







一、部署自己的 AI模型
参考:
【嵌入式AI开发&Maxim篇四】美信Maxim78000Evaluation Kit AI实战开发二
开发环境搭建->AI模型搭建->模型训练->模型量化->模型转换->模型部署
但过程中使用的代码都是提供的示例。
进入目录检查cuda
cd $AI_PROJECT_ROOT
cd ai8x-training
./check_cuda.py
二、模型搭建
我们以指纹识别模型为例开发自己的AI模型,指纹识别数据集包含100个类别,大小为260*260,训练集30张,测试集5张。
2.1 数据集处理与加载
首先进入datasets文件夹,参考其他数据集的加载方式,创建新的dataloader文件 fpr2.py。如下:
"""
figerprint-recognition Dataset
"""
import os
import numpy as np
import torchvision
from torchvision import transforms
from PIL import Image
import ai8x
import torch
from torch.utils.data import Dataset
class FVCDataset(Dataset):
def __init__(self, data_file, transform=None, dir=None):
'''
data_file: 指纹的.npy格式数据
label_file:指纹的.npy格式标签
'''
# 所有图片的绝对路径
self.datas=os.listdir(data_file)
self.transform = transform
self.dir = dir
def __getitem__(self, index):
img_path=self.datas[index]
data = 0
path='/home/xb/Maxim/ai8x-training/data/fpr2/fingerprint/fingerprint/'+self.dir+img_path
data=Image.open(path)
# # data=Image.open(img_path)
# if self.load_train:
# path='/home/xb/Maxim/ai8x-training/data/fpr2/fingerprint/fingerprint/'+'train/'+img_path
# data=Image.open(path)
# # data=np.array(data)
# # data = Image.fromarray(data)
# if self.load_test:
# path='/home/xb/Maxim/ai8x-training/data/fpr2/fingerprint/fingerprint/'+'test/'+img_path
# data=Image.open(path)
# # data=np.array(data)
# # data = Image.fromarray(data)
label, _= img_path.split('_')
label=int(label)-1
if self.transform is not None:
# data = torch.tensor(np.array(data))
data = self.transform(data).repeat(3,1,1)
# print('data:',data.shape)
# data = self.transform(data).unsqueeze(0).repeat(3, 1, 1)
# data=np.array(data)
# data = Image.fromarray(data)
# print('data:',data.shape)
# return torch.from_numpy(np.array(data)), torch.from_numpy(np.array(label))
return torch.from_numpy(np.array(data)), torch.from_numpy(np.array(label))
def __len__(self):
return len(self.datas)
def fpr_get_datasets(data, load_train=True, load_test=True):
"""
Load the figerprint-recognition dataset.
The original training dataset is split into training and validation sets (code is
inspired by https://github.com/ZhugeKongan/Fingerprint-Recognition-pytorch-for-mcu).
By default we use a 90:10 (45K:5K) training:validation split.
The output of torchvision datasets are PIL Image images of range [0, 1].
"""
(data_dir, args) = data
#data_dir='/disks/disk2/lishengyan/dataset/fingerprint/'
data_dir='/home/xb/Maxim/ai8x-training/data/fpr2/fingerprint/fingerprint/'
if load_train:
data_path =data_dir+'train/'
dir = 'train/'
train_transform = transforms.Compose([
# transforms.RandomCrop(32, padding=4),
# transforms.RandomHorizontalFlip(),
transforms.Resize((64,64)),
transforms.ToTensor(),
ai8x.normalize(args=args)
])
train_dataset = FVCDataset(data_path,train_transform,dir)
else:
train_dataset = None
if load_test:
data_path = data_dir + 'test/'
dir='test/'
test_transform = transforms.Compose([
transforms.Resize((64,64)),
transforms.ToTensor(),
ai8x.normalize(args=args)
])
test_dataset = FVCDataset(data_path,test_transform,dir)
if args.truncate_testset:
test_dataset.data = test_dataset.data[:1]
else:
test_dataset = None
return train_dataset, test_dataset
datasets = [
{
'name': 'fpr2',
'input': (3, 64, 64),
'output': ('F1', 'F2', 'F3', 'F4', 'F5', 'F6', 'F7', 'F8','F9', 'F10','F11', 'F12', 'F13', 'F14', 'F15', 'F16', 'F17', 'F18','F19', 'F20',
'F21', 'F22', 'F23', 'F24', 'F25', 'F26', 'F27', 'F28','F29', 'F30','F31', 'F32', 'F33', 'F34', 'F35', 'F36', 'F37', 'F38','F39', 'F40',
'F41', 'F42', 'F43', 'F44', 'F45', 'F46', 'F47', 'F48','F49', 'F50','F51', 'F52', 'F53', 'F54', 'F55', 'F56', 'F57', 'F58','F59', 'F60',
'F61', 'F62', 'F63', 'F64', 'F65', 'F66', 'F67', 'F68','F69', 'F70','F71', 'F72', 'F73', 'F74', 'F75', 'F76', 'F77', 'F78','F79', 'F80',
'F81', 'F82', 'F83', 'F84', 'F85', 'F86', 'F87', 'F88','F89', 'F90','F91', 'F92', 'F93', 'F94', 'F95', 'F96', 'F97', 'F98','F99', 'F100'
),
'loader': fpr_get_datasets,
},
]其中注意修改:
data_dir='/home/xb/Maxim/ai8x-training/data/fpr2/fingerprint/fingerprint/'data_dir 为你数据集的绝对路径
train 和 test 的数据路径作了修改,多传入类一个 dir 的参数
data_path =data_dir+'train/'
dir = 'train/'
data_path = data_dir + 'test/'
dir='test/'在 __getitem__ 中继续修改添加,此举是为了以绝对路径打开数据集图片
img_path=self.datas[index]
data = 0
path='/home/xb/Maxim/ai8x-training/data/fpr2/fingerprint/fingerprint/'+self.dir+img_path
data=Image.open(path)此外
datasets = [
{
'name': 'fpr2',
'input': (3, 64, 64),
'output': ('F1', 'F2', 'F3', 'F4', 'F5', 'F6', 'F7', 'F8','F9', 'F10','F11', 'F12', 'F13', 'F14', 'F15', 'F16', 'F17', 'F18','F19', 'F20',
'F21', 'F22', 'F23', 'F24', 'F25', 'F26', 'F27', 'F28','F29', 'F30','F31', 'F32', 'F33', 'F34', 'F35', 'F36', 'F37', 'F38','F39', 'F40',
'F41', 'F42', 'F43', 'F44', 'F45', 'F46', 'F47', 'F48','F49', 'F50','F51', 'F52', 'F53', 'F54', 'F55', 'F56', 'F57', 'F58','F59', 'F60',
'F61', 'F62', 'F63', 'F64', 'F65', 'F66', 'F67', 'F68','F69', 'F70','F71', 'F72', 'F73', 'F74', 'F75', 'F76', 'F77', 'F78','F79', 'F80',
'F81', 'F82', 'F83', 'F84', 'F85', 'F86', 'F87', 'F88','F89', 'F90','F91', 'F92', 'F93', 'F94', 'F95', 'F96', 'F97', 'F98','F99', 'F100'
),
'loader': fpr_get_datasets,
},
]上面代码修改 'name':'fpr2' ,因为我的文件名修改成了 fpr2.py
2.2 深度学习模型搭建
虽然美信也是基于pytorch进行模型开发部署,但使用的CNN模板库都已经重写过了,添加了支持量化和max78000部署的设计。因此,开发自己的AI模型首先需要根据美信自定义的 PyTorch 类重写AI模型。任何设计为在 MAX78000 上运行的模型都应该使用这些类。ai8x.py与默认类torch.nn.Module有三个主要变化:
-
额外的“融合”操作,用于模型中的池化和激活层;
-
与硬件匹配的舍入和裁剪;
-
支持量化操作(使用
-8命令行参数时)。
为了方便比较,我们设计一个简化的resnet模型,新建model/ai85net-fpr2.py文件如下:(注意:使用ai8x库搭建模型,分类层前建议不要用池化层,会造成无法收敛)
import torch
import torch.nn as nn
import ai8x
class AI85Net_FPR(nn.Module):
"""
5-Layer CNN that uses max parameters in AI84
"""
def __init__(self, num_classes=100, num_channels=1,dimensions=(64, 64), bias=False, **kwargs):
super().__init__()
self.conv1 = ai8x.FusedConv2dReLU(num_channels, 16, 3, stride=1, padding=1, bias=bias,
**kwargs)
self.conv2 = ai8x.FusedConv2dReLU(16, 20, 3, stride=1, padding=1, bias=bias, **kwargs)
self.conv3 = ai8x.FusedConv2dReLU(20, 20, 3, stride=1, padding=1, bias=bias, **kwargs)
self.conv4 = ai8x.FusedConv2dReLU(20, 20, 3, stride=1, padding=1, bias=bias, **kwargs)
self.resid1 = ai8x.Add()
self.conv5 = ai8x.FusedMaxPoolConv2dReLU(20, 20, 3, pool_size=2, pool_stride=2,
stride=1, padding=1, bias=bias, **kwargs)
self.conv6 = ai8x.FusedConv2dReLU(20, 20, 3, stride=1, padding=1, bias=bias, **kwargs)
self.resid2 = ai8x.Add()
self.conv7 = ai8x.FusedConv2dReLU(20, 44, 3, stride=1, padding=1, bias=bias, **kwargs)
self.conv8 = ai8x.FusedMaxPoolConv2dReLU(44, 48, 3, pool_size=2, pool_stride=2,
stride=1, padding=1, bias=bias, **kwargs)
self.conv9 = ai8x.FusedConv2dReLU(48, 48, 3, stride=1, padding=1, bias=bias, **kwargs)
self.resid3 = ai8x.Add()
self.conv10 = ai8x.FusedMaxPoolConv2dReLU(48, 96, 3, pool_size=2, pool_stride=2,
stride=1, padding=1, bias=bias, **kwargs)
self.conv11 = ai8x.FusedAvgPoolConv2dReLU(96, 32, 1, pool_size=2, pool_stride=2,
padding=0, bias=bias, **kwargs)
self.fc = ai8x.Linear(32*4*4, num_classes, bias=True, wide=True, **kwargs)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def forward(self, x): # pylint: disable=arguments-differ
"""Forward prop"""
#print(x.shape)
#x.repeat(1,3,1,1)
x = self.conv1(x) # 16x32x32
x_res = self.conv2(x) # 20x32x32
x = self.conv3(x_res) # 20x32x32
x = self.resid1(x, x_res) # 20x32x32
x = self.conv4(x) # 20x32x32
x_res = self.conv5(x) # 20x16x16
x = self.conv6(x_res) # 20x16x16
x = self.resid2(x, x_res) # 20x16x16
x = self.conv7(x) # 44x16x16
x_res = self.conv8(x) # 48x8x8
x = self.conv9(x_res) # 48x8x8
x = self.resid3(x, x_res) # 48x8x8
x = self.conv10(x) # 96x4x4
x = self.conv11(x) # 512x2x2
# print(x.size())
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def ai85net_fpr2(pretrained=False, **kwargs):
"""
Constructs a AI85Net5 model.
"""
assert not pretrained
return AI85Net_FPR(**kwargs)
models = [
{
'name': 'ai85net_fpr2',
'min_input': 1,
'dim': 2,
},
]此段只修改下列函数的函数名为 ai85net_fpr2,与文件名一致
def ai85net_fpr2(pretrained=False, **kwargs):
"""
Constructs a AI85Net5 model.
"""
assert not pretrained
return AI85Net_FPR(**kwargs)下列中,'name': 'ai85net_fpr2',与文件名一致
models = [
{
'name': 'ai85net_fpr2',
'min_input': 1,
'dim': 2,
},
]2.3 修改学习率调整策略
新建 policies/schedule-fpr2.yaml 文件,写入
lr_schedulers:
training_lr:
class: MultiStepLR
milestones: [80, 140]
gamma: 0.2
policies:
- lr_scheduler:
instance_name: training_lr
starting_epoch: 0
ending_epoch: 200
frequency: 12.4 开始训练
新建train函数的运行命令scrips/train-fpr2.sh。注意:训练这种量化模型,参数优化很重要,SGD优化器需要适合的超参数设置,因此对于越复杂的模型,建议使用Adam优化器,并初始化较低的学习率。
#!/bin/sh
python train.py --epochs 200 --optimizer Adam --lr 0.001 --batch-size 64 --gpus 0 --deterministic --compress policies/schedule-fpr2.yaml --model ai85net_fpr2 --dataset fpr2 --param-hist --pr-curves --embedding --device MAX78000 "$@"修改的部分 policies/schedule-fpr2.yaml --model ai85net_fpr2 --dataset fpr2
运行训练:
bash scripts/train-fpr2.sh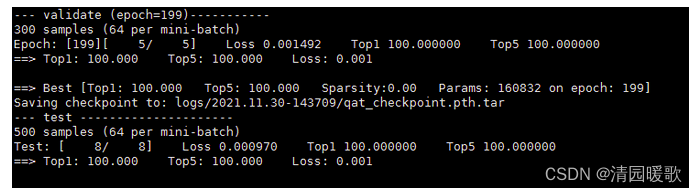
模型大小为1.89M。为进行对比,使用torch.nn.Module构建的模型:
class AI85Net_FPR(nn.Module):
"""
5-Layer CNN that uses max parameters in AI84
"""
def __init__(self, num_classes=10, num_channels=1, dimensions=(64, 64),
planes=32, pool=2, fc_inputs=256, bias=False, **kwargs):
super().__init__()
# Limits
assert planes + num_channels <= ai8x.dev.WEIGHT_INPUTS
assert planes + fc_inputs <= ai8x.dev.WEIGHT_DEPTH-1
# Keep track of image dimensions so one constructor works for all image sizes
self.conv1 = nn.Conv2d(num_channels, 16, kernel_size=3, stride=1,padding=1, bias=False)
self.conv2 = nn.Conv2d(16, 20, kernel_size=3, stride=1, padding=1, bias=False)
self.conv3 = nn.Conv2d(20, 20, kernel_size=3, stride=1, padding=1, bias=False)
self.conv4 = nn.Conv2d(20,20, kernel_size=3, stride=1, padding=1, bias=False)
# self.resid1 = nn.Conv2d(20, 20, kernel_size=3, stride=1, padding=1, bias=False)
self.conv5 = nn.Conv2d(20, 20, kernel_size=3, stride=1, padding=1, bias=False)
self.pool5 = nn.MaxPool2d(2, 2)
self.conv6 = nn.Conv2d(20, 20, kernel_size=3, stride=1, padding=1, bias=False)
# self.resid2 = nn.Conv2d(20, 20, kernel_size=3, stride=2, padding=1, bias=False)
self.conv7 = nn.Conv2d(20, 44, kernel_size=3, stride=1, padding=1, bias=False)
self.conv8 = nn.Conv2d(44, 48, kernel_size=3, stride=1, padding=1, bias=False)
self.pool8 = nn.MaxPool2d(2, 2)
self.conv9 = nn.Conv2d(48, 48, kernel_size=3, stride=1, padding=1, bias=False)
# self.resid3 = nn.Conv2d(48, 48, kernel_size=3, stride=2, padding=1, bias=False)
self.conv10 = nn.Conv2d(48, 96, kernel_size=3, stride=1, padding=1, bias=False)
self.pool10 = nn.MaxPool2d(2, 2)
self.conv11 = nn.Conv2d(96, 32, kernel_size=1, stride=1, padding=0, bias=False)
self.pool11 = nn.AvgPool2d(2, 2)
self.fc = nn.Linear(32*4*4, num_classes, bias=True)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def forward(self, x): # pylint: disable=arguments-differ
"""Forward prop"""
x = F.relu(self.conv1(x))
x_res = F.relu(self.conv2(x))
x = F.relu(self.conv3(x_res))
x= x + x_res
x = F.relu(self.conv4(x))
x_res = self.pool5(F.relu(self.conv5(x)))
x = F.relu(self.conv6(x_res))
x= x + x_res
x = F.relu(self.conv7(x))
x_res = self.pool8(F.relu(self.conv8(x)))
x = F.relu(self.conv9(x_res))
x = x + x_res
x = self.pool10(F.relu(self.conv10(x)))
x = self.pool11(F.relu(self.conv11(x)))
# print(x.size())
x = x.view(x.size(0), -1)
x = self.fc(x)
return x运行结果为:
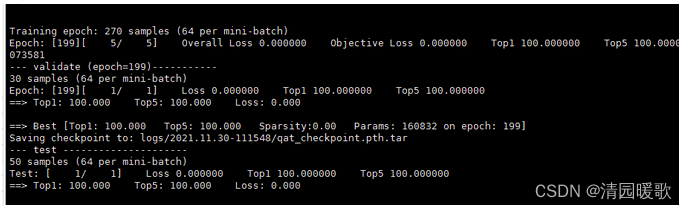
模型大小1.85M。且明显比ai8x收敛快。接着,我们评估模型量化的结果。
三、模型量化
模型训练完后,生成的模型文件保存在ai8x-training/logs下
量化有两种主要方法——量化感知训练和训练后量化。量化前我们先将步骤2保存的两个模型文件移动到ai8x-synthesis目录下,可以把四个文件就复制到ai8x-synthesis
这里为新建了一个 self_proj/fpr2 的文件夹,把qat和朴素量化的分别放到了里面
因为nn库的模型不支持量化,这里就没有跑nn的模型
3.1 量化感知训练(QAT)
量化感知训练只需要下面两个文件,在 ai8x-synthesis 下执行命令
cp ../ai8x-training/logs/2023.09.13-235136/best.pth.tar self_proj/fpr2/best.pth.tar
cp ../ai8x-training/logs/2023.09.13-235136/qat_best.pth.tar self_proj/fpr2/qat_best.pth.tar 量化感知训练是性能更好的方法。它默认启用。QAT 在训练期间学习有助于量化的其他参数。需要quantize.py.的输入 checkpoint:
要么是qat_best.pth.tar,最好的 QAT 时期的 checkpoint;
要么是qat_checkpoint.pth.tar,最终的 QAT 时期的 checkpoint。
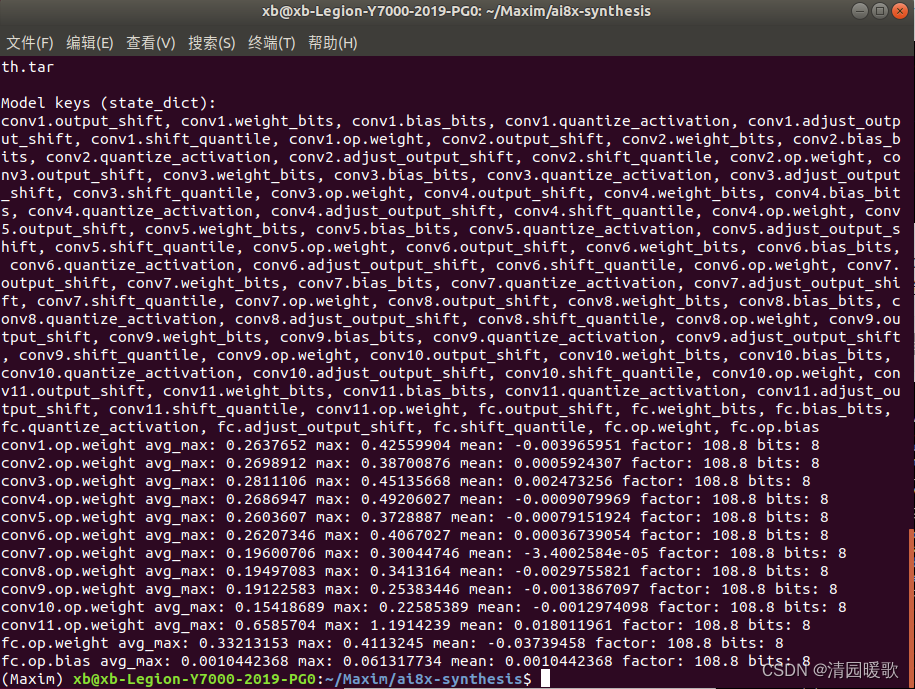
ai8x模型量化:量化后1.88M
./quantize.py self_proj/fpr2/qat/qat_best.pth.tar self_proj/fpr2/qat/qat_best-ai8x-q.pth.tar --device MAX78000 -v "$@"
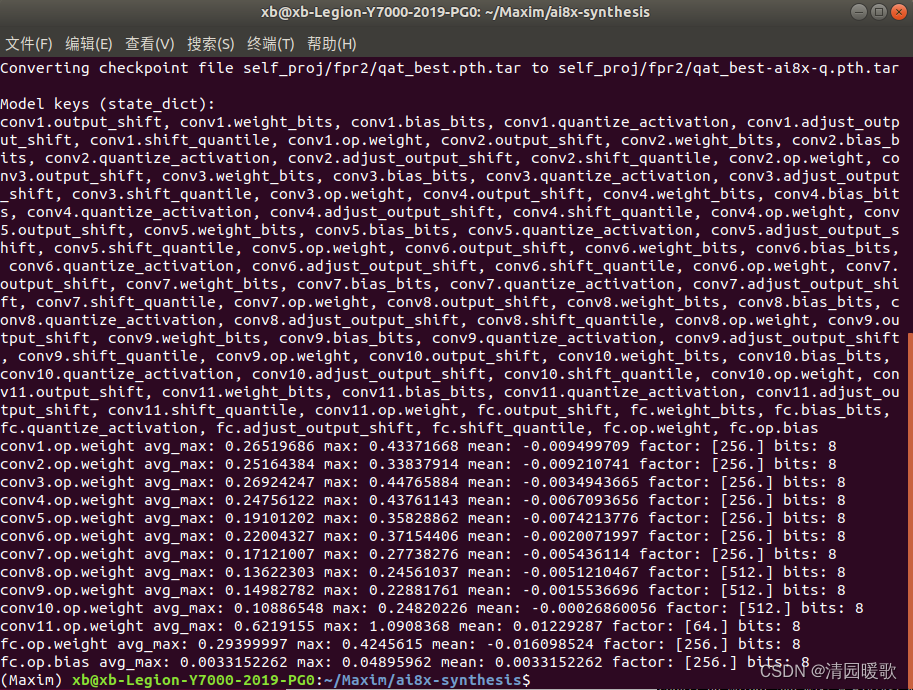
3.2 训练后量化
这种方法也称为“朴素量化”。需在训练时指定--qat-policy None。
虽然在quantize.py 中实现了几种裁剪方法,但根据实验结果,使用简单的固定比例因子进行裁剪效果最好。如a--scale 0.85。quantize.py用于训练后量化的输入检查点通常是best.pth.tar,最佳时期的检查点,或checkpoint.pth.tar,最终时期的检查点。
./quantize.py self_proj/fpr2/simple/best.pth.tar self_proj/fpr2/simple/best-ai8x-q.pth.tar --device MAX78000 --scale 0.85 --clip-method SCALE -v "$@"
该quantize.py软件具有以下重要的命令行参数:
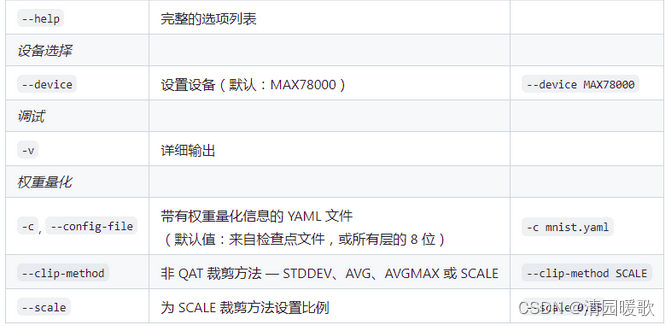
可以直接命令行输入执行
也可以写到 scripts/quantize_fpr2.sh,quantize_fpr2.sh 是新建的
#!/bin/sh
python quantize.py self_proj/fpr2/simple/best.pth.tar self_proj/fpr2/simple/best-ai8x-q.pth.tar --device MAX78000 --scale 0.85 --clip-method SCALE -v "$@"执行
scripts/quantize_fpr2.sh3.3 其他量化方法
https://github.com/pytorch/glow/blob/master/docs/Quantization.md、
https://github.com/ARM-software/ML-examples/tree/master/cmsisnn-cifar10、
https://github.com/ARM-software/ML-KWS-for-MCU/blob/master/Deployment/Quant_guide.md或 Distiller 的方法
四、模型评估
切换到训练项目
cd ../ai8x-training创建一个评估脚本并修改它:
cp scripts/evaluate_mnist.sh scripts/evaluate_fpr2.sh
vim scripts/evaluate_fpr2.shpython ./train.py --model ai85net_fpr2 --dataset fpr2 --confusion --evaluate --exp-load-weights-from ../ai8x-synthesis/self_proj/fpr2/qat/qat_best.pth.tar -8 --device MAX78000 "$@"
运行评估:
scripts/evaluate_fpr2.sh若遇到以下量化前后精度差别巨大问题,参考上篇文章解决:【嵌入式AI开发&美信问题篇一】Maxim78000 AI实战开发-训练与测试评估精度差距大
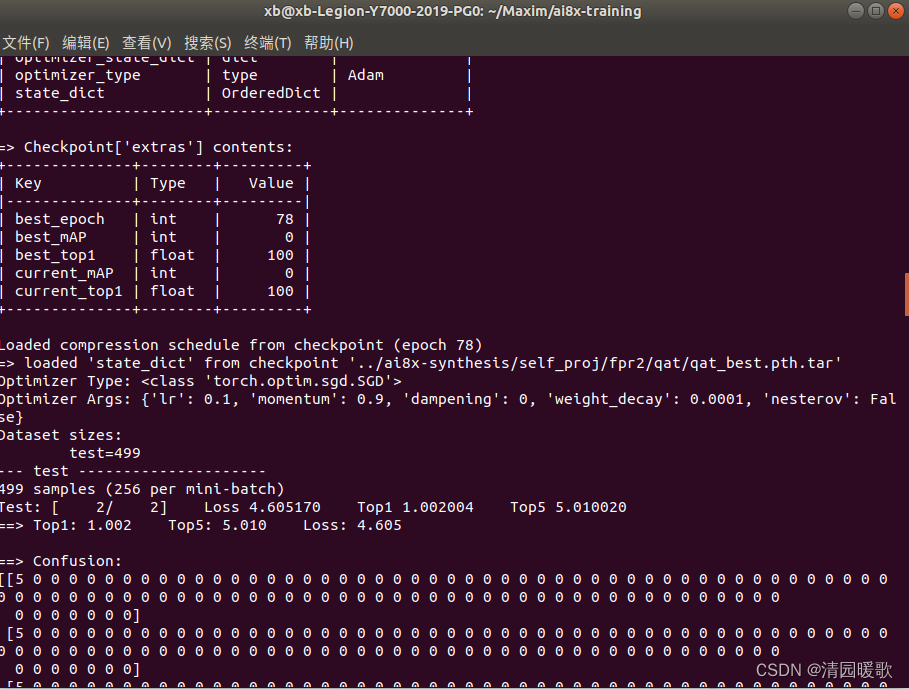
修改完成后,进行评估。
先评估没有经过量化的模型:可以看到,不支持不量化就进行评估。
python ./train.py --model ai85net_fpr2 --dataset fpr2 --confusion --evaluate --exp-load-weights-from ../ai8x-synthesis/self_proj/fpr2/qat/qat_best.pth.tar -8 --device MAX78000 "$@"
scripts/evaluate_fpr2.sh或者直接执行命令
./train.py --model ai85net_fpr2 --dataset fpr2 --confusion --evaluate --exp-load-weights-from ../ai8x-synthesis/self_proj/fpr2/qat/qat_best.pth.tar -8 --device MAX78000 "$@"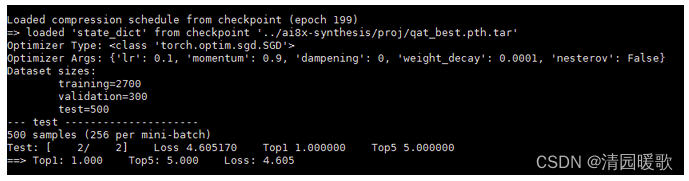
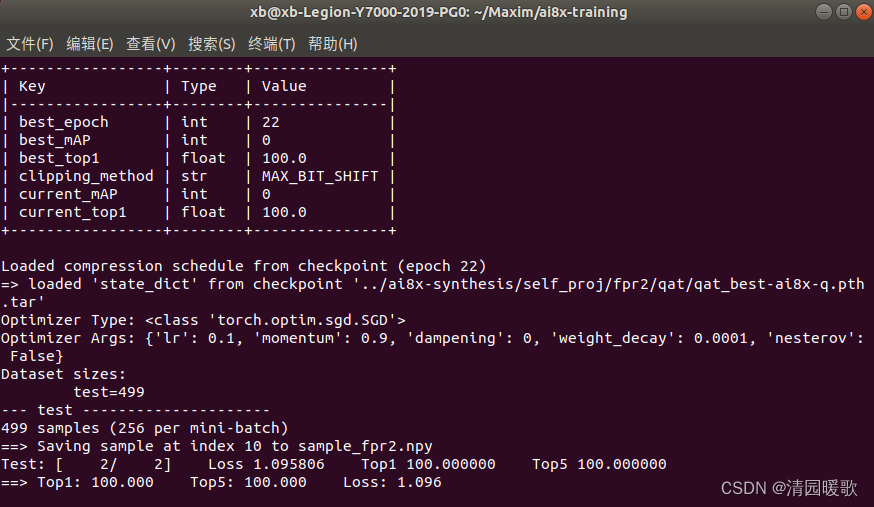
然后看看使用感知训练量化的ai8x模型:100%
python ./train.py --model ai85net_fpr2 --dataset fpr2 --evaluate --exp-load-weights-from ../ai8x-synthesis/self_proj/fpr2/qat/qat_best-ai8x-q.pth.tar -8 --device MAX78000 "$@"scripts/evaluate_fpr2.sh或者直接执行命令
./train.py --model ai85net_fpr2 --dataset fpr2 --evaluate --exp-load-weights-from ../ai8x-synthesis/self_proj/fpr2/qat/qat_best-ai8x-q.pth.tar -8 --device MAX78000 "$@"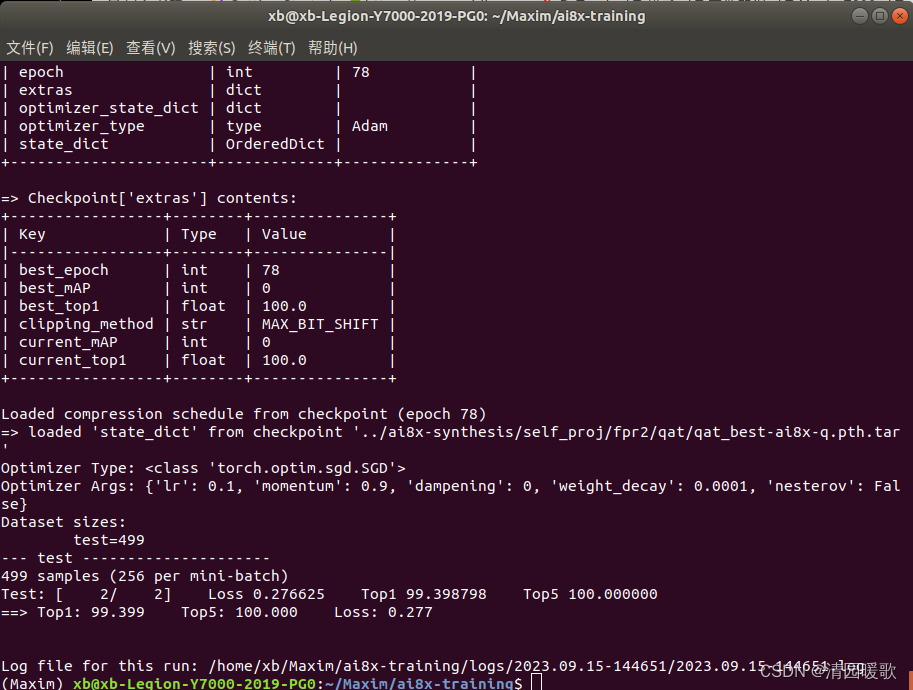
然后测试训练后量化的ai8x模型:
--scale 0.85时
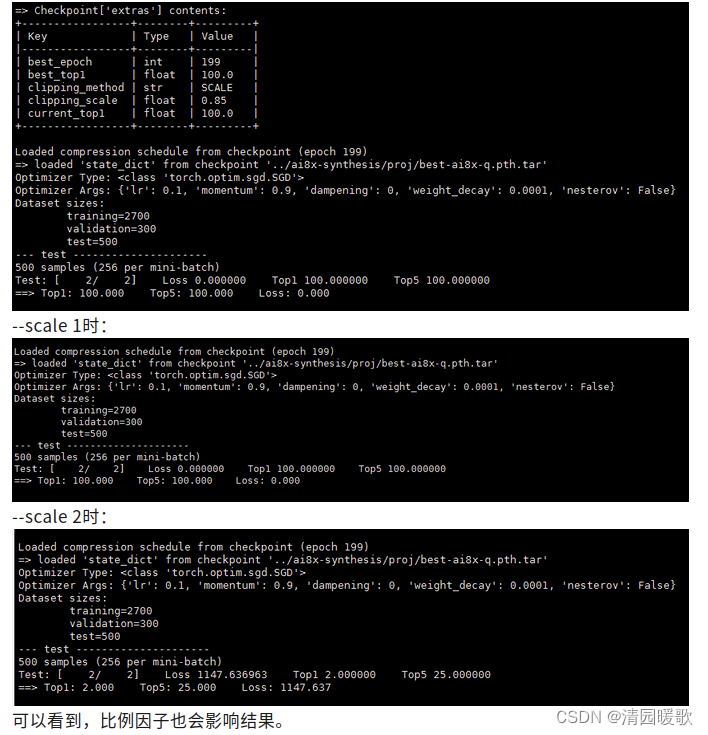
五、模型转换
该部分与上篇是一样的,配置文件位于ai8x-synthesis/networks文件夹下,新建我们模型的配置文件,根据示例格式编辑,如下:
https://github.com/MaximIntegratedAI/MaximAI_Documentation/blob/master/Guides/YAML%20Quickstart.md
新建 fpr2-chw.yaml
# CHW (big data) configuration for MNIST
arch: ai85net_fpr2
dataset: fpr2
# Define layer parameters in order of the layer sequence
layers:
# Layer 0
- out_offset: 0x2000
processors: 0x0000000000000001
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
data_format: HWC
# Layer 1
- out_offset: 0x4000
processors: 0x0ffff00000000000
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
# Layer 2 - re-form data with gap
- out_offset: 0x0000
processors: 0x00000000000fffff
output_processors: 0x00000000000fffff
operation: passthrough
write_gap: 1
# Layer 3
- in_offset: 0x4000
out_offset: 0x0004
processors: 0x00000000000fffff
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
write_gap: 1
# Layer 4 - Residual-1
- in_sequences: [2, 3]
in_offset: 0x0000
out_offset: 0x2000
processors: 0x00000000000fffff
eltwise: add
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
# Layer 5
- out_offset: 0x2000
processors: 0xfffff00000000000
output_processors: 0x000000fffff00000
max_pool: 2
pool_stride: 2
pad: 1
operation: conv2d
kernel_size: 3x3
activate: ReLU
# Layer 6 - re-form data with gap
- out_offset: 0x0000
processors: 0x000000fffff00000
output_processors: 0x000000fffff00000
op: passthrough
write_gap: 1
# Layer 7 (input offset 0x0000)
- in_offset: 0x2000
out_offset: 0x0004
processors: 0x000000fffff00000
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
write_gap: 1
# Layer 8 - Residual-2 (input offset 0x2000)
- in_sequences: [6, 7]
in_offset: 0x0000
out_offset: 0x2000
processors: 0x000000fffff00000
eltwise: add
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
# Layer 9
- out_offset: 0x0000
processors: 0x00000fffffffffff
max_pool: 2
pool_stride: 2
pad: 1
operation: conv2d
kernel_size: 3x3
activate: ReLU
# Layer 10 - re-form data with gap
- out_offset: 0x2000
processors: 0x0000ffffffffffff
output_processors: 0x0000ffffffffffff
op: passthrough
write_gap: 1
# Layer 11
- in_offset: 0x0000
out_offset: 0x2004
processors: 0x0000ffffffffffff
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
write_gap: 1
# Layer 12 - Residual-3
- in_sequences: [10, 11]
in_offset: 0x2000
out_offset: 0x0000
processors: 0x0000ffffffffffff
eltwise: add
max_pool: 2
pool_stride: 2
pad: 1
pool_first: false
operation: conv2d
kernel_size: 3x3
activate: ReLU
# Layer 13
- out_offset: 0x2000
processors: 0x0000ffffffffffff
avg_pool: 2
pool_stride: 2
pad: 0
operation: conv2d
kernel_size: 1x1
activate: ReLU
# Layer 14 - LINNER
- out_offset: 0x0000
processors: 0x000000000ffffffff
operation: mlp
flatten: true
output_width: 32生成测试样本:10个
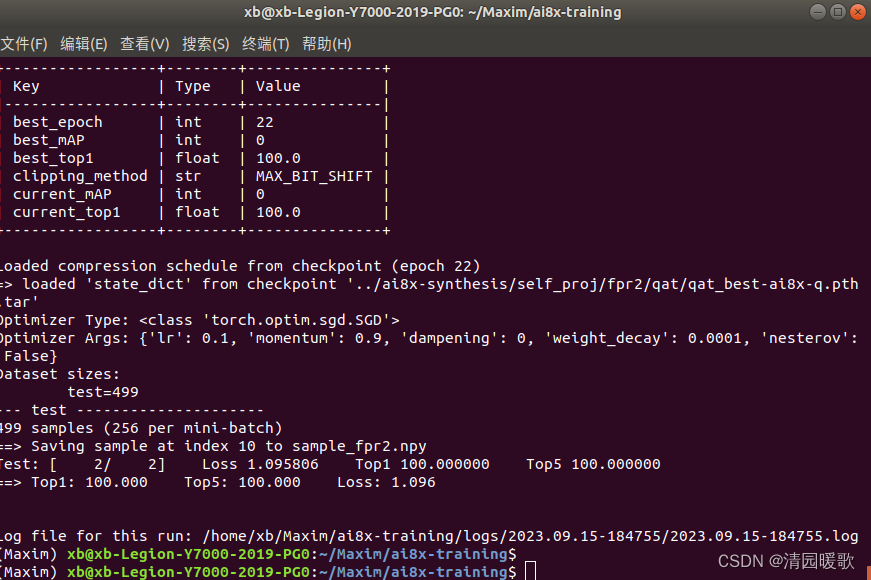
./train.py --model ai85net_fpr2 --save-sample 10 --dataset fpr2 --evaluate --exp-load-weights-from ../ai8x-synthesis/self_proj/fpr2/qat/qat_best-ai8x-q.pth.tar -8 --device MAX78000 "$@"
会在 ai8x-training 文件下生存 sample_fpr2.npy
移动到测试目录:
cp sample_fpr2.npy ../ai8x-synthesis/tests/sample_fpr2.npy修改 ai8x-synthesis/izer/versioncheck.py 第55行,不然会报错,相关安装
python github 项目 python运行github项目_mob6454cc6ba5a5的技术博客_51CTO博客
g = github.MainClass.Github()安装 pip install xxhash
要在demos/ai85-fpr2/文件夹中生成嵌入式 MAX78000 示例c代码,执行以下命令行:
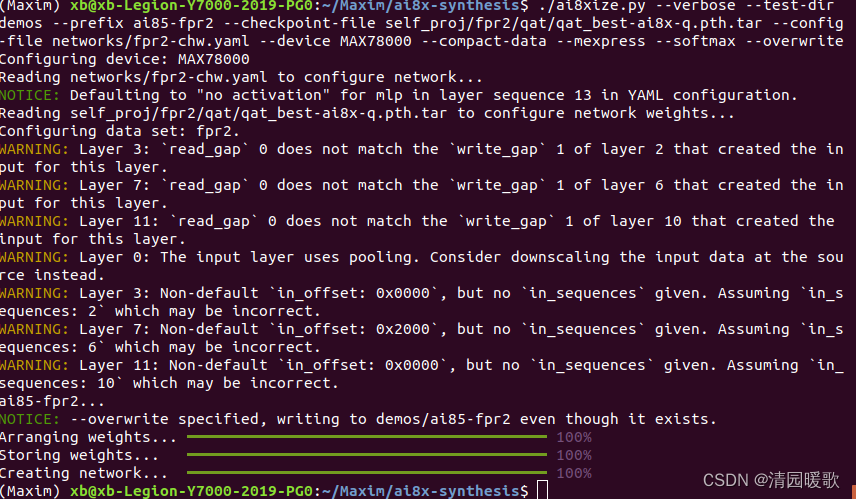
./ai8xize.py --verbose --test-dir demos --prefix ai85-fpr2 --checkpoint-file self_proj/fpr2/qat/qat_best-ai8x-q.pth.tar --config-file networks/fpr2-chw.yaml --device MAX78000 --compact-data --mexpress --softmax --overwrite
在代码生成阶段,会自动评估是否超内存,需重新对网络进行压缩,或换个内存片。

遇到这种问题是因为处理器选择不对:处理器位数与输入输出通道位数应保持一致。一个f代表4位,即4个通道,不够取余。

出现下面错误:

原因是创建残差链接时,先前的内存块被重写了。芯片的内存块为0x0000-0x8000,而8位的64*64就占了一半内存。而且内存中残差的实现方式是按字间隔储存,所以当存一个残差块时,内存就被间隔写满了,因此重写了之前的内存。
因此,推荐使用残差网络时,第一层残差的特征图建议不要大于64*64.我们将模型修改(见第六章修改部分)并重新进行测试
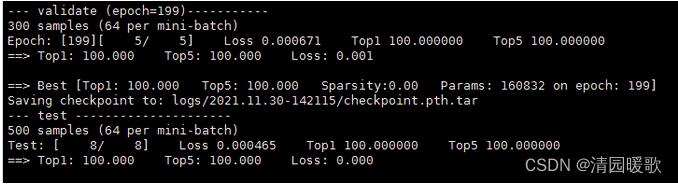
模型训练部分结果:
量化:
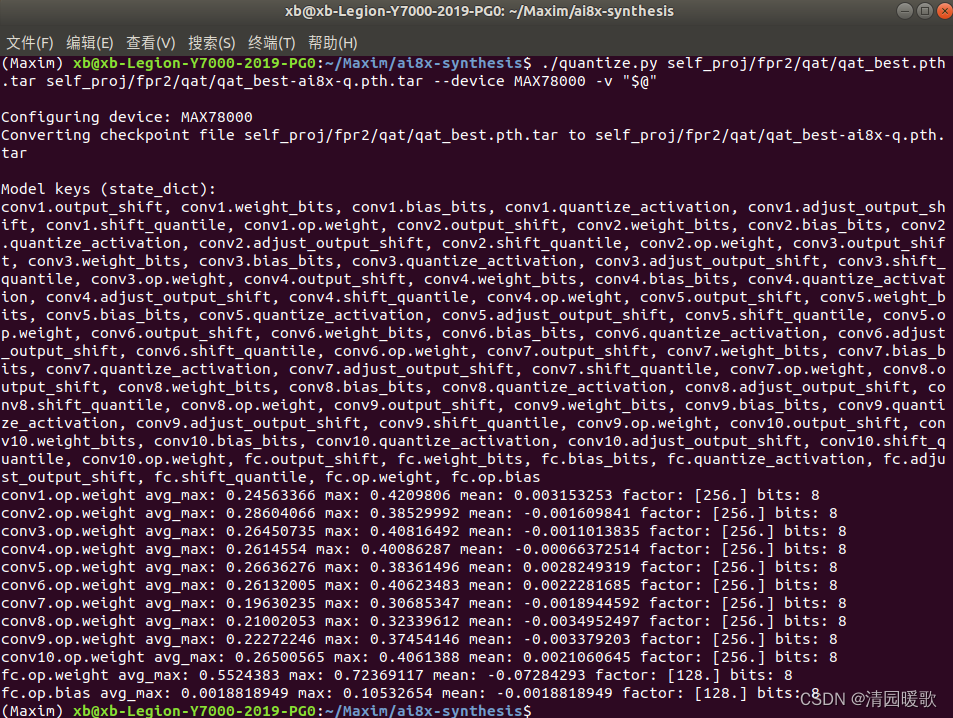
未量化后模型评估:
量化后模型评估:
生成sample_fpr2.npy:
模型转换:
./ai8xize.py --verbose --test-dir demos --prefix ai85-fpr2 --checkpoint-file self_proj/fpr2/qat/qat_best-ai8x-q.pth.tar --config-file networks/fpr2-chw.yaml --device MAX78000 --compact-data --mexpress --softmax --overwrite
Configuring device: MAX78000
warning就先不管了。。。。。
六、修改部分(先看)
ai85-training/models/ai85net-fpr2.py
修改:
(1)
self.conv1 = ai8x.FusedConv2dReLU(num_channels, 16, 3, pool_size=2, pool_stride=2,stride=2, padding=1, bias=bias, **kwargs)
(2)
#self.conv11 = ai8x.FusedAvgPoolConv2dReLU(96, 32, 1, pool_size=2, pool_stride=2,
# padding=0, bias=bias, **kwargs)
(3)
#x = self.conv11(x) # 512x2x2
import torch
import torch.nn as nn
import ai8x
class AI85Net_FPR(nn.Module):
"""
5-Layer CNN that uses max parameters in AI84
"""
def __init__(self, num_classes=100, num_channels=1,dimensions=(64, 64), bias=False, **kwargs):
super().__init__()
self.conv1 = ai8x.FusedConv2dReLU(num_channels, 16, 3, pool_size=2, pool_stride=2,stride=2, padding=1, bias=bias, **kwargs)
self.conv2 = ai8x.FusedConv2dReLU(16, 20, 3, stride=1, padding=1, bias=bias, **kwargs)
self.conv3 = ai8x.FusedConv2dReLU(20, 20, 3, stride=1, padding=1, bias=bias, **kwargs)
self.conv4 = ai8x.FusedConv2dReLU(20, 20, 3, stride=1, padding=1, bias=bias, **kwargs)
self.resid1 = ai8x.Add()
self.conv5 = ai8x.FusedMaxPoolConv2dReLU(20, 20, 3, pool_size=2, pool_stride=2,
stride=1, padding=1, bias=bias, **kwargs)
self.conv6 = ai8x.FusedConv2dReLU(20, 20, 3, stride=1, padding=1, bias=bias, **kwargs)
self.resid2 = ai8x.Add()
self.conv7 = ai8x.FusedConv2dReLU(20, 44, 3, stride=1, padding=1, bias=bias, **kwargs)
self.conv8 = ai8x.FusedMaxPoolConv2dReLU(44, 48, 3, pool_size=2, pool_stride=2,
stride=1, padding=1, bias=bias, **kwargs)
self.conv9 = ai8x.FusedConv2dReLU(48, 48, 3, stride=1, padding=1, bias=bias, **kwargs)
self.resid3 = ai8x.Add()
self.conv10 = ai8x.FusedMaxPoolConv2dReLU(48, 32, 3, pool_size=2, pool_stride=2,
stride=1, padding=0, bias=bias, **kwargs)
# torch.Size([64, 32, 6, 6])
#self.conv11 = ai8x.FusedAvgPoolConv2dReLU(96, 32, 1, pool_size=2, pool_stride=2,
# padding=0, bias=bias, **kwargs)
self.fc = ai8x.Linear(32*2*2, num_classes, bias=True, wide=True, **kwargs)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def forward(self, x): # pylint: disable=arguments-differ
"""Forward prop"""
#print(x.shape)
#x.repeat(1,3,1,1)
#print(x.size())
x = self.conv1(x) # 16x32x32
#print(x.size())
x_res = self.conv2(x) # 20x32x32
#print(x.size())
x = self.conv3(x_res) # 20x32x32
#print(x.size())
x = self.resid1(x, x_res) # 20x32x32
#print(x.size())
x = self.conv4(x) # 20x32x32
#print(x.size())
x_res = self.conv5(x) # 20x16x16
#print(x.size())
x = self.conv6(x_res) # 20x16x16
#print(x.size())
x = self.resid2(x, x_res) # 20x16x16
#print(x.size())
x = self.conv7(x) # 44x16x16
#print(x.size())
x_res = self.conv8(x) # 48x8x8
#print(x.size())
x = self.conv9(x_res) # 48x8x8
#print(x.size())
x = self.resid3(x, x_res) # 48x8x8
#print(x.size())
x = self.conv10(x) # 96x4x4
#x = self.conv11(x) # 512x2x2
#print(x.size())
x = x.view(x.size(0), -1)
#print(x.size())
x = self.fc(x)
return x
def ai85net_fpr2(pretrained=False, **kwargs):
"""
Constructs a AI85Net5 model.
"""
assert not pretrained
return AI85Net_FPR(**kwargs)
models = [
{
'name': 'ai85net_fpr2',
'min_input': 1,
'dim': 2,
},
]ai8x-synthesis/networks/fpr2-chw.yaml
修改:
(1)
# Layer 0
- out_offset: 0x2000
processors: 0x0000000000000111# CHW (big data) configuration for MNIST
arch: ai85net_fpr2
dataset: fpr2
# Define layer parameters in order of the layer sequence
layers:
# Layer 0
- out_offset: 0x2000
processors: 0x0000000000000111
operation: conv2d
kernel_size: 3x3
max_pool: 2
pool_stride: 2
pad: 1
activate: ReLU
data_format: HWC
# Layer 1
- out_offset: 0x0000
processors: 0x0ffff00000000000
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
# Layer 2 - re-form data with gap
- out_offset: 0x2000
processors: 0x00000000000fffff
output_processors: 0x00000000000fffff
operation: passthrough
write_gap: 1
# Layer 3
- in_offset: 0x0000
out_offset: 0x2004
processors: 0x00000000000fffff
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
write_gap: 1
# Layer 4 - Residual-1
- in_sequences: [2, 3]
in_offset: 0x2000
out_offset: 0x0000
processors: 0x00000000000fffff
eltwise: add
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
# Layer 5
- out_offset: 0x2000
processors: 0xfffff00000000000
output_processors: 0x000000fffff00000
max_pool: 2
pool_stride: 2
pad: 1
operation: conv2d
kernel_size: 3x3
activate: ReLU
# Layer 6 - re-form data with gap
- out_offset: 0x0000
processors: 0x000000fffff00000
output_processors: 0x000000fffff00000
op: passthrough
write_gap: 1
# Layer 7 (input offset 0x0000)
- in_offset: 0x2000
out_offset: 0x0004
processors: 0x000000fffff00000
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
write_gap: 1
# Layer 8 - Residual-2 (input offset 0x2000)
- in_sequences: [6, 7]
in_offset: 0x0000
out_offset: 0x2000
processors: 0x000000fffff00000
eltwise: add
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
# Layer 9
- out_offset: 0x0000
processors: 0x00000fffffffffff
max_pool: 2
pool_stride: 2
pad: 1
operation: conv2d
kernel_size: 3x3
activate: ReLU
# Layer 10 - re-form data with gap
- out_offset: 0x2000
processors: 0x0000ffffffffffff
output_processors: 0x0000ffffffffffff
op: passthrough
write_gap: 1
# Layer 11
- in_offset: 0x0000
out_offset: 0x2004
processors: 0x0000ffffffffffff
operation: conv2d
kernel_size: 3x3
pad: 1
activate: ReLU
write_gap: 1
# Layer 12 - Residual-3
- in_sequences: [10, 11]
in_offset: 0x2000
out_offset: 0x0000
processors: 0x0000ffffffffffff
eltwise: add
max_pool: 2
pool_stride: 2
pad: 0
pool_first: false
operation: conv2d
kernel_size: 3x3
activate: ReLU
# Layer 13 - LINNER
- out_offset: 0x2000
processors: 0x000000000ffffffff
operation: mlp
flatten: true
output_width: 32七、模型部署
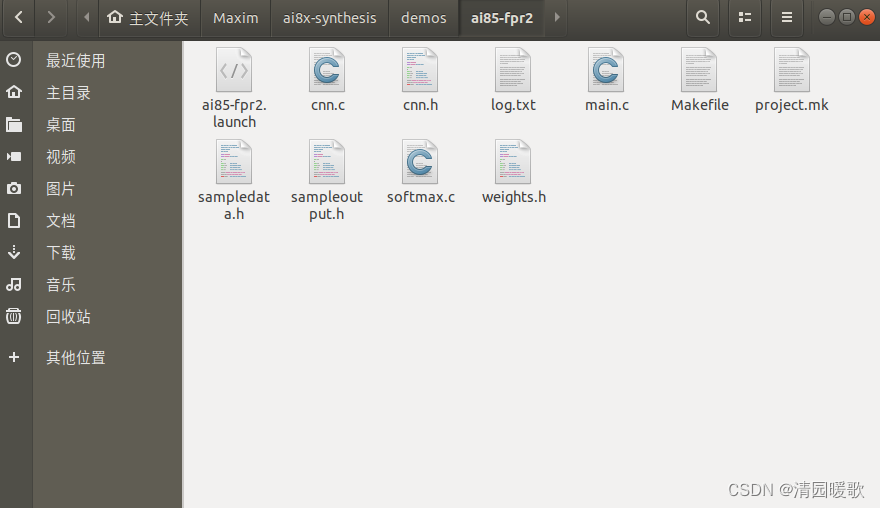
把模型转换生成在 ai8x-synthesis-demos-ai85-fpr2 文件夹的文件重新复制一份到 MaximSDK-self_proj-fpr2 中,自己新建的文件夹
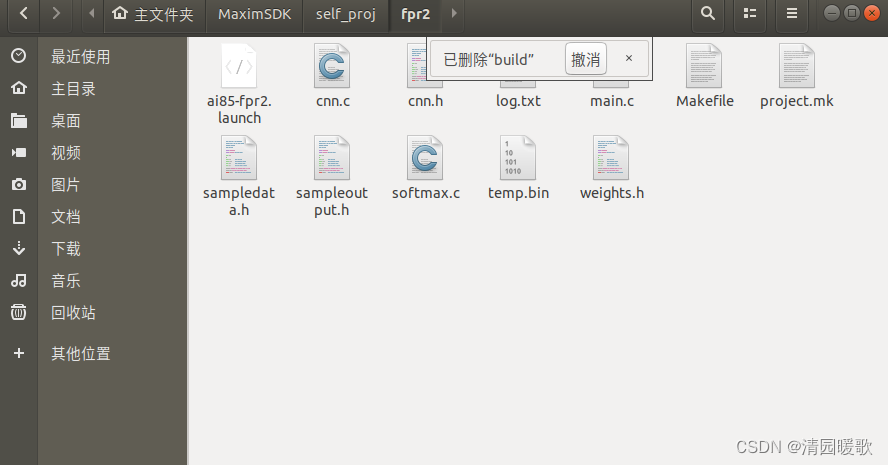
打开 makefile 文件
# Default board.
BOARD ?= FTHR_RevA在当前文件夹下 /home/xb/MaximSDK/self_proj/fpr2
(1)直接 make,此时在 build 文件夹下生成了 max78000.elf
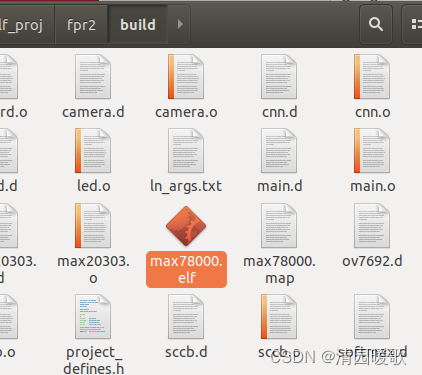
生成的.elf文件(max78000.elf或max78000-combined.elf)包含调试和其他元信息。要确定真正的 Flash 图像大小,请检查.map文件,或将其转换.elf为二进制图像并检查生成的图像。
arm-none-eabi-objcopy -I elf32-littlearm build/max78000.elf -O binary temp.bin
ls -la temp.bin
(2)打开 openocd
进入 /home/xb/MaximSDK/Tools/OpenOCD/scripts 文件夹
-s 后面可不要,这里到这里路径下搜索interfacce和target文件夹
linux 下输入
openocd -f interface/cmsis-dap.cfg -f target/max78000.cfg -s/home/xb/MaximSDK/Tools/OpenOCD/scriptswindows 下输入
openocd -f interface/cmsis-dap.cfg -f target/max78000.cfg -s/e/MaximSDK/Tools/OpenOCD/scripts打开 openocd
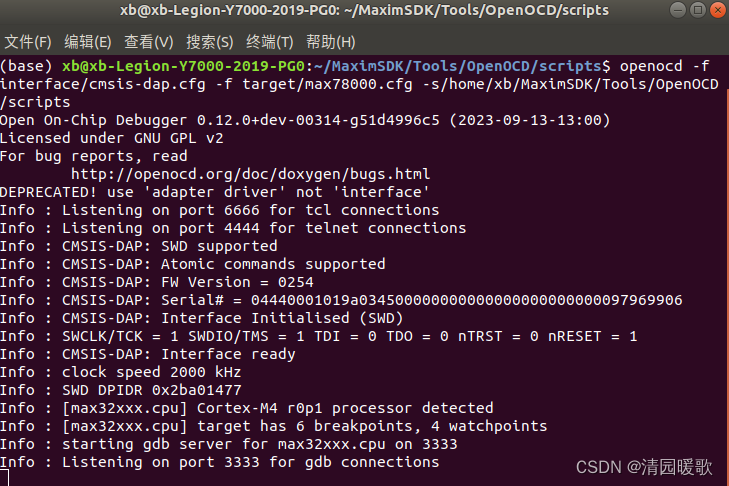
openocd:ctrl+c 退出
(3)启动 GDB
然后在文件夹 /home/xb/MaximSDK/self_proj/fpr2 下打开另一命令窗口,使用以下命令之一启动 GDB:
arm-none-eabi-gdb build/max78000.elf
arm-none-eabi-gdb build/max78000-combined.elf这里用
arm-none-eabi-gdb build/max78000.elf
gdb:ctrl+d 退出
(4)打开串口调试工具 minicom
命令行:sudo minicom 运行,sudo minicom -s 运行配置
这里板子的usb名称是:ttyACM0
ctrl+A 后按 x 退出
(5)下一步
GDB 连接到 OpenOCD 后复位 MAX78000:
target remote localhost:3333monitor reset halt
加载并验证应用程序:
loadcompare-sections
重置设备并运行应用程序:
monitor reset haltc
其他:
ubuntu下使用串口调试终端minicom链接typec接口_ubuntu串口终端_six2me的博客-CSDN博客


















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











