







NeRV的缺点:
1.位置嵌入没有与框架的内容相结合,内容不可知。
2.模型参数分布不均,靠后层(接近输出)比靠前层(接近嵌入)具有更少的参数。
这也是隐式表达共同的缺点:以牺牲可泛化性为代价,具有简单性。
HNeRV优点:
1.用可学习的编码器生成内容自适应的嵌入。
2.引入HNeRV block,构建参数在整个网络上分布较为均匀的视频解码器。
3.HNeRV对帧的顺序没有依赖,可以有效地随机访问帧来并行解码帧。
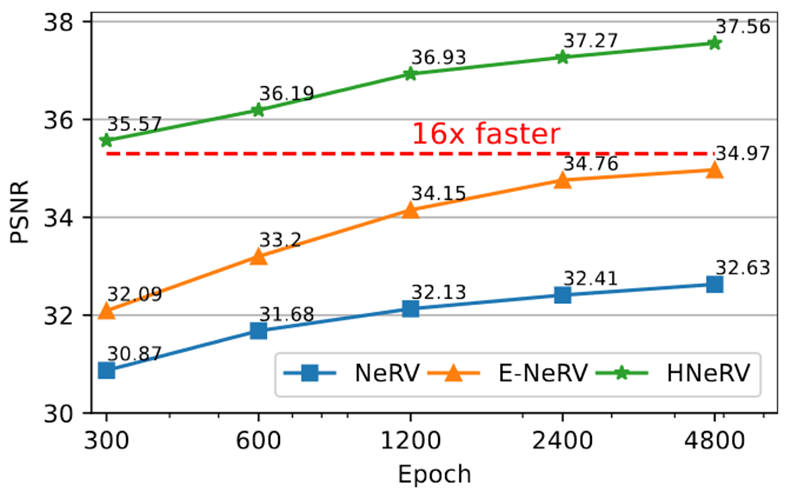
HNeRV局限性:
1.将视频存储为一个神经网络,对于新的视频,需要训练来适应。
2. 最佳的嵌入和模型大小以及网络架构仍然是一个开放的问题。
3.增加靠后层的参数提高了性能,但运行速度减慢
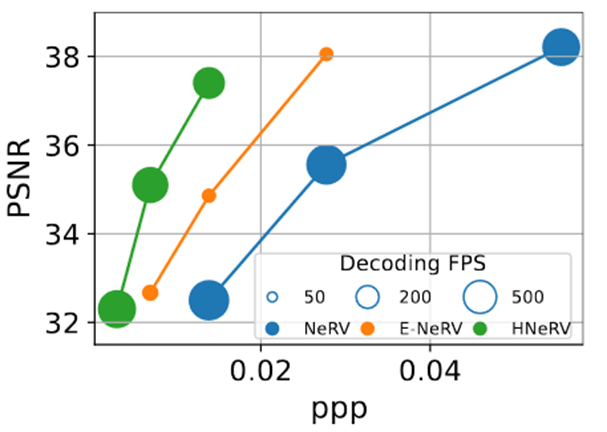
紧凑性(ppp),重建质量(PSNR),解码速度(FPS)。
Ppp计算:模型参数量/视频的像素数量。
Architecture
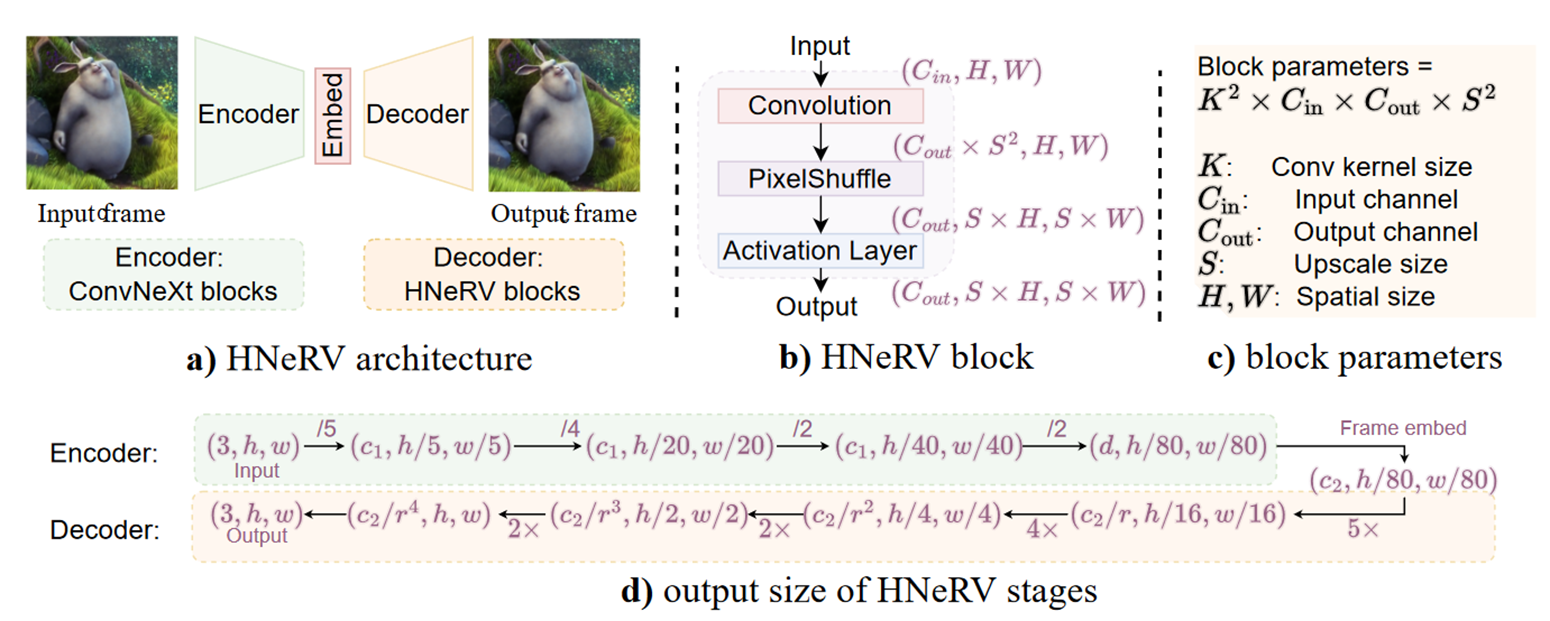
与NeRV只输入时间帧t不同,HNeRV输入的是一帧帧图片或者视频信息。
图片经过可学习的ConvNeXt blocks,得到微小的嵌入,即图中的Embed(这指的是一个数据结构,而不是一个embde block),在输入给创新的HNeRV blocks得到decoder后的图片。
创新的HNeRV block和NeRV的区别只在于卷积核大小以及输出的通道数不同,目的是得到更均衡的模型参数。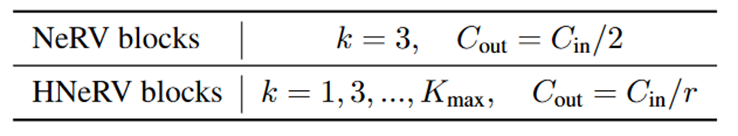
NeRV块使用固定的K = 3,且Cout = Cin / 2。
对于后面的层,参数很少,不足以存储高分辨率的视频内容。
Downstream
压缩:
与NeRV的压缩基本相同,但Prune会使大部分参数权重为0,后续熵编码的时候有误差。
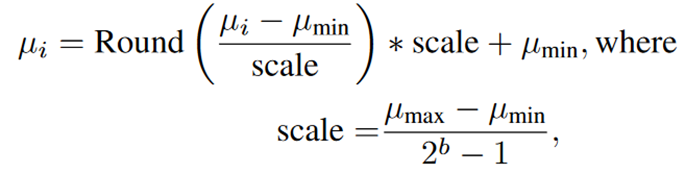
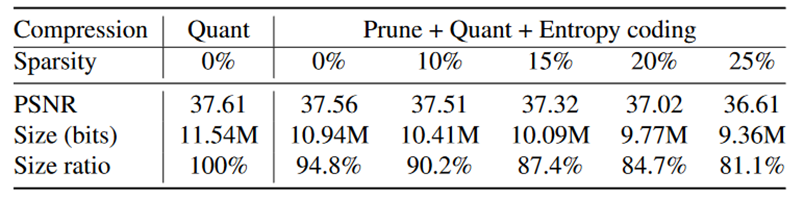
什么意思?是说不用Prune+Entropy了?
代码中也只找到Quant的代码。
视频修复:
对于部分失真视频,只计算非遮蔽像素的损失。
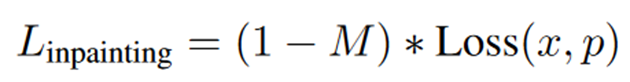
M是掩码,其中失真像素为1,其他为0。
Experiments
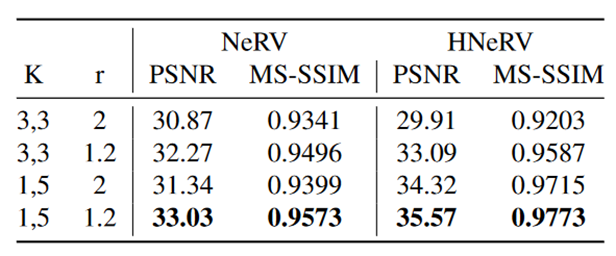
将Kmax = 5的NeRV记为(1,5),因为FC层可看作1*1的卷积层。
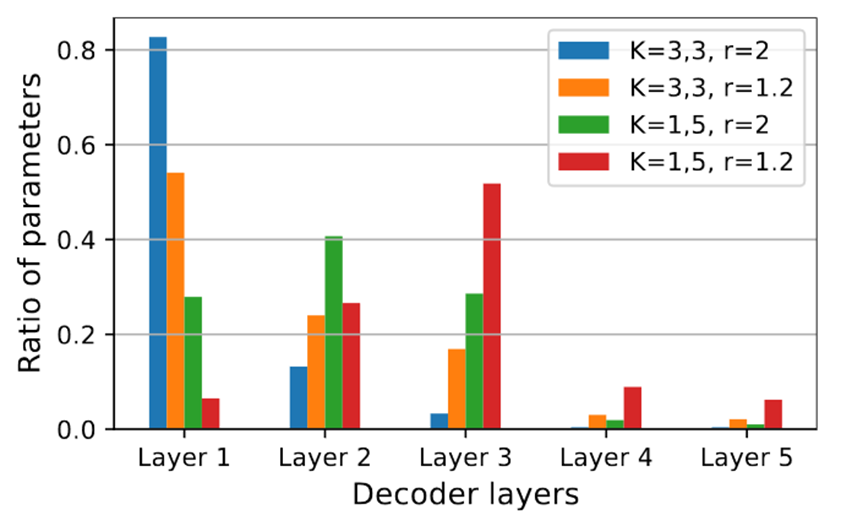
创新的HNeRV层使得靠后层的参数量增加。但也不算很均匀啊?
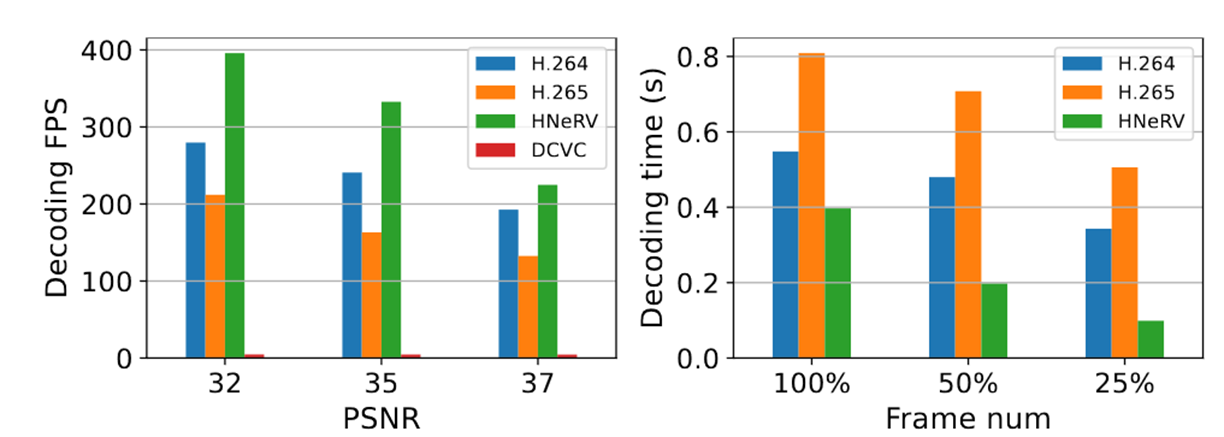
大多数压缩方法以自回归的方式对帧进行编码和解码,不能随机访问帧。
HNeRV可以并行解码,解码时间随解码帧数线性减少。
相比之下,H.264和H.265仍然需要对大部分帧进行解码,即使只需要其中的一部分。















 1257
1257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









