原始问题和噪声变体的大型回归问题集上测试了选择策略的性能。我们观察到,与标准锦标赛选择和GP中控制代码膨胀的最新方法相比,新的选择技术有助于减少代码增长并提高演化解的泛化能力。
- 所提出的选择策略设计的简单性允许进一步改进。在本文中,添加了一个先进的交叉算子来观察性能的进一步提升。
在接下来的章节中,我们介绍了论文的研究背景。第3节回顾了GP中改进锦标赛选择的相关工作。本文提出的三种锦标赛选择策略见第4节。第5节给出了本文采用的实验设置。第6节将所提出的选择策略与标准锦标赛选择的性能进行分析和比较。通过与第7节中最先进的交叉策略的耦合,该方法得到了进一步的增强。第八节研究了所提出的技术在噪声数据集上的能力。最后,第9节对全文进行了总结,并对未来的工作进行了展望。
2. Background
该部分介绍了所提出的选择策略中使用的一些重要概念,包括GP个体的语义、个体的误差向量以及Wilcoxon符号秩检验。
在GP中,通常将程序的语义简单地定义为其关于一组输入值[27、31]的行为。在形式上,程序的语义定义如下:
定义 2.1. 设 K = ( k 1 , k 2 , … k N ) K= ( k_1, k_2, \ldots k_N) K=(k1,k2,…kN)是问题的适应值情形.程序P的程序语义 S ( P ) S(P) S(P)是在所有适应值情况下运行 P P P得到的输出值的向量。
S ( P ) = ( P ( k 1 ) , P ( k 2 ) , … , P ( k n ) ) , for i = 1 , 2 , … , N . S(P)=(P(k_1),P(k_2),\ldots,P(k_n)), \text{for} ~~ i =1,2,\ldots,{N}. S(P)=(P(k1),P(k2),…,P(kn)),for i=1,2,…,N.
这个定义对于定义了一组适应度情况的问题是有效的。通过将语义向量与问题的目标输出进行比较,计算出个体的误差向量。更确切地说,个体的误差向量定义为:
定义2.2. 令 S = ( s 1 , s 2 , … s N ) S= ( s_1, s_2, \ldots s_N) S=(s1,s2,…sN)为个体 P P P的语义, Y = ( y 1 , y 2 , … y N ) Y= ( y_1, y_2, \ldots y_N) Y=(y1,y2,…yN)为问题在 N N N 个适应度案例上的目标输出。程序 P P P的错误向量 E ( P ) E(P) E(P) 是由 N N N 个元素组成的向量。
E ( P ) = ( ∣ s 1 − y 1 ∣ , ∣ s 2 − y 2 ∣ , … , ∣ s n − y n ∣ ) . E(P)=\left(|s_1-y_1|,|s_2-y_2|,\ldots,|s_n-y_n|\right). E(P)=(∣s1−y1∣,∣s2−y2∣,…,∣sn−yn∣).
Wilcoxon符号秩检验是一种非参数统计假设检验,用于比较两个相关样本,以评估它们的总体均值排名是否有差异[20]。当无法假定总体服从正态分布时,该检验被用作配对 Student’s t-test 检验的替代。设N是检验的样本量, x 1 , i a n d x 2 , i x_{1,i}~\mathrm{and}~x_{2,i} x1,i and x2,i 是第 i i i 对样本.假设 H 0 H_0 H0:两两之间的差异服从零附近的对称分布,假设 H 1 H_1 H1:两两之间的差异不服从零附近的对称分布。试验进行如下:
1.对于 i = 1 , … , N i=1,\ldots,N i=1,…,N,计算 ∣ x 2 , i − x 1 , i ∣ |x_{2,i}-x_{1,i}| ∣x2,i−x1,i∣和sgn ( x 2 , i − x 1 , i ) (x_{2,i}-x_{1,i}) (x2,i−x1,i),其中sgn为符号函数:
sgn ( x ) : = { − 1 if x < 0 , 0 if x = 0 , 1 if x > 0. (1) \operatorname{sgn}(x):=\begin{cases}-1&\quad\text{if }x<0,\\0&\quad\text{if } x=0,\\1&\quad\text{if }x>0.\end{cases}\tag{1} sgn(x):=⎩ ⎨ ⎧−101if x<0,if x=0,if x>0.(1)
2.排除 ∣ x 2 , i − x 1 , i ∣ = 0 |x_{2,i}-x_{1,i}|=0 ∣x2,i−x1,i∣=0的对。令 N r N_r Nr为缩减后的样本量。
3.将剩余的 N r N_r Nr对从最小绝对差到最大绝对差排序, ∣ x 2 , i − x 1 , i ∣ |x_{2,i}-x_{1,i}| ∣x2,i−x1,i∣。
4.对成对进行排序,以最小为1st。领结获得的等级等于他们所跨越的等级的平均值。令 R i R_i Ri表示秩。
5.计算检验统计量W,即符号秩和:
W = ∑ i = 1 N r [ sgn ( x 2 , i − x 1 , i ) ⋅ R i ] (2) W=\sum_{i=1}^{N_r}[\operatorname{sgn}(x_{2,i}-x_{1,i})\cdot R_i]\tag{2} W=i=1∑Nr[sgn(x2,i−x1,i)⋅Ri](2)
6.将W的值与一个阈值进行比较,判断是否拒绝原假设 H 0 H_0 H0。
在实际应用中,p值往往是通过试验计算得到的。这个值被定义为当原假设为真时,获得一个与实际观察到的结果相等或更极端的结果的概率[38]。如果p值小于一个阈值(称为临界值),则拒绝原假设,两个数据集存在显著差异。否则,我们不能拒绝原假设。在统计学中,p-value的两个流行值(0.1和0.05)经常被使用。这些值分别对应于拒绝原假设的99%和95%的置信水平。
3. Related work
选择是影响进化算法性能的关键因素[10]。进化算法中常用的选择策略包括适应度比例选择、等级选择和锦标赛选择[4]。在GP中最流行的选择方法是锦标赛选择[45]。在标准的锦标赛选择中,从种群中随机选择若干个个体(锦标赛规模)。这些个体相互比较,选择获胜者(在更好的健身方面)进入交配池。锦标赛选择的优势在于,它允许通过调整锦标赛规模来调整选择压力。较小的竞赛规模导致较低的选择压力,而较大的竞赛规模导致较高的选择压力。
由于锦标赛选择是GP中最受欢迎的选择方法,已经有许多研究来分析其行为并提高其有效性。早期的研究大多集中在抽样和选择上。盖瑟科尔等人[14]分析了每个个体的选择频率以及在不同的锦标赛规模值的锦标赛选择中未被选中和未抽样个体的可能性。索科洛夫和惠特利提出了无偏锦标赛选择[41],其中所有的个体都有公平的机会参加锦标赛。
Xie和他的同事进行了一系列研究来调查GP中的锦标赛选择。Xie指出,标准的锦标赛选择会导致适应度差的个体可以被多次选择,而适应度好的个体不会被多次选择[44]。因此,他提出了全覆盖的锦标赛选择方法[44],该方法将采样个体排除在下一个锦标赛之外,以确保每个个体都有平等的机会参加锦标赛。其次,Xie et al [45、47]分析了无替换锦标赛选择的性能,其中没有个体可以被多次采样到同一个锦标赛中。锦标赛选择中的另一个问题是,当使用锦标赛规模的小值时,一些个体根本不被采样。然而,谢长廷等. [48]表明,在标准锦标赛选择中,非抽样问题并不严重影响选择绩效。
总体而言,先前的研究表明,采样策略对GP性能的影响较小。因此,研究者们更加关注锦标赛选择的第二步:选择。Goldberg和Deb在文献[15]中提出了二元锦标赛选择,即随机选择两个个体,以概率p,0.5 <p≤1.0选择适应度较好的个体。Back [3]把最好的个体排在第一位,并通过计算排在第j位的个体的选择概率:
N − k ( ( N − j + 1 ) k − ( N − j ) k ) (3) N^{-k}((N-j+1)^k-(N-j)^k)\tag{3} N−k((N−j+1)k−(N−j)k)(3)
其中, k k k为锦标赛规模, N N N为人口规模。相反,布利克勒和Thiele [4]将最差个体排在第一位,并引入了累积适应值分布 S ( f j ) S(f_j) S(fj),它表示适应值 f j f_j fj或更差的个体的数量。最后,计算第 j j j个个体的选择概率为:
( S ( f j ) N ) k − ( S ( f j − 1 ) N ) k . (4) \left(\frac{S(f_j)}N\right)^k-\left(\frac{S(f_{j-1})}N\right)^k.\tag{4} (NS(fj))k−(NS(fj−1))k.(4)
Julstrom和Robinson也将最差的个体排在第一位,并提出了加权k -锦标赛方法[ 19 ]。选择一个介于0和1之间的参数w,通过公式计算秩为j的个体的选择概率:
k ( 1 − w ) N k ( 1 − w k ) ( ( j − 1 ) + w ( N − j ) ) k − 1 (5) \frac{k(1-w)}{N^k(1-w^k)}((j-1)+w(N-j))^{k-1} \tag{5} Nk(1−wk)k(1−w)((j−1)+w(N−j))k−1(5)
后来,Hingee和Hutter [18]引入了d次多项式秩方案,用于计算秩为 j j j的个体的概率:
P ( I = j ) = ∑ t = 1 d + 1 a t j t − 1 (6) P(I=j)=\sum_{t=1}^{d+1}a_tj^{t-1} \tag{6} P(I=j)=t=1∑d+1atjt−1(6)
他们还证明了每个概率竞赛图都等价于一个唯一的多项式秩方案。
近来,研究者将注意力集中在适应选择压力上。Xie和Zhang [46]提出了一种根据种群的适应度等级分布自动调整选择压力的方法。在每个世代中,它们将种群聚成S簇。接下来,他们用替换的方法从S个簇中采样K个簇,并在K个采样簇中选择赢家。最后,从获胜集群中返回一个随机个体。在语法演化方面,Forstenlechner等人引入了语义聚类选择[12]。GP种群中的个体根据其误差向量的相似性进行聚类。然后,从同一簇中抽取父代以提高语义局部性。此外,通过保持多个聚类的存在来管理语义多样性。
最近,赫尔穆特和马西森提出了词表选择[17]。其思想是基于部分健身案例而不是所有健身案例来评估个体的优良性。每次必须选择一个父代,Lexicase的选择随机地洗牌了适合案例的列表。然后,在第一个适应值的情况下,删除没有达到最佳误差值的任何个体。如果种群中存在多个个体,则移除第一个适应案例,并与下一个适应案例重复此过程。La Cava等人[25]将这一技术推广到实值回归问题,并证明了与标准锦标赛选择[16、33]相比,该技术保持了更好的多样性。
本文通过对GP程序语义的统计分析,提出了一种新的锦标赛选择中获胜者的选择方法。具体来说,我们将注意力集中在符号回归问题中产生的误差向量上。文献中最相似的方法是语义选择(Semantic in Selection,SiS)技术[13],它计算父母的语义相似度,并选择语义不相似的父母(也就是说,它们的语义向量之间有很大的差异). 我们不计算语义向量的差异,而是基于误差向量进行统计分析,以确定参加锦标赛的个体的语义多样性。本文方法的详细介绍将在下一节中给出。
4. Methods
本部分提出了三种使用Wilcoxon符号秩检验的统计锦标赛选择技术。其目的是根据统计检验而不是根据它们的适合度值来选择育种亲本。第一种方法称为随机统计锦标赛选择[6],简称TS-R。TS-R的主要目标是促进GP群体的语义多样性,其过程类似于标准的锦标赛选择。然而,在锦标赛中并没有使用适应度值进行个体之间的比较,而是对这些个体的误差向量进行了统计检验。对于一对个体,如果检验表明个体是不同的,则认为适应度值较好的个体为胜者。相反,如果测试确认两个个体没有差异,则从配对中选择一个随机个体。接下来,将胜出者与竞赛规模中的其他个体进行对比测试。算法1对TS-R进行了详细的描述。

在算法1中,函数RandomIndividual()从GP种群中返回一个随机个体。函数Error(A)将个体A的误差向量赋给样本1(1),函数Testing(样品1、样品2)进行Wilcoxon符号秩检验。最后两个函数GetBetterFitness(A、B)和GetRandom(A、B)分别在A和B中找到适应度较好的个体或者在两个个体之间返回一个随机个体。最后,alpha是用来判断是否为原假设的临界值被拒绝。如果p值小于α,则拒绝原假设,选择适应度较好的个体作为赢家。如果检验不能拒绝原假设,则从配对中选择一个随机个体。
第二个被提出的锦标赛选择称为基于规模的统计锦标赛选择[6],简称TS-S。TSS在促进多样性的目标上与TS-R相似。此外,TS-S还旨在减少GP种群中的代码增长。在TS-S中,如果统计检验不能拒绝原假设,则从配对中选择个体规模较小的个体。算法2给出了TS-S的详细描述,其中函数GetSmallerSize(A、B)返回A和B中规模较小的个体,如果A和B的规模相等,则返回第一个个体。

第三种锦标赛选择方法称为概率统计锦标赛选择方法,简称TS-P。该方法不同于TS-R和TS-S方法,它不依赖临界值来决定胜者。相反,TS-P使用p值作为选择获胜者的概率。适应度较好和较差的个体分别以1-p-value和p-value的概率被选择。算法3对TS-P进行了详细的描述。在该算法中,GetBetterWwithProbability(A , B , p-值)以1-p-value的概率返回A和B之间适应度较好的个体,以p-value的概率返回适应度较差的个体。

在提出的3种锦标赛选择技术中,对抽样个体的误差向量进行了一系列的Wilcoxon符号秩检验。潜在的,有两个限制。首先,统计检验的过度使用可能导致显著性差异被偶然发现[7]。因此,这可能会影响统计锦标赛选择的绩效。在第6节中,我们表明,平均而言,TS-R和TS-S中大约50%到70%的Wilcoxon检验是显著的。这个庞大的数字可能有助于缓解受偶然性影响的测试的影响。
第二,执行一系列统计测试所带来的计算时间开销。我们比较了统计锦标赛选择和标准锦标赛选择中选择步骤的计算时间,发现统计锦标赛选择中选择步骤的执行时间大于标准锦标赛选择中选择步骤的执行时间。然而,统计锦标赛选择往往有助于显著降低GP群体的代码增长。随后,使用统计锦标赛选择的GP系统往往比使用标准锦标赛选择的系统运行得更快。
5. Experimental settings
我们对提出的锦标赛选择技术在25个回归问题上进行了测试。其中,15个问题是文献[43]中推荐的GP基准问题,另外10个问题取自UCI机器学习库[2]。对于每个问题,我们也从原始的(无噪声的)形式创建了一个有噪声的版本,产生了25个有噪声的数据集。实验共使用了50个数据集。测试问题的详细说明如表1所示,包括问题的缩写、名称、特征数、训练和测试样本数等。

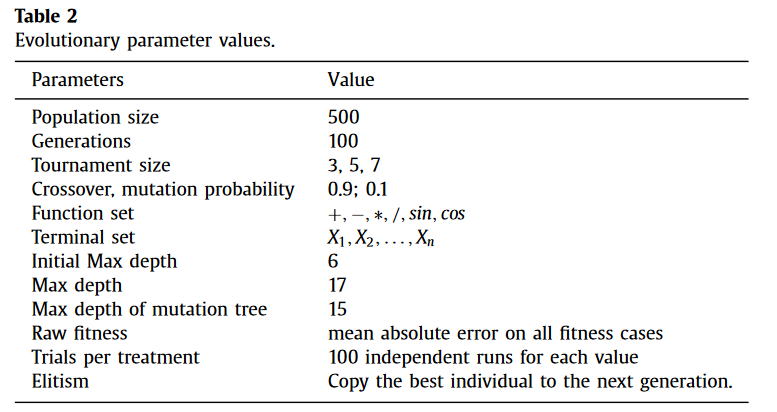
实验所用GP参数如表2所示。每个问题的终端集包含 N N N个变量,对应于该问题的特征数。原始适应度为所有适应度情况下绝对误差的平均值。因此,较小的取值较好。测试了竞赛规模(以下简称旅游规模)的3个流行值:3、5和7。2 TS-R和TS-S的Wilcoxon检验临界值均为alpha = 0.05。对于每个问题和每个参数设置,进行100次运行。
为了进行统计分析,我们遵循Derrac [8]的方法对结果进行Friedman’s检验。如果Friedman检验表明,在95%的置信水平下,至少一项技术与其他技术有显著差异。我们进行了 post-hoc 采用Bonferroni Dunn校正各比较的p值进行分析[8]。在下面的表格中,如果一个方法的结果显著优于GP的标准锦标赛选择(以下简称GP),这个结果在最后被标记为+。相反,如果与GP相比显著更差,则该结果被标记为-。
所有测试的方法的源代码都可以下载。3所有的技术都是用Java实现的,除了GP是我们用Python实现的。4此外,本文中的每个实验都使用相同的计算平台( (操作系统: Windows 7 Ultimate ( 64bit )),RAM 16.0GB,Intel & CoreTMi7-4790 CPU @ 3.60GHz )。
我们将实验分为3组。第一个目的是基于统计分析来研究三种锦标赛选择变体的表现。第二种尝试通过与最先进的语义交叉算子[36]的结合来提高所提出的选择策略的性能。第三组实验检验了策略在含噪问题实例上的性能。
6. Performance analysis of statistics tournament selection
这一部分分析了统计锦标赛选择方法的性能,并与Galvan-Lopez等[13]提出的GP和语义选择(SiS)方法进行了比较。比较中使用的第一个指标是被检验方法的泛化能力[1、42]。100次测试误差的中位数如表3所示。可以看出,SiS和GP的测试误差大致相等。两种技术的测试误差之间的差异往往是微不足道的。SiS仅在F12上显著优于GP,GP仅在F5上显著优于SiS,且TUR-size = 3。反之,三种统计量的锦标赛选择的检验误差往往小于GP的检验误差。在三种统计锦标赛选择中,TS-S在测试数据上的表现最好。TS-S在游程长度为3的17个问题和游程长度为7的14个问题上取得了最好的性能。
在使用Friedman’s检验的统计比较方面,所提出的锦标赛选择往往显著优于GP。在TUR-size = 3时,TS-R在4个问题上显著优于GP,TS-S在12个问题上显著优于GP,TS-P在3个问题上显著优于GP。对于tourism-size = 7,分别为9个、12个和6个问题。相反,GP只在巡回7 ( F23 )的一个问题上显著优于TS-S。
第二个度量是它们的解的平均大小。这些数值如表4所示。虽然SiS方法得到的解往往和GP方法得到的解一样复杂,但统计锦标赛选择方法得到的解比GP和SiS方法简单。利用Friedman’s test统计检验也表明TS-R、TS-S和TS-P所得解的大小在大多数问题上明显小于GP。特别地,TS-S的解的大小在所有问题上总是远小于GP的解的大小。这在一定程度上解释了为什么TS-S在测试数据上的表现优于表3中遵循奥康姆剃刀原则的其他技术[29]。


我们还采用与Nguyen等[32]类似的方法测量了GP、Si S和TS-S (5)的父母与子女之间的语义距离。这些信息显示了一种方法在搜索空间中发现不同区域的能力。在表5中给出了在总体上平均的一对个体(例如,父母和子女)与游程长度为3的100游程之间的语义距离。显然,与GP相比,SiS和TS-S都保持了更高的语义多样性。TS-S和SiS分别在23个和21个问题上保持了比GP更好的语义多样性。这些结果表明,TS-S实现了其增强GP群体语义多样性的目标之一。

本节的最后一个结果是,在TS-S和TS-R的Wilcoxon检验中,当Tweet-size = 3时,拒绝原假设(Nrejnull)的百分比。该值在公式中计算。(7)
N rejnull = N p N test (7) N_{\text{rejnull}}=\frac{N_p}{N_{\text{test}}} \tag{7} Nrejnull=NtestNp(7)
其中 N p N_p Np是拒绝原假设的Wilcoxon检验的次数, N test N_{\text{test}} Ntest是在每种选择技术下进行的Wilcoxon检验的总次数。表6显示,有大量的检验拒绝了原假设。TS-R的这一数值往往在30%~70%之间,TS-S的数值略高于(从50%提高到近90%)。因此,统计检验将对TS-R和TS-S中的选择过程产生相当大的影响[7]。

总体而言,三种统计锦标赛选择方法找到了更简单的解决方案,并在未见数据上具有更好的泛化能力。特别地,TS-S方法得到的解比GP方法得到的解要复杂得多。此外,TS-S的泛化能力也优于GP和SiS。
7. Combining semantic tournament selection with semantic crossover
在这一部分中,我们通过将该技术与最近提出的交叉随机期望算子(RDO) [36]相结合,提出了对TS-S (在提出的三种选择技术中,最好的方法)性能的改进。也就是说,在TS-S中,我们用RDO代替标准交叉。由此产生的GP系统称为具有随机期望算子的统计锦标赛选择,简称为TS-RDO。之所以将RDO与TS-S相结合,是因为TS - S的训练误差往往比GP更差[6]。此外,RDO在训练数据[32、36]上表现良好。我们预测,这些语义选择和语义交叉策略以TS-RDO的形式耦合将导致性能的提高。
我们将TS-RDO与TS-S,pureGP (一种最先进的膨胀状态控制方法) [26],RDO [36]和GP进行了比较。RDO的设置类似于[32]中的设置。这些方法的测试数据结果如表7所示。可以看出,TS-RDO在五种测试技术中取得了最好的结果。TS-RDO的试验误差分别在3和7个问题上最小,分别为12和14个问题。此外,TS-RDO更频繁地显著优于GP与TS-S相比。TS-RDO在游程为3的17个问题和游程为7的21个问题上明显优于GP,而TS-S仅为10和11。RDO取得了次优的(后面的TS-RDO)结果。在所有问题上,RDO的测试误差往往小于GP。这与Pawlak等人[32、36]中的结果是一致的,其中RDO已经被报道在未见到的数据上表现良好。
在表7所考察的5种方法中,pureGP的表现最差,在游程大小为3和7的情况下,pureGP仅在2和4题上显著优于GP,而在9和10题上则差于GP。这个结果与特鲁希略等人[26]中的结果略有不同,在未见到的数据上,与GP相比,纯GP表现得同样好。原因可能是我们的实验中测试的问题比[26]中的问题更困难。进一步的研究需要对此进行检验。

解的平均规模如表8所示。纯GP和TS - S得到的溶液尺寸均明显小于GP。通过对GP和TS - S的比较,表中显示它们的解的大小大致相等。对于RDO,它的解也往往小于GP的解。然而,这似乎只有在基准问题上才是如此。在大多数UCI问题上,RDO的解比GP的解更复杂。表8中的最佳技术是TS - RDO。该方法在大多数与解的大小有关的问题上取得了最好的结果。TS - RDO分别在游程为3和7的12和13个问题上找到的解的平均尺寸最小。

总的来说,与TS-S相比,TS-RDO改善了测试误差,并进一步减小了解决方案的大小。此外,该技术优于RDO和纯GP,这两种最近提出的用于提高GP性能和减少GP代码膨胀的方法。
8. Performance analysis on the noisy data
本节考察了第七节中的五种方法在含噪数据上的表现。在数据挖掘中,人们观察到当问题与噪声[39、40]结合时,问题将变得更加困难。我们通过在表1中问题的所有特征和目标函数中添加10%的均值为零、标准差为1的高斯噪声,在原数据集的基础上创建了一个噪声数据集。此外,训练数据和测试数据都安装了噪声。噪声数据上的测试误差如表9所示。

从表9中可以观察到一些有趣的结果。首先,TS-RDO对含噪数据的一致性略高于无噪数据。TS-RDO在所有锦标赛规模都取值的问题上取得了最好的测试误差。其次,RDO在有噪声数据上的性能不如在无噪声数据上的性能。该技术仅在一个问题上取得了最优的性能,即TUR-Size = 7。这说明RDO在噪声问题上容易出现过拟合现象。第三,TS-S的表现也比在无噪声数据上更加稳健和一致。该方法在游程长度为3和7的11和13个问题上明显优于GP,而在无噪声数据上分别只有10和11个。最后,就泛化能力而言,clean GP仍然是最差的方法。
由于所检验的方法在含噪数据上的解的大小与在无噪数据上的结果相似,因此在补充中给出。图1给出了进化过程中4个典型问题的测试误差和种群规模。6可以看出,TS-RDO往往在整个进化过程中取得了最低的测试误差。TS-RDO很快取得了较好的测试误差,并经常不断提高该值。在一个问题上,F25,的测试误差TS-RDO在末代略有上升。然而,这种交叉在几代后就过拟合了,特别是在UCI问题上,如F22和F25。该图还表明,GP和纯GP的测试误差通常比其他测试误差大得多。最后,TS-S是过拟合影响较小的技术。这种选择仅仅是测试误差的趋势大多是向下的技术。

在种群规模增长方面,GP、TS - S和TS - RDO三种方法都没有引起GP种群代码量的大幅增长。这些技术的种群规模在进化过程中只是略有增加。相反,GP和RDO的种群数量增长较快,远远高于GP、TS - S和TS - RDO。
本文最后分析的实验结果是5种方法的平均运行时间。超过100次运行的平均运行时间如表10所示。显然,TS-S是所有测试方法中速度最快的系统,特别是当游程=3时。这并不奇怪,因为TS-S的编码增长比GP少得多(图1)。与GP相比,所有其他技术都需要更长的运行时间。对于pureGP,由于使用了Python语言实现,所以计算时间比GP和其他算法都要长。与GP相比,RDO也需要更长的运行时间,这与之前的研究结果一致[32]。最后,虽然TS-RDO比GP慢,但它的执行时间与RDO相比已经大大减少。因此,通过将TS-S与RDO相结合,我们获得了比所有测试方法更好的测试误差。此外,该技术还有助于减少GP码的增长,从而降低RDO的计算开销。

表11给出了GP、TS-S中选择步的平均执行时间和一次运行的平均执行时间。可以看出,TS-S的选择步长比GP慢。然而,这种开销大多是可以接受的。此外,由于TS-S有助于减少GP种群的代码增长,因此TS-S一次运行的总体计算时间往往小于GP。

我们还观察到TS-S中选择步的执行时间在适应度函数个数较多的问题(F8、F9等)上往往比在适应度函数个数较少的问题(F1、F1等)上要高。在第一组问题上,只对部分适应度情况进行统计检验,可以进一步减少TS-S的计算时间。为了验证这一假设,进行了一个额外的实验,在适应度案例数大于100的问题上,对适应度案例的100个随机值进行了Wilcoxon检验。本实验结果(表12)表明,该技术(TS-S-100)有助于进一步减少TS-S的运行时间(约50% ),同时其测试误差基本得以保留。因此,TS-S-100的平均运行时间始终远小于GP。
9. Conclusions and future work
在本文中,我们引入了使用 statistical test 作为语义选择方法的一部分的思想,该方法利用了 GP 个体的误差向量。我们提出了三种不同的锦标赛选择方法,利用对这些语义向量的统计分析来为交配池选择获胜者。提出的技术旨在增强 GP 种群中的语义多样性和减少代码膨胀。在大量的符号回归问题上检验了该方法的有效性,包括 GP 基准问题和从 UCI 数据集中抽取的额外问题实例。在实验结果中我们观察到,所提出的技术尤其是 TS-S 在提高 GP 泛化能力和减少 GP 代码增长方面优于标准的锦标赛选择和纯 GP (控制 GP 代码膨胀的最新方法的状态)。
所提方法的优点之一是设计和实现简单。这使得它可以通过与 GP 中的先进技术结合来进一步改进。本文将语义锦标赛选择的最佳方法 TS-S 与最近提出的语义交叉 RDO 相结合。由此得到的方法 TS-RDO 取得了更好的测试误差,在更大程度上减少了 code growth。此外,生成了每个问题的噪声实例,并测试了各种策略的性能,表明所提出的方法在噪声问题上具有良好的性能。
未来的工作有多个研究方向。首先,实验结果表明,所提方法的性能对锦标赛规模的不同取值具有鲁棒性。但是,如果在学习过程中能够自适应地调整锦标赛的规模会更好 [16]。其次,本文使用统计分析只是为了增强选择性。也有可能在 GP 算法的其他阶段使用统计分析,例如在模型选择中 [49]。在应用方面,TS-S 和 TS-RDO 可以应用于任何输出为单一实数的问题域。在本文中,我们专注于 GP 最流行的问题域- -符号回归,未来我们将把语义选择扩展到分类和程序综合等流行的问题域。然而,它并不像RDO那样高。第二好的技术往往是RDO。















 3151
3151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









