







1.前言
目前目标检测以及分割的模型发展速度非常快,可能YOLO12都快出来了,我们的论文还在编辑中或者投稿中。这个时候大家可能在想我做这个还有什么意义?反正做出来精度、速度也比不上人家。之前我也经常在想这个问题,现在我可以大声地回答大家,完全有意义!!!理由如下:
学术需求:现在每年中文和英文的发文量都是非常大的(巨大),多少本科生、研究生靠这个毕业呢,嘿嘿嘿!
背景需求:目前各种检测对象层出不穷,苹果、梨、地面裂缝检测都很常见了。但是大家有没有深入思考背后隐藏的问题呢?是不是检测对像体积小,可以作为小目标检测问题?是不是背景比较复杂,可以作为伪装物体检测问题? 是不是有部署的需求,可以作为轻量化的方向?
所以你做的完全有意义!大胆地做吧!正在更新中!

2 改进思路(4大法宝)
无事生非
在原始的数据集上加一些噪声,例如随机遮挡,或者调整饱和度亮度什么的,主要是根据具体的任务来增加噪声或扰动,不可乱来。如果它的精度下降的厉害,那你的思路就来了,如何在有遮挡或有噪声或其他什么情况下,保证模型的精度。例如行人重识别中的遮挡问题,人脸识别的戴口罩问题,晚上灯光下的过度曝光问题等。
去尝试一个新场景的数据集,因为原来的模型很可能是过拟合的。如果在新场景下精度下降的厉害,思路又有了,如何提升模型的泛化能力,实现在新场景下的高精度。
后浪推前浪
考虑一下模型是否太复杂,例如:人工设计的地方太多,后处理太多,需要调参的地方太多。基于这些情况,你可以考虑如何设计一个end-to-end模型,在设计过程中,肯定会出现训练效果不好的情况,这时候需要自己去设计一些新的处理方法,这个方法就是你的创新。
推陈出新
替换一些新的结构,引入一些其它方向的技术,例如transformer,特征金字塔技术等。这方面主要是要多关注一些相关技术,前沿技术,各个方向的内容建议多关注一些。
出奇制胜
尝试去做一些特定的检测或者识别。通用的模型往往为了保证泛化能力,检测识别多个类,而导致每个类的识别精度都不会很高。因此你可以考虑只去检测或识别某一个特定的类。以行为识别为例,一些通用的模型可以识别几十个动作,但你可以专门做跌倒检测。在这种情况下你可以加很多先验知识在模型中,例如多任务学习。换句话来说,你的模型就是专门针对跌倒设计的,因此往往精度可以更高。
3. 改进点总结
3.1 网络结构改进
3.2 添加注意力机制
这部分内容大多了,更新的注意力机制也太多了。一般的论文是直接添加一些现有的注意力机制,大部分高水平的论文就有自己特有的结构了(大部分还是改进)
3.3 改进损失函数
- Wise-IoU
- S-IoU
这部分内容也比较多,大家可以关注一些最新的损失函数
3.4标签匹配策略
- SimOTA
- ATSS标签匹配策略
- NanoDet动态标签分配策略
这部分有一定改进难度,所以目前出现的论文较少
4 论文结果图(锦上添花)
4.1数据集可视化
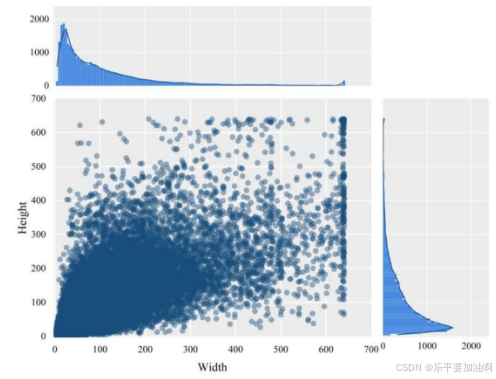
4.2热力图可视化

体现模型重点关注区域,推荐使用。
4.3特征图可视化

对每个通道的特征进行可视化,推荐使用。
5、英文顶刊论文创新点🌟
Lightweight object detection algorithm for robots with improved YOLOv5
Abstract
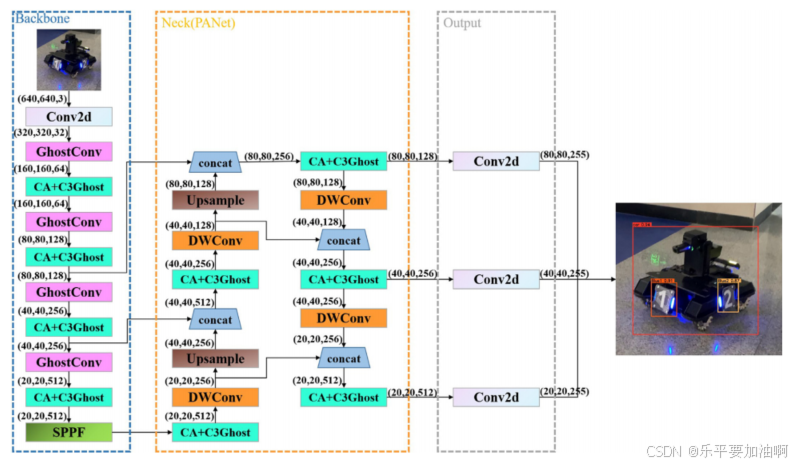
机器人目标检测是实现机器人智能的重要环节。目前,基于深度学习的目标检测算法被用于机器人目标检测。然而,在实际应用中也面临着一些挑战,比如机器人经常使用资源受限的设备,导致检测算法计算时间长,检测率不理想。为了解决这些问题,本文提出了一种基于改进YOLOv5的轻型机器人目标检测算法。为了减少特征提取所需的处理量并提高检测速度,C3Ghost和GhostConv模块已被引入YOLOv5主干。在YOLOv5颈部网络中,DWConv模块与C3Ghost模块结合使用,进一步减少了模型参数的数量,保持了精度。同时引入了CA (Coordinated Attention)模块,提高了对被检测对象特征的提取,抑制了无关特征,提高了算法的检测精度。为了验证该方法的性能,我们分别使用自建数据集(共4561张机器人图像)和PascalVOC数据集进行了测试。结果表明,与自建数据集上的YOLOv5s相比,该算法在mAP(0.5)不变的情况下,FLOPs降低54%,模型参数个数减少52.53%。通过实例分析和比较,证明了该算法的有效性和优越性。
论文创新点总结
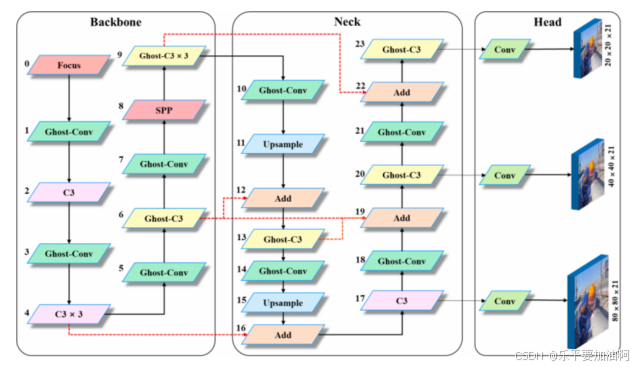
CA (Coordinated Attention)模块
DWConv
C3Ghost模块
GhostConv
结构
FFCA-YOLO for Small Object Detection in Remote Sensing Images
Abstract
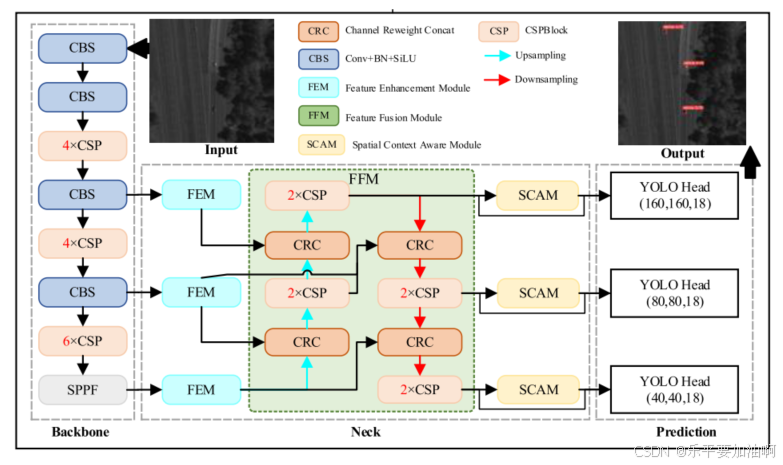
遥感小目标的检测任务十分艰巨,存在特征表示不充分、背景混乱等问题。特别是,当算法将部署到船上进行实时处理时,这需要在有限的计算资源下对精度和速度进行广泛的优化。为了解决这些问题,本文提出了一种高效的特征增强、融合和上下文感知YOLO (FFCA-YOLO)检测器。FFCA-YOLO包括三个创新的轻量级即插即用模块:特征增强模块(FEM)、特征融合模块(FFM)和空间上下文感知模块(SCAM)。这三个模块分别提高了网络的局部感知能力、多尺度特征融合能力和跨通道、跨空间的全局关联能力,同时尽量避免增加复杂度。从而增强小目标的弱特征表征,抑制易混淆的背景。
利用VEDAI和AI-TOD两个公共遥感小目标检测数据集和USOD一个自建数据集验证了FFCA-YOLO的有效性。FFCA-YOLO的准确率达到0.748、0.617和0.909(以mAP50计算),超过了几个基准模型和最先进的方法。同时,在不同的模拟退化条件下验证了FFCA-YOLO的鲁棒性。
此外,为了在保证效率的同时进一步减少计算资源消耗,基于部分卷积(PConv)对FFCA-YOLO的主干和颈部进行重构,优化了精简版FFCA-YOLO (L-FFCA-YOLO)。
与FFCA-YOLO相比,L-FFCA-YOLO速度更快,参数规模更小,计算能力要求更低,精度损失小。
论文创新点总结
特征增强模块(FEM)
特征融合模块(FFM)
空间上下文感知模块(SCAM)
结构
Joint-attention feature fusion network and dual-adaptive NMS for object detection
Abstract
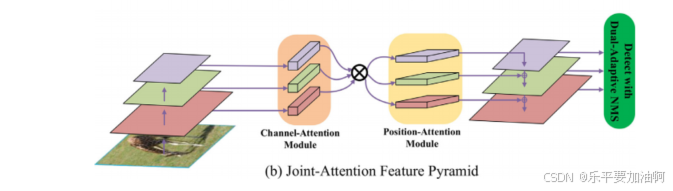
注意机制和非最大抑制(NMS)已被证明是目标检测的有效组成部分。然而,基于单一关注机制的不同尺度、不同层次的特征融合并不总是能产生令人满意的效果,而且可能会引入冗余信息,使结果不如预期。另一方面,NMS方法通常面临单常数阈值困境,即阈值越低,会错过高度重叠的实例对象,而阈值越高,则会产生更多的误报。因此,如何优化特征映射中不同维度的关联,以及如何自适应设置NMS阈值,仍然阻碍着有效的目标检测。虽然单独寻址会导致次优检测,但本文提出将联合关注特征融合网络中的信息特征表示馈送到自适应NMS中,以获得全面的性能增强。具体而言,我们在三层特征金字塔网络(FPN)中嵌入了两种类型的注意力模块:采用渠道-注意力模块,通过从全局角度重新评估渠道之间的关系来增强特征表示;位置注意模块利用特征之间的相关性发现丰富的上下文特征信息。此外,我们开发了双自适应NMS,根据实例对象密度动态调整抑制阈值,即当实例对象聚集时阈值上升,当对象稀疏时阈值下降。在COCO数据集上对该方法进行了评估,大量的实验结果表明,与现有方法相比,该方法具有优越的性能。
论文创新点总结
双自适应NMS
注意力模块
结构
A lightweight vehicles detection network model based on YOLOv5
Abstract
车辆检测技术对于实现自动监控和人工智能辅助驾驶系统具有重要意义。最先进的目标检测方法,即一类YOLOv5,经常用于检测车辆。然而,它面临着一些挑战,如高计算负荷和不理想的检测率。针对这些问题,本文提出了一种改进的轻量级YOLOv5车辆检测方法。该方法在YOLOv5颈部网络中引入C3Ghost和Ghost模块,减少特征信道融合过程中的浮点运算,提高特征表达性能。在YOLOv5骨干网中引入卷积块注意模块(CBAM),选择对车辆检测任务至关重要的信息,抑制非关键信息,从而提高算法的检测精度。进一步将CIoU_Loss作为边界盒回归损失函数,加快边界盒回归速度,提高算法的定位精度。为了验证所提出方法的性能,我们通过两个案例研究测试了我们的模型,即PASCAL VOC数据集和MS COCO数据集。结果表明,与现有的YOLOv5相比,该模型的检测精度提高了3.2%,FLOPs降低了15.24%,模型参数数量减少了19.37%。通过案例分析和比较,证明了该方法的有效性和优越性。
论文创新点总结
C3Ghost和Ghost模块
CBAM
CIoU_Loss
结构
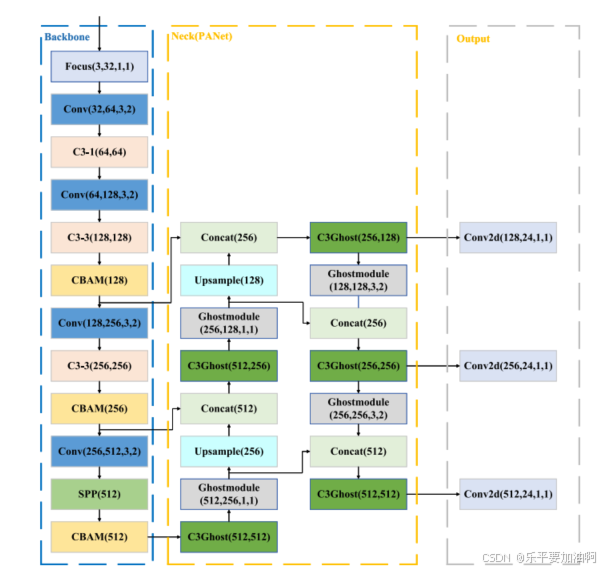
Mixed local channel attention for object detection
Abstract
注意机制是计算机视觉中应用最广泛的组成部分之一,它可以帮助神经网络突出重要元素,抑制无关元素。然而,绝大多数通道注意机制只包含通道特征信息,忽略了空间特征信息,导致模型表示效果或目标检测性能较差,且空间注意模块往往复杂且昂贵。为了在性能和复杂性之间取得平衡,本文提出了一种轻量级的混合本地信道注意(MLCA)模块来提高目标检测网络的性能,该模块可以同时包含信道信息和空间信息,以及局部信息和全局信息,以提高网络的表达效果。在此基础上,提出了MobileNet-Attention-YOLO(MAY)算法,用于比较不同注意力模块的性能。在Pascal VOC和SMID数据集上,MLCA比其他注意技术在模型表示效率、性能和复杂性之间取得了更好的平衡。
对比PASCAL VOC数据集上的挤压-激励(SE)注意机制和SIMD数据集上的坐标注意(CA)方法,mAP分别提高了1.0%和1.5%。
论文创新点总结
注意力机制
结构
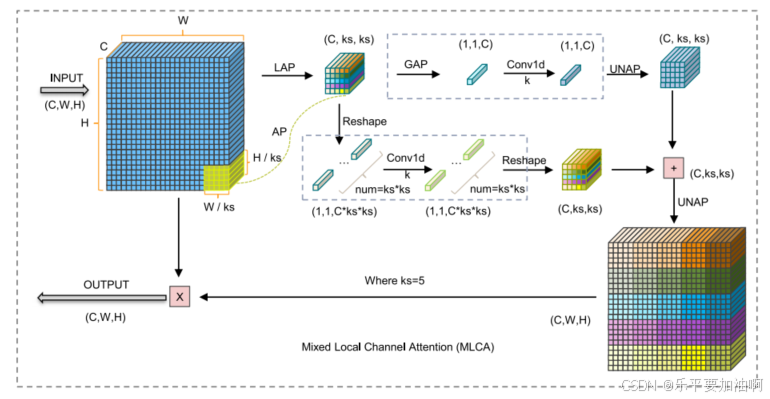
Real-time detection of a camouflaged object in unstructured scenarios based on hierarchical aggregated attention lightweight network
Abstract
在复杂的室内环境中,准确、实时地抓取家居用品是家庭服务机器人面临的一个挑战。本文以透明杯子为识别对象,针对需要护理的老年人,提出了一种准确、可靠、实时的视觉算法,解决复杂非结构化室内场景中杯子重叠、模糊、小的识别问题。为了满足家庭服务机器人的轻量化部署,同时兼顾高尺度和低尺度语义特征,本文设计了基于拆分洗牌块(SSB)和分组洗牌块(GSB)特征编码单元的多尺度融合轻量化骨干网。其中,深度可分离卷积(DwConv)用于减少编码单元参数的数量,特征shuffle用于促进信息交换和信息表达能力。为了准确识别隐藏在复杂背景下的透明杯子,本文提出了一种结合多尺度分层聚集关注和多分支并行卷积结构的轻量化特征增强模块。该模块采用自适应加权策略和信道归一化加权策略,突出各分支特征图中边界特征的活动区域,增强边界信息的交换,减少详细信息的丢失。在IndoorCup和MobileCup数据集上的实验结果表明,该方法的检测准确率分别为93.6%和92.6%,模型计算量仅为0.91 M,可以轻量化部署在室内移动机器人上进行实时检测。定性比较结果表明,该方法具有较强的鲁棒性。它能有效地抑制因背景干扰引起的误检和漏检。同样,它也可以有效地识别复杂背景中的伪装物体和小物体。
论文创新点总结
轻量化主干网络
注意力机制
结构
LDS-YOLO: A lightweight small object detection method for dead trees from shelter forest
Abstract
枯死树的检测和定位对于森林的管理和自然度评估具有极其重要的意义,及时补种枯死树可以有效抵御自然灾害,保持生态系统的稳定。死树具有目标小、细节信息不明显的特点,导致了识别困难的问题。本文提出了一种基于YOLO框架的小目标检测轻量级新架构LDS-YOLO。具体而言,提出了一种新的特征提取模块,该模块重用前一层的特征,以实现密集连接,减少对数据集的依赖。然后,对于空间金字塔池(SPP),引入SoftPool方法,保留目标的详细信息,保证小目标不被遗漏。
同时,采用少量参数的深度可分卷积代替传统的卷积来减少模型参数的数量。我们在自制的无人机图像数据集上对该方法进行了评估。实验结果表明,LDS-YOLO体系结构与现有模型相比具有良好的性能,AP值为89.11%,参数大小为7.6 MB,可用于快速检测防护林枯死树木,为三北防护林林业管理提供科学的理论依据。
论文创新点总结
Dense connection module
SoftPool方法
深度可分卷积
结构
YOLO-SM: A Lightweight Single-Class Multi-Deformation Object Detection Network
Abstract
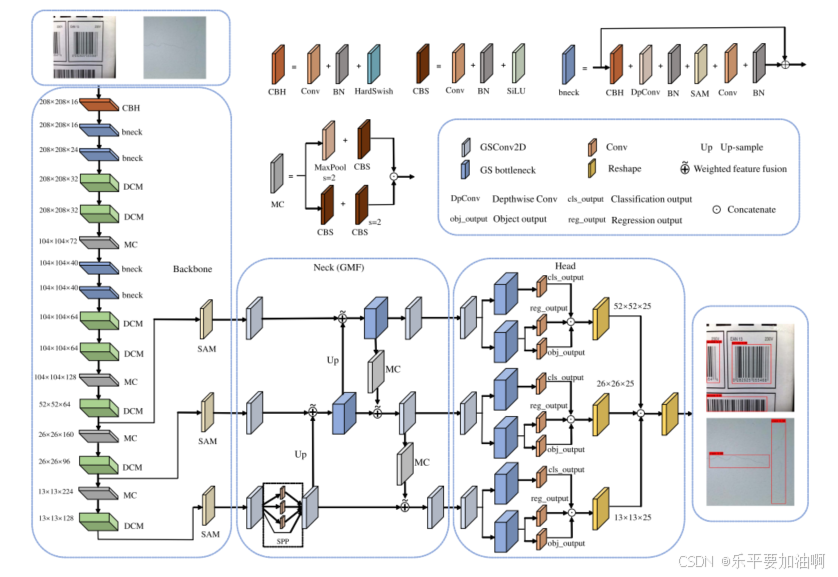
近年来,随着卷积神经网络(Convolutional Neural Networks, cnn)的快速发展,目标检测取得了巨大的进步。然而,目标检测主要针对多类任务,很少有网络用于检测单类多变形目标。本文旨在开发针对单类多变形目标的轻量化目标检测网络,促进目标检测网络的实际应用。首先,我们设计了一个密集连接的多尺度(DCM)模块来增强变形对象的语义信息提取。结合DCM模块和其他策略,我们设计了一个轻量级的目标检测骨干结构,即DCMNet。然后,利用特征线性生成策略构建了用于特征融合的轻型颈部结构幽灵多尺度特征(GMF)模块。最后,利用DCMNet和GMF模块,提出了单类多变形目标的目标检测网络YOLO-SM。大量的实验表明,我们提出的主干结构,DCMNet,显著优于最先进的模型。YOLO-SM在条形码公共数据集上的平均精度(mAP)达到97.66%,高于其他最先进的目标检测模型,推理时间达到55.45帧/秒,证明YOLO-SM在检测单类多变形目标时具有良好的速度和精度性能权衡。此外,在单类多变形裂纹公共数据集上,mAP达到了86.11%,在多类数据集Dish20上mAP达到了99.84%,远远高于其他最先进的目标检测模型,证明了YOLO-SM具有良好的泛化能力。
论文创新点总结
DCM模块
GMF模块
结构
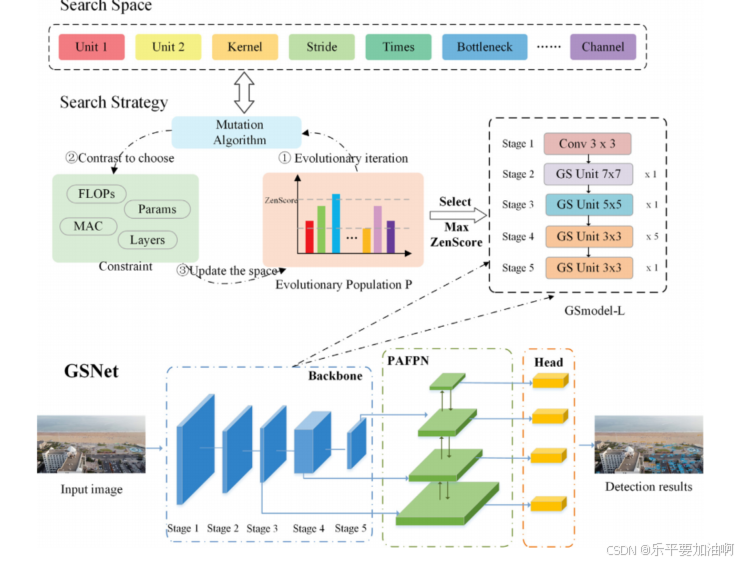
Lightweight network learning with Zero-Shot Neural Architecture Search for UAV images
Abstract
轻量级网络架构对于无人机(uav)的自主和智能监控至关重要,例如在物体检测,图像分割和人群计数应用中。目前基于神经结构搜索(NAS)的轻量级网络学习需要耗费大量的计算资源。另外,低性能嵌入式平台和高分辨率无人机图像对轻量级网络学习提出了挑战。为了解决这一问题,本文提出了一种基于零射击神经结构搜索的无人机图像轻量化目标检测模型GhostShuffleNet (GSNet)。本文还介绍了组成GSNet的新组件,即GhostShuffle单元(松散地基ShuffleNetV2)和骨干gmodel - l。首先,利用GhostShuffle (GS)单元构建轻量级搜索空间,减少参数和浮点操作(FLOPs);其次,将参数、FLOPs、层数和内存访问成本(MAC)作为约束条件,对零射击神经结构搜索算法的搜索策略进行约束,从而搜索最优网络GSmodelL。最后,以最优的gmodel - l作为骨干网,加入Ghost-PAN特征融合模块和检测头,完成轻量化目标检测网络(GSNet)的设计。在VisDrone2019 (14.92%mAP)数据集和我们的UAV-OUC-DET (8.38%mAP)数据集上进行了大量实验,证明了GSNet的效率和有效性。
论文创新点总结
神经结构搜索(NAS)
Ghost-PAN特征融合模块
GhostShuffle单元
结构
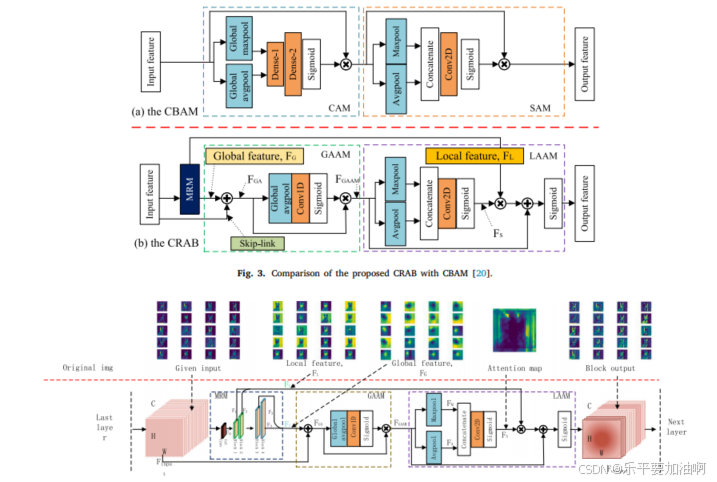
Attention-based convolution neural network for magnetic tile surface defect classification and detection
Abstract
由于有限的样品可用性和不相关的背景干扰,有效识别磁砖表面缺陷已被证明是极具挑战性的,这也在显著影响永磁电机的寿命和可靠性方面起着至关重要的作用。为了解决这些挑战,我们的研究从视网膜注意机制的综合分析中获得灵感,并提出了三个指导标准:多层次分辨率,寻找什么,以及看在哪里。利用这些准则作为基础原则,通过结合视网膜注意机制来增强所设计的神经网络结构的表示学习能力。随后,在这些指导准则的基础上,我们引入了一种新的卷积视网膜注意块(convolutional retinal attention block, CRAB)来学习判别性和鲁棒性的特征表示,用于磁砖表面缺陷的分类和检测。该算法包括三个模块:多分辨率模块(MRM)、全局注意力聚合模块(GAAM)和局部注意力聚合模块(LAAM),旨在通过精炼有意义信息和抑制冗余信息来提取具有区别性和鲁棒性的特征。跨图像分类和目标检测任务的综合实验结果表明,该方法优于SE、ECA和CBAM等现有方法,并能有效增强在VGG-16、GoogLeNet、ResNet-18和ResNet-50等多种骨干网上的表示能力。通过对工业磁砖表面缺陷分类和检测任务的评估,进一步表明该方法的准确率分别达到99.50%和96.98%。这些结果强调了该方法在广泛和无关紧要的背景下检测工业表面缺陷的良好应用前景。
论文创新点总结
注意力机制
结构
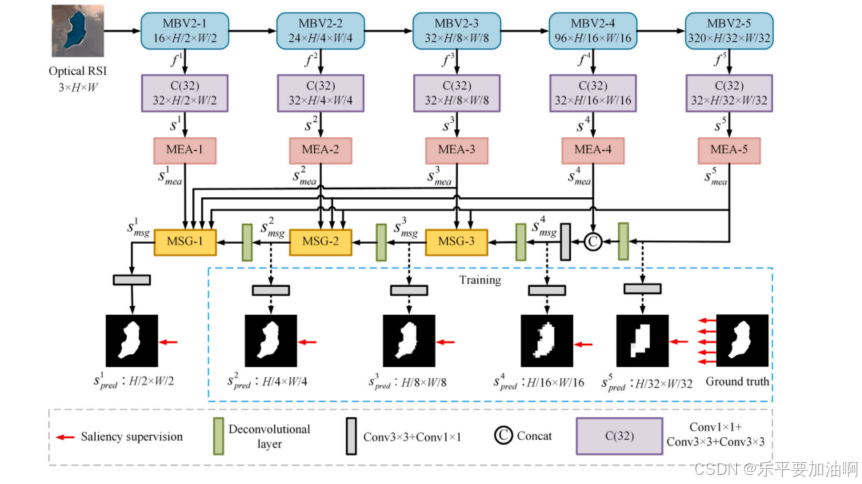
MEANet: An effective and lightweight solution for salient object detection in optical remote sensing images
Abstract
光学遥感图像中显著目标检测(RSI-SOD)的目的是对光学遥感图像中引人注意的目标进行分割。随着全卷积神经网络在像素级分割方面的巨大成功,RSI-SOD的性能得到了显著提高。然而,大多数RSISOD方法主要侧重于提高检测精度,而忽略了内存和计算成本,这阻碍了它们在资源受限应用中的部署。在本文中,我们提出了一种新的轻量级RSI-SOD网络,名为MEANet,以解决这些挑战。具体来说,设计了一个多尺度边缘嵌入注意(MEA)模块,通过将边缘信息整合到空间注意图中来增强对显著目标的捕获。在此基础上,构建了u型解码器网络,并引入了多级语义引导(MSG)模块来缓解u型网络中的语义稀释问题。通过与27个最先进的基于fcn的模型进行广泛的定量和定性比较,该模型在仅保持3.27M参数和9.62G FLOPs的情况下,表现出具有竞争力或更优的性能。
论文创新点总结
MEA模块
MSG模块
结构
Real-time vehicle detection algorithm based on a lightweight You-Only-Look-Once (YOLOv5n-L) approach
Abstract
车辆检测算法对自动驾驶技术具有重要意义。现有的车辆检测算法结构复杂,硬件配置要求高,难以应用于移动终端设备。为了解决这些问题,本文提出了一种改进的YOLOv5轻量级算法,命名为YOLOv5n-L。首先,利用深度可分卷积和C3Ghost模块代替多个C3模块,减少模型参数,提高检测速度;在骨干网中加入了压缩激励注意机制,提高了算法的精度,抑制了环境干扰。最后,利用双向特征金字塔网络进行多尺度特征融合,丰富了特征信息,提高了算法的特征提取能力。实验结果表明,与原算法相比,模型权重降低了40%,仅为2.3 m,平均精度(mAP@0.5)提高了1.7%。探测速度达到80 FPS,能够实时准确探测车辆目标。
论文创新点总结
深度可分卷积
C3Ghost模块
压缩激励注意机制
BIFPN
A lightweight face-assisted object detection model for welding helmet use
Abstract
自动焊接头盔使用(WHU)检测技术对于施工现场的安全管理具有重要意义,因此,本文提出了一种基于YOLOv5s的轻型人脸辅助WHU检测模型(WHU- yolo)。首先,将Ghost模块引入到YOLOv5s中,对骨干和颈部的特征提取部位进行优化,降低模型复杂度。然后,基于双向特征金字塔网络(Bi-FPN)重构YOLOv5s的颈部;在建立的焊接头盔和人脸检测(WHD)数据集上进行的实验结果表明,在人脸数据的辅助下,误报率大大降低,平均精度(mAP)达到83.65%。同时,在NVIDIA GeForce GTX 1070和640 × 640输入尺寸的环境下,推理时间高达5.7 ms的WHU-YOLO实现了模型压缩,与YOLOv5s相比,参数、权重尺寸和浮点运算(FLOPs)分别降低了35.7%、34.4%和30.1%,检测性能没有下降。
论文创新点总结
Ghost模块
Bi-FPN
结构
6、参考
zhihu.com/question/36757207/answer/2153876227


















 2055
2055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









