






创新点
提出一种新的深度压缩算法来减少点云的内存占用。
利用点之间的稀疏性和结构冗余来降低比特率。
先利用高效且自适应的八叉树结构来获得原始点云的初始编码。
然后在树的每个中间节点上学习一个树结构的深度条件熵模型,结合场景的先验上下文来帮助预测节点符号。
最后从熵模型中预测的概率被传递给编码器,将序列化的符号编码成最终的比特流。
Architecture
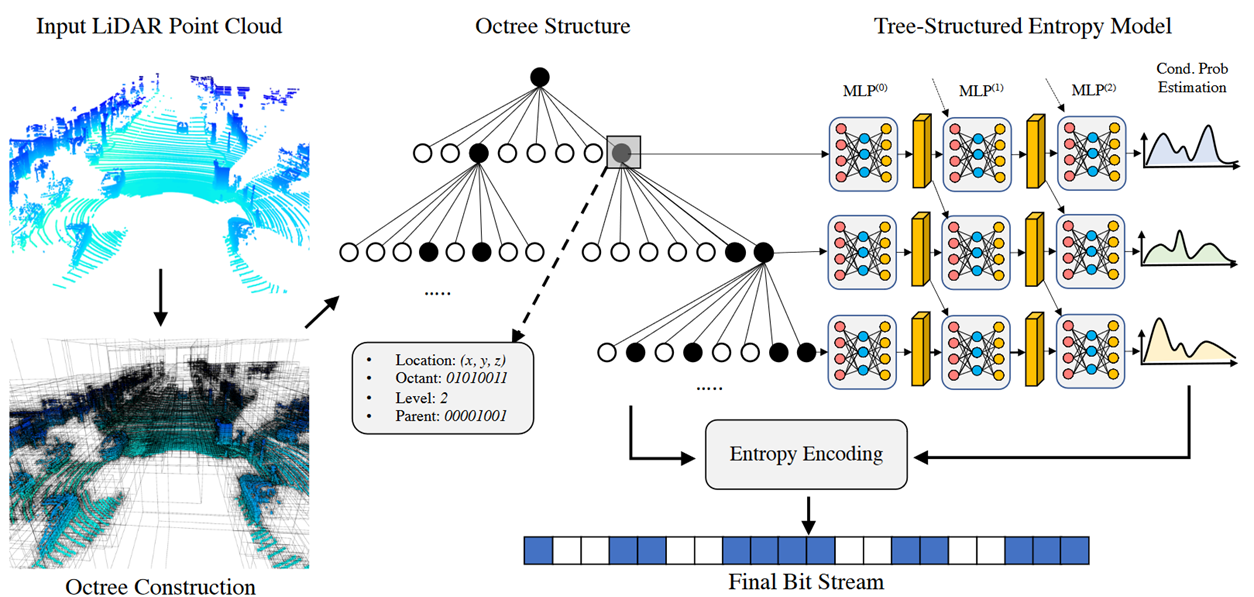
上下文包括:
Location:节点的3D位置编码为R3中的向量,表示节点在三维空间中的空间坐标。
Octant:八叉树块索引,范围在{0,1,2,…,7}的整数。此索引标识当前节点xi属于其父节点的哪个八叉树块。
Parent:父节点的占用状态,范围为{0,1,2,…,255}的整数,父节点的8位占用位的十进制化,指示父节点的哪些子八叉树块被占用。
Octant和Parent的解释和图片上的对不上。
为什么熵模型能减少bit数
把所有体素的八位占用率进行排序,根据哈夫曼编码,减少编码的总长度。最后编码的bit流包含从根到叶所有结点的占用率。然后再从根到叶根据bit流解码出占用位可以重建出整颗八叉树。
为什么要用网络学习占用率
以便可以扩展到其他点云模型上,进行扩展。
Deep Entropy Model
给定占用序列x=[x1,x2…xn],熵模型的目标是学习一个估计分布q(x),与实际分布p(x)的交叉熵最小: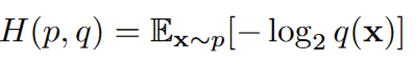
将q(x)分解为每个个体占用符xi的条件概率的乘积: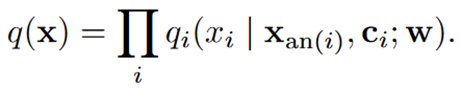
Xan(i)是当前结点祖先的集合,直到指定的k阶。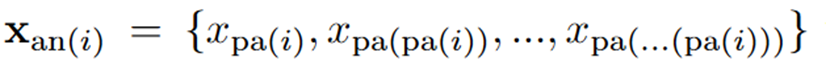
W是熵模型权重。
Ci是相应上下文:包括节点深度、父节点占位和当前八元组的空间位置等信息。
用MLP为每个节点提取一个独立的深度特征: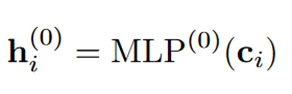
从hi(0)开始,在当前节点特征和父节点的特征之间进行K次聚合。
聚合也使用一个MLP: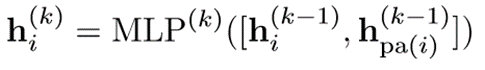
对每个节点进行端到端的交叉熵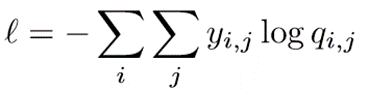 y是真实概率,q是预测概率。
y是真实概率,q是预测概率。
最终输出位于第K个聚合特征hi(k)的线性层,为给定节点的8比特占用符号产生256维的概率softmax
Encoder-Decoder
编码:
从根到叶在不同的层次上依次应用熵模型,不在同一层次的节点之间传播信息。因此,在每个层内,可以将概率估计的计算并行化。
之后用熵编码算法(如算术编码)对八叉树原始比特流进行无损压缩。通过预测序列中每个字节xi的类别分布(0~255)来确定算术编码器的熵模型。
解码:
在解码算法中使用相同的熵模型。然后从解压后的比特流中建立八叉树,并用于重建点云。
由于熵模型的自回归特性,每个节点概率估计只依赖于自身和更高层的节点特征。此外,八叉树以广度优先的搜索方式序列化。因此,给定节点xi,它的祖先xan(i)在xi之前被解码,使得解码器也可以解码xi。
Experiments
上下文特征的消融实验:
L,P,O,LL分别表示结点八叉树层级,父节点占有率,八元组索引和空间位置
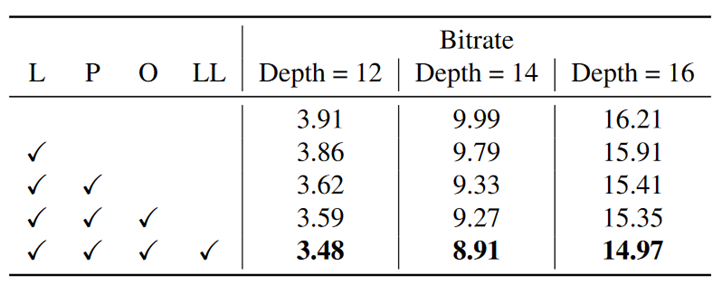
上下文特征的消融实验
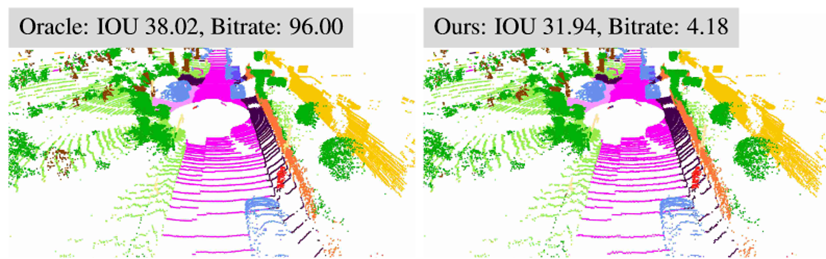
下游感知任务的量化结果















 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









