







遗传算法和差分进化算法
遗传算法(Genetic Algorithm,GA)和差分进化算法(Differential Evolution,DE)都是优化算法,可以用于搜索和优化参数空间以寻找支持向量机(Support Vector Machine,SVM)模型的最佳参数。
遗传算法(GA):
遗传算法模拟了生物进化中的基因遗传和适者生存的过程。
在优化SVM参数时,可以将SVM的参数(例如核函数类型、惩罚因子C、核函数参数等)编码为染色体。遗传算法通过选择、交叉和变异的操作来操作这些染色体,生成新的参数组合。适应度函数可以根据SVM在训练集或交叉验证集上的性能来评价每个参数组合的好坏。遗传算法根据适应度函数评价参数组合的表现,并通过遗传操作生成新一代参数组合,直到找到满意的解或达到迭代次数。
差分进化算法(DE):
差分进化算法是一种基于群体搜索的优化算法,通过迭代寻找最优解。
DE通常通过随机选择种群中的个体来形成新的个体,并通过变异和交叉操作来产生新的参数组合。
对于SVM参数优化,DE也可以将SVM的参数编码成个体,并通过差分变异等操作来生成新的参数组合。
适应度函数用于评估每个参数组合的性能,以指导差分进化算法生成下一代参数组合。
差分进化算法重复迭代直到收敛或达到预设的停止条件。
SVM分类数据:
这里的数据选择阿里天池的心跳数据集, 4000条数据分为7:3;
from sklearn import neural_network as nn
import time
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold
from sklearn.metrics import make_scorer,f1_score,accuracy_score, precision_score,recall_score
from sklearn.svm import SVC
from bayes_opt import BayesianOptimization
data = pd.read_csv('D://data.csv')
data = data.drop(columns = ['id']) #删除‘id’那一列
new_data=pd.DataFrame(columns=['heartbeat_signals','label'])
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
for i in range(4):
d=data[data['label']==i]
train_data=d.sample(n=1000,axis=0)
new_data=pd.concat([new_data,train_data],ignore_index=True)
new_data = reduce_mem_usage(new_data)
new_data=np.array(new_data)
print(new_data.shape)
Y=new_data[:,-1]
Y=np.float64(Y).reshape(-1,1)
X_train, X_test, y_train, y_test = train_test_split(new_data[:,0:-1], Y, test_size=0.3, random_state=42)
print(y_train)
X_train=X_train.tolist()
X_test=X_test.tolist() #将序列转换为列表的函数
for i in range(len(X_train)):
X_train[i]=''.join(X_train[i])
X_train[i]=X_train[i].split(',')
X_train[i]=[float(j) for j in X_train[i]]
# X_train[i]=[float(j) for j in X_train[i]]
X_train=np.array(X_train)
print(X_train.shape,y_train.shape)
for i in range(len(X_test)):
X_test[i]=''.join(X_test[i])
X_test[i]=X_test[i].split(',')
X_test[i]=[float(j) for j in X_test[i]]
X_test=np.array(X_test)
print(X_test.shape,y_test.shape)
利用OPT库内的遗传算法和差分进化算法,对SVM模型的参数进行寻优,寻找最佳参数组合。
对SVM进行遗传算法寻优和差分进化算法寻优:
总代码:
from sklearn import neural_network as nn
import time
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold
from sklearn.metrics import make_scorer,f1_score,accuracy_score, precision_score,recall_score
from sklearn.svm import SVC
from bayes_opt import BayesianOptimization
data = pd.read_csv('data.csv')
data = data.drop(columns = ['id']) #删除‘id’那一列
new_data=pd.DataFrame(columns=['heartbeat_signals','label'])
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
for i in range(4):
d=data[data['label']==i]
train_data=d.sample(n=1000,axis=0)
new_data=pd.concat([new_data,train_data],ignore_index=True)
new_data = reduce_mem_usage(new_data)
new_data=np.array(new_data)
print(new_data.shape)
Y=new_data[:,-1]
Y=np.float64(Y).reshape(-1,1)
X_train, X_test, y_train, y_test = train_test_split(new_data[:,0:-1], Y, test_size=0.3, random_state=42)
print(y_train)
X_train=X_train.tolist()
X_test=X_test.tolist() #将序列转换为列表的函数
for i in range(len(X_train)):
X_train[i]=''.join(X_train[i])
X_train[i]=X_train[i].split(',')
X_train[i]=[float(j) for j in X_train[i]]
# X_train[i]=[float(j) for j in X_train[i]]
X_train=np.array(X_train)
print(X_train.shape,y_train.shape)
for i in range(len(X_test)):
X_test[i]=''.join(X_test[i])
X_test[i]=X_test[i].split(',')
X_test[i]=[float(j) for j in X_test[i]]
X_test=np.array(X_test)
print(X_test.shape,y_test.shape)
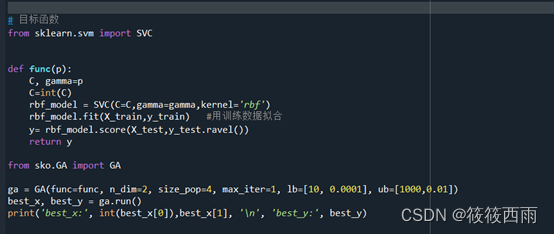
# 目标函数
from sklearn.svm import SVC
def func(p):
C, gamma=p
C=int(C)
rbf_model = SVC(C=C,gamma=gamma,kernel='rbf')
rbf_model.fit(X_train,y_train) #用训练数据拟合
y= rbf_model.score(X_test,y_test.ravel())
return y
from sko.GA import GA
ga = GA(func=func, n_dim=2, size_pop=4, max_iter=1, lb=[10, 0.0001], ub=[1000,0.01])
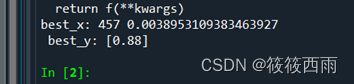
best_x, best_y = ga.run()
print('best_x:', int(best_x[0]),best_x[1], '\n', 'best_y:', best_y)
'''
# 目标函数
# 目标函数
from sklearn.svm import SVC
def obj_func(p):
C, gamma=p
C=int(C)
rbf_model = SVC(C=C,gamma=gamma,kernel='rbf')
rbf_model.fit(X_train,y_train) #用训练数据拟合
y= rbf_model.score(X_test,y_test.ravel())
return y
from sko.DE import DE
de = DE(func=obj_func, n_dim=2, size_pop=4, max_iter=1, lb=[10, 0.0001], ub=[1000,0.01])
best_x, best_y = de.run()
print('best_x:', int(best_x[0]),best_x[1], '\n', 'best_y:', best_y)
'''


















 1553
1553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









