







不创新注意力机制,而是权衡现有的准确性和效率(利用scale的力量)。
模型性能更多受到规模的影响,而不是复杂的设计。
将simple和efficient置于某些机制的准确性之上,从而实现可扩展性,而这些机制在scale后对整体性能来说是次要的。
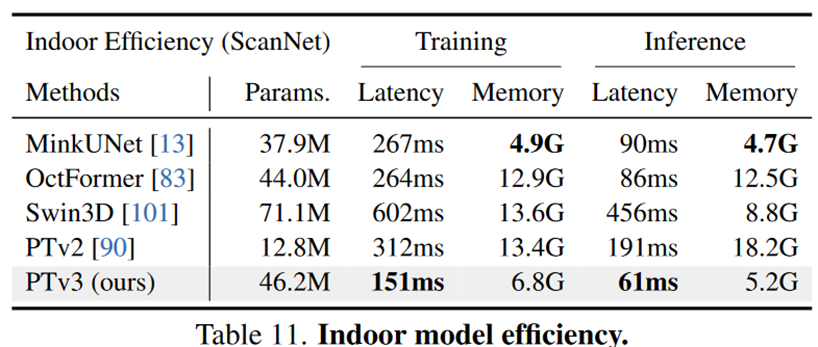
实现了显著的缩放,将感受野从16扩展到1024点,同时很高效(相比于其前身PTv2 ,处理速度提高了3倍,内存效率提高了10倍)。

创新点
1.按特定模式组织的点云(体素化后的点云序列)的邻域替代KNN查询邻居(28%的forward time)。
2.用适合序列化点云的精简方法替换复杂的注意力机制。
3.消除相对位置编码的依赖(26%的forward time),用xCPE。
局限性和前景
1.使用点积注意力,与向量注意力对比,收敛速度降低且进一步缩放也受到限制。
2.已经表现出对现有任务的性能过剩,想提出综合的方法,充分释放潜力(多模态)。
3.多模态:序列化可将n维数据转为结构化的一维数据,且保留了空间临近性,同样可以用于图像,为整合图像和点云数据的大规模协同预训练创造了机会。
原理
一般模型性能中准确性和效率不可兼得,大多是牺牲效率以获得准确性。
然而准确性和效率之间并不绝对冲突(稀疏卷积)。
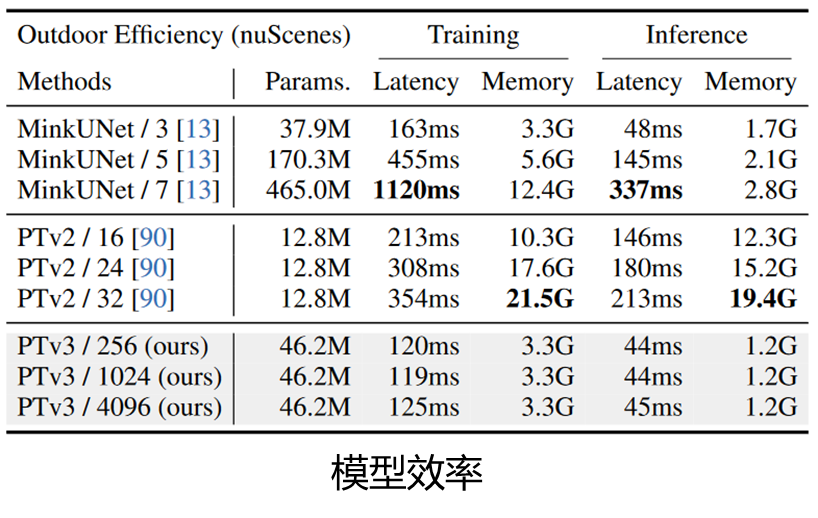
/后面的数字是卷积核大小或者说邻居数量。
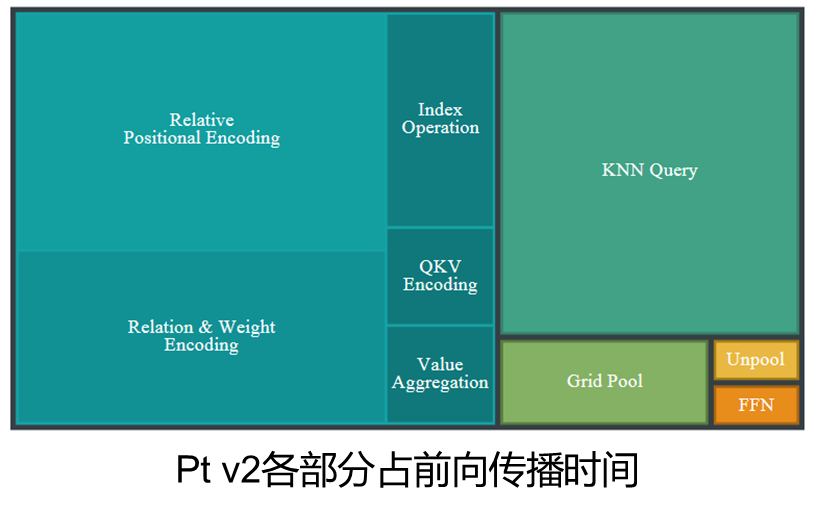
Knn(28%)和rpe(26%)占据了大量的前向传播时间。
Serialization
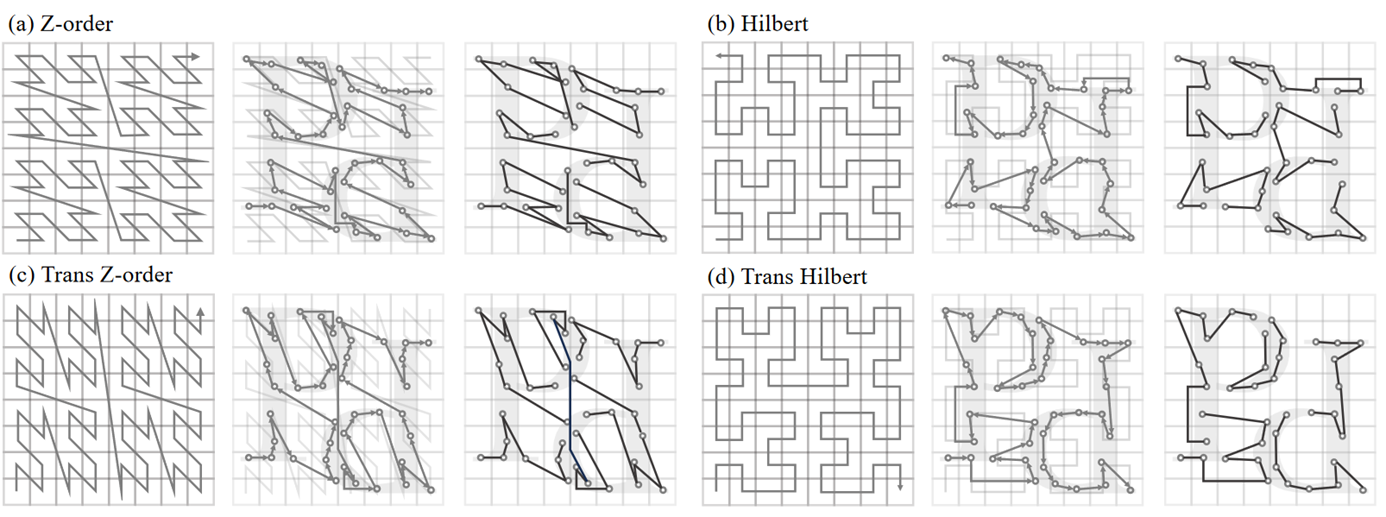
空间填充曲线:在更高维的离散空间中通过每一点且在一定程度上保持空间邻近性的路径。
z-order曲线:简单性和易于计算。Hilbert曲线:更优越的局部保持特性。
标准的空间填充曲线通过xyz的顺序遍历,改变遍历顺序,如先y再x,得到重排序变体(trans)。
优点:数据结构中的相邻点在空间中也可能是相邻的。没有进行物理上的重排,而是记录一个映射。保持了对各种序列化模式的兼容性,并为它们之间的有效转换提供了灵活性。
可表示为一个双射函数φ:Z→Zn和φ−1:Zn→Z。
将一个位置p投影到一个网格大小为g∈R的离散空间上,记为φ-1(⌊p/g⌋)
编码过程:为每个点分配64bit整数来记录序列化码,后k位分配给φ-1编码,其余位分配给批次索引b∈Z
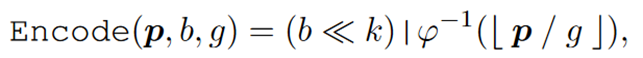
≪表示向左移位,|表示按位或。
Serialized Attention
序列化的自注意主要包含两个部分:分组和窗口自注意,且各窗口间最好有交互(swin)。
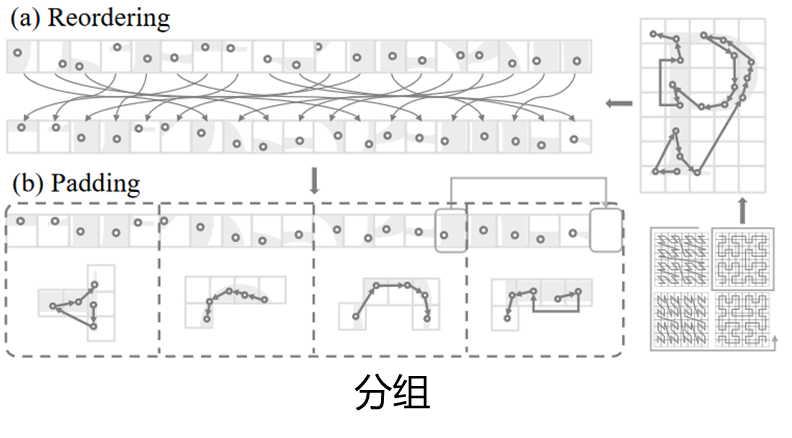
Padding:从邻居patch中拿一个point过来(空的,那随便拿有什么区别?)
尽管与KNN相比,这种分组方法可能会牺牲一些邻域搜索的准确性,但这种牺牲是有益的。
鉴于注意力对参考点的重新加权能力,在效率和扩展性上的增益远远超过了邻域精度的轻微损失。
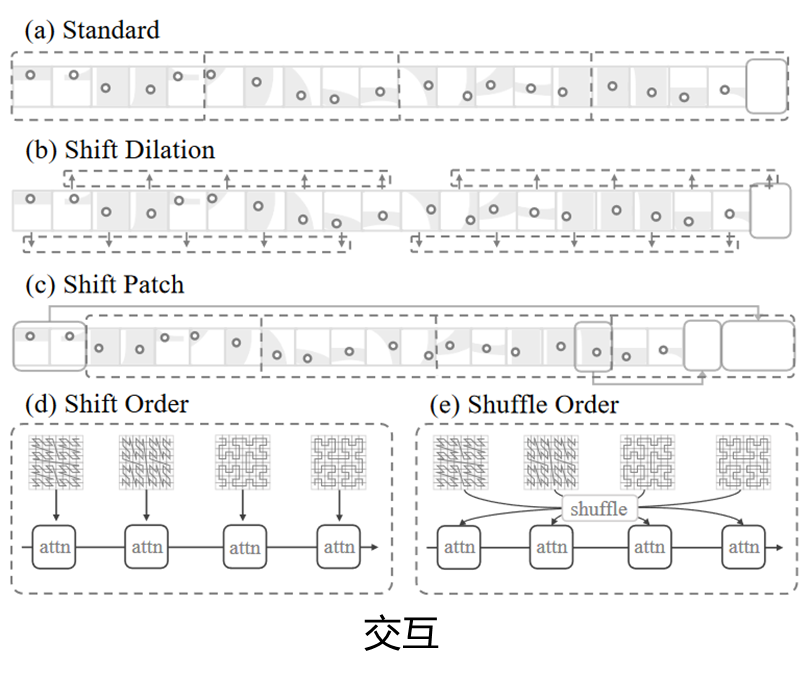
Shift Patch:patche的位置在序列化的点云中进行了移动,最大化patche之间的交互。
Shift Order:点云数据的序列化顺序在注意力块之间动态变化。防止模型过度拟合单一模式,促进数据之间更强大的特征整合。
Shuffle Order:引入了随机洗牌。每个注意力层的感受野不受限于单一模式,提高泛化能力。
Architecture
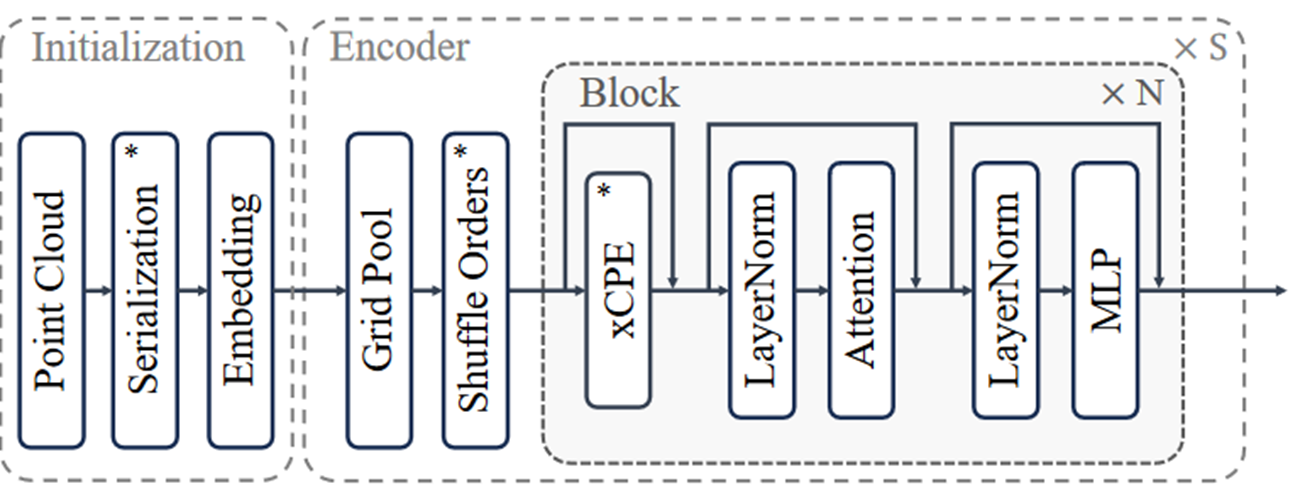
以前一般用相对位置编码RPE,但效率低且复杂。使用xCPE。
增强的条件位置编码(xCPE),通过在注意力层之前添加一个带有跳跃连接的稀疏卷积层来实现。
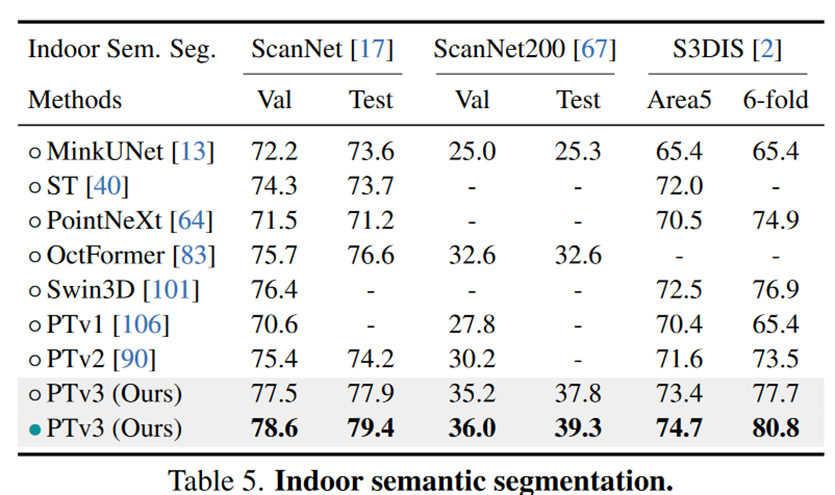
Experiments
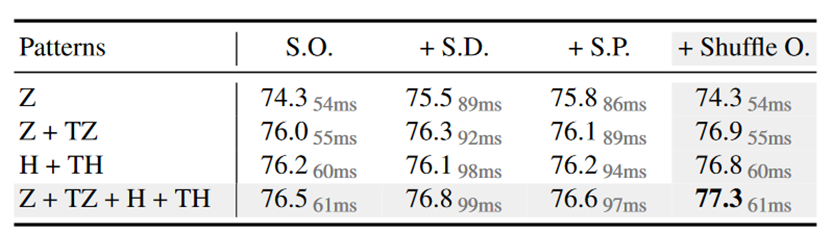
序列化方法,以及多种窗口交互的对比。

多种位置编码的对比。

不同Patch大小的对比。














 1213
1213











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









