






softmax的定义和代码
softmax可用于求解多分类问题的概率大小,通过对比最大概率的位置argmax来得到类别
softmax的特点:相加等于1,其交叉熵损失函数的导数为softmax输出值与真实值之间的差距
def softmax_(input):#@save
input_exp=torch.exp(input)
return input_exp/torch.sum(input_exp,dim=1,keepdim=True)
常见损失函数
交叉熵
针对分类问题,交叉熵越大,说明不确定性越高,信息量越大。
根据公式,对于二分类问题(01),只需要考虑1的概率y_hat即可,对1的y_hat对数相加,得到其交叉熵。
对交叉熵进行修改,将其变为所有目标类概率的对数综合,即认为所有的yj都是1.
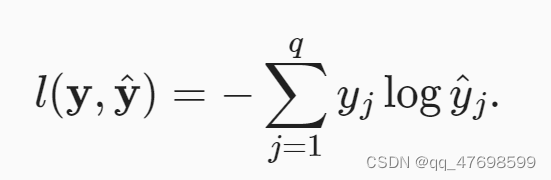
def cross_entropy(y_true,y_hat):
return -torch.log(y_hat[range(y_hat.shape[0]),y_true])#修改后的交叉熵
内置函数,使用内置交叉熵函数需要将softmax对输出的处理作用去除,因为该函数没有将softmax概率传递到损失函数中, 而是在交叉熵损失函数中传递未规范化的预测,并同时计算softmax及其对数
loss=torch.nn.CrossEntropyLoss(reduction='none')#保留每一个step的损失
内置的计算
lossNum=loss(y_pred,y)
分类问题的精度求解,即正确分类数/总样本数
def accuracy(y_true,y_hat):
y_label=torch.argmax(y_hat,dim=1)
y_diff= y_label.type(y_true.dtype)==y_true
return float(y_diff.type(y_true.dtype).sum())#输出的是正确分类的样本数,需要除以y.numel()才能得到精度
Lp范数损失函数
L1范数在损失函数的所有位置都有一样的导数值,但是在0点处存在拐点,不可导
L2范数在损失函数的中心0处拥有最小导数值,且越靠近0越小,会导致误差越小收敛越慢
Huber‘s Robust Loss在中心处拥有L1的导数特性,在远中心区域有L2的特性

累加器设置
为了方便在训练过程中,对多个batch的训练误差和测试误差累积计算,引入累加器
#累加器是一个1维的
class Accumulator():#@save
def __init__(self,shape):
self.receptor=[0.0]*shape
def add(self,*args):
self.receptor=[a+float(b) for a,b in zip(self.receptor,args)]#对各个元素进行加法操作
def reset(self):
self.receptor=[0.0]*len(self.receptor)
def __getitem__(self, item):#实现索引
return self.receptor[item]
网络训练流程
该过程包括了对自定义模型和内置模型的训练
内置总体流程是:模型参数梯度清零–》预测–》损失值计算–》反向传播–》梯度更新
其中train和eval模式的区别是:将一些在train中需要修改的参数确定下来,发生改变或不能被改变,如在BN层中和Dropout层中的计算,测试模式和训练模式的功能不同
def train_epoch_ch3(epoch,model,train_iter,updater,loss):
metric=Accumulator(3)#累加器,第一个存储损失值,第二个存储正确分类数,第三个存储参与训练batches的样本数
for x,y in train_iter:
if isinstance(model,torch.nn.Module):
model.train()#确定维train模式
if isinstance(updater,torch.optim.Optimizer):#判断类别是否匹配
model.zero_grad()
y_pred=model(x)
lossNum=loss(y,y_pred)
lossNum.mean().backward()
updater.step()
else:
y_pred = model(x)
lossNum=loss(y,y_pred)
lossNum.sum().backward()
sgd([w,b],lr,x.shape[0])#内部自定义了梯度清零
with torch.no_grad():
metric.add(float(lossNum.sum()),accuracy(y,y_pred),y.numel())
print(f'loss_mean:{metric[0]/metric[2]},accuracy_mean:{metric[1]/metric[2]}')
return metric[0]/metric[2],metric[1]/metric[2]
测试集的训练流程
def estimate(model,test_iter):
if isinstance(model,torch.nn.Module):
model.eval()#将内置模型改为测试模式
metrics=Accumulator(2)
for x,y in test_iter:
with torch.no_grad():#加快计算速度
metrics.add(accuracy(y,model(x)),y.numel())#添加测试正确样本数和总样本数
return metrics[0]/metrics[1]
epoch的循环
def train_ch3(model,updater,loss,trainIter,testIter):
for epoch_num in range(epoch):
train_metrics=train_epoch_ch3(epoch,model,trainIter,updater,loss)
test_acc=estimate(model,testIter)#测试集的精度和损失计算
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss#如果没有达到条件,则输出train_loss(作为错误信息,也可以输出字符串如'error for calculation')
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
内置模型的建立
需要先将图片数据打平,再建立线性模型
model=torch.nn.Sequential(torch.nn.Flatten(),torch.nn.Linear(num_input,num_output))
模型参数的初始化
def initialize(model):
if type(model)==torch.nn.Linear:
torch.nn.init.normal_(model.weight,std=0.01)
model.apply(initialize)
loss=torch.nn.CrossEntropyLoss(reduction='none')
updater=torch.optim.SGD(model.parameters(),lr=lr)
train_ch3(model, updater, loss, trainIter, testIter)
总代码
import torch
from d2l import torch as d2l
import torchvision
from torch.utils import data
from torchvision import transforms
def softmax_(input):#@save
input_exp=torch.exp(input)
return input_exp/torch.sum(input_exp,dim=1,keepdim=True)
def sgd(params,lr,batchsize):#@save
with torch.no_grad():
for param in params:
param-=lr*param.grad/batchsize
param.grad.zero_()
class Accumulator():#@save
def __init__(self,shape):
self.receptor=[0.0]*shape
def add(self,*args):
self.receptor=[a+float(b) for a,b in zip(self.receptor,args)]
def reset(self):
self.receptor=[0.0]*len(self.receptor)
def __getitem__(self, item):
return self.receptor[item]
def LinearNet(x):
return softmax_(torch.matmul(x.reshape((-1,w.shape[0])),w)+b)
def cross_entropy(y_true,y_hat):
return -torch.log(y_hat[range(y_hat.shape[0]),y_true])
def accuracy(y_true,y_hat):
y_label=torch.argmax(y_hat,dim=1)
y_diff= y_label.type(y_true.dtype)==y_true
return float(y_diff.type(y_true.dtype).sum())
def train_epoch_ch3(epoch,model,train_iter,updater,loss):
metric=Accumulator(3)
for x,y in train_iter:
if isinstance(model,torch.nn.Module):
model.train()
if isinstance(updater,torch.optim.Optimizer):
model.zero_grad()
y_pred=model(x)
lossNum=loss(y_pred,y)
lossNum.mean().backward()
updater.step()
else:
y_pred = model(x)
lossNum=loss(y,y_pred)
lossNum.sum().backward()
sgd([w,b],lr,x.shape[0])
with torch.no_grad():
metric.add(float(lossNum.sum()),accuracy(y,y_pred),y.numel())
print(f'loss_mean:{metric[0]/metric[2]},accuracy_mean:{metric[1]/metric[2]}')
return metric[0]/metric[2],metric[1]/metric[2]
def estimate(model,test_iter):
if isinstance(model,torch.nn.Module):
model.eval()
metrics=Accumulator(2)
for x,y in test_iter:
with torch.no_grad():
metrics.add(accuracy(y,model(x)),y.numel())
return metrics[0]/metrics[1]
def train_ch3(model,updater,loss,trainIter,testIter):
for epoch_num in range(epoch):
train_metrics=train_epoch_ch3(epoch,model,trainIter,updater,loss)
test_acc=estimate(model,testIter)
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
num_input=3600
num_output=10
epoch=10
lr=0.01
w=torch.normal(0,0.01,[num_input,num_output],dtype=torch.float32,requires_grad=True)
b=torch.zeros(num_output,dtype=torch.float32,requires_grad=True)
if __name__=='__main__':
trans=[transforms.ToTensor()]
trans.insert(0,transforms.Resize(60))
trans=transforms.Compose(trans)
trainData = torchvision.datasets.FashionMNIST('../data', train=True, transform=trans, download=True)
testData = torchvision.datasets.FashionMNIST('../data', train=False, transform=trans, download=True)
trainIter = data.DataLoader(trainData, batch_size=20, shuffle=True, num_workers=4)
testIter=data.DataLoader(testData, batch_size=20, shuffle=True, num_workers=4)
train_ch3(LinearNet, sgd, cross_entropy, trainIter, testIter)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









