






 斯坦福团队利用大语言模型开发的GenerativeAgents在模拟环境中展示了可信的人类行为。文章探讨了不同方法在人类行为模拟中的应用,以及LLM在生成行为、规划和交互中的作用。通过实验评估了Agents的交互能力和社会行为,揭示了潜在的局限性和未来研究方向。
斯坦福团队利用大语言模型开发的GenerativeAgents在模拟环境中展示了可信的人类行为。文章探讨了不同方法在人类行为模拟中的应用,以及LLM在生成行为、规划和交互中的作用。通过实验评估了Agents的交互能力和社会行为,揭示了潜在的局限性和未来研究方向。
文章摘要
Generative Agents是斯坦福相关团队借助大语言模型(LLM)创建的”代理“(或称为”智能体“),通过搭建沙盒环境对25个Agents的行为进行模拟仿真,实验表明其能够产生可信的人类行为。Agents从一段描述开始,生成行动计划,与其他Agents、环境或人类产生交互,Agents产生记忆与形成联系,最终进行协调联动。
一、相关工作
1. 人类与AI交互
(1) 与Agents产生交互;
(2) 通过向系统中输入信息,观察系统发展动态。
2. 人类行为的可信代理:对事件和社会交互的模拟
(1) Rule-based approaches:(有限状态机、行为树)人工制作的交互,难以符合开放世界的广度;
(2) Learning-based approaches:(强化学习)适用于对抗性环境;
(3) Cognitive architecture:长、短期记忆,感知-计划-行动循环中运行,与手工制作的行动程序进行匹配,适用于非开放世界。
3. LLM和人类行为
(1) LLM用于生成行为和角色的描述、生成用户参与的交互式人类行为、生成和分解动作序列,规划机器人任务;
(2) 之前采用First-order template,最近采用静态知识库和信息检索方案;
(3) 本文采用Agent架构进行检索,动态更新experience,结合Agent当前状态和计划产生行动。
二、Agent的实现和交互
1. Initial memory
自然语言进行描述,作为模拟开始时的memory;
2. Agents产生的交互
每个time step内,
(1) Agents通过自然语言描述当前行为(action);
(2) 自然语言→真实的行动(movement)+对环境产生影响;
(3) 通过LLM将action转换为emojis进行显示。
(4) Agent结构决定其是否与其他Agents产生对话。
3. User交互
(1) User指定身份(已经存在的Agent或之前不存在的Agent)与Agent进行交互;
(2) 直接对Agent产生命令;
(3) User可以直接对环境进行修改。
4. Agents移动
(1) Agent架构和游戏引擎控制;
(2) 模型指定目的地;
(3) 计算移动路径;
(4) 进行移动。
三、Agent运行过程
1. 从一段描述开始;
2. 产生计划;
3. 与其他Agents或环境产生交互
4. 产生记忆与形成联系;
5. 进行协调联动。
四、社会行为
1. 信息扩散:通过Agent和Agent之间的交流传递信息。
2. 关系记忆:Agents之间形成新的关系,并且记住和其他Agents之间的互动。
3. 协调联动:多个Agents之间在相关事件上产生联动。
五、Agent架构
1. 综合和检索信息机制+LLM
能够与其他Agent进行交互、对环境变化产生反应,输入为当前环境和过去经验,输出生成行为;
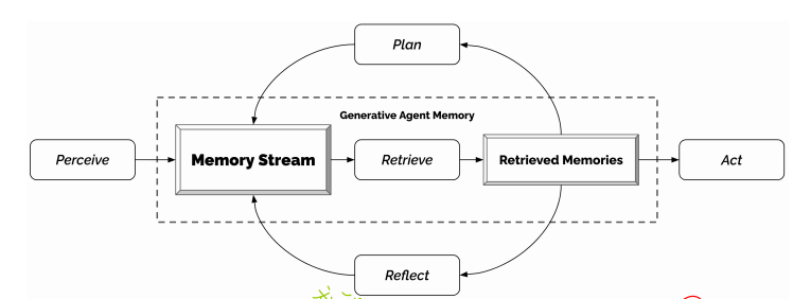
2. Memory and Retrieval
① 挑战
在交互过程中要根据记忆产生更加详实、相关、具有信息量的反应,而非简单的总结。
② 方式
1) Memory stream
保存Agent全面的经验记录(自然语言描述+产生时间+最近访问时间):包括Agent自己产生的行为、其他Agents产生的行为、非Agents物体产生的行为。
2) Retrieval function
输入当前情况,输出memory stream中的一个子集至语言模型。检索的依据由三部分组成:
a. 临近程度(recency):分数随时间呈指数衰减;
b. 重要程度(importance):直接要求语言模型输出一个整数分数;
c. 相关程度(relevance):使用语言模型对每个memory生成一个嵌入向量,计算查询memory嵌入向量和其他memory嵌入向量的余弦相似度。
3. Reflection
① 挑战
只有观察记忆时,难以产生推断。需要产生更水平的反映(reflection)。
② 方式
1) 第二种memory(reflection)
a. 将Agent产生的更高水平、更抽象的思想作为一种memory,与之前memory一同检索。
b. 当最新事件的importance得分总和超过一定阈值时,产生reflection。
c. 实现过程:
a) 将最近的多条记录(100条)输入LLM,询问LLM使之产生几个最突出的高级问题;
b) 将这些问题作为检索的queries,获得相关的memory;
c) 将这些memory输入LLM,提示LLM提取几个重要的见解,进行记录。
4. Planning and Reacting
① 挑战
在更长时间内进行规划,保证行为序列的连贯性和可信性。
② 方式
1) Planning
描述Agent未来行为列表,使Agent的行为随时间保持一致。
a. 内容:位置、开始时间、持续时间;
b. 存储在memory stream中,包含在检索过程中,使Agent决定如何行动时保持观察、反射(reflect)和计划,在需要时中途改变计划;
c. 实现过程:
a) 制定初始计划,大致概述当天议程。使用Agent的总体描述和前一天的总结来提示语言模型;
b) 将初始计划保存在memory stream中,然后递归地分解为更细粒度的行动(一小时、十五分钟)至所需。
2) Reacting and updating plans
a. 实现过程:
a) 根据行为执行过程中的context和产生的memory生成Agent的描述,提示语言模型,决定Agent是否应该继续现有的计划还是做出反应;
b) 然后在反应发生时重新生成代理的现有计划;
c) 如果动作表明要生成Agents之间的交互,那么生成对话。
3) Dialogue
a. 通过调用Agent_1的记忆中关于对方的信息提示LLM,产生他们的对话;
b. Agent_2将Agent_1发起的对话作为想要做出反应的事件;
c. Agent_2调用有关的记忆以及此次对话中有关的记忆提示LLM,做出回应;
d. 直至一方结束对话。
六、环境实现:
1. 沙盒环境:
使用Phaser网络游戏开发框架;
2. 补充服务器:
(1) 作用
使Agent可以使用沙箱信息,并使Agent能够移动和影响沙箱环境;
(2) 实现
维护一个JSON数据结构
① 内容:每个Agent的代理信息(当前位置+当前操作的描述+与它们交互的沙箱对象);
② 在每个time step中,
1) 解析来自Agent的任何改变;
2) 将Agent移动到新位置;
3) 更新Agent交互对象的状态;
4) 将每个Agent的预设视觉范围内的所有Agents和对象发送到该Agent的memory中;
5) Agent的动作将更新JSON。
3. 树状结构:
(1) 将区域和对象表示为树状数据结构,边表示包含关系;
(2) 将树转为自然语言传递给生成代理;
(3) Agent在构建单独的环境子树,在行动时进行更新;
(4) 每个操作具体的位置:需遍历Agent的环境树,将其中一部分转换为自然语言,提示语言模型给出合适区域,从树根开始进行递归,直至叶子结点;
(5) 当代理对对象执行操作时,提示语言模型询问对象状态发生了什么变化。
七、评估方式:
1. Controlled evaluation:
(1) 内容
通过采访(interview)测试Agent行为的可信度,包括5个问题类别:
① Self-knowledge:保持自我认知
② Memory:记忆准确性
③ Plans:长期规划
④ Reaction:对事件的可信行为
⑤ Reflection:对问题的深入理解
(2) 方式
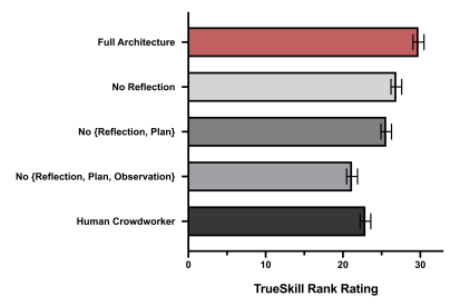
① 100名参与者比较四种不同的Agent架构和同一Agent的人类访谈回答,将可信度进行排序。
② 四个消融实验+人类基准
(3) 分析方法
① TrueSkill rating
② Kruskal-Wallis test
③ Dunn post-hoc test
④ HolmBonferroni method
⑤ 两阶段的qualitative open coding
(4) 结果
(5) 存在的问题
① 可能无法从内存中检索出正确的实例;
② 检索出不完整的记忆碎片;
③ 产生幻觉;
④ 由于语言模型中编码的真实世界知识来修饰Agents的认知。
2. End-to-end evaluation
(1) 消息扩散:通过与Agents对话确定其是否了解模拟开始时对某些Agents设定的信息,在memory stream中定位提供信息的对话来验证没有产生幻觉。模拟结束时计算了解信息Agents所占百分比。
(2) 关系信息:通过对话确定Agents之间是否存在关系,检查memory stream确定没有产生幻觉,形成无向图。对比模拟开始到模拟结束后网络密度的增加。
(3) 协调联动:记录参与事件的Agents数量。
八、局限性
1. 记忆集越来越大,在检索信息片段方面构成了挑战,选择适当的位置可能不那么典型,行为可能不那么可信;
2. 有些难以用自然语言传达的物理规范导致一些错误行为被认为是正确行为;
3. 指令调优可能产生影响,似乎引导Agent的行为总体上更礼貌和合作;
九、未来工作
1. 检索模块:微调组成检索函数的三部分来检索给定上下文的更多相关信息;
2. 体系结构:改进体系结构,使其更具成本效益,探索并行化Agents或开发专门构建Agents的语言模型;
3. 评估:着眼于长期观察生成代理的行为,以更全面地了解它们的能力,为更有效的性能测试建立严格的基准;
4. 改变和对比基础模型,以及在未来的模拟中用于代理的超参数,可以为这些因素对代理行为的影响提供有价值的见解;
5. 检验Generative Agents的鲁棒性;
6. 改进LLM。
(以上内容为本人阅读文献所做记录,如有错误,欢迎指出;欢迎相关研究人员一起讨论、多多指教)
文献阅读记录:
AI小镇体验:


















 4914
4914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











