






横断面网络分析
由节点Node和边线edge组成
节点
- 中心性:用来评估节点在网络结构中的核心程度。(改变中心性高的节点会影响许多其他节点。)
- 中心性指标:
- 强度strength:与其他节点直接相连的加权值(绝对值)的总和。
- 紧密度/接近度closeness:一个节点与其他节点之间的平均最短路径长度的倒数。(中心节点平均距离短)。
- 中介度betweenness:某节点在其他任意两节点最短路径上的频率,用于测量某节点在其他节点联系中的重要性。越多紧密度越高。
- 预期影响expected influence:与其他节点直接相连的加权值(有正有负)的总和。

边线
- 节点之间存在的关系。
- 边线特征:
- 权重weight:网络中边线所连接节点之间关系的密切程度。边线越粗,关系越紧密。
- 符号sign:节点之间关系的性质。(边线的颜色,绿or蓝表示正向关系,红色表示负向关系)
- 指向性direction:边线是否具有因果关系的指标。指向节点为原因,被指向节点为结果。
网络类型
相关矩阵网络
- 最基本的一种网络结构;
- 例如皮尔逊相关etc,一种不具有指向性的加权矩阵网络结构;
- 存在较多的虚假关系。
偏相关网络(Partial Correlation Network)
- 最常用,又称配对马尔可夫随机场PMRF/浓缩图/高斯图论模型;
- 只保留节点之间的直接连接,减少了虚假相关;
- 无向网络模型;
- 可以根据不同数据类型使用不同的PMRF模型;
- 连续型变量:高斯图论模型GGM
- 又称为高斯随机场(Gaussian Random Field),浓缩图(Concentration Graph)以及偏相关网络(Partial Correlation Network)。
- 二分类变量:伊辛模型Ising model
- 使用逻辑回归(logistic regression)计算节点之间的联系强弱,实际上是预测模型的结合。(模型中边线所代表的是某个节点能够预测其他节点的程度)。
- 两种都有:混合图形模型mixed model
- 连续型变量:高斯图论模型GGM
正则化偏相关网络(Regularized Partial Correlation Network)
- 适用于处理变量数量多于样本量的情况,这种情形在高维数据分析中常见。
- 正则化:通过引入一个惩罚项(如L1范数或L2范数)来限制模型复杂度,从而增强模型的泛化能力和稳定性。
GLASSO网络(Graphical Least Absolute Shrinkage and Selection Operator)
- GLASSO网络结构属于正则化偏相关网络的一种。是一种用于估计概率图模型中变量之间关系的方法,特别是在变量数量多于样本数量的情况下。通过使用Lasso(最小绝对收缩和选择算子) 技术来进行正则化,从而推断变量间的偏相关网络。
- 核心思想:
- 是构建一个稀疏的逆协方差矩阵(也称为精度矩阵),这个矩阵可以表示变量之间的直接关系,而非间接相关;
- 通过在协方差矩阵的逆上引入L1惩罚项(Lasso算法),促使非重要的连接(即精度矩阵中的元素)趋于零,从而实现网络的稀疏化;
- 设置调谐(调优)参数/惩罚系数λ来控制减少虚假变量的程度:需要适当把握λ的大小(值偏低时,剔除的连接较少,仍存在较多虚假连接;值偏高时,剔除的连接较多,真实连接可能被一起剔除);
- 应用范围:单一网络估计或比较一组网络估计;
基于EBIC的LASSO算法
- 是一种目前研究发现比较具有特异性的算法,能够将虚假连接和真实连接区分,而且不对虚假连接进行估计。
- 扩展贝叶斯信息准则 Extended Bayesian Information Criterion(EBIC):
- 用于选择最佳的模型,通过考虑模型的复杂度和拟合优度来优化模型选择。
- 将EBIC最小化能够较好地发现真实连接的网络模型,特别是本身不存在太多真实连接的网络。
- 但这种算法的敏感性较多变,和真实网络结构和样本量有关。例如,当真实网络存在很多连接或者特定某些节点存在很多连接,敏感性会减弱。
- 使用的γ一般设置为0.5。
一般分析步骤
1. 构建EBIC GLASSO网络
- 控制网络中包含的所有其他变量后,通过偏相分析计算出每个成对连续变量的关联;
- 每个变量定义为一个节点,变量之间的边为它们的关联;边的粗细和颜色代表不同的相关性。
2. 计算中心性指标(Centrality Indices)
- 一般计算三个中心性指标:强度(Strength Centrality)、接近度(Closeness Centrality)和中介性(Betweenness Centrality)。
- 有时还有:
- 度中心性:一个节点的度中心性是指该节点连接的边数。在有向网络中,可以进一步区分为入度中心性(入边数)和出度中心性(出边数)。
- 特征向量中心性:一个节点的所有邻居的特征向量中心性的加权总和。
- Katz中心性:Katz中心性是度中心性的一种推广,不仅计算直接连接的节点,还包括通过所有长度的路径达到的所有节点。
- 预期影响(EI)中心性:用于度量节点在考虑边权重和网络的拓扑结构的情况下的影响力。具体来说,它考虑了节点的度和其邻居的度,通过一个数学公式(通常是度与权重的乘积)来计算。
3. 估计可预测性(Predictability)
- 通常通过从回归模型中获得决定系数R²来量化可预测性。R²值越高,表示该症状的变化在网络中其他症状的帮助下可以得到更好的预测。
- 可预测性不受样本容量大小影响;
- 社区样本可预测性 > 临床样本;
- 存在诸多局限:
- 现有研究还不能解决网络中特定单个节点对单个节点的影响程度,网络里可以量化一个节点被其他相邻节点所决定的程度;
- 横断数据估计的网络是无方向网络,一个节点的可预测性是通过计算连接到它的所有边线的权重而不考虑边线的方向,因此节点的可预测性往往高估;
- 如果存在两个或以上的变量评估的是同一问题,例如对悲观情绪采用不同的问题测量,那么症状网络中两个节点的可预测性就会增加,两个节点之间边线权重也会被高估。这时如果将这两个节点解释为相互决定的关系,就会导致错误的解读结果。
4. 评估网络的稳定性和准确性
-
Bootstrapped差异检验(bootstrapped difference test):用于估计两个样本之间差异的置信区间或进行假设检验。它主要应用于样本量小或数据不符合常规统计检验的正态分布假设时。一般步骤如下:
- 数据重采样:从两个原始样本中分别进行有放回抽样,多次抽取与原样本大小相同的新样本。这一过程被称为“重采样”。
- 计算差异:对于每一对重采样得到的样本,计算其统计量(如平均值、中位数)的差异。
- 构建差异分布:重复上述过程多次(通常上千至上万次),从而获得大量的统计量差异值。这些差异值形成了一个经验分布,反映了样本统计量差异的可能变化。
- 置信区间与假设检验:
- 置信区间:根据上述得到的差异分布,可以计算出任何置信水平下的置信区间(如95%置信区间)。如果置信区间不包含0,则认为两样本间有显著差异。
- 假设检验:设定原假设为两个样本统计量之间无差异(即差异为0)。通过比较实际观察到的样本差异与重采样差异分布的关系,可以计算出一个p值,从而进行假设检验。
-
在网络分析中使用bootstrapped差异检验的一般步骤:
- 采用non-parametric bootstrapping计算 *置信区间CI (confidence interval) * 来估计边的准确性:
- 基于95%CI的新数据集是通过对数据中的观察值随机重新抽样而创建的(例如袋子有100个球,每次抽60个球抽1000次,就有1000个新数据集)
- 为了评估网络的稳定性,执行case-dropping bootstrap procedure来计算 相关稳定性系数CS-C (correlation stability coefficient) :
- 节点在中心度指标上的稳定性:主要检验随着网络结构中样本量或节点数量的减少,中心都指标的序列是否能够保持不变的程度。(一般重点分析随着样本量减少而出现变化的情况)
- 每个新数据集的大小不同,有100个球,每个数据集分别抽100个、90、80、……个球,稳定性会慢慢减少。
- CS-C值表明,原始中心性指数与基于样本子集网络的中心性指数之间的相关性以95%的概率保持在0.7以上时,可以去除的最大样本比例。
- CS-C应该>0.25,最好>0.5。
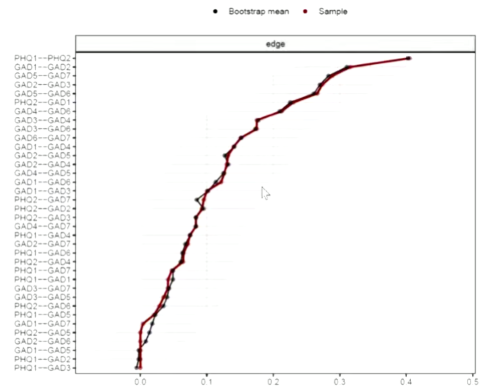
- 采用non-parametric bootstrapping计算 *置信区间CI (confidence interval) * 来估计边的准确性:
- 网络属性的差异评估(边线,节点):
- bootstrapped difference tests
- 例:黑色格子代表显著,灰色代表不显著
- 边线

- 节点
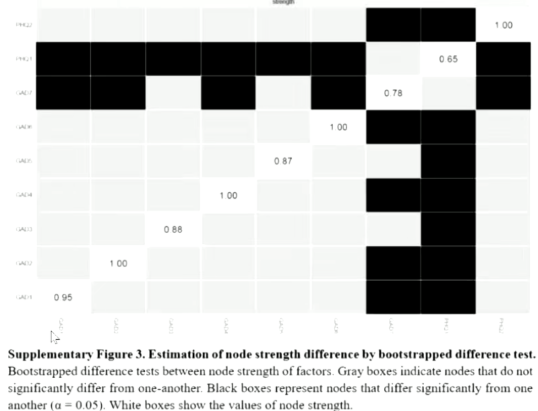
- 边线
相对重要性分析(Relative Importance Analysis,RIA)
- 一种用于评估在多变量预测模型中,各个预测变量对于预测结果的贡献程度的统计方法。
- 在多变量回归模型中,预测变量往往存在一定程度的共线性,即变量之间相互关联。这种关联使得单个变量对预测结果的影响难以直接从回归系数中解读。相对重要性分析很好的解决了这个难题。
- 常用方法:
- Lindeman, Merenda, and Gold (LMG) 方法:这种方法通过计算每个预测变量在所有可能的变量子集中的平均贡献来估计相对重要性。它考虑了变量进入模型的所有可能顺序,确保了评估的公平性。
- Shapley 值回归:源自博弈论的Shapley值,用于公平地分配合作游戏中的“支付”。在相对重要性分析中,Shapley值被用来量化每个变量在预测模型中的贡献,考虑到所有可能的变量组合和顺序。
- 条件和边缘贡献:这些方法通过考虑变量单独及其与其他变量交互时的贡献,来评估其在模型中的重要性。
- 一般步骤包括:
- 模型构建:首先建立一个包含所有感兴趣的预测变量的多变量回归模型。
- 计算贡献:使用上述方法之一(如LMG或Shapley值)来计算每个变量的贡献。
- 结果解释:分析各个变量的贡献度,识别出对模型预测能力影响最大的变量。
网络比较
-
只适用于二分数据和连续数据,不适用于混合模型,应用于比较多个样本或单一样本不同特征;
-
网络比较测试(Network Comparison Test, NCT):一种用于比较两个或多个网络结构差异的统计方法,特别在心理学和神经科学等领域中,用于分析不同群体(如不同病理状态、不同治疗反应等)的心理网络或脑网络的差异。这种方法可以用来判断两个网络在全局或局部连接模式上是否存在显著差异。
- 基于对网络中的各个节点以及节点间连接的统计特性进行分析。通常关注以下几个方面:
- 节点强度差异:节点强度指的是一个节点与其他节点的连接强度之和,NCT可以检验两个网络中对应节点的强度是否存在显著差异。
- 边权重差异:检验两个网络中相应的边(节点间的连接)权重是否有显著差异。
- 全局网络特性:比如网络的密度(网络中实际连接数与可能连接数的比例)、聚类系数(节点的邻居间连接的密集程度)等,NCT能分析这些全局特征在不同网络中的差异。
- 一般步骤测试步骤:数据准备、网络构建、差异计算、统计推断、结果解释。
- 基于对网络中的各个节点以及节点间连接的统计特性进行分析。通常关注以下几个方面:
-
置换检验测试(permutation tests):一种非参数统计方法,用来检验两个或多个样本组之间的差异是否具有统计学意义。核心思想是通过重新分配(置换)数据标签来模拟在零假设(即两个样本组没有差异的情况)下可能观察到的数据分布。
- 全局差异
- 网络结构的不变性:假设网络结构为一个整体,而且这一结构在不同子样本中保持不变。
- 全局强度的不变性: 假设网络中所有边的强度之和(即网络密度)在不同子样本中保持一致。
- 局部差异
- 边线连接强度的不变性:检验网络结构中的某一特定边线强度在子样本中是否出现差异。
- 全局差异
跨诊断流网络
- 一个用来理解和研究各种心理健康问题的通用框架。
- 横断面网络属于静态网络,流网络属于动态网络。
网络特点
- 跨诊断性(Transdiagnostic):这种网络不是针对单一的精神疾病诊断进行研究,而是探索不同精神疾病之间共享的心理和生理机制。这种方法可以揭示导致多种疾病的共同因素,比如情绪调节障碍可能同时出现在抑郁症、焦虑症及其他情感障碍中。
- 动态性(Dynamic):流网络强调的是症状和机制在时间上的变化和流动,不仅仅局限于静态的状态。这意味着网络能够反映个体状况的变化,如症状的发展、恶化或缓解过程,以及治疗反应的动态变化。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









