






1 摘要
- 相比于新闻文章,社交媒体上有大量有关人类情绪和相应原因的表述,但是现在社交媒体数据上的情绪原因抽取做的还不多,因为缺少社交媒体数据的细粒度标注。
- 早期研究要么采用基于规则的方法,要么采用需要大量特定领域标注数据的有监督机器学习方法。前者抽取性能受限,后者受制于有标注的数据量不足,且很难迁移到其他领域。
为了解决以上这两个问题,本篇文章提出了两种改进策略。
- 为了解决第一个问题,我们设计了一个更专用的基于规则的系统,基于成分句法分析树来发现社交媒体中的因果模式。该系统使我们能够获取大量细粒度的注释数据。也就是说,作者通过肉眼观察或者自动化工具,归纳总结后发现,成分句法分析树中存在某种模式时,通常就存在因果关系。利用这一特性,对于社交媒体上大量无标注数据,只需要获取并分析它们的语法分析树,并进行解析,就能自动化地给出标注,从而获取大量的细粒度标注数据。
- 为了解决第二个问题,作者在第一步标注好的数据基础上,采用一种特定的训练策略,训练一种神经网络模型,进一步提高模型的泛化能力。
实验结果证实了在无监督和弱监督场景下,作者的方法相比于其他方法具有优势。
2 引言
- 早期的研究旨在通过从语言学角度,使用基于规则的方法解决任务。这些方法的优点是设计的规则较为通用,很容易泛化到其他领域,缺点是抽取性能有限。
- Some recent studies further employed statistical machine learning or deep learning models to extract emotion causes in social media.这些研究都侧重于在特定领域的小数据集上训练他们的模型。但是它们严重依赖原因标注,只适用于特定领域。由于社交媒体上存在大量无标注数据,这些数据分布于各种领域,为每个领域数据建立一个模型是不现实的。
为了解决上述问题,我们提出了一种无需人类标注就能抽取社交媒体情绪原因的方法。该方法主体是一种基于规则的方法,并采用一种特殊的训练策略。
首先是constituency based rule方法,通过发现情绪和原因表达中特殊的句法模式,不依赖人类标注就能获得大量基于规则标注的数据集。然后是引入了一个规则引导的伪监督学习 (RGPS) 框架来开发一个通用的系统,用于在社交媒体上提取情感原因。该方法涉及通过屏蔽提示词在规则注释数据集上训练模型,并包括一个用于迭代学习的标签细化模块。
为了评估方法的有效性,在COVID-19 ECE数据集和CoEmoCau数据集上进行实验,我们的实验结果如下:
1) 与之前的基于规则的方法相比,我们提出的基于成分的规则在跨度级别的情感原因提取性能上显示出显著的提升。此外,这种方法实现了高精度,这对于社交媒体中的大规模实际应用非常有益。
2) 伪监督ECE模型基于CBR显著提高了情感原因提取的召回率,从而导致F值的显著提升。基于25600个实例的基于规则的伪注释,我们的RGPS方法在跨度级别的提取性能上与使用数百个人工标注实例的标准监督学习方法相当。
3)通过利用我们的RGPS方法并结合少量人工标注数据,我们进一步提高了性能。例如,借助200个人工标注实例的帮助,我们的方法得到的结果与使用该数据集上全部人工标注得到的结果相当。
3 方法
因为社交媒体博文比较短,且充满非正式表达,因此更适合在跨度级别去做情绪原因识别。
因此,本研究聚焦于跨度级别的情感原因识别任务(Li et al., 2021b),其形式化定义如下:给定一个包含N个词符序列的帖子S = [w1, w2, ..., wN]和在S中标注的情感表达E = [e1, e2, ..., eK],跨度级别的情感原因识别任务旨在从S中检测出激发情感表达的情感原因跨度的边界。
3.1 基于成分的规则
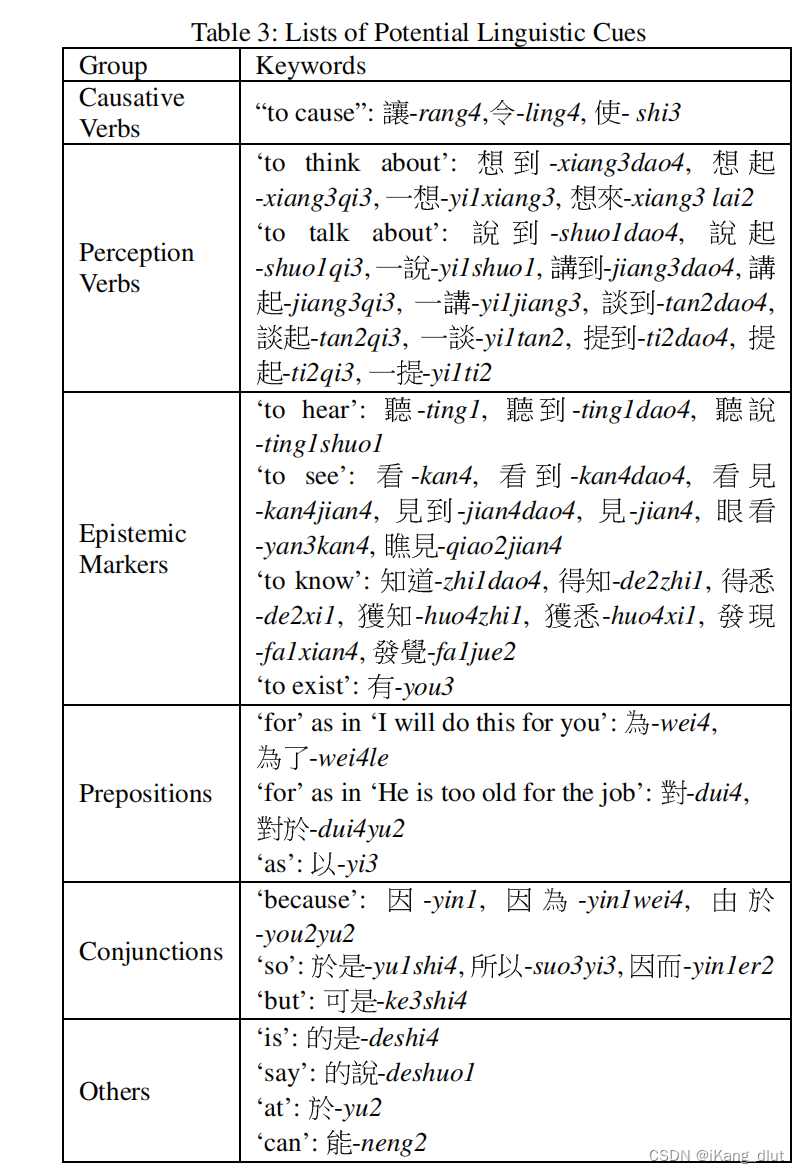
以前的工作发现了一些特定的词表明了情绪原因,将这些词总结为七个类别。
3.1.1 对数据集的观察和假设

如表 1 所示,作者基于人工注释数据集 (COVID19-ECE) 的统计数据表明,62.07% 的黄金情绪原因跨度完全与成分分析树上单个成分对应的文本跨度重叠。当放宽边界条件,允许5个token的错误时,重叠率提高到85.89%。此外,统计数据表明成分分析树中超过90%的原因组成类型,属于IP(简单从句)、VP(动词短语)和 NP(名词短语)。基于这一观察,我们提出了我们的基本假设,即跨度级情感原因提取问题可以转化为选区解析树上特定成分类型的原因成分识别问题。也即跨度级别情绪原因抽取问题可以转化为对成分解析树上特定成分进行分类。
具体来说,作者为 ECE 问题定义了选区解析树的一些关键成分和因果句法关系,如下所示。
- 情绪成分:完全覆盖情绪词,并且有最深的深度。
- 线索词成分:完全覆盖线索词,并且有最深的深度。
- 原因成分:完全覆盖原因跨度,并且有最深的深度。
- 因果关系:原因成分和线索词成分之间的连接部分。
3.1.2 模式,线索词和规则的细节
作者通过观察数据集,总结归纳出线索词和原因成分在句法分析树中存在固定的模式,
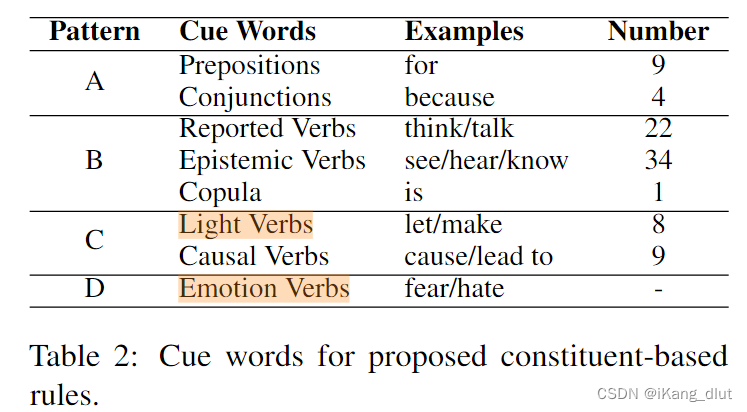
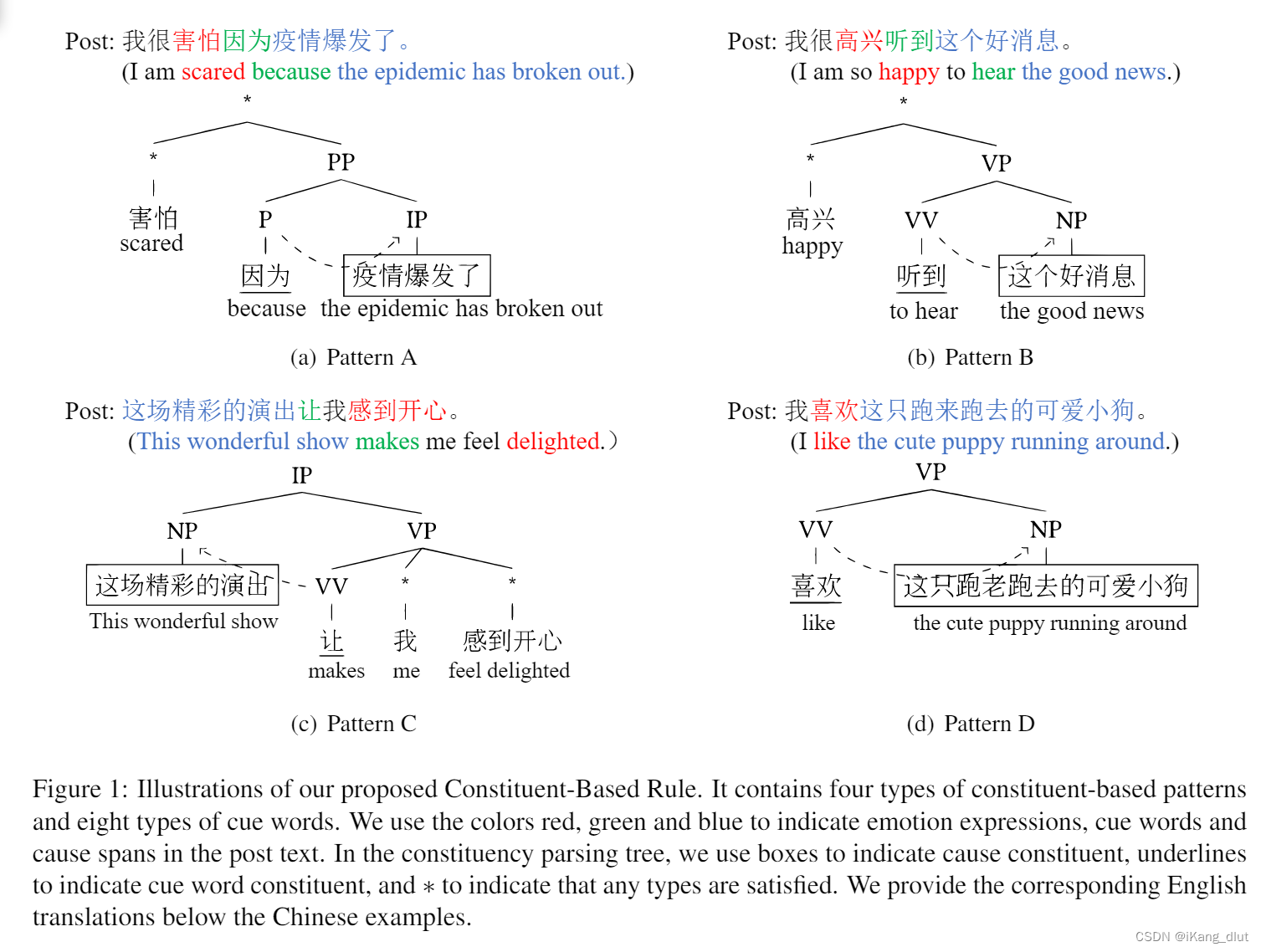
作者总结归纳得出这样的结论,线索词和原因成分在成分分析树中存在较为固定的模式,总结为以下四种。
- 在模式A中,如图1(a)所示,相应的提示词类别是介词或连词。在组成成分解析中,提示词的类别用'P'表示,以指示一个介词,其父节点类型为'PP'(介词短语)。当其右子节点属于'IP/VP/NP'时,该右子节点被认为是潜在的原因成分。具体来说,在输入文本中含有明确情感词“害怕”时,我们首先匹配介词提示词“因为”。然后,我们检查子树的模式是否与模板匹配。如果验证成功,我们可以定位树中原因成分的位置,并将相应节点映射到原因范围“疫情已经爆发”。
- 模式B,C,D为另外四种线索词和原因成分之间的模式。
采用模式匹配去做可能会在匹配过程中匹配多个候选成分,采用就近原则,选择距离情绪成分或者提示词成分最近的候选成分作为原因成分。
作者还提到,经过观察,中英文情绪原因表达的句法模式是基本接近的,因此中文微博数据集上总结出来的规则和模式,大多数可以直接迁移到英文上,只有很少的区别。
3.2 基于规则引导的伪监督学习
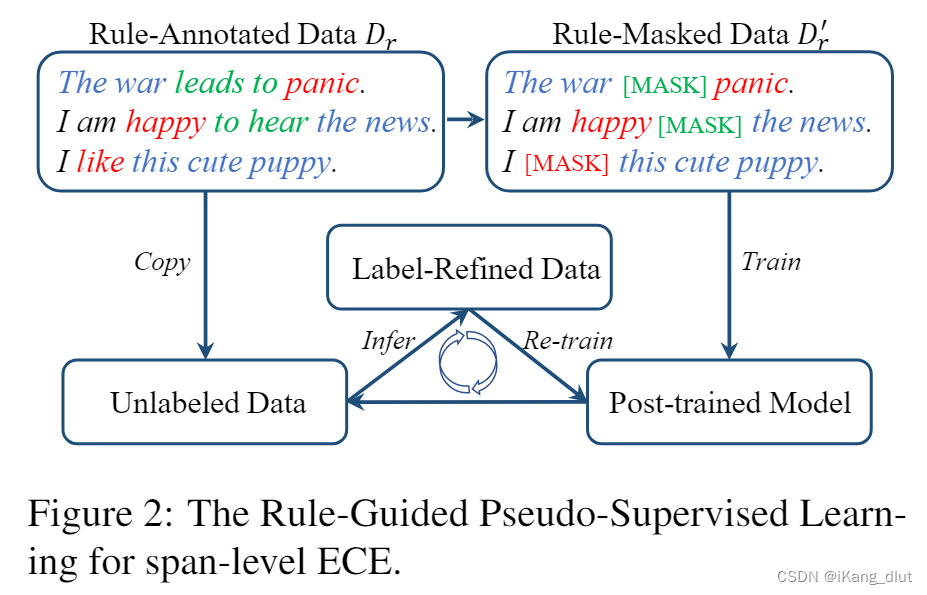
作者指出常规的注释数据集只能反映特定的模式,无法涉及所有的因果关系模式,这限制了模型的泛化能力。为了解决这个问题,提出了一种“规则引导的伪监督学习”(RGPS)方法。该方法使用案例推理(CBR)自动注释数据,创造出一个大规模的规则注释数据集。然后,利用这个数据集通过RGPS方法训练模型,从而提高其泛化能力。如图2所示。
跨度级ECE任务可以形式化为一个序列标记任务(李等人,2021b)。具体来说,一个帖子S = [w1, w2, ..., wN]和S中给定的情感表达E = [e1, e2, ..., eK]被串联起来形成一个组合序列X,作为输入输入到一个预训练模型如BERT中:[CLS],w1,...,wN,[SEP],e1,...,eK,[SEP],其中[CLS]和[SEP]是特殊标记。模型的输出是组合序列中每个标记的上下文化表示,然后我们使用条件随机场(CRF)层来预测输入帖子的标签。我们使用{B, I, O}作为标签集。这里,B、I和O分别代表原因跨度的开始、内部和外部,指示跨度范围。
为了训练模型学习超越由规则注释数据集固有的模式的因果关系,我们提出了一种称为“规则掩蔽”的方法。它涉及随机掩蔽一定比例的因果提示词和情感提示词,然后指导模型在没有看到这些明确提示的情况下预测情感原因范围。这个过程打破了规则注释数据集中固有的因果模式,并阻止模型在编码过程中依赖提示词特征,从而使模型更多地关注其他有效且有意义的信息。如图2所示,绿色和红色的[MASK]标记分别代表被掩蔽的因果提示词和情感提示词。
请注意,我们屏蔽了模型输入层注意掩码中的提示词。在训练期间,训练模型以学习原始序列标签,促进捕获情感表达和情感原因跨度之间的联系。我们使用 Dr' 来表示修改后的数据集.
from transformers import BertTokenizer, BertForMaskedLM, BertConfig
import torch
# 初始化BERT模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
# 示例文本
text = "I feel very [MASK] because my pet is sick."
# 对文本进行分词处理
inputs = tokenizer(text, return_tensors='pt')
labels = tokenizer("I feel very sad because my pet is sick.", return_tensors='pt')['input_ids']
# 将标签应用于模型
inputs['labels'] = labels
# 训练模型(这里仅为示例,实际应用中需要大量数据和迭代)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
model.train()
outputs = model(**inputs)
loss = outputs.loss
loss.backward()
optimizer.step()
# 打印损失值
print(loss.item())
gpt4给出了这样一段代码示例,用以说明屏蔽情绪词并进行掩码重建的过程。
CBR生成的标签有限且常常不准确。经过初步实验,我们发现通过伪标签进行初始训练的模型已经显著优于基于规则的方法。因此,我们提出标签细化,在训练过程中迭代更新原始标签。具体来说,我们用初始规则标签在被掩蔽规则注释的数据集D′r上训练初始模型θ(0)。在后续的迭代轮次中,我们使用前一轮模型在训练集上预测的标签作为监督标签来训练当前轮次的模型。因此,在第t次迭代中,模型的输出为ˆy(t) = BERT-CRF(x; θ(t))。在每次迭代中,我们使用前一次迭代已经收敛的模型来初始化当前轮次的模型。原始规则注释数据集中的信息通过迭代训练程序传播。随后的模型在一个新的、具有更准确和多样化标签的细化数据集上进行训练,这有助于模型更有效地学习。
从图中可以看出,在初始轮次,模型首先在随机mask掉因果提示词和情感提示词的基于规则标注的数据集上进行训练,这时模型的表现已经优于优于一些基于规则的方法了。然后模型不断地在无标签数据集上进行迭代地训练,不断优化模型的效果。
4 实验
4.1 实验设置
4.1.1 实验数据集和指标
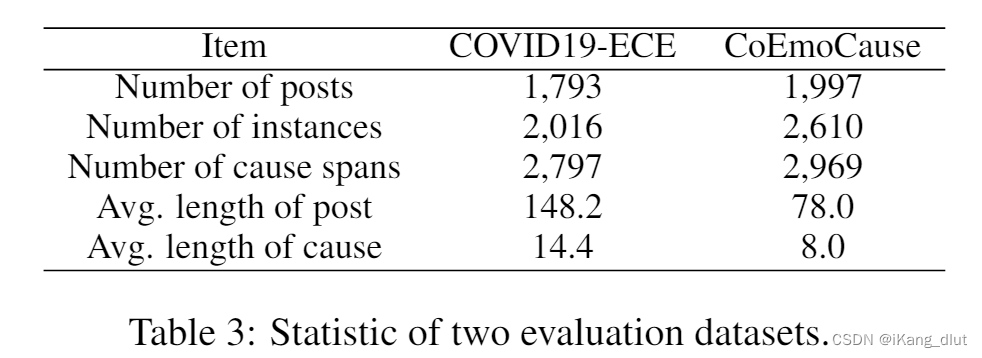
本文在COVID19-ECE和CoEmoCause两个数据集上进行实验,表3是对两个标注数据集的介绍:
COVID19-ECE是用户爬取的大规模语料库,由人工进行标注。
CoEmoCause是一个中文细粒度的情绪原因配对抽取数据集,最初来自SMP2020微博情感分类竞赛。
从表3中可以看出,CoEmoCause总的条目数较多,但是单句长度较短。
4.1.2 伪监督训练数据集
因为COVID19-ECE和CoEmoCause都与新冠病毒有关,所以作者使用前面提到的基于成分分析树和规则的方法,获取大量以COVID-19为主题的基于规则进行标注的数据集,获取方法如下:
- 我们从2020年2月到2020 年 6 月的 COVID-19 流行主题下从新浪微博收集数据作为原始语料库。我们使用 Lee 等人(2010b)提出的因果线索词词典和 Gui 等人(2016a)提出的情感词词典进行关键词匹配,,但是对这两个词典进行了细微修改。我们使用 Berkeley Neural Parser (Kitaev and Klein, 2018) 对预处理语料库中的自动注释执行 CBR。我们最终获得了一个包含大约 400K 个帖子的规则注释数据集。
- 我们随机抽样 51,200 个实例来形成我们的训练集,表示为 Dr。规则注释训练集的统计数据如表4所示。我们将训练集划分为几个训练数据大小不断增加的训练子集,分别由400、1600、3200、6400、12800、25600、38400和51200个实例组成。我们根据不同的实验设置选择训练子集进行模型训练。
4.1.3 实现细节
我们使用 Huggingface Transformers 的 PyTorch 版本实现了我们的模型(Wolf 等人,2020)。我们对 BERT/RoBERTa 使用 1e-5 的学习率为 1e-5,CRF 层使用 1e-2。我们对[16,32,64,128,256]中的批大小进行网格搜索,并将其设置为16。热身应用于最初的10%步骤。变压器层之间的dropout率设置为0.1。AdamW作为优化器。在完全监督的设置中,我们使用验证集来保留检查点以进行最终测试。在无监督设置中,我们训练模型,直到它收敛并使用最后 10 步的测试集的平均评估结果作为最终结果。所有结果都平均超过 4 次随机复制实验。
4.2 方法比较
作者将本文提到的CBR+RGPS方法与其他方法在两种设置下进行比较,比较的依据是是否使用了少量的人工标注。
- 首先是没有使用人工标注的,有三种:
- 李和徐等人2014年提出了一种词级三元组的基于规则的方法。
- CBR:即本文提出的基于句法成分树的规则标注的方法。
- CBR+RGPS:本文提出的方法,包括了CBR和一轮label refinement。
- 使用了额外的200个人工标注实例作为补充:
- BERT-base+CRF,在200个人工标注上进行有监督训练。
- 自训练,使用一种模型,先在200个人工标注上进行有监督训练,再在25600个无标签实例上进行自学习。
- CBR+BERT-CRF+FT:先使用BERT+CRF在25600个基于CBR进行规则标注的示例上进行训练,然后在200个人类标注上进行微调。
- CBR+RGPS+FT:将本文提出的方法,在200个人类标注上进行微调。
- 使用全量人类标注,微调BERT-CRF,作为其他基线模型的表现上限。
4.3 主要结果
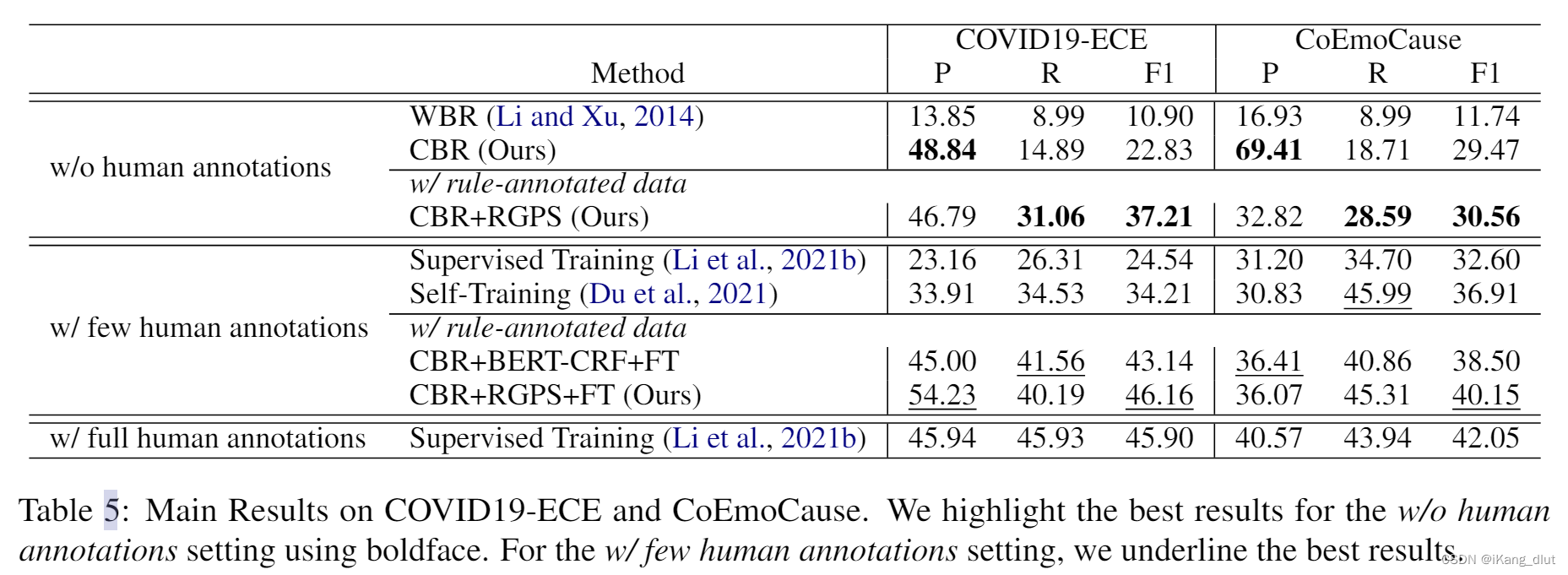
作者在Covid19-ECE 和 CoEmoCause 上比较了这些方法,结果如表5所示:
-
CBR与WBR的比较:
- 在不需要任何人工标注的情况下,提出的CBR(基于成分的规则)方法在所有指标上都优于WBR(基于词的规则)方法,并且获得了高精度分数。这对于社交媒体上的大规模实际应用非常有益。
- 认为成分解析提供了更准确的原因跨度候选,加上提出的因果句法模式,从而导致了更好的整体性能。
-
CBR+RGPS的表现:
- 在25,600个规则标注实例的基础上,CBR+RGPS(基于成分的规则加上规则引导的预测策略)显示出相比于基于规则的方法在召回率和F1分数上的显著提高。
- 这表明RGPS可以改善基于规则方法存在的低覆盖率问题。然而,在CoEmoCause数据集上观察到精度的明显下降,这可能归因于数据集分布的差异。
-
CBR+RGPS+FT的改进:
- 通过纳入额外200个人工标注实例,提出的CBR+RGPS+FT模型(基于成分的规则加上规则引导的预测策略,再进行微调)在CBR+RGPS基线上展现了进一步的改进。
- 它达到了与需要1,300个人工标注实例的完全监督基线相当甚至更好的结果。CBR+RGPS+FT还在F1分数上超过了半监督和CBR+BERT-CRF+FT。
-
结论:
- 这些发现表明,规则标注的数据可以为模型提供有价值的知识,提出的RGPS模块可以帮助有效地利用这些规则标注的数据。
4.4 RGPS的消融实验
 RGPS由LR即label refinement和rule masking两部分构成
RGPS由LR即label refinement和rule masking两部分构成
- 规则掩码(Rule Masking, RM):这部分对RGPS至关重要,为进一步的改进提供了坚实的基础。通过使用规则掩码,模型能够理解情感和原因之间的深层联系,从而提高性能。实验发现,当线索词被掩码的比例在60%-80%时,RGPS能够取得最佳结果。
- 标签细化(Label Refinement, LR):这部分有助于提高模型的泛化性能和召回率,但以牺牲一定精度为代价。
4.5 规则标注数据的大小
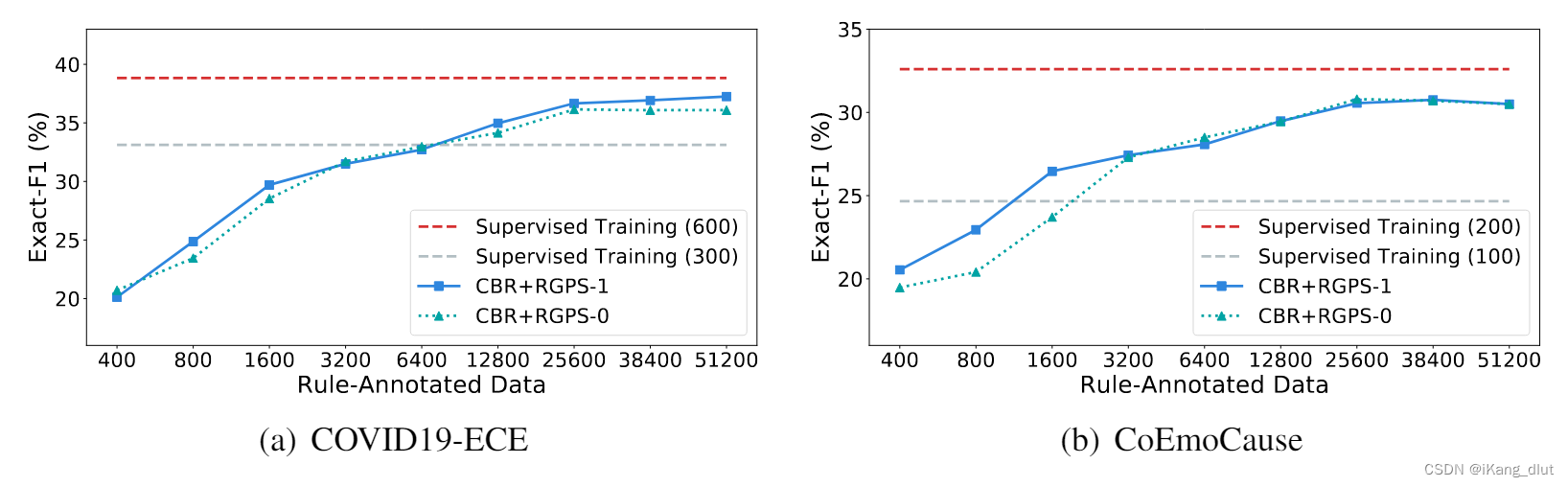
- 研究了不同规模规则标注数据对性能的影响。实验显示,在规则标注实例数量低于10K时,模型性能有显著增长。当数据量达到约25K时,增长速度放缓并趋于稳定。
- 在COVID19-ECE数据集上,将训练数据扩展到约50K实例时,CBR+RGPS方法的性能接近使用600个人工标注实例训练的模型。经过一轮标签细化的模型(CBR+RGPS-1)表现优于未进行细化的模型(CBR+RGPS-0),证明了方法的有效性。
4.6 人类标注数据的讨论

- 在两个数据集(COVID19-ECE和CoEmoCause)上探讨了不同模型对不同规模人工标注数据的依赖性。实验结果显示,CBR(25600)+RGPS+FT方法在仅使用100个人工标注实例进行微调时,在COVID19-ECE数据集上就能达到47.5%的F1分数,而其他模型需要至少600个数据实例来达到类似的结果。
- 在CoEmoCause数据集上,CBR(25600)+RGPS+FT也表现优于其他方法,表明该方法能够更好地减轻模型对人工标注数据的依赖。
4.7 规则之外的泛化性
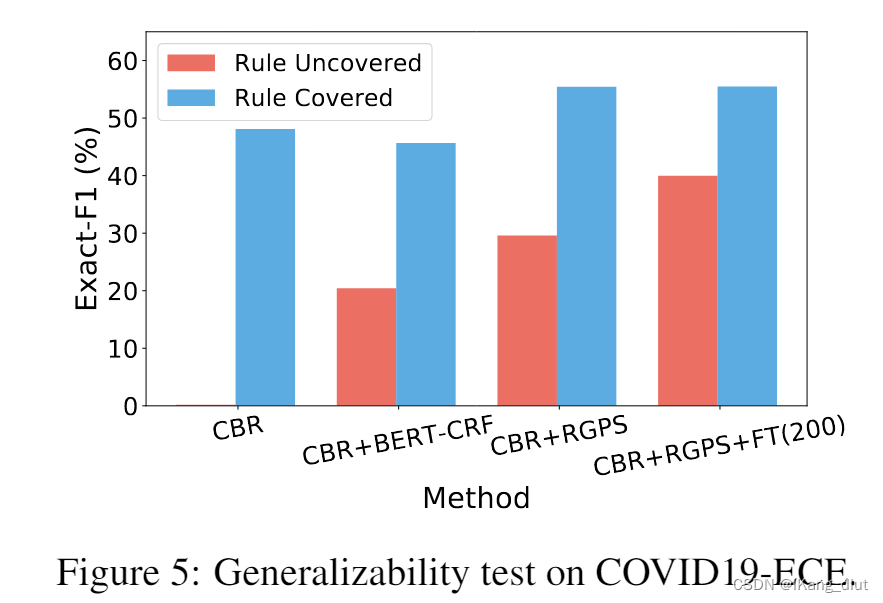
- 进一步调查了模型在规则覆盖范围内外的测试集上的泛化能力。所有模型均在25,600个规则标注实例上训练。
- CBR+RGPS在规则覆盖范围外的数据实例上明显优于CBR和CBR+BERT-CRF,表明所提出的伪监督框架有助于模型泛化到规则覆盖范围之外的数据。
- 纳入少量人工标注数据后,CBR+RGPS+FT(25600)在规则覆盖范围外的数据上取得了进一步改进,但在规则覆盖范围内的数据上的性能提升有限。















 2191
2191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









