







目录
1.3 tf.cast、tf.convert_to_tensor(类型转换)
2.3.1 tf.random.normal(分布初始化采样)
4.4 增加、减少维度( Expend dim 和 Squeeze dim )
一、数据类型概念
1.1 相关类型
numpy 不支持 gpu
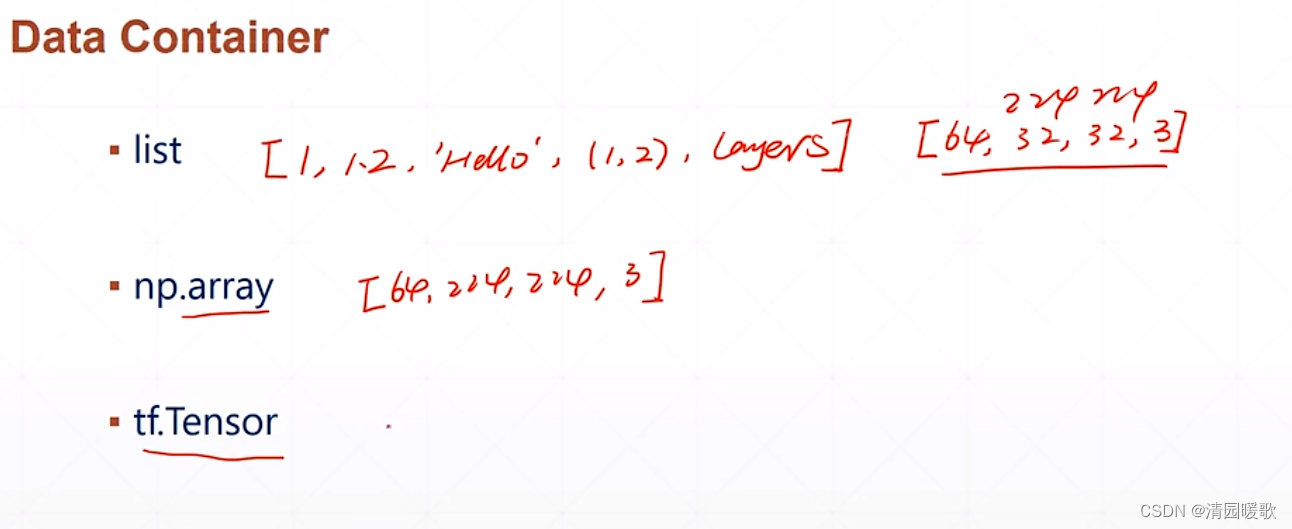
scalar:数学上讲一个零位的数据,如 1.1,2,3,就是一个准确的数据类型
实际上都可以叫做 tensor


1.2 tf.constant(数据创建和判断)
当创建一个 2.2,却指定 int 类型的话就会报错
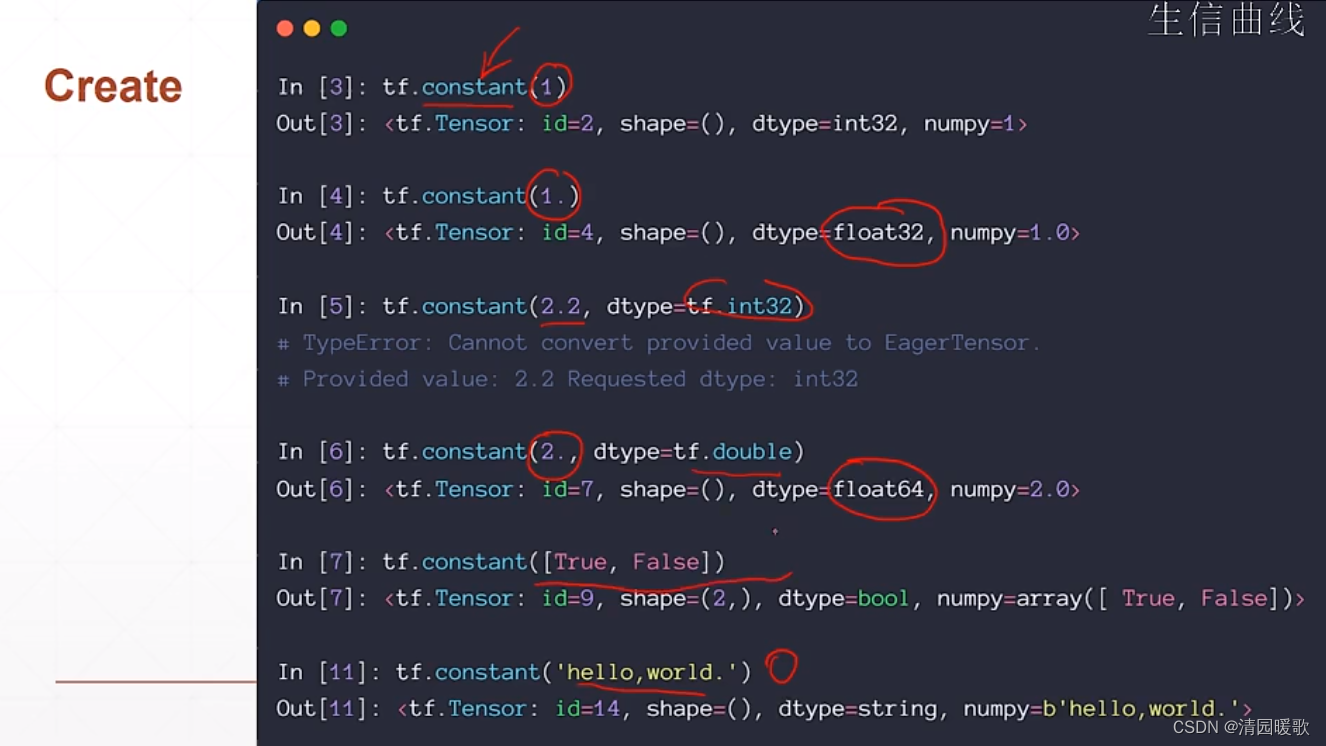
cpu 和 gpu 上tensor 的区别就是,对于cpu上的只能cpu操作,gpu的只能gpu操作
ndim 显示的是 维度
name 参数是没有什么意义的
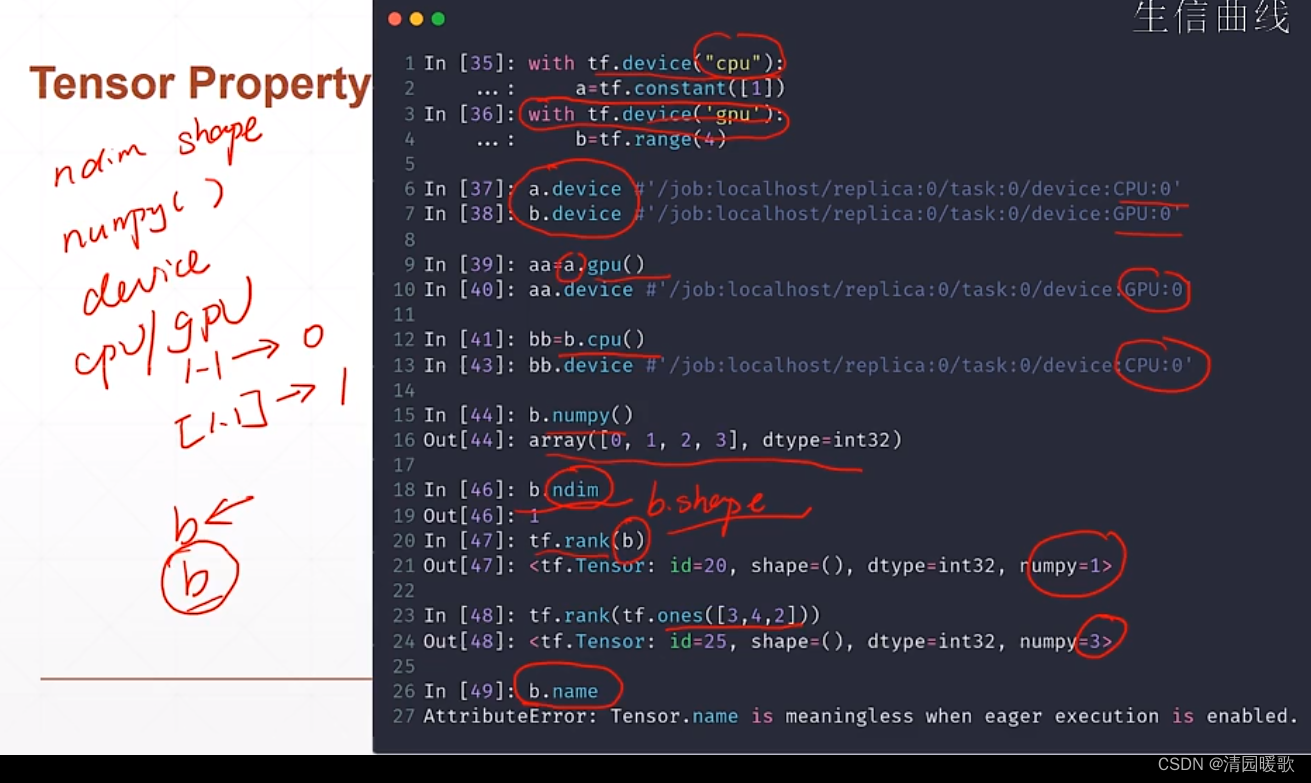
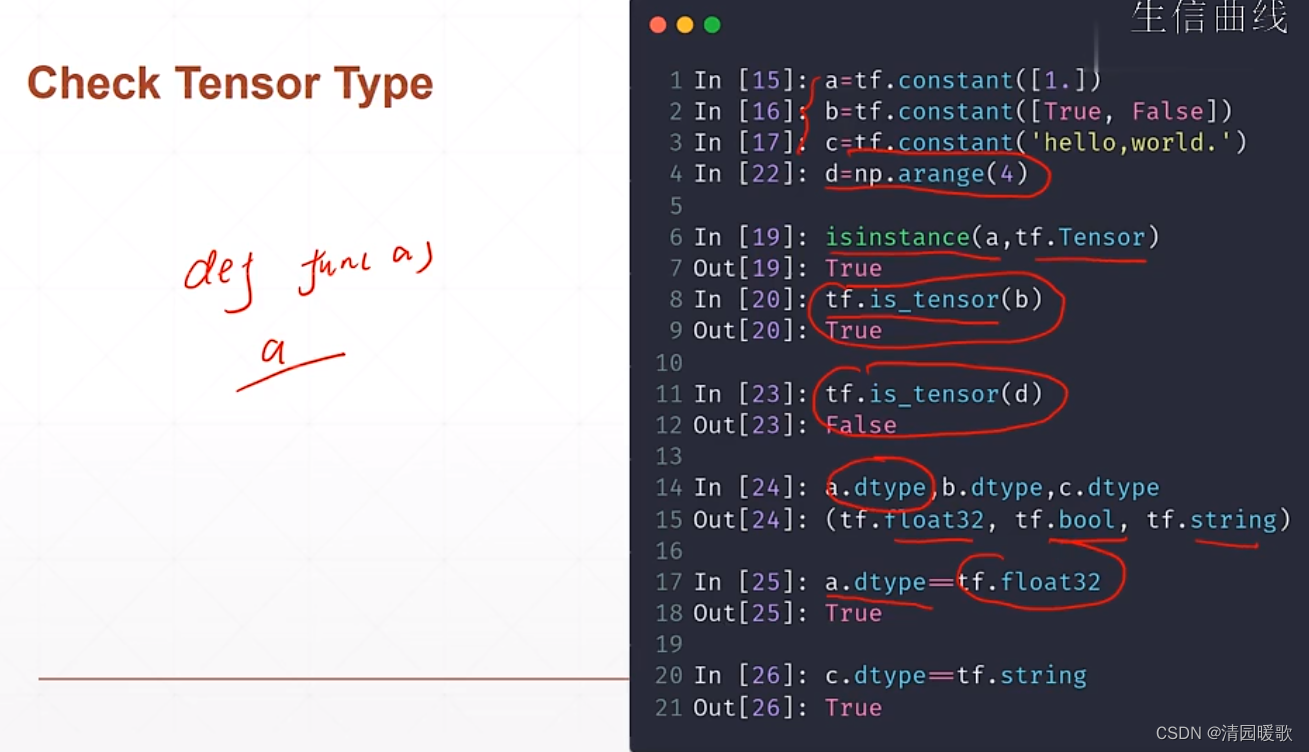
判断是不是tensor 用 isinstance 和 is_tensor
判断类型也可以如:a.dtype == tf.float32
1.3 tf.cast、tf.convert_to_tensor(类型转换)
numpy的类型 和 tensor 也可以转换
还有 cast 转换函数
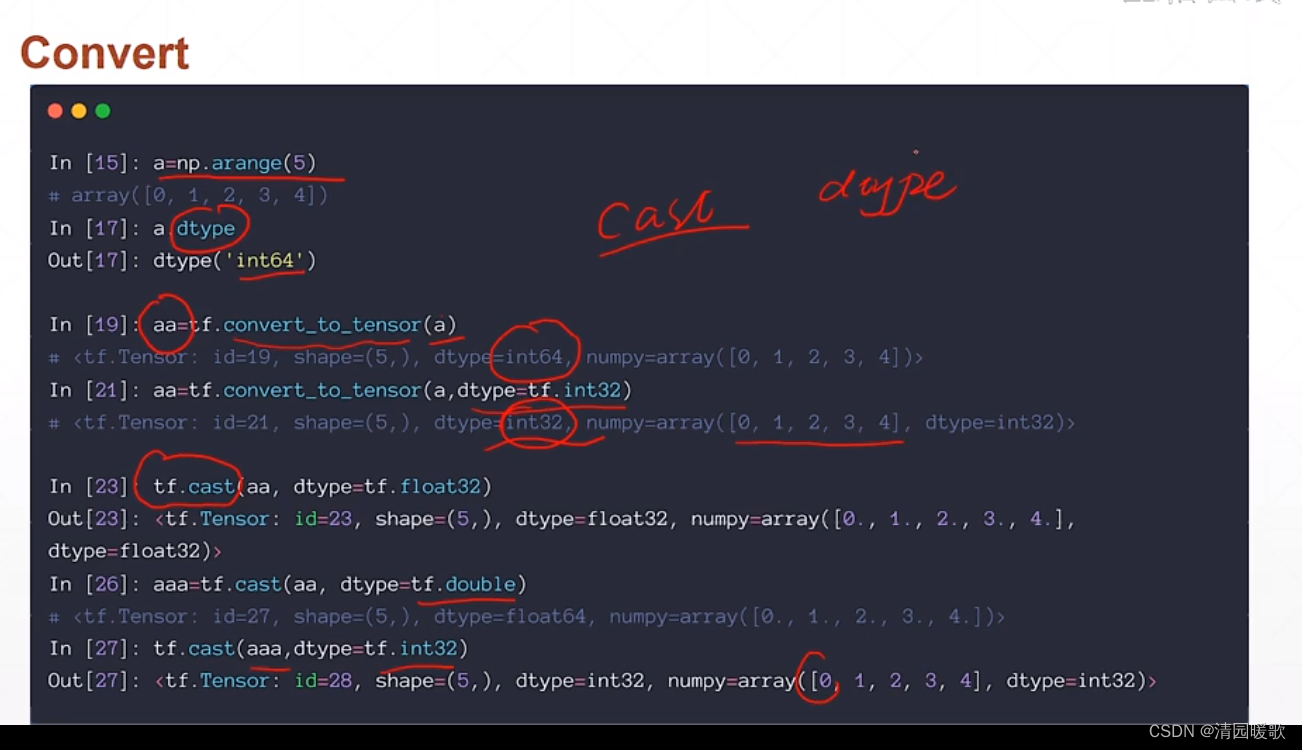
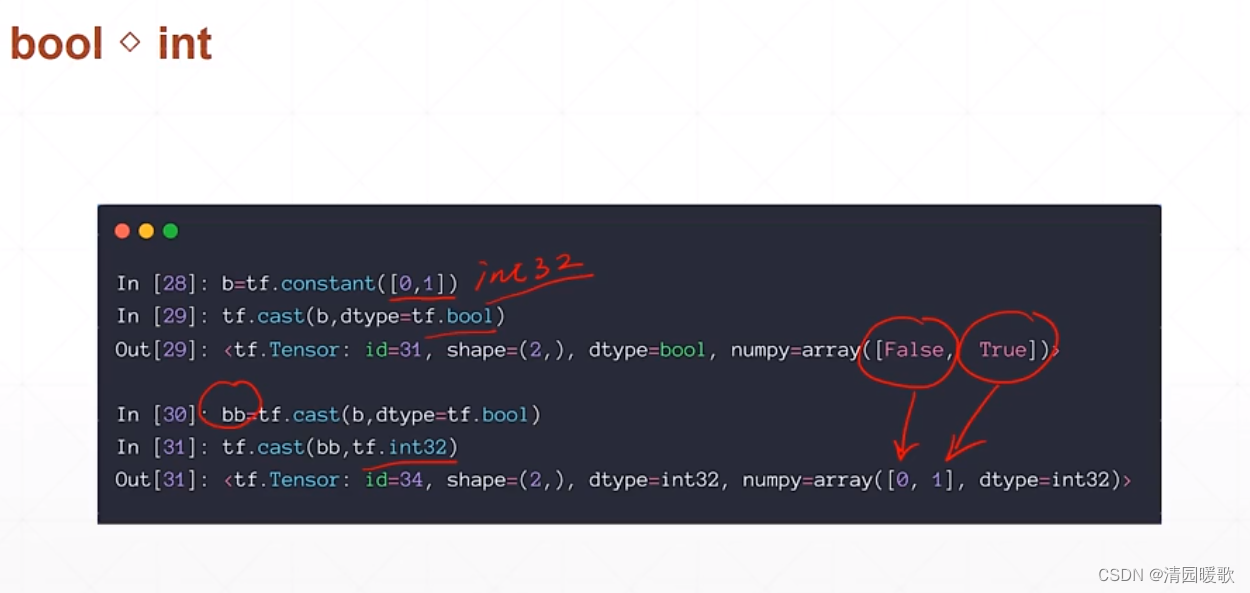
整形和布尔型转换
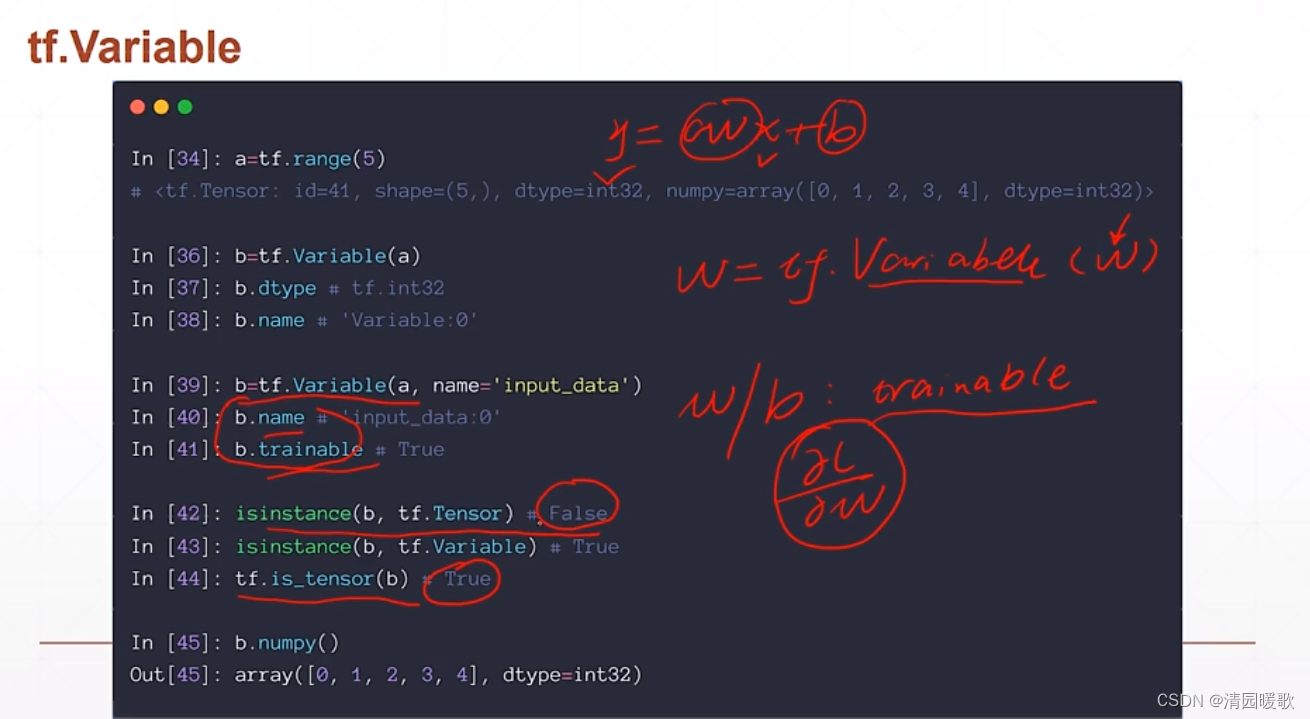
1.4 tf.Variable
如 y = wx + b
x,y 都是 tensor类型;而 w 和 b 都是需要被梯度优化的参数,所以他们除了是 tensor 类型以外,还有一个 Variable 属性
相当于把 原本的tensor类型的 w 用 w = tf.Variable(w) 包一下,这样 w 就自动具备一个可求导特性
如下的 w 就具有了 name 和 trainbale(即可训练的意思) 两个属性
但用 isinstance 显示 false,is_tensor 显示 true,所以 isinstance 不推荐使用
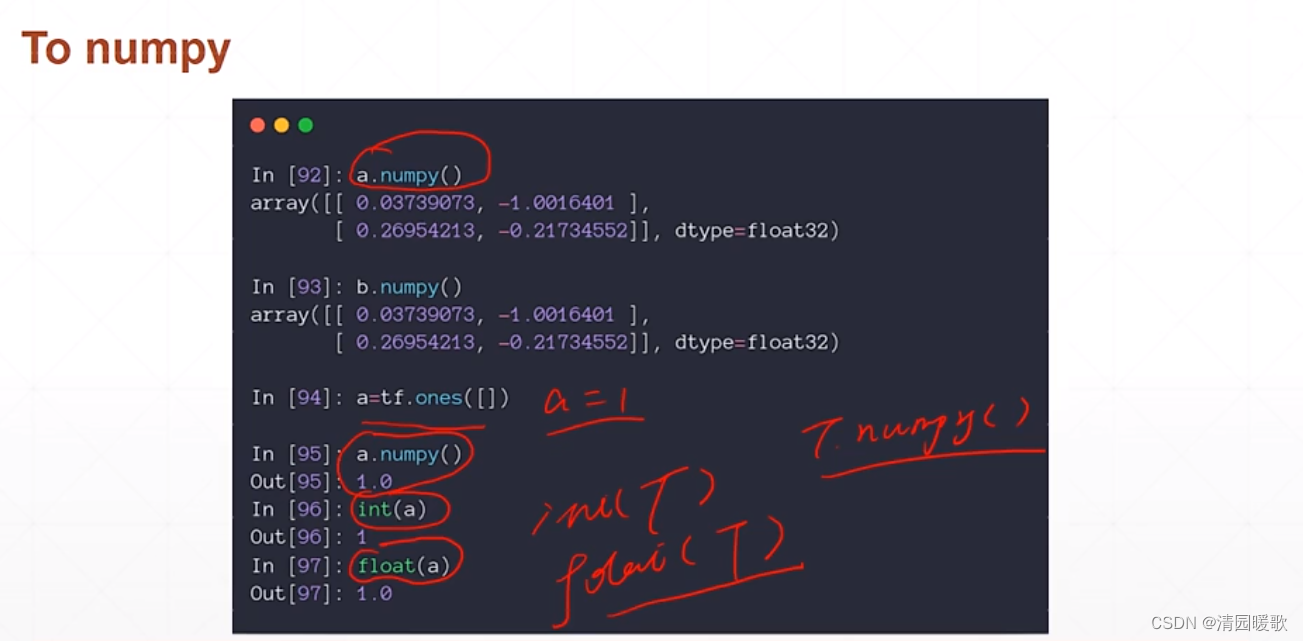
1.5 转换成 Numpy
用 .numpy() ,或者可以直接如 int(b),float(b)
二、创建 Tensor

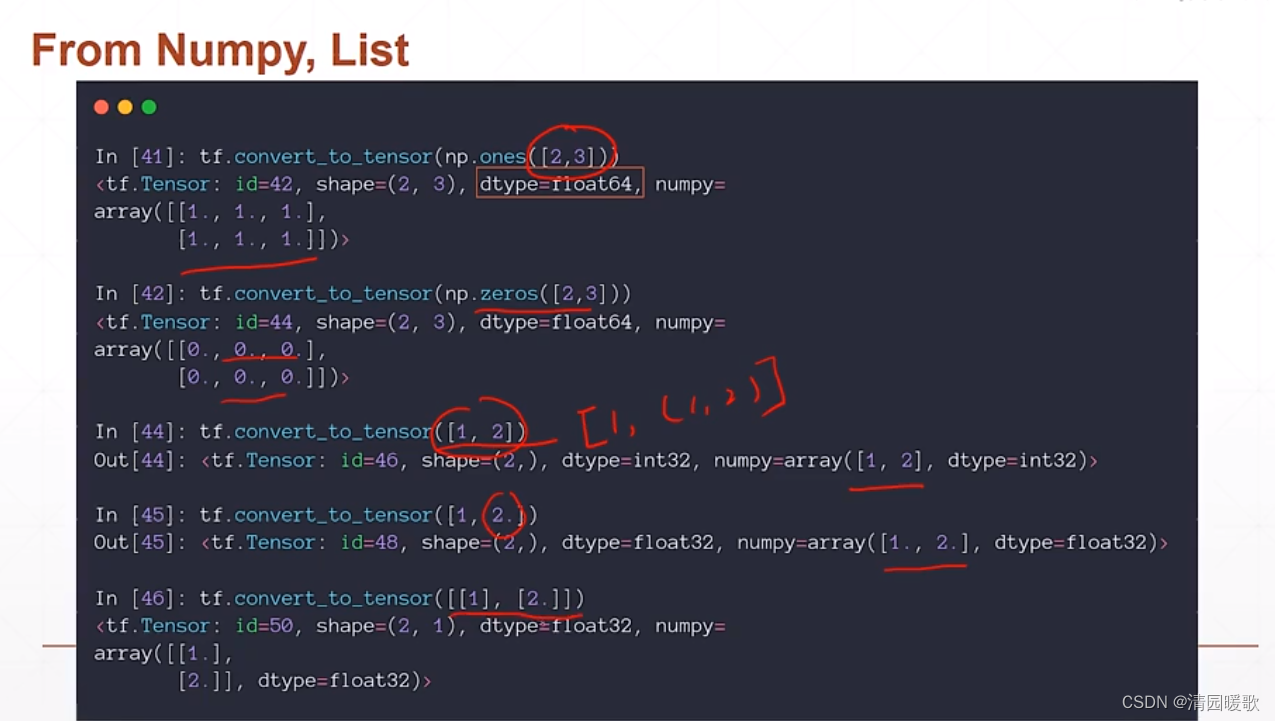
2.1 From Numpy , List
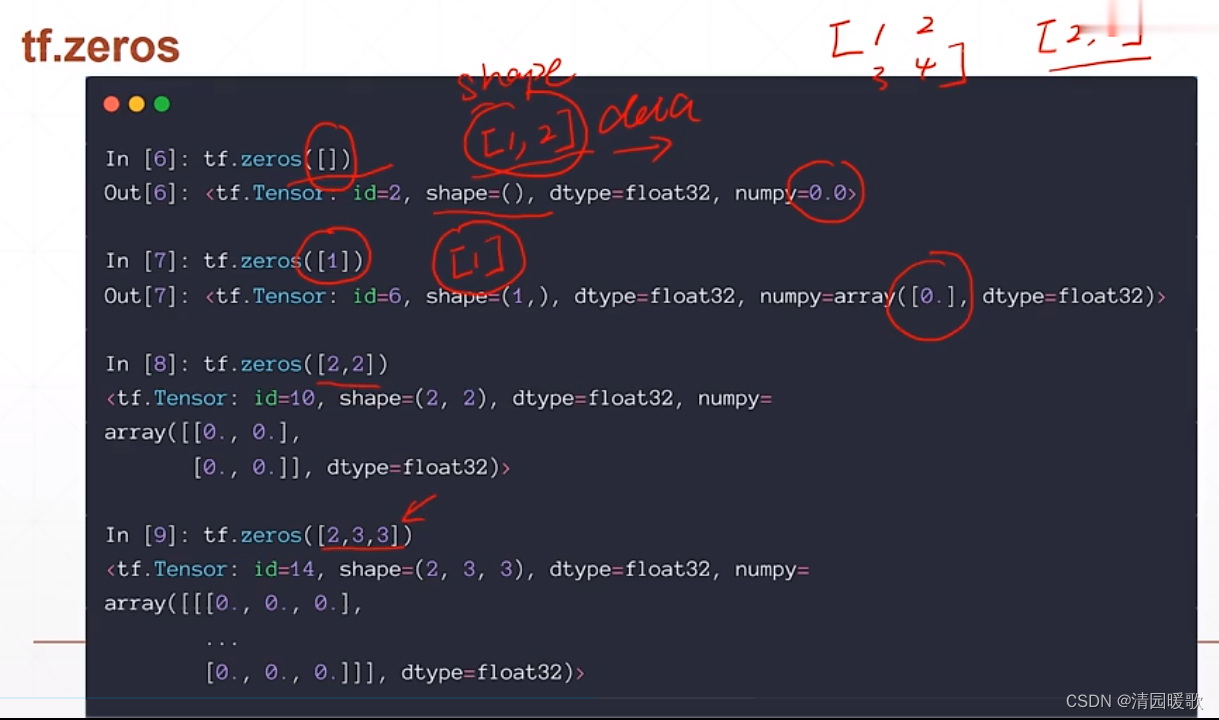
2.2 tf.zeros , tf.ones,Fill
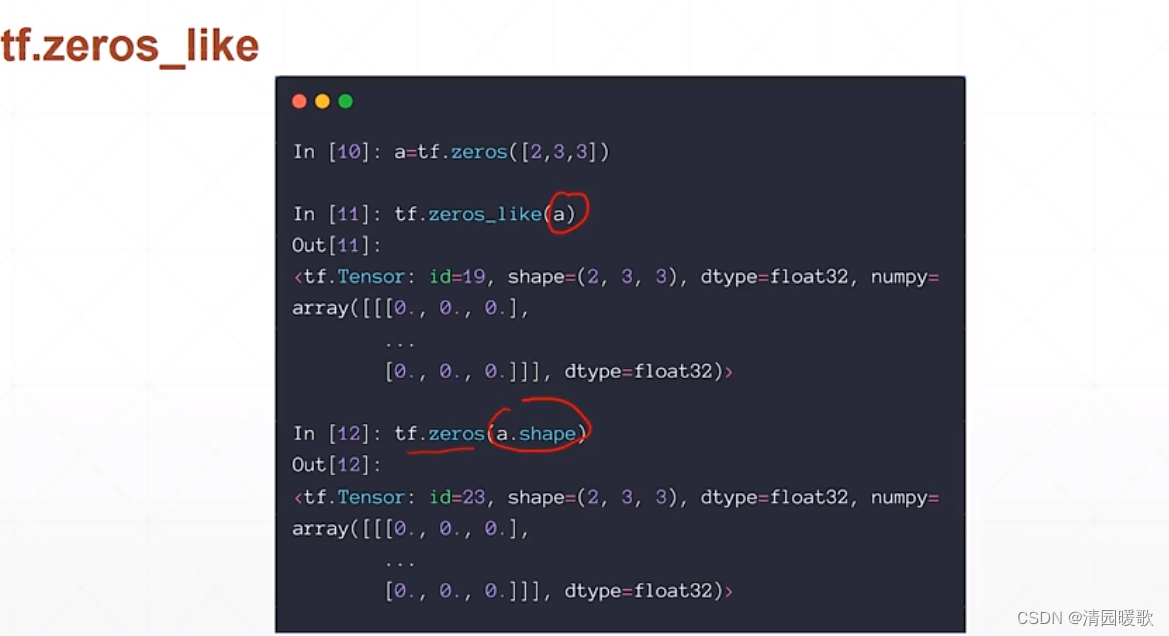
tf.zeros_like(a) 根据传过来的 shape 建立全 0 的, 等同于tf.zeros(a.shape)
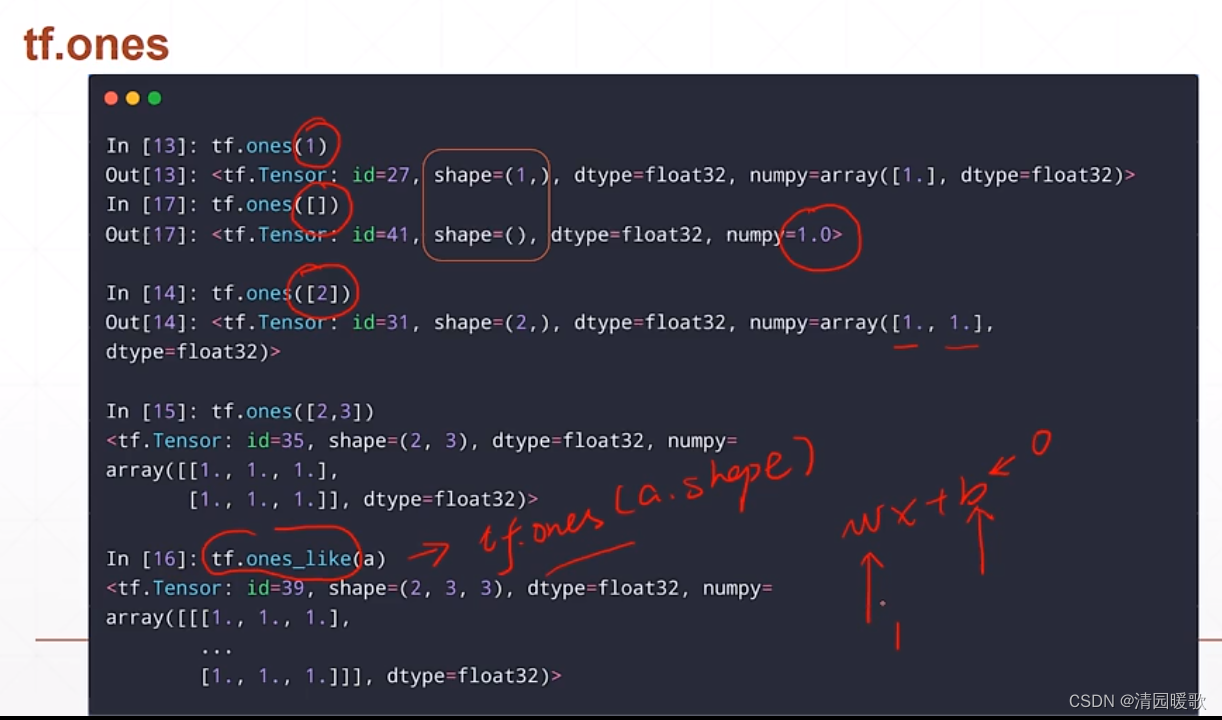
2.3 随机化创建
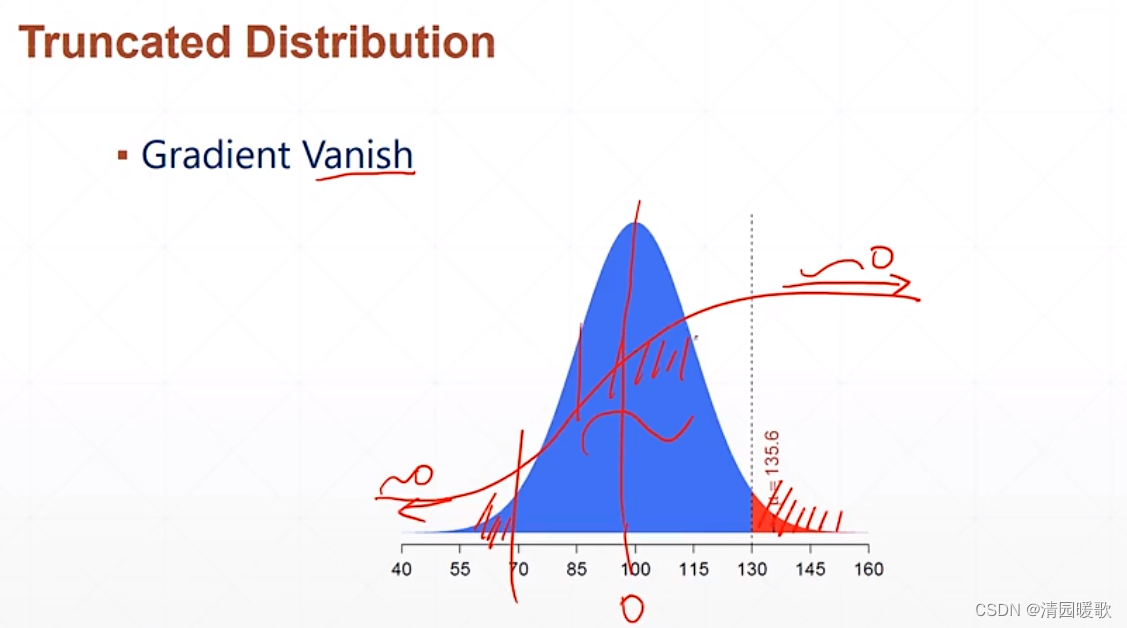
2.3.1 tf.random.normal(分布初始化采样)
mean:均值 , stddev:方差
truncated_normal:是个截断的,截断部分区间
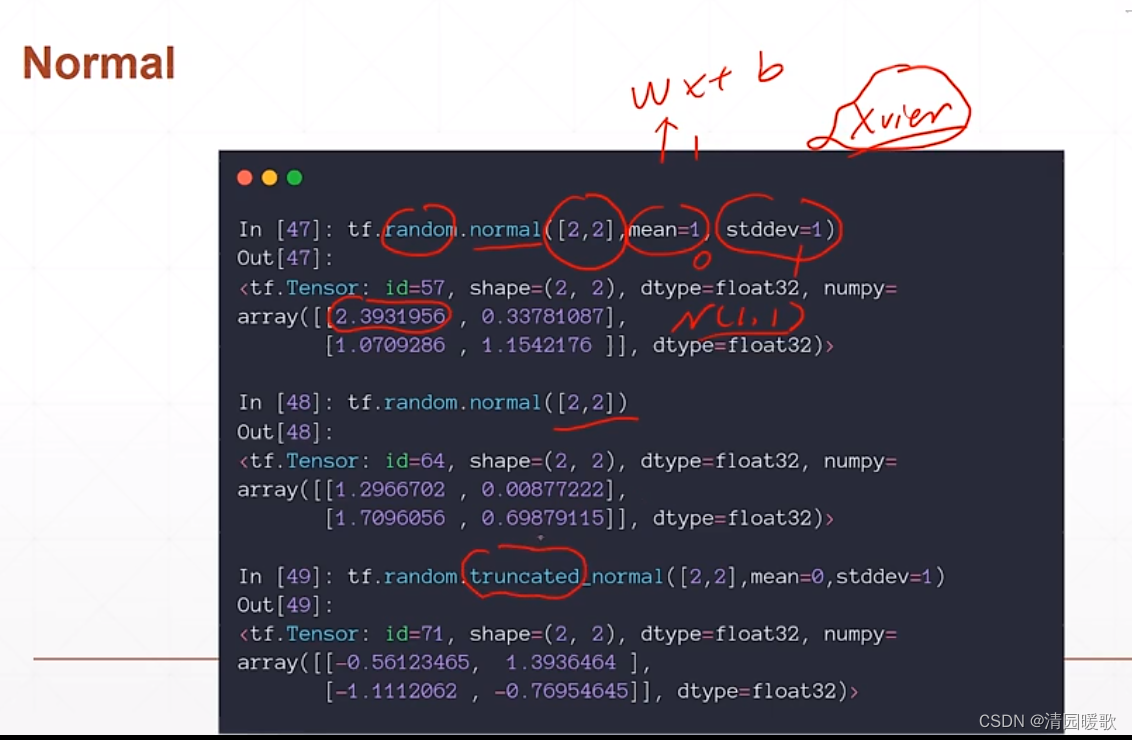
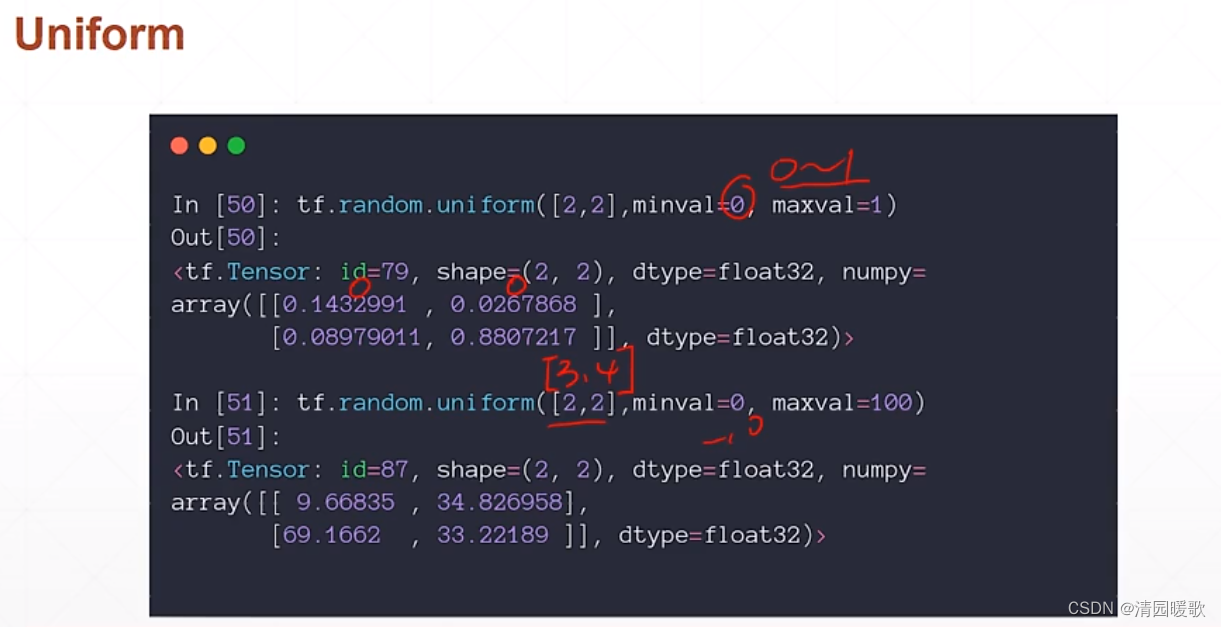
2.3.2 tf.random.uniform(均匀采样)
均匀采样
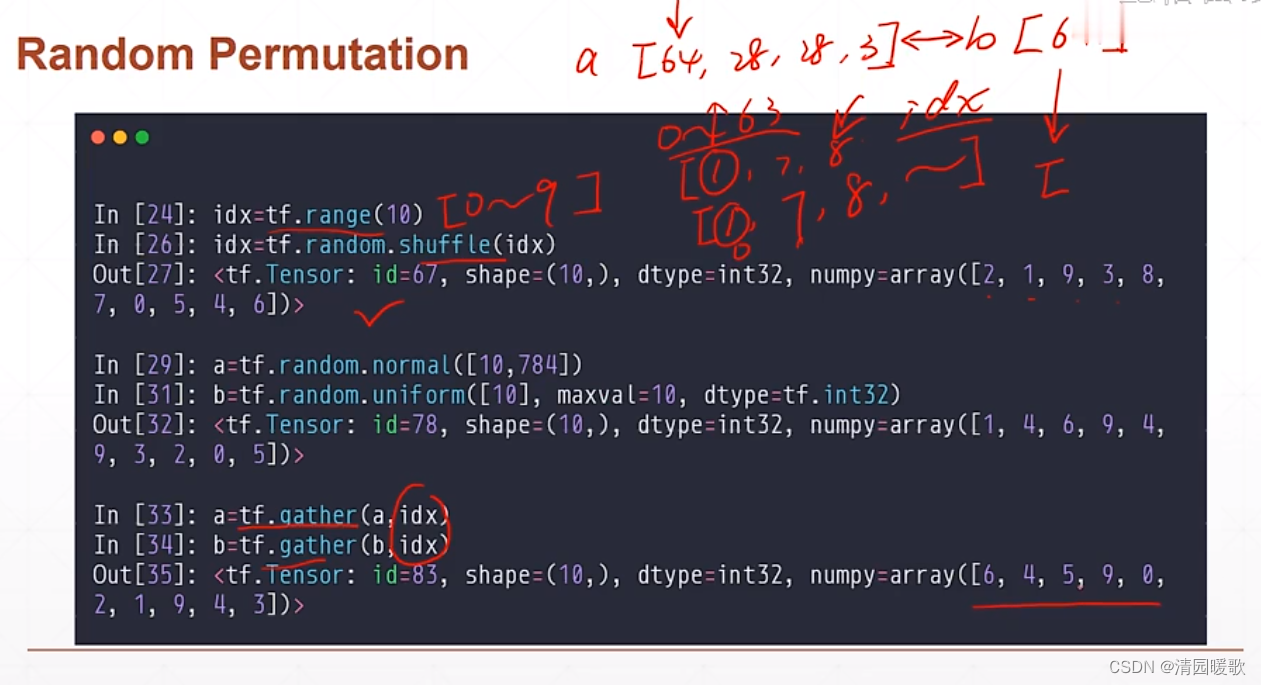
2.3.3 tf.random.shuffle(数据打散)
可用于有对应关系的
gather 对有对应关系的数据进行打乱
2.3.4 tf.constant
tf.constant(1):创建一个标量
tf.constant([1]):创建一个向量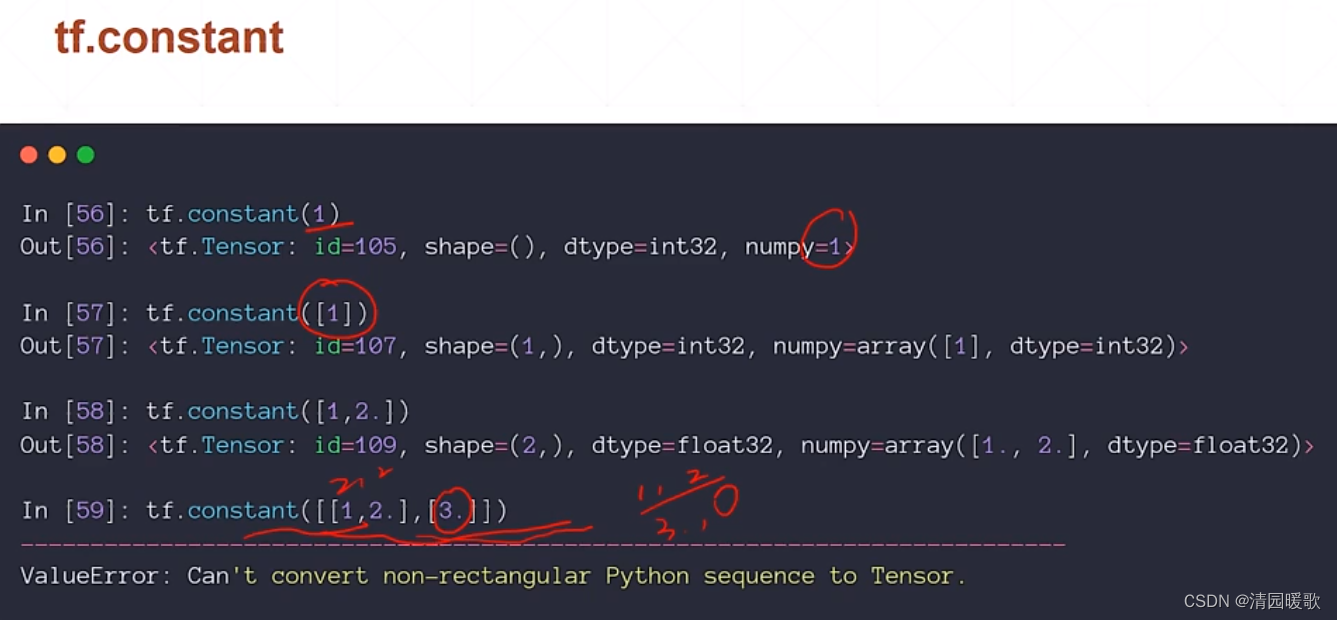
2.4 各种 shape 的 Tensor

2.4.1 Scalar(标量)
类似 loss 、 accuracy
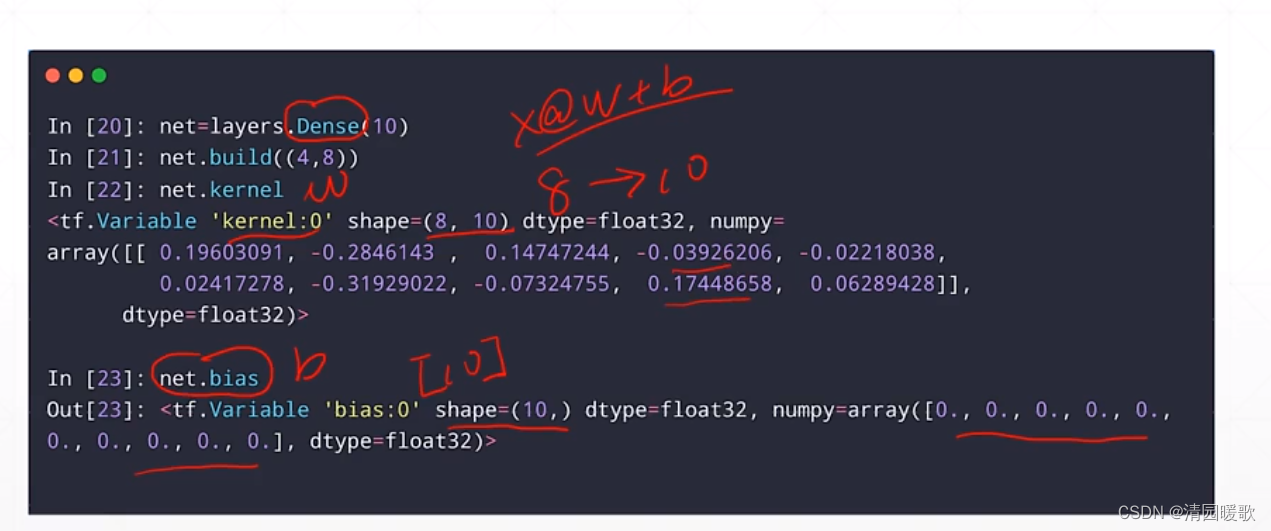
2.4.2 Vector(向量)
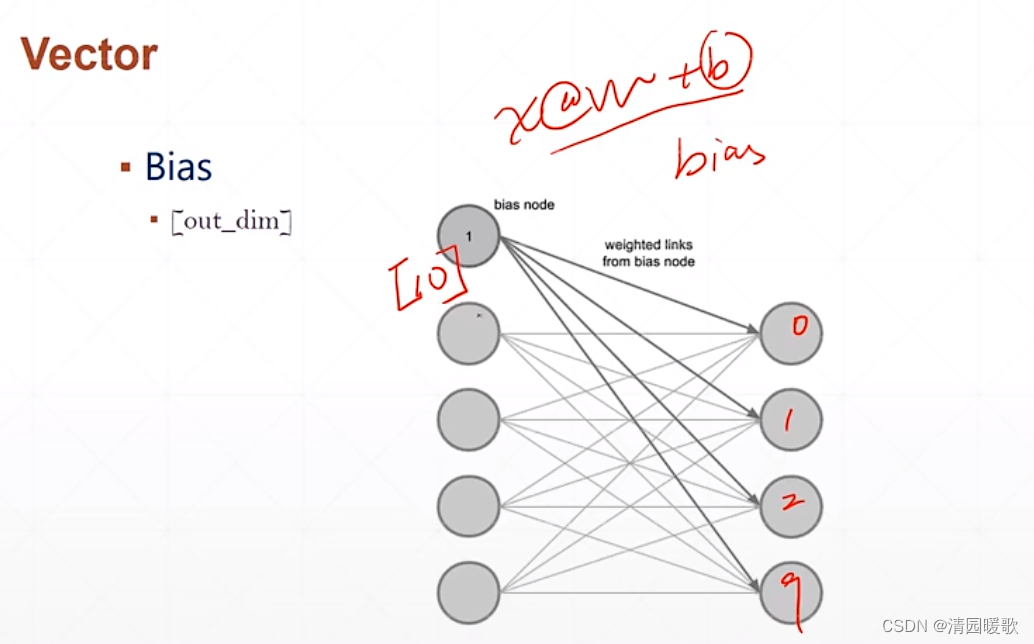
kernel 是 w,初始化是随机的
bias 是 b,初始化是 0
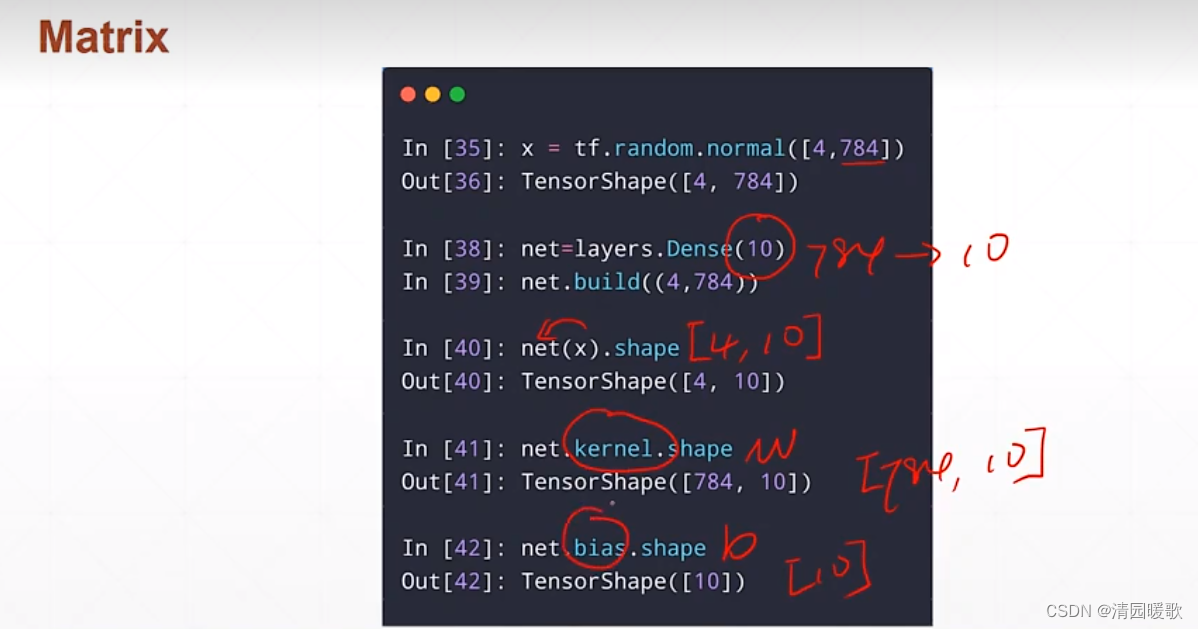
2.4.3 Matrix(矩阵)

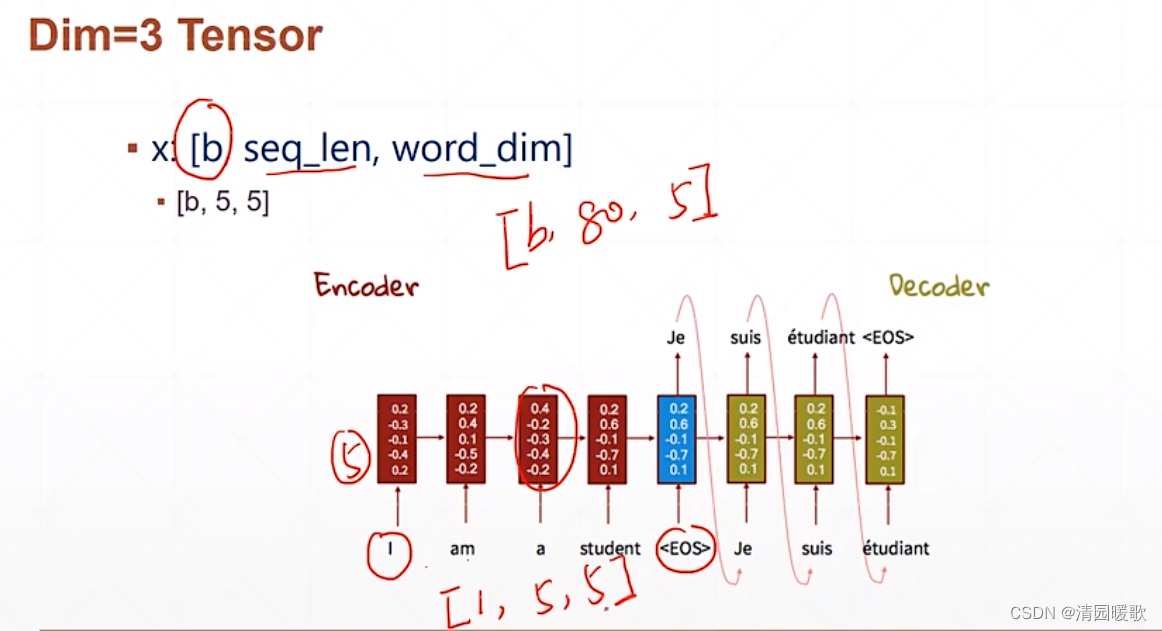
2.4.4 Dim = 3 Tensor
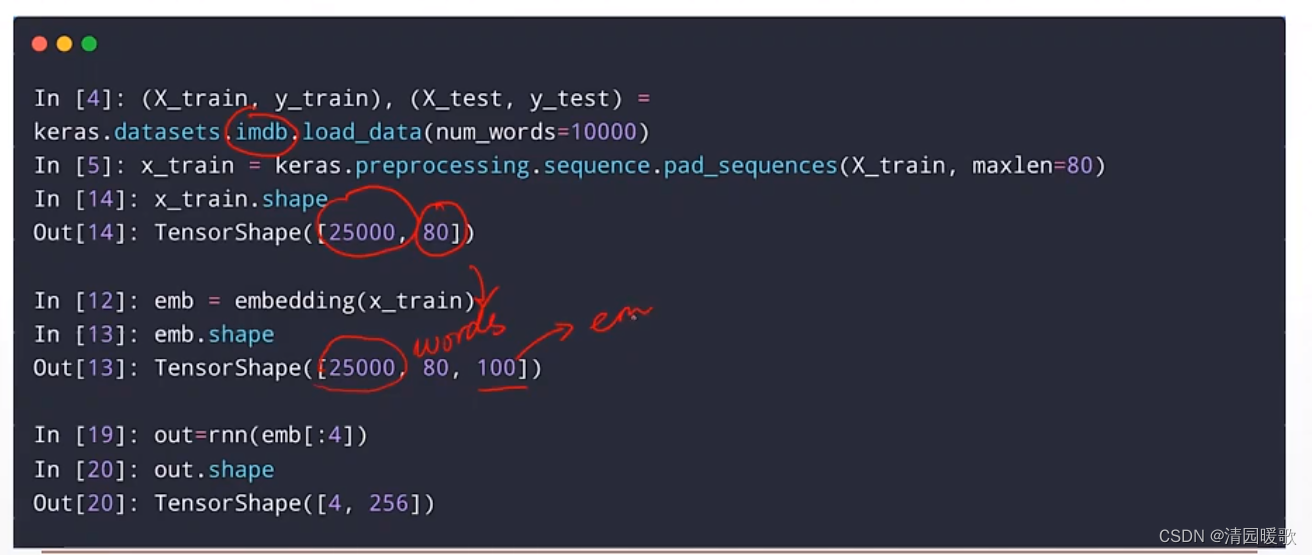
2.4.5 Dim = 4 Tensor(图片)
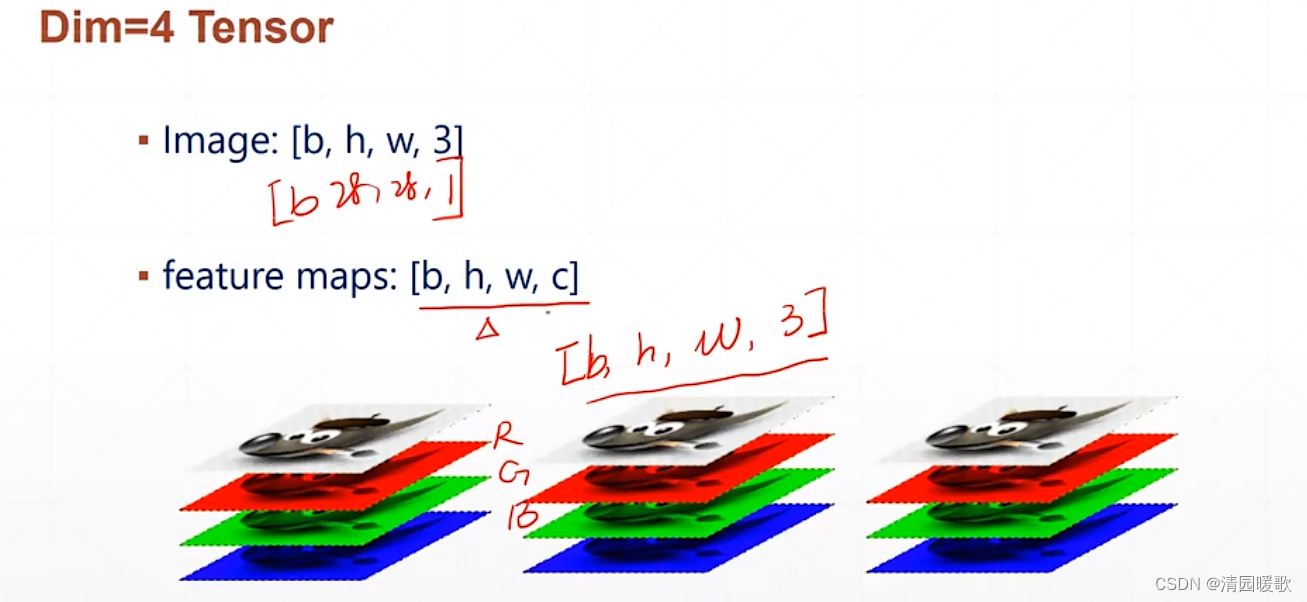
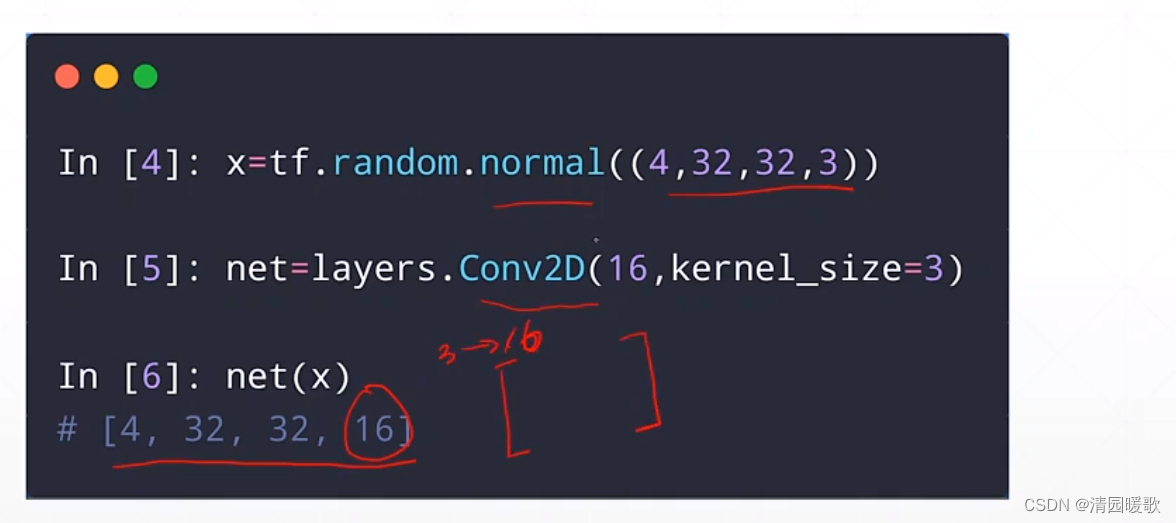
2.4.6 Dim = 5 Tensor
如,有 4 个任务,每个人物 64 张图片,每个图片 28 × 28 ×1

三、索引与切片
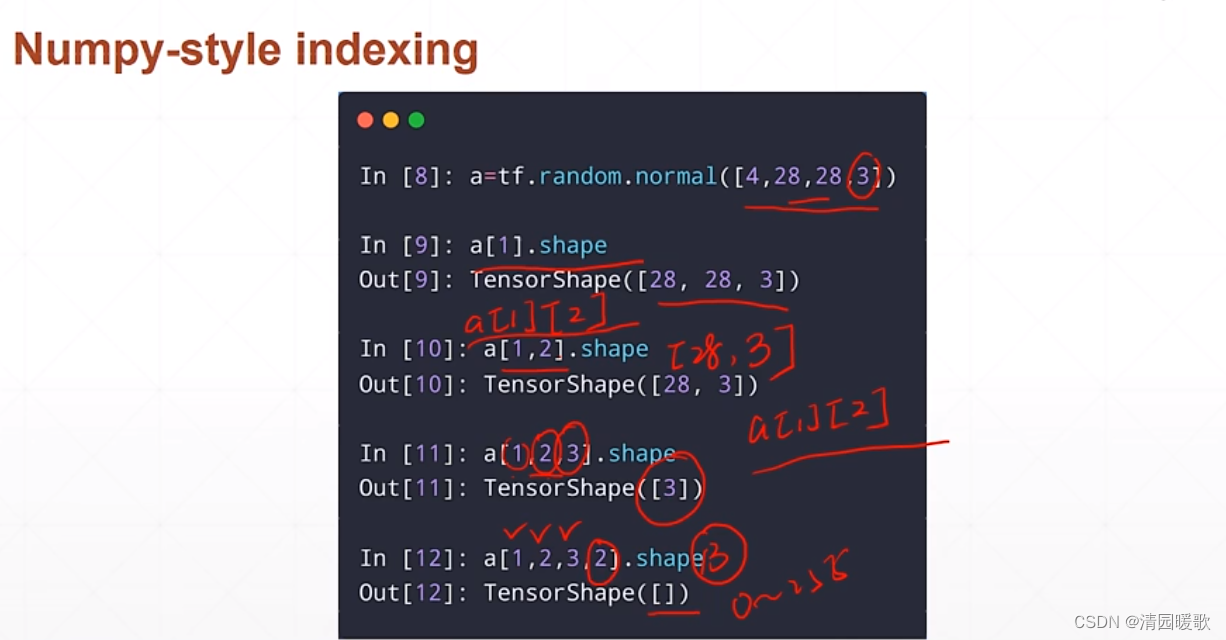
3.1 单个索引 [idx][idx][idx]
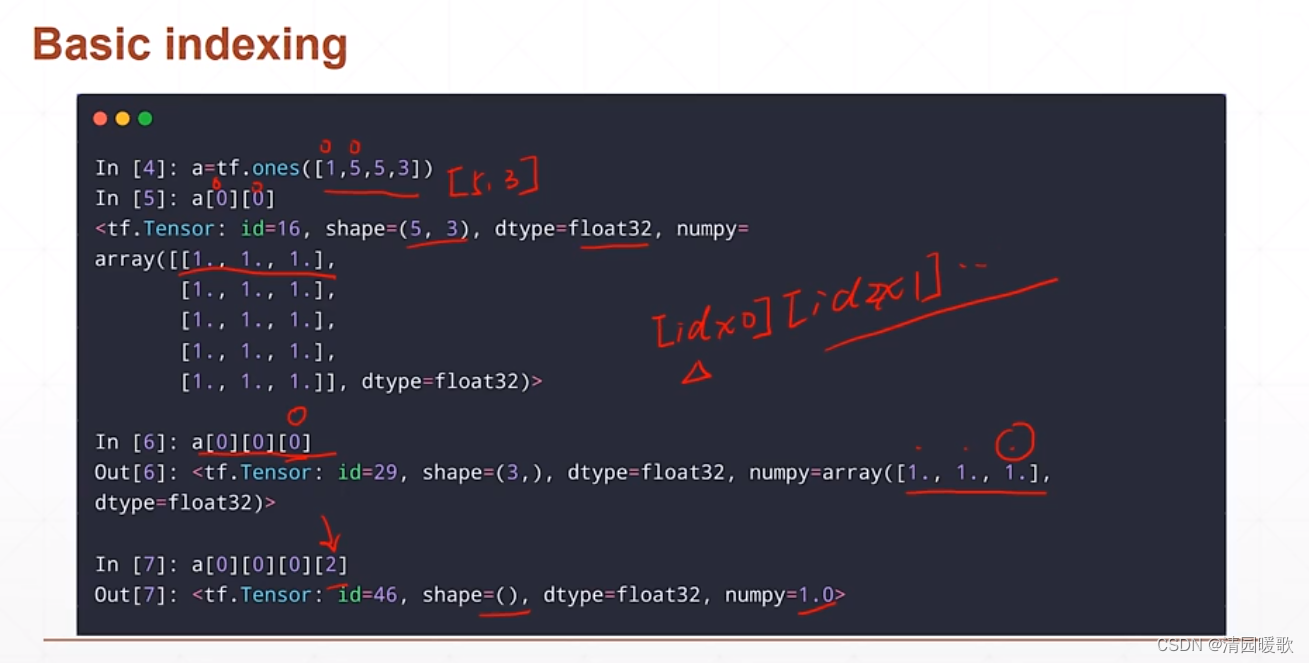
3.2 单个索引 [idx, idx, idx]
3.3 范围索引 [A : B) 和 [ : ]
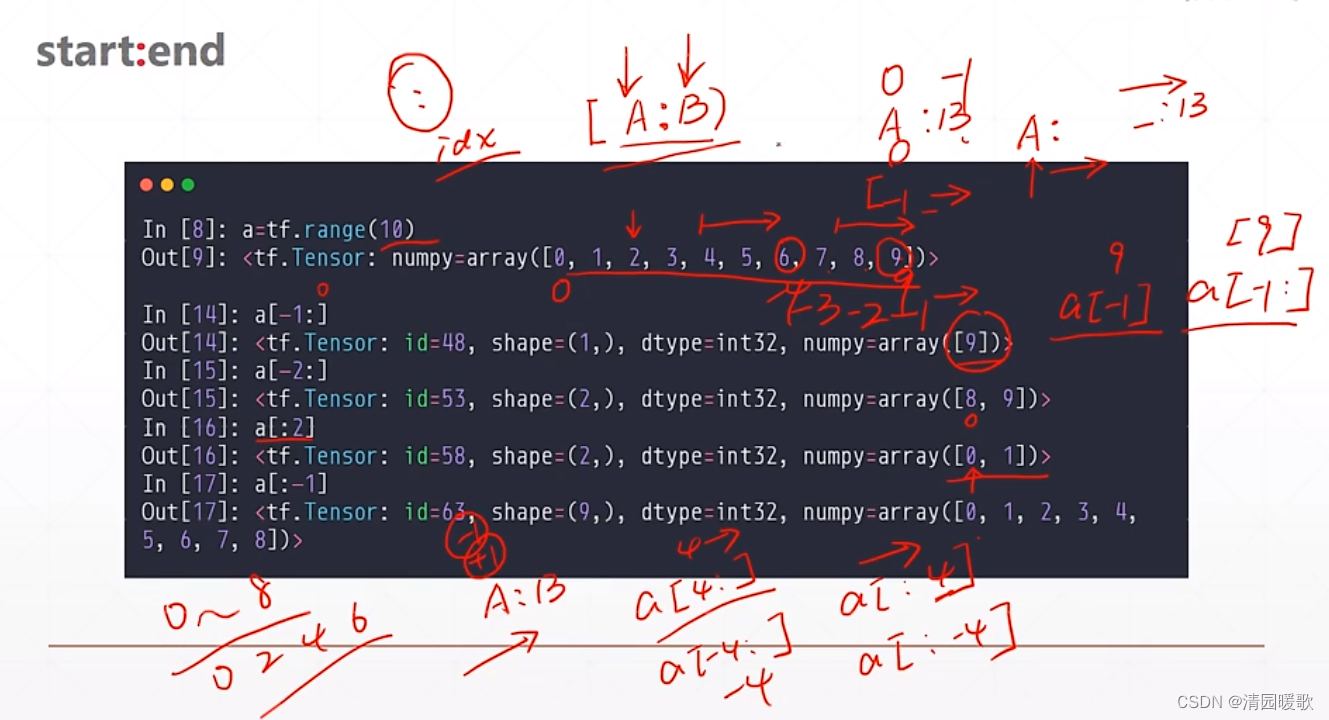
[ : ] :表示取所有维度
如下 a[0] 相当于 a[0, :, :, :]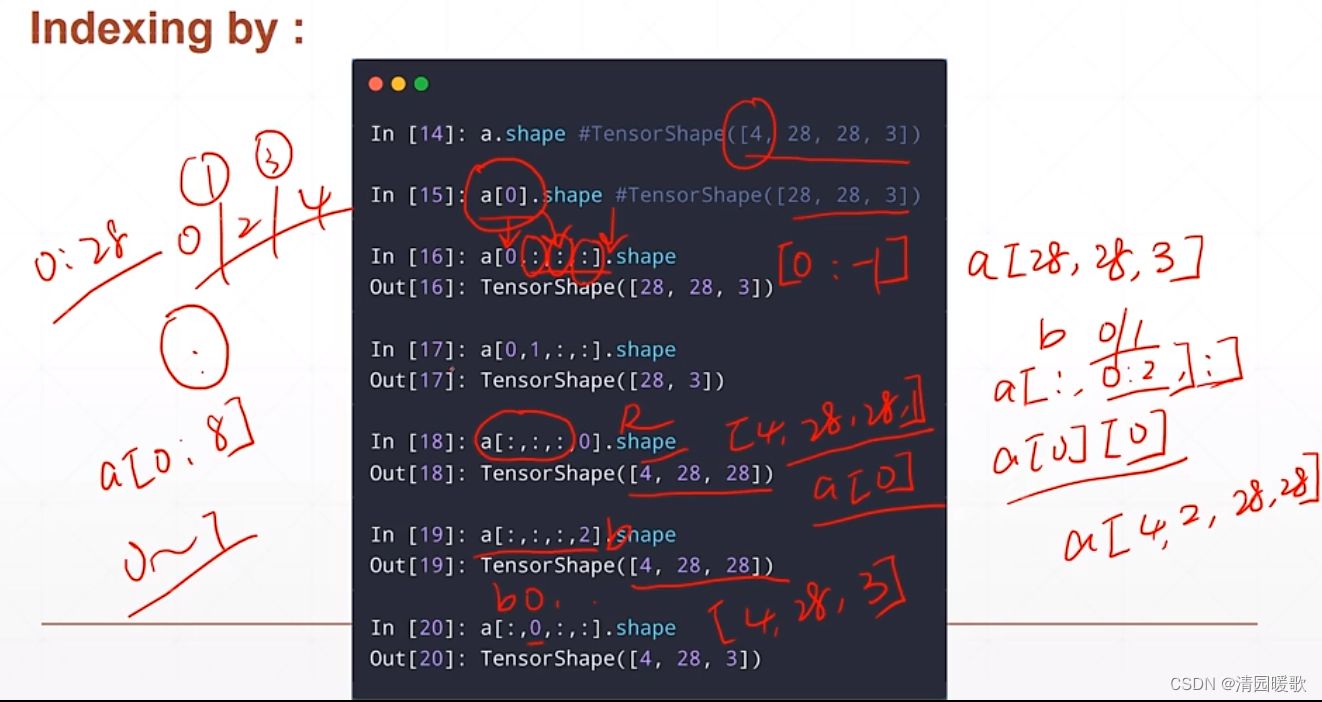
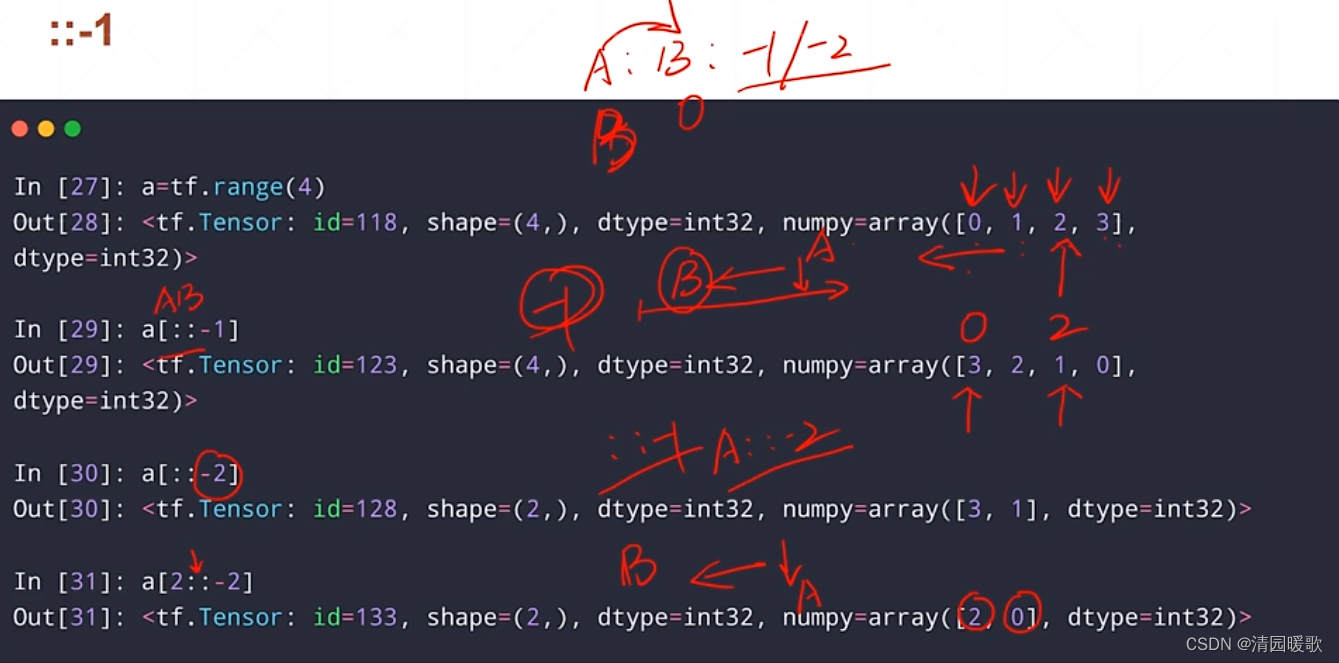
3.4 间断索引(双冒号,即 : :)
(1)范围隔行用法 ::

(2)逆序 :: -1 / -2
3.5 三个点 . . .
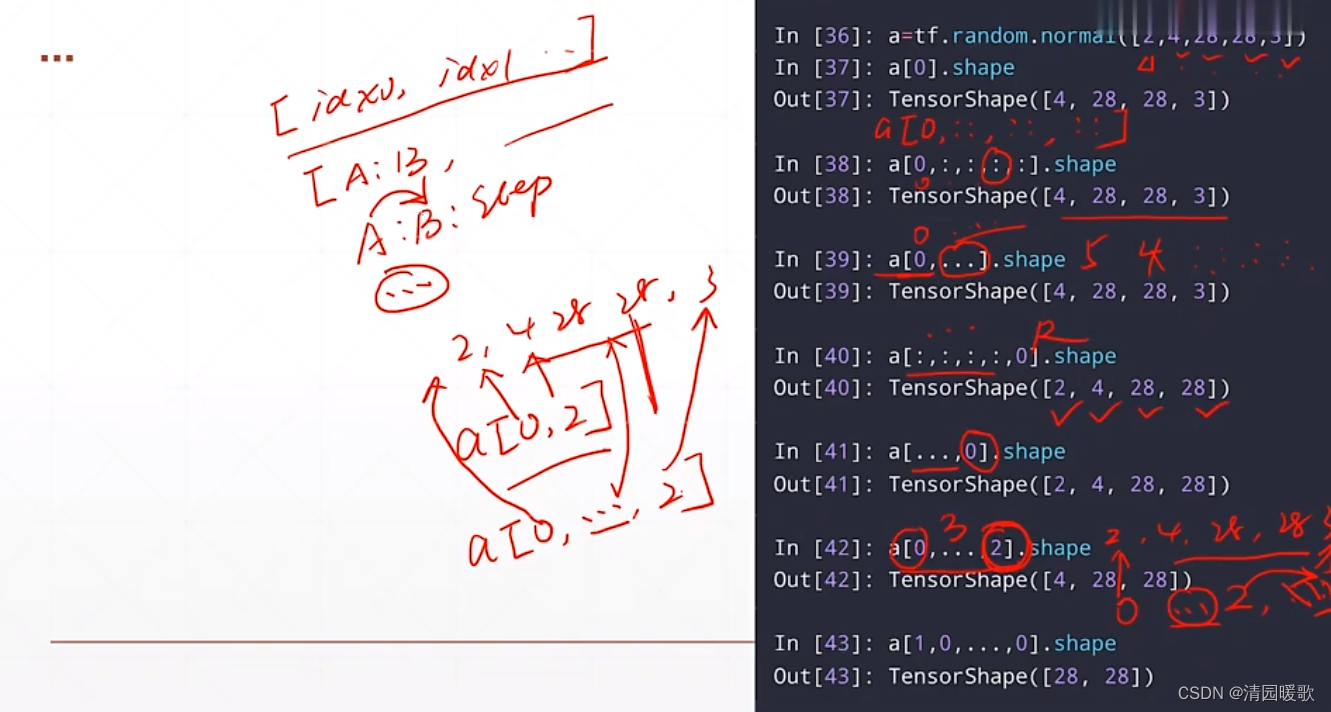
3.6 selective indexing
如下,[4, 28, 28, 3],低于第一个28,我们不直接从A到B取索引,而是单独取其中的第3,27,9,13行,这就是切片indices,就用到了gather的功能,这里是取了4行,gather也就是收集的意思

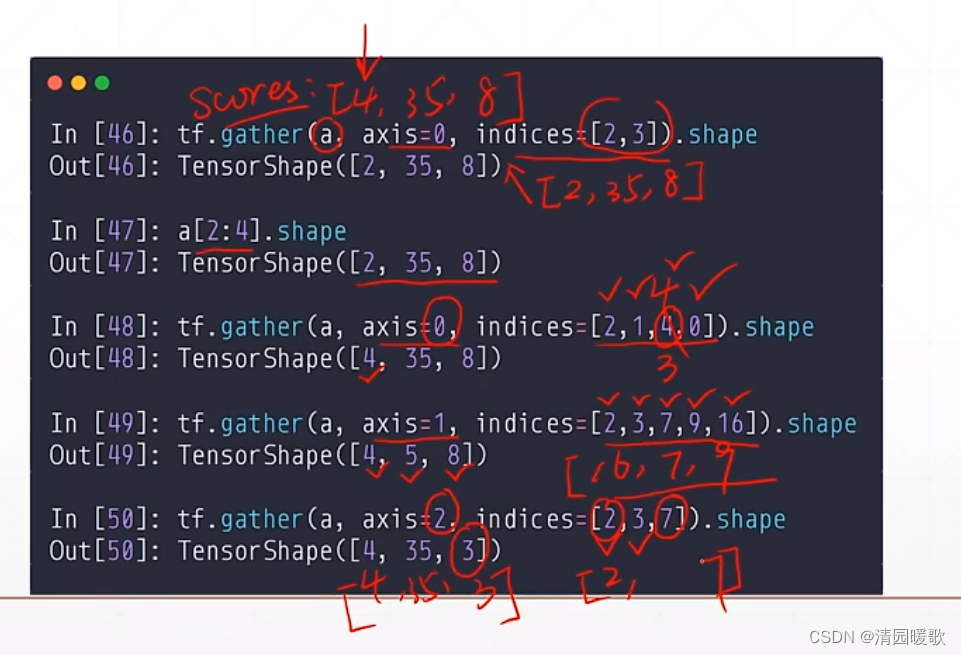
3.6.1 tf.gather
假设有4个班级,每个班级35个学生,每个学生8门课程

axis 给出了要取哪个维度
indices 给出了 索引号
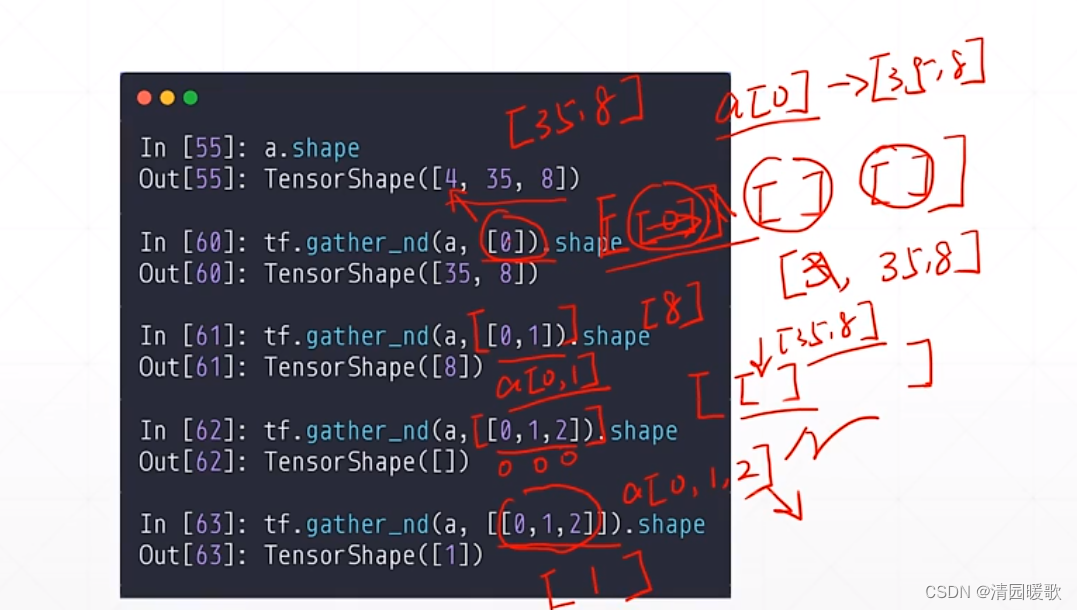
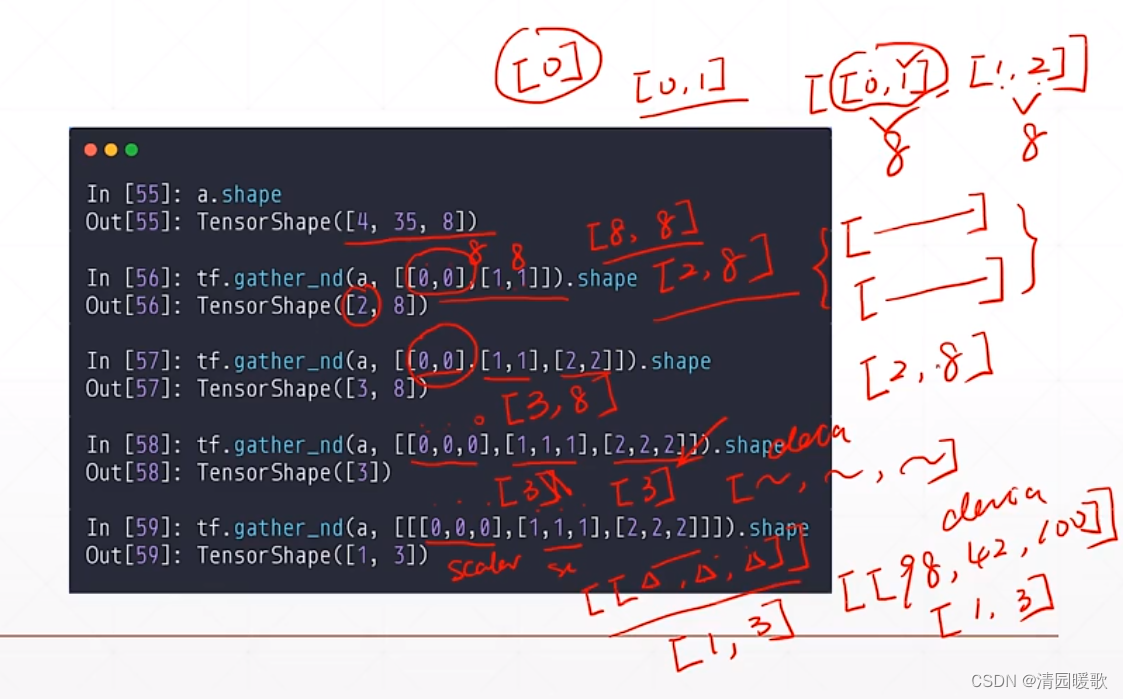
3.6.2 tf.gather_nd
如果要获得 多少个学生的多少个学科的成绩,那么该如何实现?
比如要得到,4个班级 7个学生 3门课的成绩,首先可以通过 两个gather 串联实现

但如果 要取第2个学生的第0门课,第3个学生的第4门课,第8个学生的第2门课这种,用两个gather的方法就无法实现
如下 4个班级的4个学生的成绩,就有 [4, 8] 个数据,相当于是在多个维度,指定了index,gather是在某一个维度

如下,tf.gather_nd(a, [0]) 表示在 [ [ ] [ ] [ ] ] 取第一个维度 [0] 的全部,所以是 [35, 8],返回的是维度
最后的 tf.gather_nd(a, [ [0, 1, 2] ]) 输出的是 成绩的一个具体值,标量,所以是1

3.6.3 tf.boolean_mask
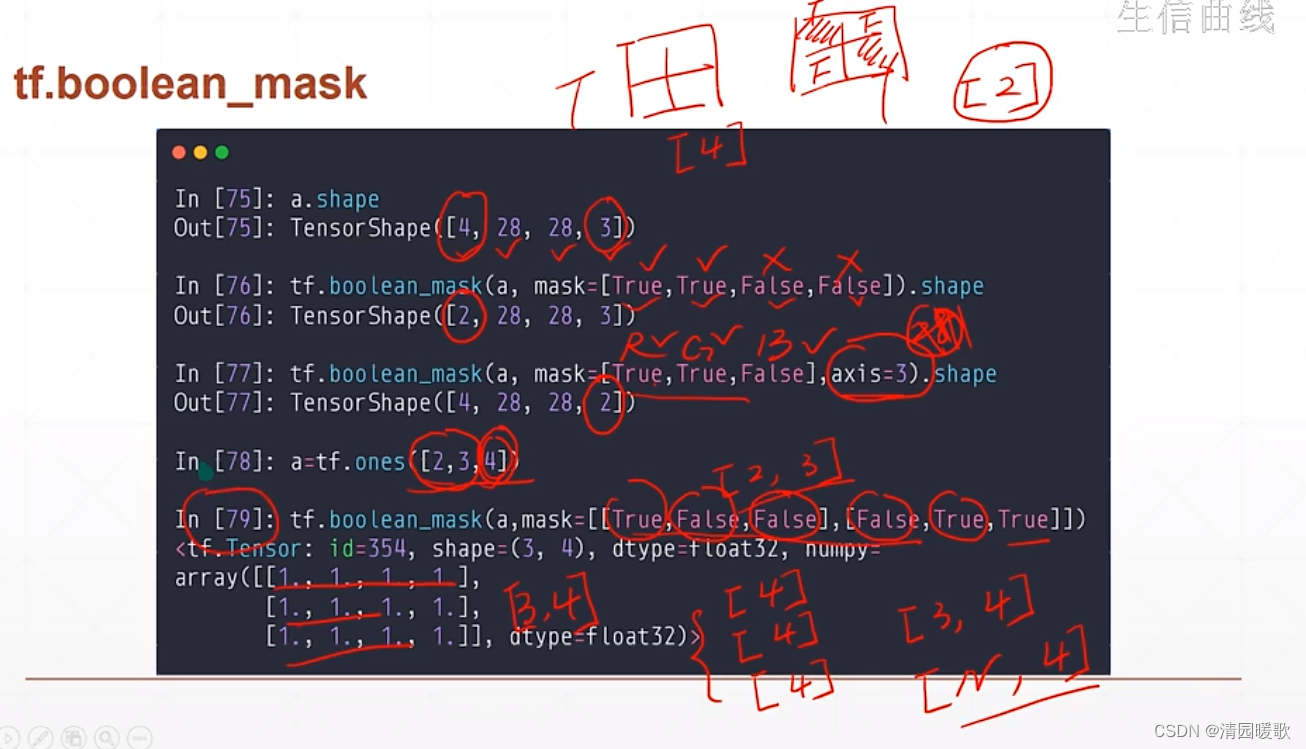
四、维度变换

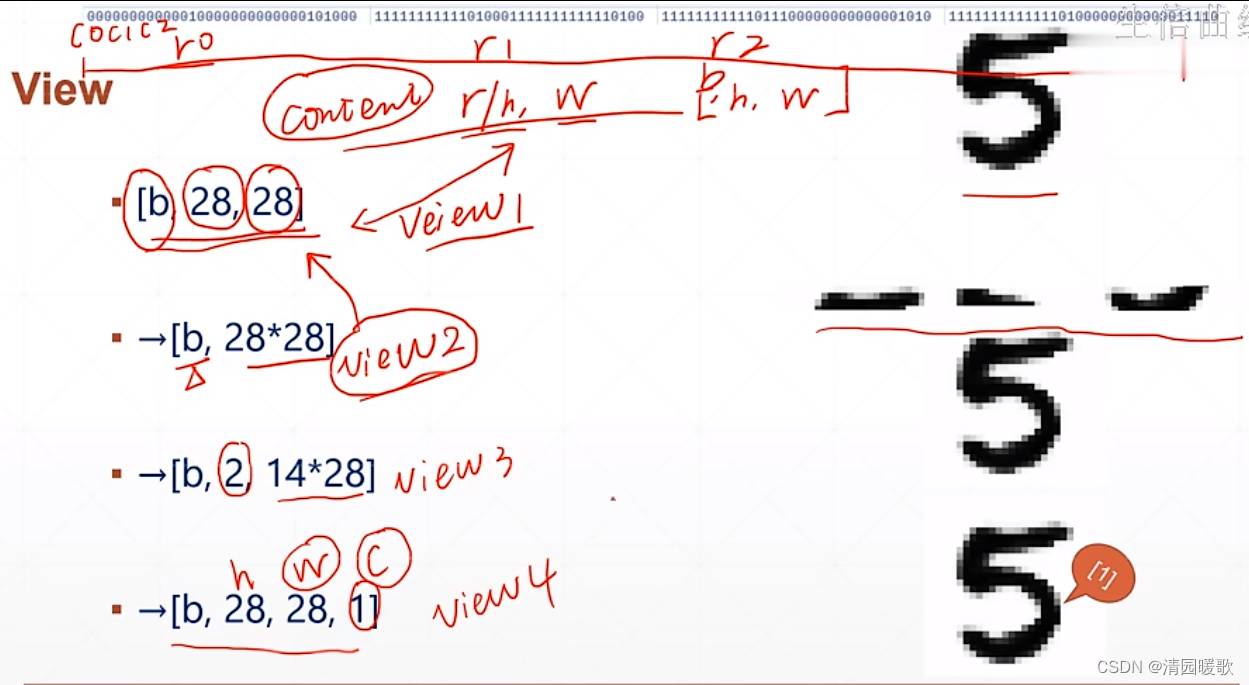
4.1 View概念
了解view 的概念,如下的 view1和 view2,view1 是有一个长和宽的概念,而view2 则是把这个图片当成一个整体,view2不关注图片的具体二维信息,而是直接把图片的 rgb 的数据拿过来使用;view3 把图片分成了上下两部分;view4 只是多了一个 channel;这些view对图片原来的content内容没有改变
4.2 tf.reshape
-1 是自动计算,使得满足原来尺寸
784*3 是数据点的总数量
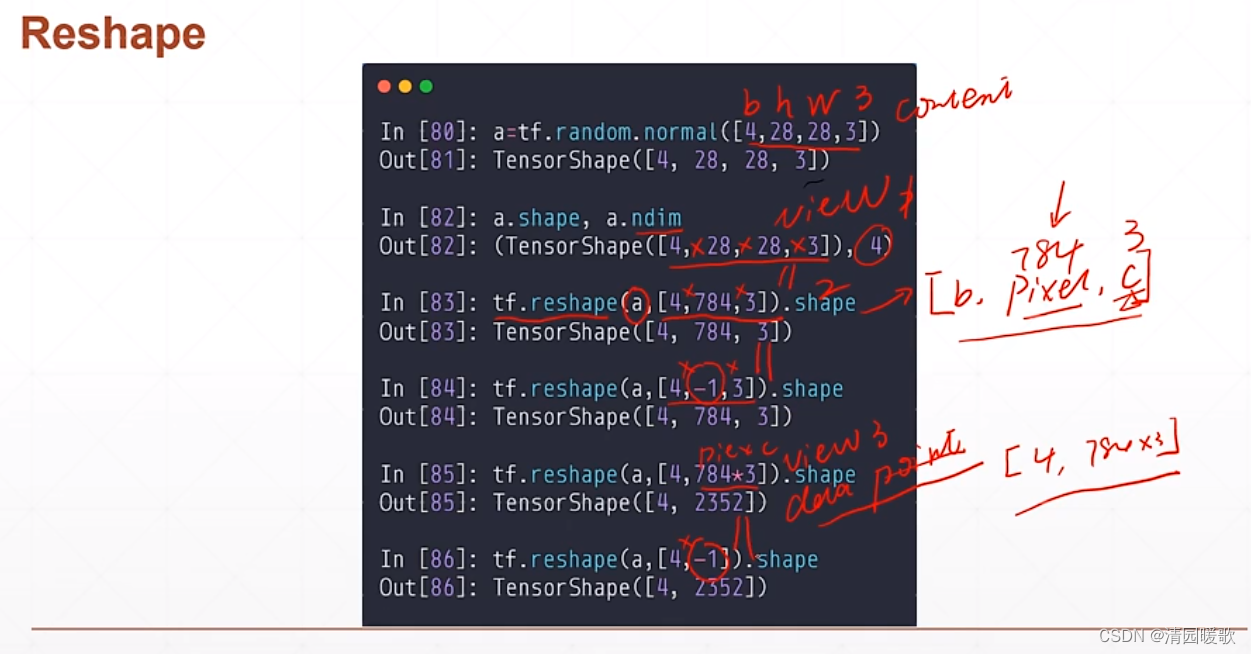

如上,reshape 操作非常灵活,提供很多的可能性,但有没有具体的含义要具体来看
但也可能带来潜在的问题,即把图片从 [4,28,28,3] 变成 [4,784,3] 后再变回 [4,28,28,3] 时,这是就需要原来图片 content 的信息 ,如下所示,把 height 和 width 维度记错 或 记混了

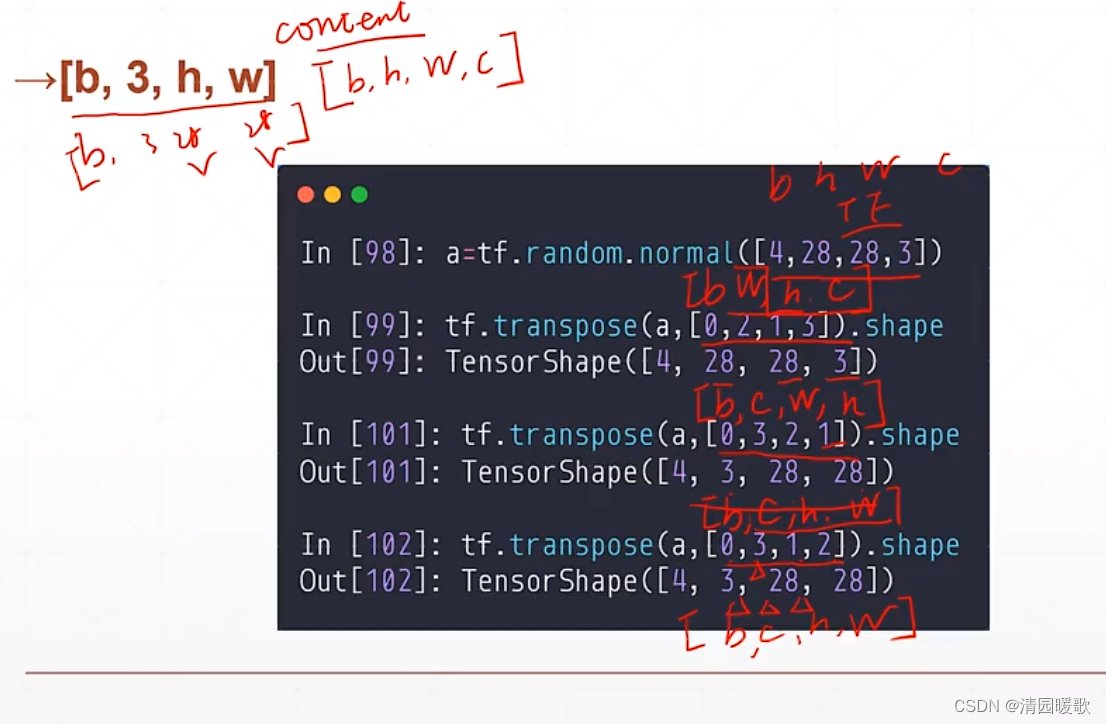
上述都是在改变 view, 那么如何改变 content 呢?如将 h,w交换,或把 c 提到前面,这就用到一个函数:tf.transpose
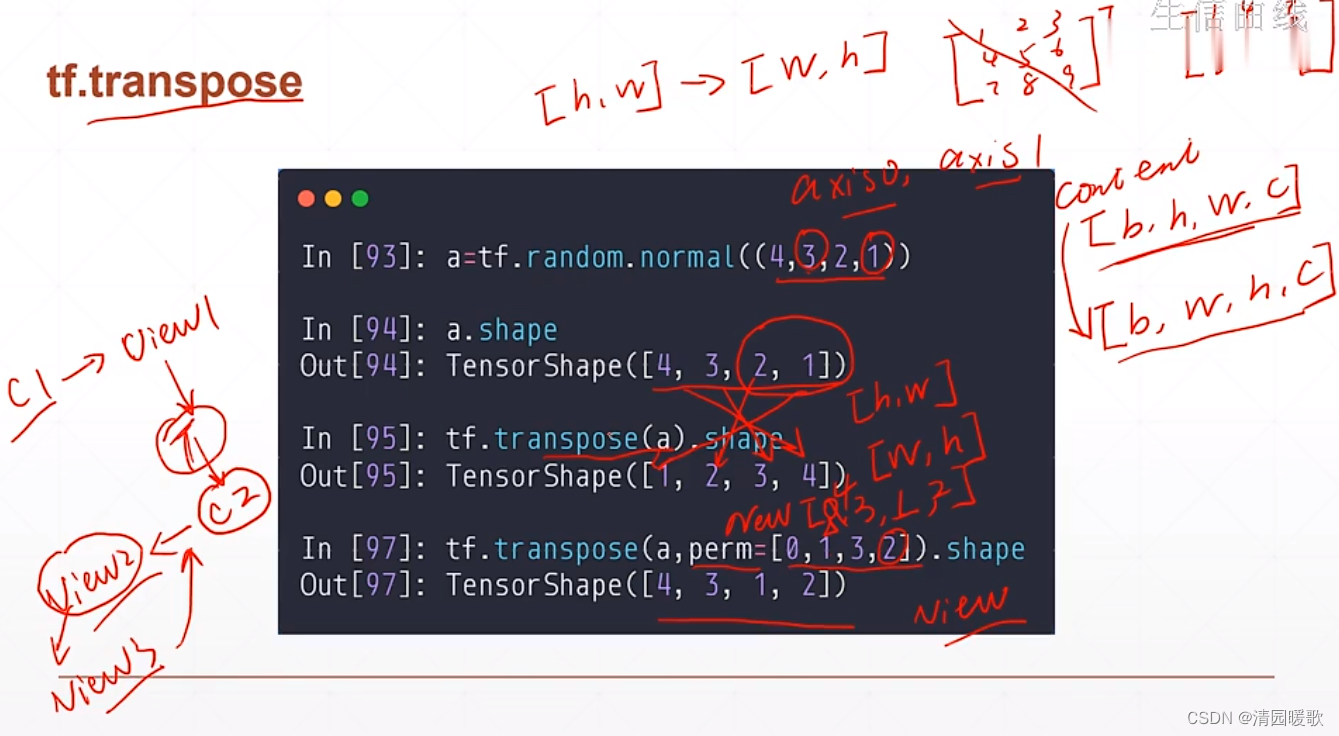
4.3 tf.transpose
与矩阵的转置类似,不设置参数就是全部转置,可以设置参数规定新的维度是什么,所以每一次的 view 必须跟踪相应的 content
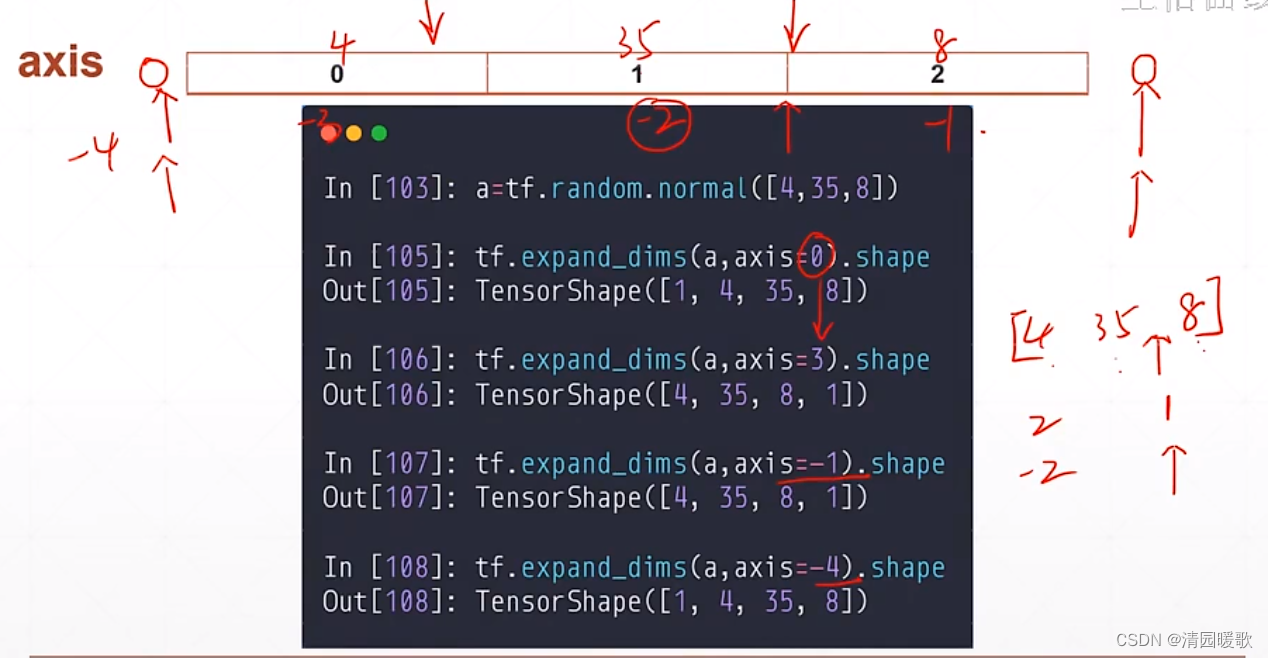
4.4 增加、减少维度( Expend dim 和 Squeeze dim )

4.4.1 tf.expend_dims
如下,要增加一个 school 的维度

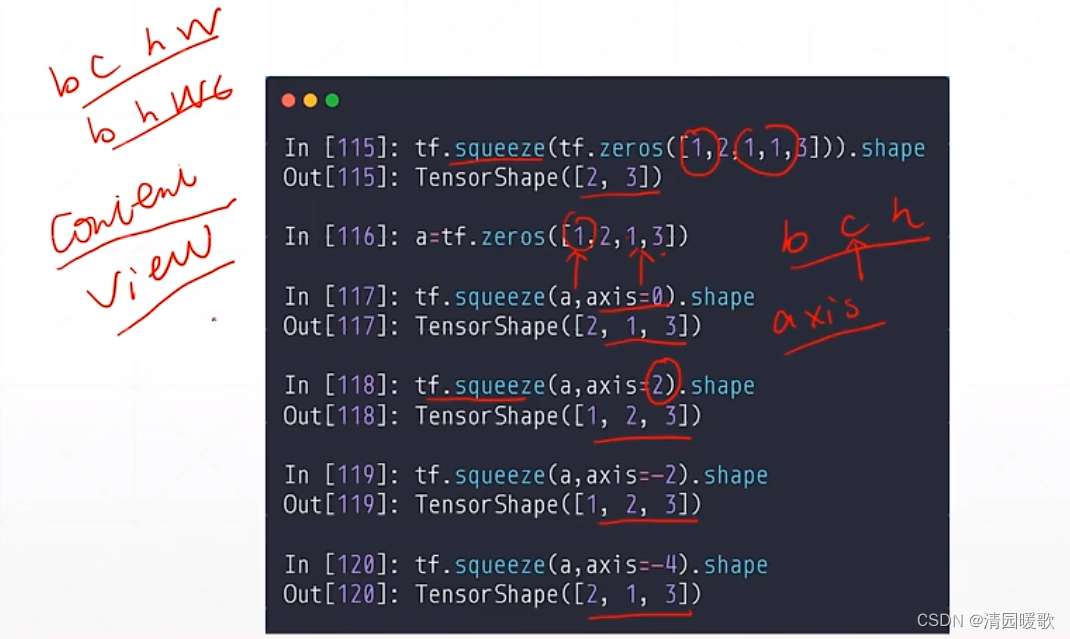
4.4.2 tf.squeeze

五、Broadcasting(张量维度扩张)
指对某一个维度重复多次,但是没有真正的复制一个数据
如下 [b, 10] + [10] 得到的是 [b, 10] 的,但不能直接相加,要把 [10] 转换成一个 [b, 10] 的tensor,这个过程就是 broadcasting

broadcasting操作流程:
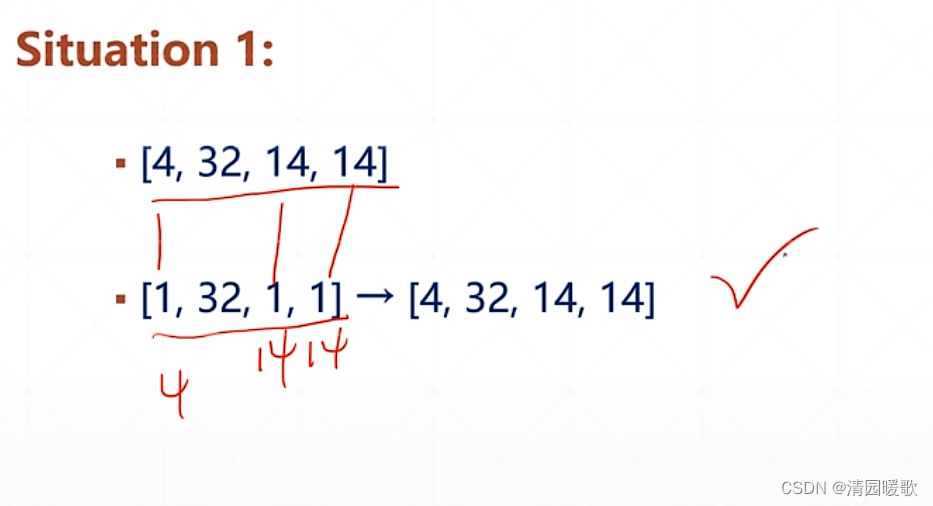
如果 a,b 的 tensor 的 维度 dimension 不一致,如 [4,16,16,32] 和 [32] 相加,首先要把小维度对齐,左边大右边小,往前延伸插入维度,再把每个维度对齐,把1扩张为4,16

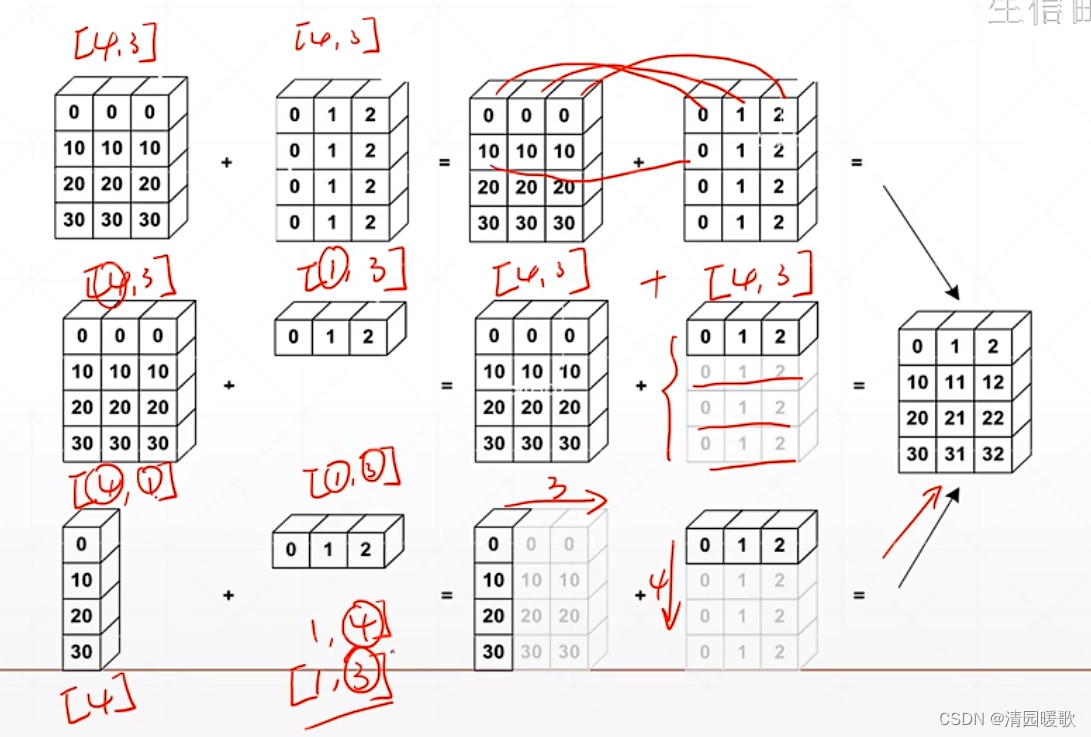
那么 broadcasting 到底代表什么意义?
如假设要把英语和物理都加分,英语加5,物理加10,此时是小维度scores,此时创建出班级学生的维度[1,1,8] 在扩张
而下一种情况是对学生0的成绩都加5分,就是把每个班级前两个学生的每个科目都加5分

broadcasting的好处?
(1)写起来更加简洁
(2)节省更多内存

节省了 2^7 个字节数
什么是能够broadcasting的?

如下情形:



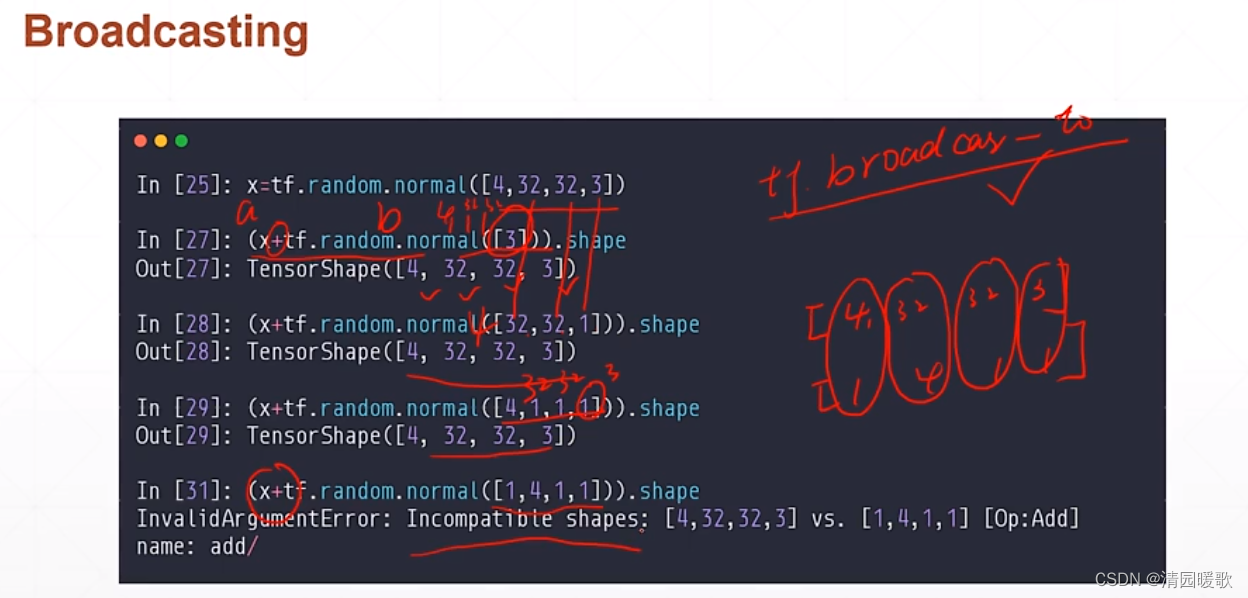
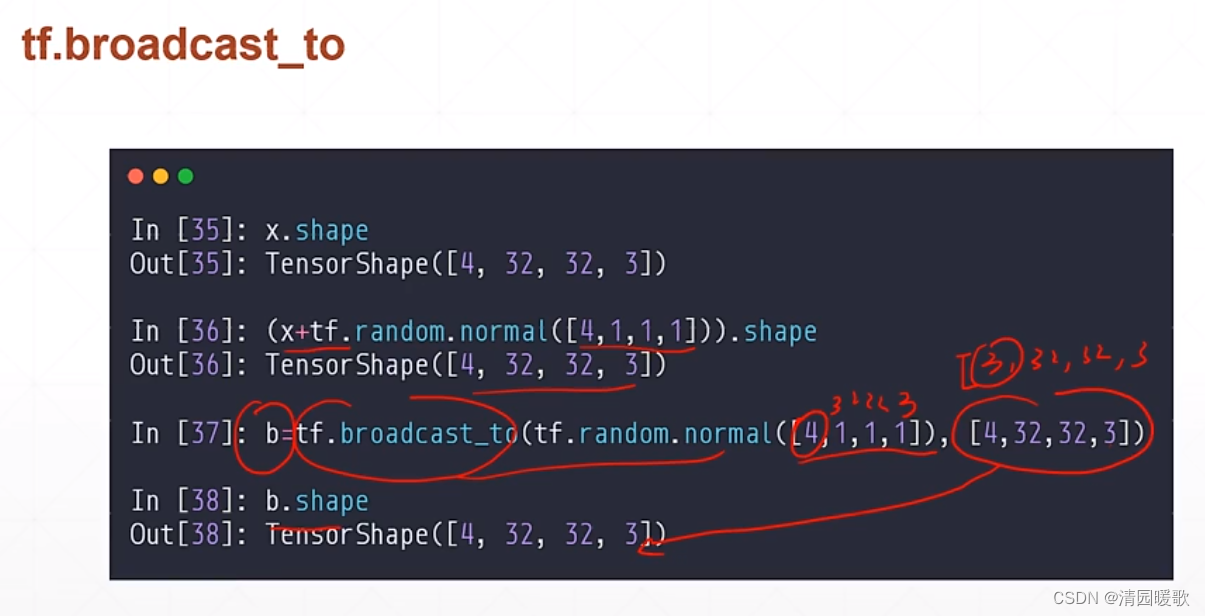
5.1 tf.broadcast_to
也可以通过调用 tf.broadcast_to 来完成维度的扩张,不调用就是自动完成
5.2 tf.tile
tf.tile(a2, [2,1,1]) 把0维复制2次,1,2维复制1次就是没变,得到shape=(2,3,4)
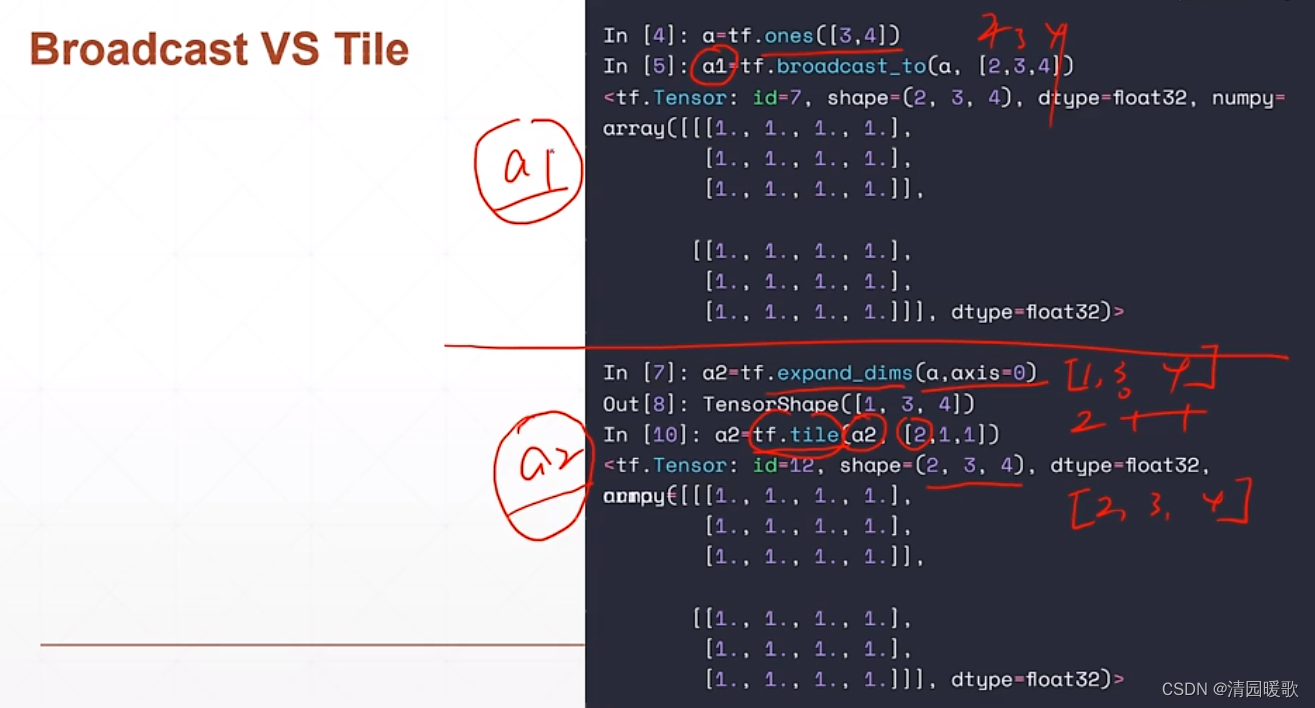
a1和a2 在共用上面是等价的,但a2占用内存更大,a1实际上的内存区域是没有扩张复制的
六、数学运算

操作类型:
(1)对某个具体的元素
(2)对矩阵类型
(3)对某个维度,某个轴

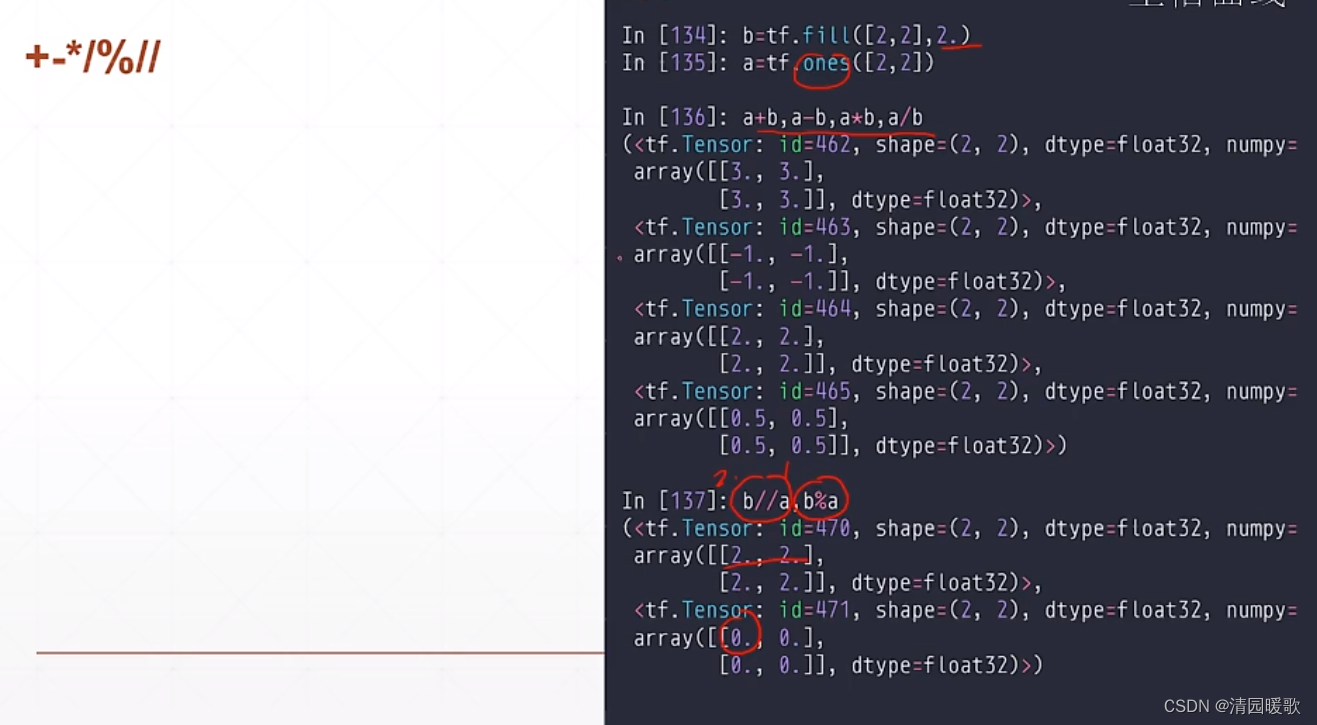
6.1 加减乘除(+,-,*,/,%,//)
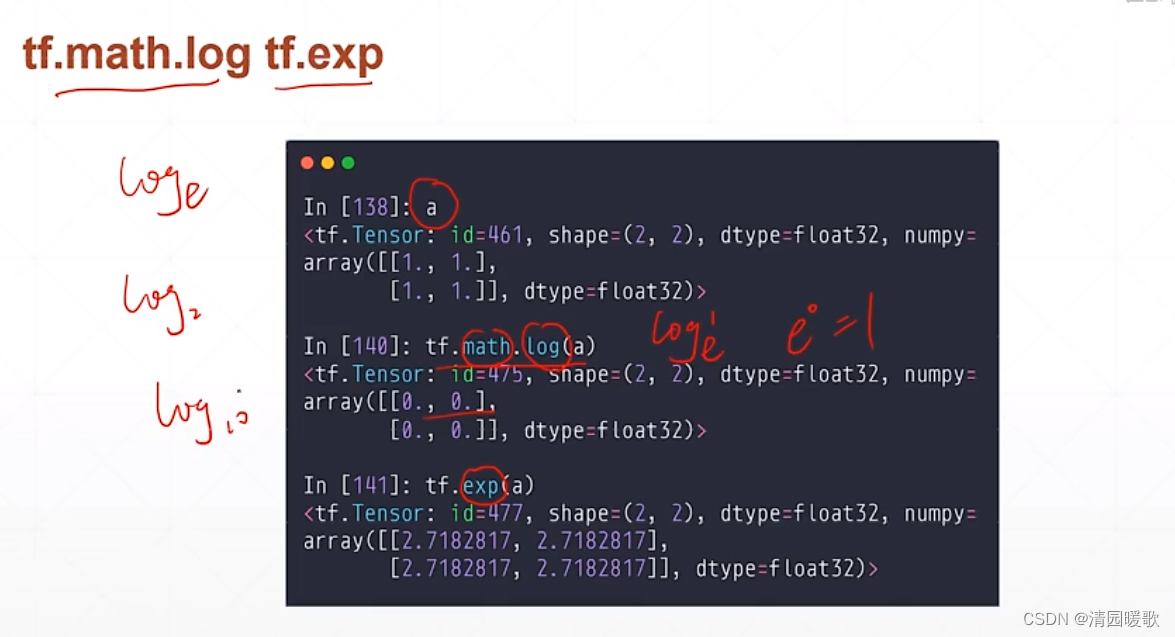
6.2 tf.math.log , tf.exp
tf.math.log 是 loge ,即 ln,没有log2,log10之类的
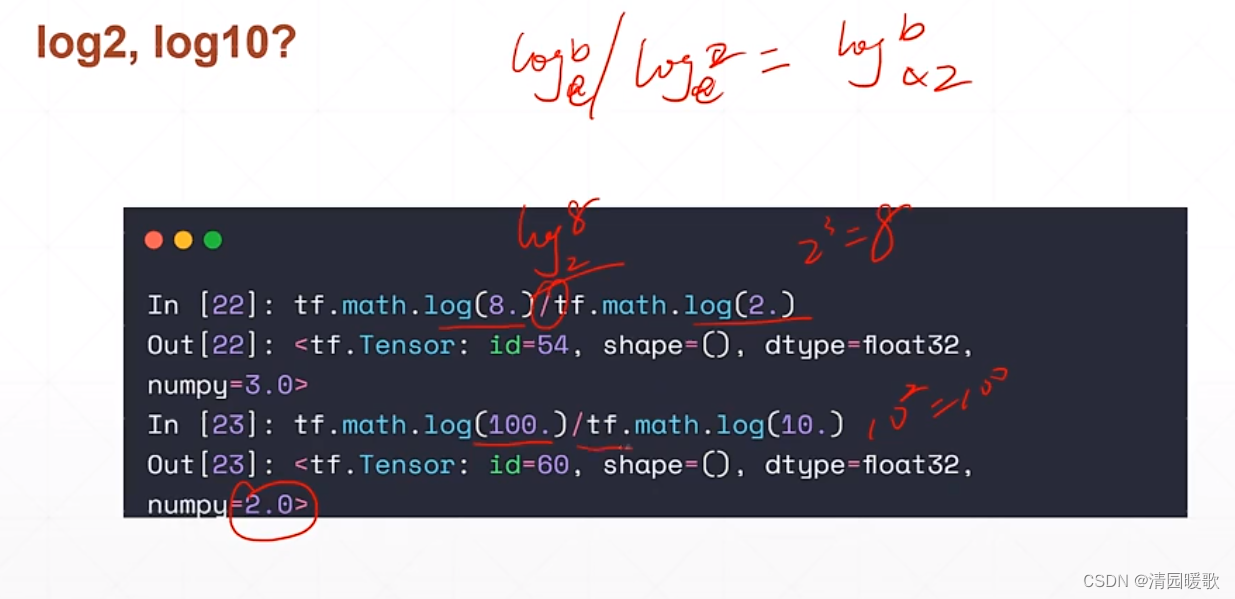
所以 log2 要变一下得到,根据 log_a^b / log_a^c = log_c^b
即 ln8 / ln2 = log_2^8 = 3
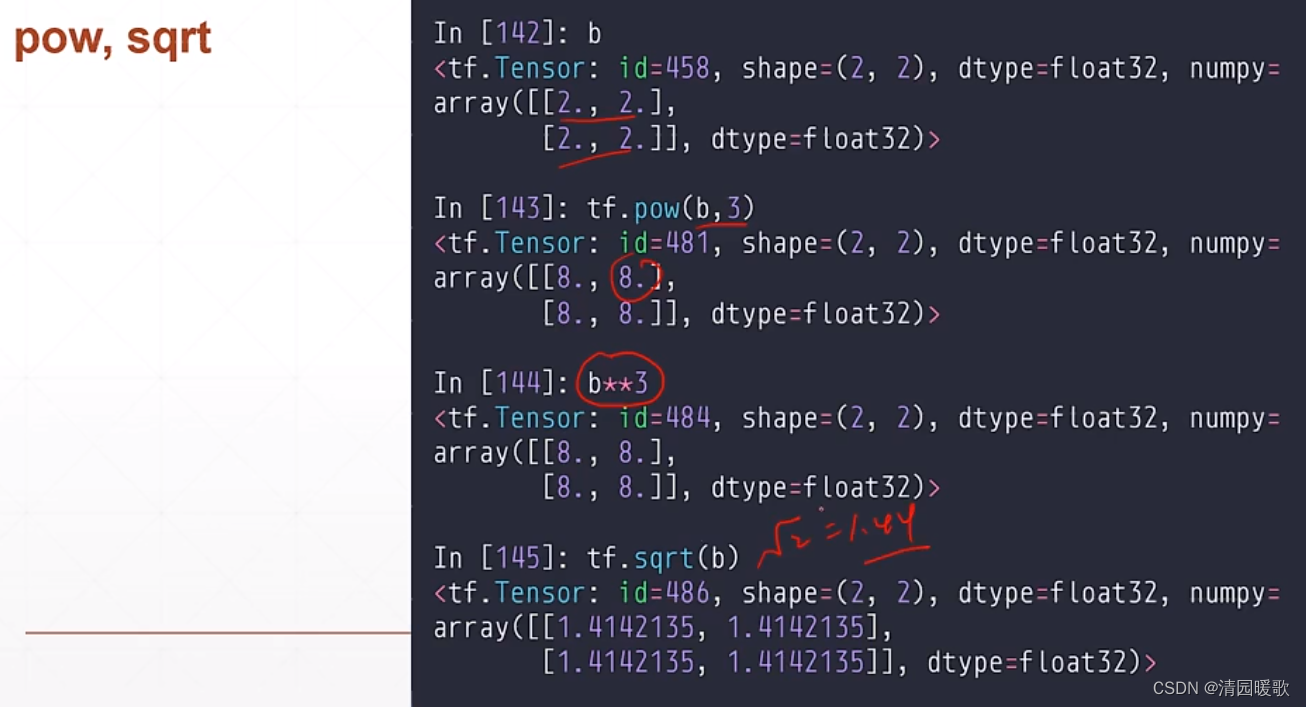
6.3 平方,开方(pow,sqrt)
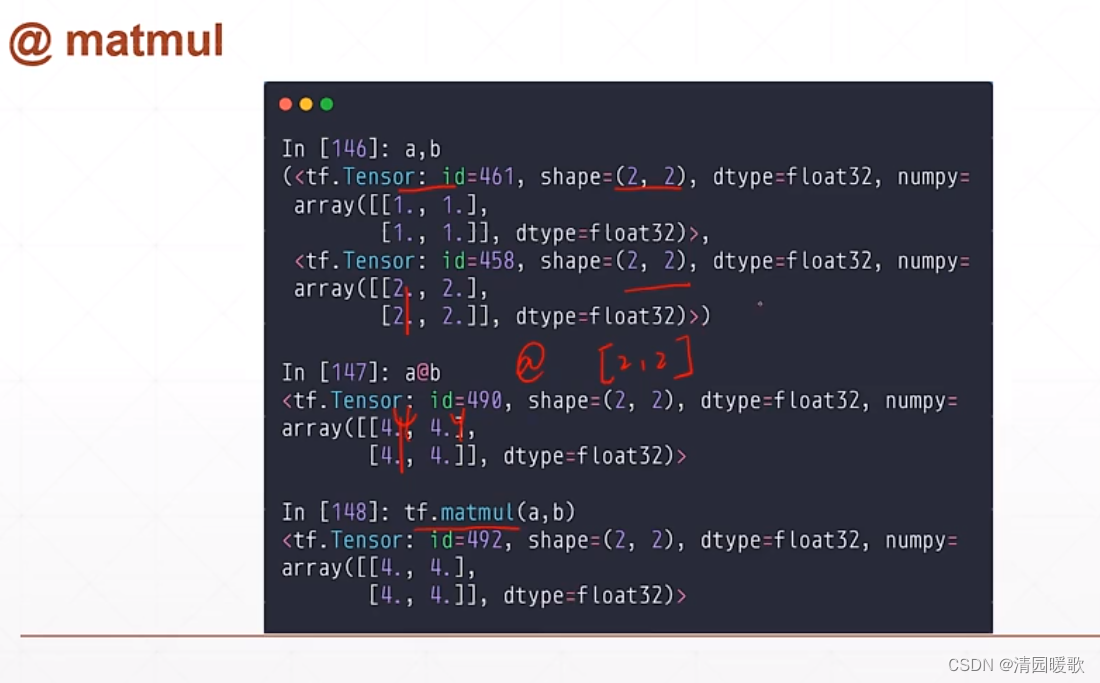
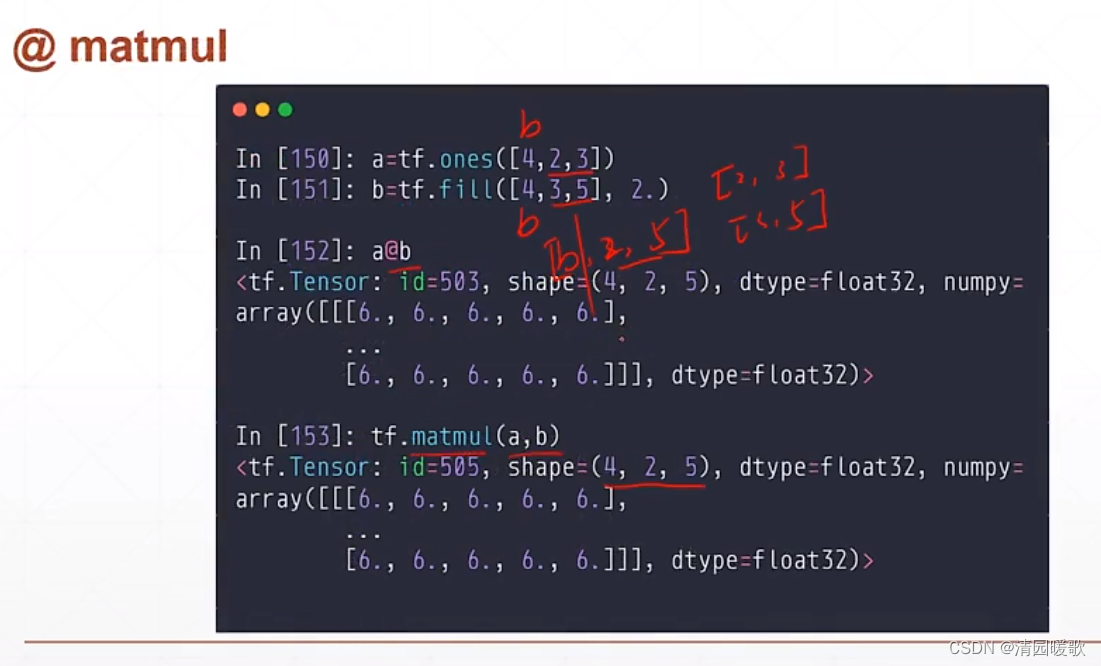
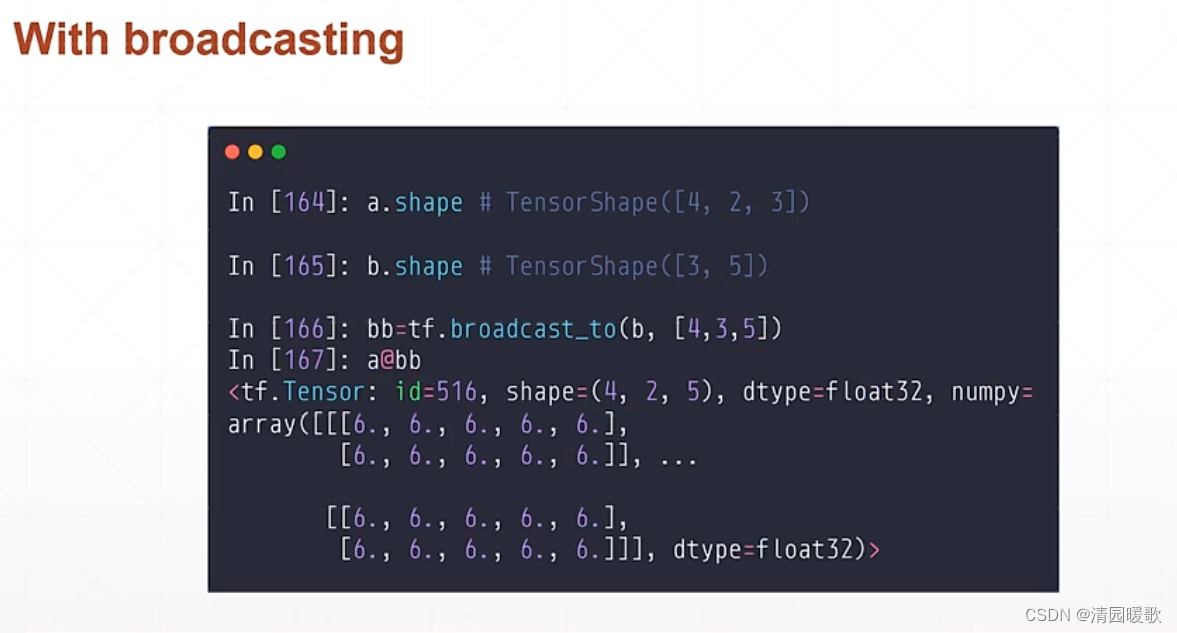
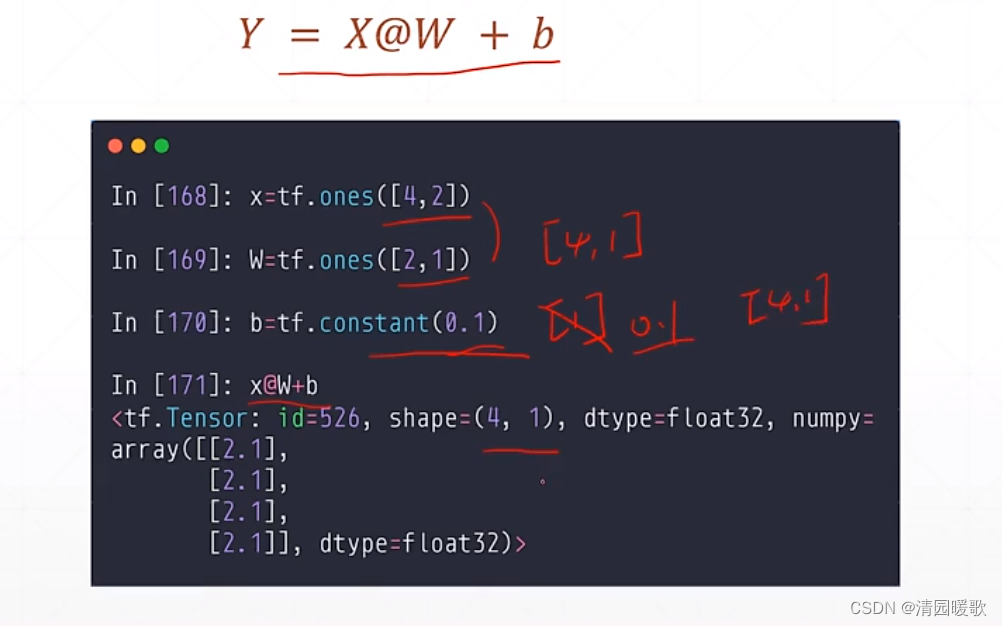
6.4 矩阵相乘(@ matmul)

七、前向传播实战使用


如何屏蔽这些无用的信息呢?

使用 os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
0是全打印,2是只打印error的信息,这些信息是CPP打印出来的
7.1 代码
具体原理已省略
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
# x: [60k, 28, 28]
# y: [60k]
(x, y), _ = datasets.mnist.load_data()
# x: [2~255] => [0~1.]
x = tf.convert_to_tensor(x, dtype=tf.float32) / 255.
y = tf.convert_to_tensor(y, dtype=tf.int32)
print('tensorflow版本号:', tf.__version__)
print(x.shape, y.shape, x.dtype, y.dtype)
print(tf.reduce_min(x), tf.reduce_max(x))
print(tf.reduce_min(y), tf.reduce_max(y))
train_db = tf.data.Dataset.from_tensor_slices((x,y)).batch(128)
train_iter = iter(train_db)
sample = next(train_iter)
print('batch:', sample[0].shape, sample[1].shape)
# [b, 784] => [b, 256] => [b, 128] => [b, 10]
# [dim_in, dim_out], [dim_out]
# stddev = 0.1 方差变为0.1
w1 = tf.Variable(tf.random.truncated_normal([784, 256], stddev=0.1)) # truncated_normal 创建一个正态分布的
b1 = tf.Variable(tf.zeros([256]))
w2 = tf.Variable(tf.random.truncated_normal([256, 128], stddev=0.1)) # truncated_normal 创建一个正态分布的
b2 = tf.Variable(tf.zeros([128]))
w3 = tf.Variable(tf.random.truncated_normal([128, 10], stddev=0.1)) # truncated_normal 创建一个正态分布的
b3 = tf.Variable(tf.zeros([10]))
lr = 1e-3 # 0.001 = 10^-3
for epoch in range(10): # iterate db for 10 对整个数据集迭代10次
for step, (x,y) in enumerate(train_db): # for every batch对数据集每个batch
# x: [128, 28, 28]
# y: [128]
# [b, 28, 28] => [b, 28*28]
x = tf.reshape(x, [-1, 28*28])
with tf.GradientTape() as tape: # 默认追踪的是 tf.Variable 类型,所以在上面 w,b 的前面加上 tf.Variable
# 这两个类型是一样的,只是tf.Variable会默认的追踪梯度的信息
# x: [b, 28*28]
# h1 = x@w1 + b1
# [b, 784]@[784, 256] + [256] => [b, 256] + [256] => [b, 256] + [b, 256]
# h1 = x@w1 + tf.broadcast_to(b1, [x.shape[0], 256]) # 这样多此一举,因为会自动转化
h1 = x@w1 + b1
h1 = tf.nn.relu(h1)
# [b, 256] => [b, 128]
h2 = h1@w2 + b2
h2 = tf.nn.relu(h2)
# [b, 128] => [b, 10]
out = h2@w3 + b3
# compute loss
# out: [b, 10]
# y: [b] => [b, 10]
y_onehot = tf.one_hot(y, depth=10) # 只需在 loss 计算之前 onehot 就行
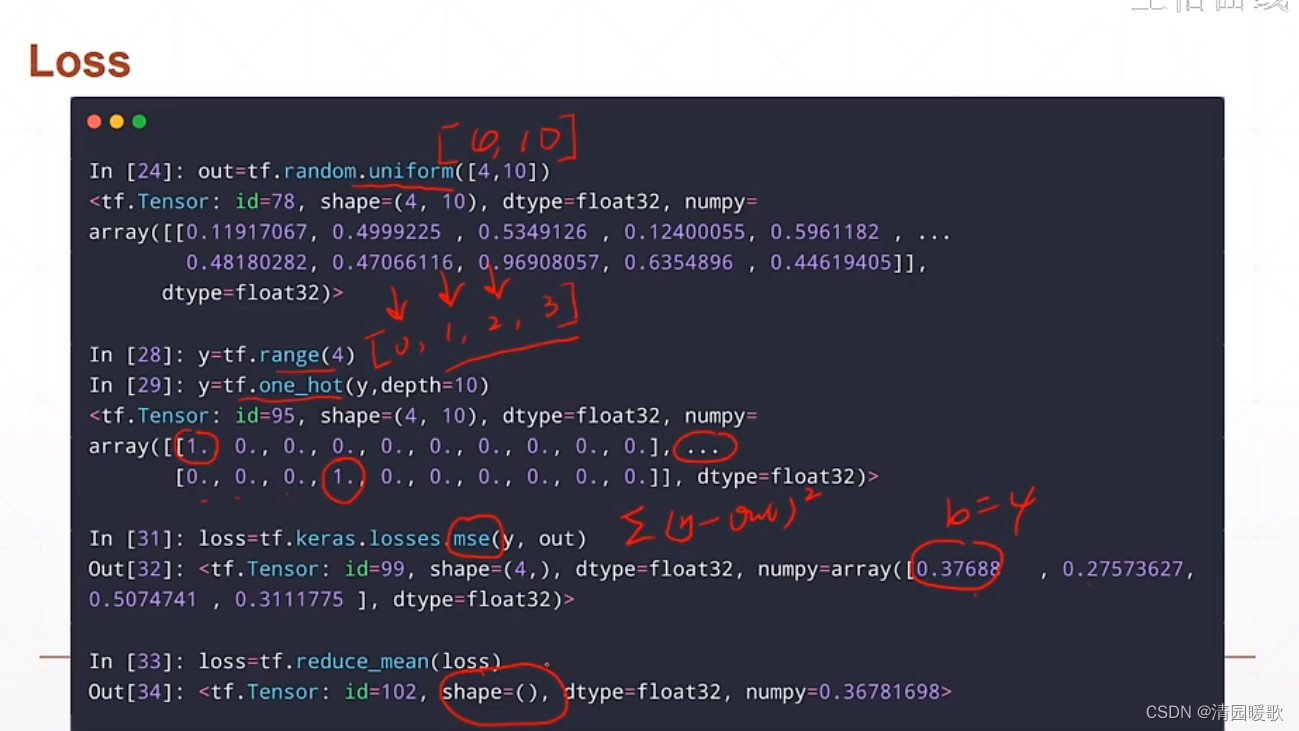
# mse = mean(sum(y-out)^2)
# [b, 10]
loss = tf.square(y_onehot - out)
# mean: scalar
loss = tf.reduce_mean(loss)
# compute gradients
grads = tape.gradient(loss, [w1, b1, w2, b2, w3, b3])
# w1 = w1 - lr * w1 grad
w1.assign_sub(lr * grads[0])
b1.assign_sub(lr * grads[1])
w2.assign_sub(lr * grads[2])
b2.assign_sub(lr * grads[3])
w3.assign_sub(lr * grads[4])
b3.assign_sub(lr * grads[5])
# 此时出现 loss:nan 梯度爆炸的情况,要在w,b初始化时,给一个范围,stddev = 0.1
# w1 = w1 - lr * grads[0] # 对 w1 的求导结果,此时计算返回的是 tf.Tensor 类型,不是 tf.Variable 类型了
# # 所以要进行原地更新的操作,使用 w1.assign_sub(lr * grads[0]),使引用保持不变
# b1 = w1 - lr * grads[1]
# w2 = w2 - lr * grads[2]
# b2 = b2 - lr * grads[3]
# w3 = w3 - lr * grads[4]
# b3 = b3 - lr * grads[5]
if step % 100 == 0:
print(epoch, step, 'loss:', float(loss)) # 美100次打印一次
















 1112
1112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











