






工具PyTorch
安装PyTorch详细过程_pytorch安装-CSDN博客
Learning PyTorch with Examples — PyTorch Tutorials 2.3.0+cu121 documentation
基础知识
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
如何建立学习模型?(训练得到模型)
1.基于规则的
人工设计,改进的图搜索树搜索等;表示学习,通过数据集的训练得到
2.经典机器学习
分类(有标签),回归,聚类(无标签),降维
SVM支持向量机方法缺陷:人工设计的特征有局限,无法应对大数据、非结构化的数据
3.深度学习(端到端的训练)
Machine Learning
数据集合分training set (分训练和开发)/test set-避免过拟合-泛化能力
y=wx+b拟合曲线:1.给定random,2.求预测结果,3.得与实际值之间评估loss(需要最小)
cost function: MSE平均平方误差mean square error
实践操作
使用jupyter分块调试,控制台输入
source activate pytorch%进入环境pytorch(或者自己重新创建环境)
jupyter notebook
或者Pycharm,在test新建python文件,运行,报错少文件,点terminal 安装,输入pip install 少的文件。
实践一
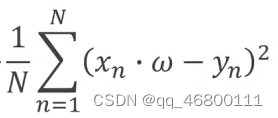
作业
线性模型下的MSE y=wx+b,通过枚举w,b,得到损失函数,求累计求和除以总数的MSE误差最小
import numpy as py #导入数组的包并简写为np
import matplotlib.pyplot as plt #导入数学绘图的包并简写为plt
from mpl_toolkits.mplot3d import Axes3D #从工具箱导入3D绘图工具包Axes3D
#数据集
x_data=[1.0,2.0,3.0]
y_data=[5.0,8.0,11.0]
#定义前向传播函数
def forward(x):
return x*w+b #注意缩进,这里w,b是在函数调用的时候才有用
#定义损失函数
def loss(x,y,w,b):
y_pred=forward(x)
return (y_pred-y)**2 #平方可用**2表示
#参数生成
W=np.arange(0.0,4.1,0.1) #(起始,终止,步长)
B=np.arange(0.0,4.1,0.1)
[w,b]=np.meshgrid(W,B) #绘3D图需要
#计算损失函数的总和
l_sum=np.zeros_like(w)
for i in range(len(W))
for j in range(len(B))
for x_val,y_val in zip(x_data,y_data)
loss_val=loss(x_val,y_val,w[i,j],b[i,j])
l_sum[i,j]+=loss_val
#创建3D图表并绘制图像
fig=plt.figre()
ax=fig.add_subplot(lll,projection='3d')
ax.plot_surface(w,b,l_sum/3,cmap='viridis')
ax.set_xlabel('w')#标注轴的名称
ax.set_ylabel('b')
ax.set_zlabel('Loss')
plt.title('3D Graph of Loss Surface with Weignt w and b')#标注标题
plt.show()实践二
梯度下降法:避免枚举的复杂度,通过损失函数相邻的下降斜率(倒数,学习率)来决定下一步的走向,能够快速找到局部最优点(类似贪心算法,注意局部最优不等于全局最优,最大问题是鞍点)
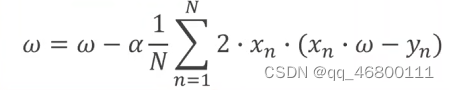
import matplotlib.pyplot as plt
#训练集
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
#初始化权重的可能取值
w=1.0
#定义前向传播函数
def forward(x):
return x*w
#定义代价函数
def cost(xs,ys):
cost=0
for x,y in zip(xs,ys):
y_pred=forward(x)
cost+=(y_pred-y)**2
return cost/len(xs)
#定义梯度函数grad
def gradient(xs,ys):
grad=0
for x,y in zip(xs,ys):
grad+=2*x*(x*w-y)
return grad/len(xs)
epoch_list=[]
cost_list=[]
print('predict (before training)',4,forward(4))#这里的w是前面给的
#梯度下降更新w
for epoch in range(100):
cost_val=cost(x_data,y_data)
grad_val=gradient(x_data,y_data)
w-=0.01*grad_val #这里的alpha是学习速率0.01
print('epoch:',epoch,'w=',w,'loss',cost_val)
print('predic (after training)',4,forward(4))
plt.plot(epoch_list,cost_list)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
随机梯度法(一次算一个)
import matplotlib.pyplot as plt
#训练集
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
#初始化权重的可能取值
w=1.0
#定义前向传播函数
def forward(x):
return x*w
#定义损失函数(无需求和)
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
#定义梯度函数grad
def gradient(x,y):
return 2*x*(x*w-y)
epoch_list=[]
loss_list=[]
print('predict (before training)',4,forward(4))#这里的w是前面给的
#梯度下降更新w
for epoch in range(100):
for x,y in zip(x_data,y_data):
grda=gradient(x)
w-=0.01*grad
print('\tgrda:',x,y,grad)
l=loss(x,y)
print('progress',epoch,'w=',w,'loss',l)
print('predic (after training)',4,forward(4))
plt.plot(epoch_list,loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
实践三
反向传播
引例:y=x*w,类似神经网络,通过更新w
import numpy as np
import matplotlib.pyplot as plt
import torch
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
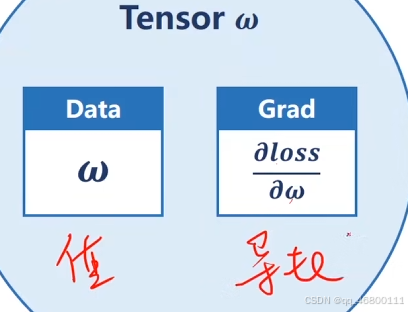
w=torch.Tensor([1.0])#Tensor用来保存w的值和相关梯度
w.requires_grad=Ture
def forward(x):
return x*w
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
print('predict (before training)',4,forward(4))
for epoch in range(100):
l=loss(1,2)
for x,y in zip(x_data,y_data):
l=loss(x,y)
l.backward()#释放计算图
print('\tgrad:',x,y,w.grad.item())#item()取值变标量
w.data=w.data-0.01*w.grad.data#由于是Tensor类型,需要直接计算
w.grad.data.zero_()#释放之前计算过的梯度
print('Epoch:',epoch,l.item())
print('predict (after training)',4,forward(4).item())注意:构建计算图是,使用张量,权重更新时使用标量
作业:
y=w1*x^2+w2*x+b
import numpy as np
import matplotlib.pyplot as plt
import torch
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w1=torch.Tensor([1.0])#初始权重
w1.requires_grad=true#设置计算梯度,默认不计算
w2=torch.Tensor([1.0])#初始权重
w2.requires_grad=true#设置计算梯度,默认不计算
b=torch.Tensor([1.0])#初始权重
b.requires_grad=true#设置计算梯度,默认不计算
def forward(x):
return w1*x**2+w2*x+b
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
print('Predict (before training)',4,forward(4))
for epoch in range(100)
l=loss(1,2)
for x,y in zip(x_data,y_data)
l=loss(x,y)
l.backward()
print('\tgrad:',x,y,w1.grad.item(),w2.grad.item(),b.grad.item())
w1.data=w1.data-0.01*w1.grad.data
w2.data=w2.data-0.01*w2.grad.data
b.data=b.data-0.01*b.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
print('Epoch:',epoch,l.item())
print('Predict (after training)',4,forward(4))
实践四
05.用PyTorch实现线性回归_哔哩哔哩_bilibili
如何利用Pytorch的工具建立自己的模型(主要是构建计算图)
1构建数据集
2设计模型(计算估计y)nn---newrod network
--定义为类(继承Module)-至少两个函数_init_()和 forward()
3构建损失
4设计循环条件
import torch
x_data=torch.Tensor([1.0],[2.0],[3.0])
y_data=torch.Tensor([2.0],[4.0],[6.0])
#定义构造模型的类,此类继承于Module
Class LinearModel(torch.nn.Module)
def _init_(self):#构造函数
super(LinearModel,self)._init_()
self.Linear=torch.nn.Linear(1,1)#构造对象,线性单元(输入维度,输出维度,默认true\+b)
def forward(self,x):
y_pred=self.Linear(x)#调用函数计算估计y
return y_pred
model=LinearModel()#实例化模型
criterion=torch.nn.MSELoss(size_average=False)#调用MSE的损失
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)#lr是学习率
for epoch in range(1000):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
print(epoch,loss.item())#注意item
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w=',model.Linear.weight.item())
print('b=',model.Linear.bias.item())
x_test=torch.Tensor([4.0])
y_test=model(x_test)
print('y_pred=',y_test.data)实践五
分类问题:logistics 回归----区别线性回归,举例0-9手写数字的识别,用识别概率表示(概率和为1),初步理解为在线性回归基础上多一个σ,并且用某些饱和(激活)函数做权重,损失变为交叉熵。
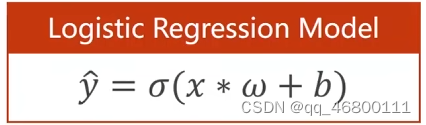


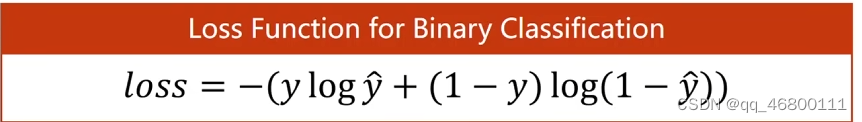 BCE:二分类交叉熵
BCE:二分类交叉熵
import troch
# import torch.nn.functional as F
x_data=torch.Tensor([1.0],[2.0],[3.0])
y_data=torch.Tensor([0],[0],[1])
class LogisticRegressionModel(torch.nn.Module):
def _init_(self):
super(LogisticRegressionModel,self)._init_()
self,linear=torch.nn.Linear(1,1)
def forward(self,x)
#y_pred=F.sigmoid(self.Linear(x))
y_pred=torch.sigmoid(self.Linear)
return y_pred
model=LogisticRegressionModel()
creterion=torch.nn.BCELoss(size_average=False)
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(1000):
y_pred=model(x_data)
loss=criterion(y_pred,y_data)
print('epoch:',epoch,loss.item)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('w=',model.Linear.weight.item())
print('b=',model.Linear.bias.item())
x_test=torch.Tensor([[4.0]])
y_test=model(x_test)
print('y_pred:',y_test.data)实践六
PyTorch 深度学习实践 第7讲_print(epoch, loss.item())-CSDN博客

import numpy as np
import torch
import matplotlib.pyplot as plt
xy=np.loadtxt('diabets.csv',delimiter=',',dtype=np.float32)#同目录下(‘文件名’,分隔符,数据处理类型)
x_data=torch.from_numpy(xy[:,:-1])#第一个“:”是指读取所有行,第二个是‘:’是指从第一列开始,-1最后一列不要
y_data=torch.from_numpy(xy[:,[-1]])#[-1]取最后一列
class Model(torch.nn.Module):
def _init_(self):
super(Model,self)._init_()
self.Linear1=torch.nn.Linear(8,6)
self.Linear2=torch.nn.Linear(6,4)
self.Linear3=torch.nn.Linear(4,1)
self.sigmoid=torch.nn.Sigmoid()
self.ReLU=torch.nn.ReLU()
def forward(self,x):
x=self.ReLU(self.Linear1(x))
x=self.ReLU(self.Linear2(x))
x=self.sigmoid(self.Linear(x))
return x
model=Model
criterion=torch.nn.BCELoss(reduction='mean')
optimizer=torch.optim.SGD(model.parameters(),lr=0.1)
epoch_lis=[]
loss_list=[]#开辟数组空间
#开始训练
for epoch in range(100):
y_pre=model(x_data)
loss=criterion(y_pred,y_data)
print(epoch,loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
plt.plot(epoch_list,loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()实践七
加载数据集、索引、Min Batch

imporch torch
imporch numpy as np
from torch.utils.data import Dataset
from troch.utils.data import DataLoder
#导入并创造数据集
class DiabetesDataset(Dataset)
def _init_(self,filepath):
xy=np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len=xy.shape[0]
self.x_data=torch.from_numpy(xy,[:,:-1])
self.y_data=torch.from_numpy(xy,[:,[-1]])
def _getitem_(self,index):
return self.x_data[index],self.y_data[index]
def _len_(self):
return self.len
dataset=DiabetesDataset('diabetes.csv')
train_loader=DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=0)#多线程操作
#构造模型建立的类
class Model(torch.nn.Module):
def _init_(self):
super(Model,self)._init_()
self.Linear1=torch.nn.Linear(8,6)
self.Linear2=torch.nn.Linrae(6,4)
self.Linear3=torch.nn.Linear(4,1)
self.sigmoid=torch.Sigmoid()
def forward(self,x)
x=self.sigmoid(self.Linear1(x))
x=self.sigmoid(self.Linear2(x))
x=self.sigmoid(self.Linear3(x))
return
model=Model()
criterion=troch.nn.BCELoss(reduction='mean')#损失执行标准
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)#设置优化方式和学习率lr
#训练
if _name_=='_main_':#在windows下多线程操作避免报错,使用Linux可以不用这句
#Training cycle
for epoch in range(100):
#Loop over all batch(小分支训练)
for i,data in enumerate(train_loader,0):
#1 Prepare data
inputs,labels=data
#2 Forward
y_pred=model(inputs)
loss=criterion(y_pred,labels)
print(epoch,i,loss.item())
#3 Backward
optimizer.zero_grad()
loss.backward()
#4.Update
optimizer.step()

实践八
多分类问题
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size=64
transform=transform.Compose([transforms.ToTensor(),transfroms.Normalize((0.137,),(0.3081,))])#归一化,均值0.137和方差(标准差)0.3081,需要求得;transform为正态分布
train_dataset=datasets.MNIST(root='diabetes.cvs.gz',train=True,download=True,transform=transform)
train_loader=DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
train_dataset=datasets.MNIST(root='diabetes.cvs.gz',train=False,download=True,transform=transform)
train_loader=DataLoader(train_dataset,shuffle=False,batch_size=batch_size)
calss Net(torch.nn.Module):
def _init_(self):
super(Net.self)._init_()
self.l1=torch.nn.Linear(784,512)#图像矩阵28*28
self.l2=torch.nn.Linear(512,256)
self.l3=torch.nn.Linear(256,128)
self.l4=torch.nn.Linear(128,60)
self.l5=torch.nn.Linear(60,10)#分多层,避免降层跨度大,信息损失多
def forward(self,x):
x=x.view(-1,784)#-1,自动获取mini_batch
x=F.relu(self.l1(x))
x=F.relu(self.l2(x))
x=F.relu(self.l3(x))
x=F.relu(self.l4(x))
return self.l5(x)#最后一层不做激活,不做线性化
model=Net()
criterion=torch.nn.CrossEntropyLoss()
optimizer=optim.SGD(model.parameters(),lr=0.01,momentum=0.5)#冲(动)量0.5,梯度下降有冲量,可以避免下降过程中停留在鞍点,没取到最优点
def train(epoch):
running_loss=0.0
for batch_idx,data in enumerate(train_loader,0)
inputs,target=data
optimizer.zero_grad()
outputs=model(inputs)
loss=criterion(outputs,target)
loss.backward()
optimizer.step()
running_loss+=loss.item()
if batch_idx % 300==299
print('[%d,%5d] loss:%.3f'% (epoch+1,batch_idx+1,running_loss/300))#300轮输出一次
running_loss=0.0
def test():
correct=0
total=0
with torch.no_grad():
for data in test_loader:
images,labels=data
outputs=model(images)
_, predicted=torch.max(outputs.data,dim=1)#_就是占个位置,表示那里有值但是用不着,可以把它改成任何峦骨
total +=labels.size(0)
correct+=(predicted==labels).sum().item()
print('accuracy on test set:%d %%' % (100*correct/total))
if _name_=='_main_':
for epoch in range(10)
train(epoch)
test()














 23万+
23万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









