







VLN算法学习:DUET——首篇使用Transformer来建模全局图节点相关性的工作Think Global, Act Local:Dual-scale Graph Transformer
【VLN入门介绍】
一文搞懂视觉语言导航,从任务介绍到基本算法讲解:https://blog.csdn.net/qq_50001789/article/details/144676313
【VLN算法笔记】
DUET(CVPR2022),首篇使用Transformer来建模全局图节点相关性的工作:https://blog.csdn.net/qq_50001789/article/details/144632851
AZHP(CVPR2023),使用自适应区域分层规划器来实现层次化导航的目的:https://blog.csdn.net/qq_50001789/article/details/144635128
GridMM(ICCV2023),使用网格记忆图来表征历史轨迹中的场景空间关系:https://blog.csdn.net/qq_50001789/article/details/144652403
【VLN辅助任务】
MLM、SAP、SAR、SPREL——预训练、微调中常用的提点策略:https://blog.csdn.net/qq_50001789/article/details/144633984
【VLN环境配置】
Matterport3DSimulator——用于视觉语言导航算法研发的仿真环境配置:https://blog.csdn.net/qq_50001789/article/details/142621259
综述
论文题目:《Think Global, Act Local: Dual-scale Graph Transformer for Vision-and-Language Navigation》
源码链接:https://github.com/cshizhe/VLN-DUET
论文出处:CVPR 2022
关键词:全局图结构特征(粗尺度)、局部全景图像特征(细尺度特征)
这一篇是非常经典的“边走边建图”论文,利用transformer建模历史节点之间的全局相关性,后续有很多VLN方法是基于这篇文章的框架做的改进。
背景
为了有效地探索新领域(或者纠正以前的错误决定),智能体应该在其记忆(memory)中跟踪已经执行的指令和访问过的位置。之前的方法大多分为两类,第一种方法使用循环架构递归建模历史信息,并将导航历史压缩在固定大小的向量中,这种隐式记忆机制在存储和利用丰富时空结构的先验经验方面效率比较低下,例如baseline中的Seq2seq架构的方法,将所有的历史信息都存到一个隐藏状态特征中;第二种方法显式存储先前的观察和动作,并且通过Transformer为动作预测建模长期依赖关系,然而这类模型只允许局部操作,即移动到相邻的位置,因此智能体必须执行导航模型N次才能回溯N步,这增加了不稳定性和计算量。
一个具有潜力的解决方案是每走一步,就建立一个全局节点地图(图结构),该地图明确地跟踪到目前为止所有观测到的访问节点以及可导航点的位置(也称候选节点candidate),并且允许智能体制定有效的长期导航计划,例如智能体能够从地图上所有可导航点的位置选择一个长期导航目标,之后使用传统算法(例如迪杰斯特拉算法)计算到目标的最短导航路径。然而,这类方法存在两个问题:
- 他们依赖于循环架构跟踪导航状态,也就是按走过的节点顺序传入lstm中,利用lstm这种递归式的建模策略建模导航过程,这一方法不利于智能体建模全局图结构特征的远距离关联关系;(Transformer建模序列间关系时,不会考虑访问节点之间的先后顺序,也就是无法建模导航过程,所以不能直接用Transformer来建模)
- 拓扑图中的每个节点通常由压缩的视觉特征表示,粒度比较粗糙,因此缺乏细节,无法在指令中感知到细粒度对象和场景描述。
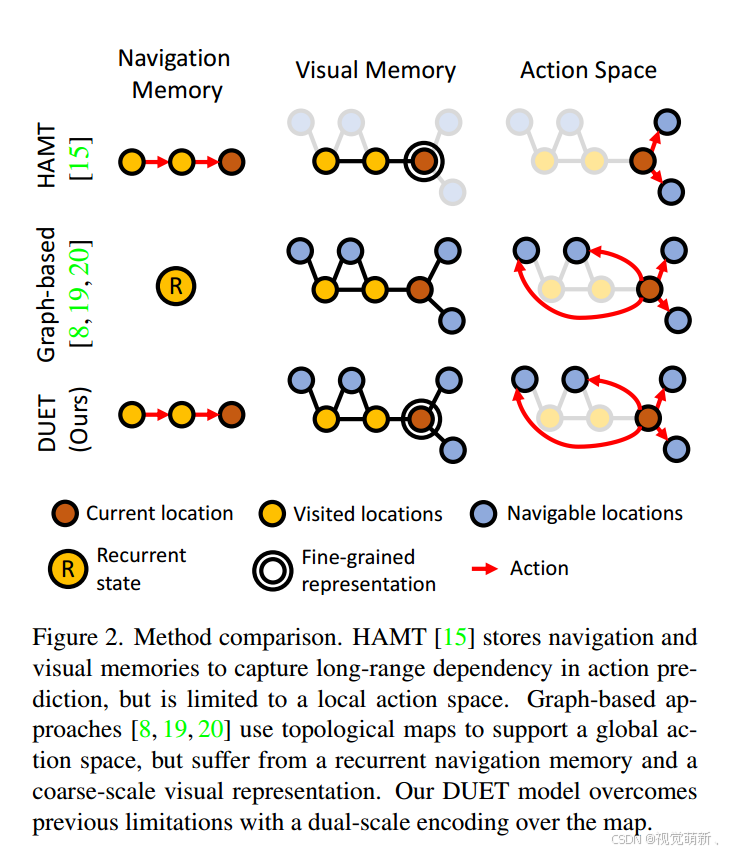
主要思想
本文主要从解决这两个缺点入手改进,针对第一个问题设计了基于变压器结构的全局图建模模块,通过为节点特征引入具有位置属性的编码(例如相对远近关系、朝向等)以及在注意力图上引入mask图,来实现兼顾建模智能体导航过程的同时,建模全局图节点之间的远程依赖关系。第二设计了双尺度动作规划方法,利用全局的图节点特征预测全局视角下的导航节点(粗粒度),同时利用局部的全景视图特征来预测局部视角下的导航节点(细粒度),最终将两个尺度下的动作预测相融合,得到算法最终的导航节点。结合这两个模块,作者提出了一种具有拓扑映射的双尺度图Transformer算法(Dual-scale graph Transformer, DUET)。如下图所示,该算法主要由两个模块组成:拓扑映射和全局动作规划。在拓扑映射中,作者通过向地图中添加新观测到的位置并更新节点的视觉特征来构建随时间变化的拓扑地图。之后,在每一步中,全局动作规划模块预测地图中的下一个目标位置或者停止动作。为了平衡全局图上的细粒度语言基础推理(grounding and reasoning),作者采用动态融合模块融合来自双尺度的动作预测:当前位置的细尺度表征和全局图的粗尺度表征。作者采用Transformer来捕获跨模态的视觉和语言关系,并通过将拓扑知识引入Transformer中来改进映射编码,在训练阶段使用模仿学习和辅助任务来对模型进行预训练,并提出一个伪交互演示器来进一步改进策略学习。

方法
问题公式化
在标准的VLN设置中,环境是一个无向图 G = { V , E } \mathcal G=\{\mathcal V,\mathcal E\} G={V,E},其中 V = { V i } i = 1 K \mathcal V=\{V_i\}^K_{i=1} V={Vi}i=1K表示 K K K个可导航的点, E \mathcal E E表示连接各个节点的边。智能体配备了RGB相机和GPS传感器,并且在以前未见过的环境中随机初始化起点。智能体的目标是解释自然语言指令,并且遍历图到目标位置,找到指令指向的对象。 W = { w i } i = 0 L \mathcal W=\{w_i\}^L_{i=0} W={wi}i=0L是包含 L L L个单词的指令编码,在每个时间步 t t t中,智能体接收到当前节点 V t V_t Vt的全景视图和位置坐标,全景图被分割成 n n n个图像 R t = { r i } i = 0 n \mathcal R_t=\{r_i\}^n_{i=0} Rt={ri}i=0n,每个图像由一个图像特征向量 r i r_i ri和一个唯一的方向表示,为了实现细粒度的视觉感知,使用带注释的对象边界框或者目标检测器在全景图中提取 m m m个对象特征 O t = { o i } i = 1 m \mathcal O_t=\{o_i\}^m_{i=1} Ot={oi}i=1m,此外,智能体还知道一些与其相邻的节点 N ( V t ) \mathcal N(V_t) N(Vt)及其坐标(又称为候选点candidate、可导航点navigable),可导航的视图 N ( V t ) \mathcal N(V_t) N(Vt)是图像集合 R t \mathcal R_t Rt的子集,步骤 t t t可能的局部动作空间 A t \mathcal A_t At包含导航到 V i ∈ N ( V t ) V_i\in\mathcal N(V_t) Vi∈N(Vt)并且在 V t V_t Vt处停止,当智能体决定在某个位置停止后,它需要预测目标在全景图中的位置。
拓扑映射
对于最初的智能体并不知道环境的图 G \mathcal G G,本算法使用沿着路径的节点观测来建立自己的全局节点地图。假设在步骤 t t t时建立的图表示为 G t = { V t , E t } \mathcal G_t=\{\mathcal V_t, \mathcal E_t\} Gt={Vt,Et},其中 G t ∈ G \mathcal G_t\in\mathcal G Gt∈G,并且有 K t K_t Kt个节点, V t \mathcal V_t Vt中有三种类型的节点,具体如下图所示:其中黄色的为访问过的节点(visited node)、蓝色的为可导航节点(navigable node,又称候选节点candidate node)、红色的为当前节点(current node)。

智能体可以访问所有访问节点和当前节点的全景视图,可导航节点是未探索的,并且只能从已经访问过的节点中部分地观测到,因此他们具有不同的视觉表示。在每个步骤 t t t中,本算法将当前节点 V t V_t Vt的视觉特征及其相邻未访问的节点 N ( V t ) \mathcal N(V_t) N(Vt)的部分视觉特征添加到 V t − 1 \mathcal V_{t-1} Vt−1中,并且相应地更新 E t − 1 \mathcal E_{t-1} Et−1。
节点视觉特征的构建
在时间步
t
t
t中,智能体接收到节点
V
t
V_t
Vt的图像特征
R
t
\mathcal R_t
Rt和目标特征
O
t
\mathcal O_t
Ot,使用多层Transformer来建模图像与目标之间的空间关联,自注意力运算过程可以表示为:
[
R
t
′
,
O
t
′
]
=
S
e
l
f
A
t
t
n
(
[
R
t
,
O
t
]
)
,
S
e
l
f
A
t
t
n
(
X
)
=
S
o
f
t
m
a
x
(
X
W
q
(
X
W
k
)
T
d
)
X
W
v
[\mathcal R'_t, \mathcal O'_t]=SelfAttn([\mathcal R_t, \mathcal O_t]),\\ SelfAttn(X)=Softmax\left(\frac{XW_q(XW_k)^T}{\sqrt{d}}\right)XW_v
[Rt′,Ot′]=SelfAttn([Rt,Ot]),SelfAttn(X)=Softmax(dXWq(XWk)T)XWv
其中
W
∗
∈
R
d
×
d
W_*\in\mathbb R^{d\times d}
W∗∈Rd×d为线性映射参数,为了便于标记,在下文使用
R
t
\mathcal R_t
Rt和
O
t
\mathcal O_t
Ot来表示编码特征。
之后将特征沿空间维度进行平均池化压缩特征(36个特征向量压缩成1个特征向量),用于更新当前节点的特征表示。由于智能体在 V t V_t Vt处也能部分地观察到 N ( V t ) \mathcal N(V_t) N(Vt),因此我们可以根据 R t \mathcal R_t Rt中相对应的视图特征来积累这些相邻可导航点的视觉特征,如果从多个位置看到了一个可导航节点,那么将所有的部分视觉特征做平均池化,可以将其视为当前相邻点的视觉特征。使用 v i v_i vi来表示每个节点 V i V_i Vi的池化视觉特征。这种粗尺度的视觉表征可以对大型图进行有效的推理,但可能无法为细粒度的语言基础(尤其是对象)提供足够的信息,因此,本文保留了 R t \mathcal R_t Rt和 O t \mathcal O_t Ot作为当前节点 V t V_t Vt的细粒度视觉特征,从而支持精细尺度上的详细推理。
注意:每当访问到一个节点时,如果这个节点被部分观测到,则会直接替换掉部分观测的特征。
全局动作规划
具体流程如下图所示,粗尺度编码器使用粗尺度视觉特征,对所有先前访问过的节点进行全局动作的预测,细尺度编码器则根据当前位置的细粒度视觉表征来预测局部动作,两个编码器的动态融合结合了对全局和局部动作的预测,可以生成更完备的动作预测结果。

文本编码器
对于 W \mathcal W W中的单词编码,添加一个对应于单词在句子中位置的位置编码和一个文本类型编码,之后将所有的单词token送入多层transformer中,从而获得上下文的单词特征,在这里表示为 W ^ = { w ^ 1 , … , w ^ L } \hat{\mathcal W}=\{\hat{w}_1,\dots,\hat{w}_L\} W^={w^1,…,w^L}。
粗尺度跨模态编码器
该模块采用粗尺度地图 G t \mathcal G_t Gt和编码指令 W ^ \hat{\mathcal W} W^在全局动作空间上进行导航预测( ∪ i = 1 t A i \cup^t_{i=1}\mathcal A_i ∪i=1tAi)
节点编码
为节点视觉特征 v i v_i vi添加了位置编码和导航步骤编码,位置编码将地图中节点的位置嵌入到以自我为中心的视图中,这是相对于当前节点的方向和距离,导航步骤编码为访问节点编码最近(latest)的时间步长,为未探索的节点嵌入0,通过这种方式,访问节点使用不同的导航历史信息进行编码,以改进与指令的一致性,同时本算法在图中添加了一个“停止”节点 v 0 v_0 v0来表示停止动作,并且将其与所有其他节点连接起来。
图感知的跨模态编码
节点的编码特征和单词特征传入多层突感值得跨模态Transformer(graph-aware cross-modal encoding)中,每个transformer包括一个交叉注意力,用于对接点特征和指令特征之间的关系进行建模,同时还包括一个图感知自注意力层,用于对环境布局进行编码。简单的自注意力模块只会考虑节点之间的视觉相似性(例如节点特征建模时用到的自注意力),因此可能会忽略节点之间的远近关系(相比于远节点来说,近节点应该会更相关)。为了解决这个问题,本文提出了图感知自注意力模块,进一步考虑了图的结构来计算注意力:
G
A
S
A
(
X
)
=
s
o
f
t
m
a
x
(
X
W
q
(
X
W
k
)
T
d
+
M
)
X
W
v
M
=
E
W
e
+
b
e
GASA(X)=softmax\left(\frac{XW_q(XW_k)^T}{\sqrt{d}}+M\right)XW_v\\ M=EW_e+b_e
GASA(X)=softmax(dXWq(XWk)T+M)XWvM=EWe+be
其中,
X
X
X表示节点的特征,
E
E
E为由
E
t
\mathcal E_t
Et得到的成对距离矩阵,
W
e
W_e
We和
b
e
b_e
be是两个可学习的参数,本文在编码器中堆叠
N
N
N层,并且将节点
V
i
V_i
Vi的输出表示成
v
^
i
\hat{v}_i
v^i,M是由节点之间的距离映射而来(相当于距离乘以一个可学习的参数)。
注意:节点编码中位置编码和导航步骤编码的引入,为每个节点特征赋予了不同的导航意义,同时在注意力权重中引入距离参数,可以在相似度关联计算的过程中引入节点的相对位置先验,两个模块可以共同促进Transformer对导航过程的建模。
全局动作预测
本模块用来预测
G
t
\mathcal G_t
Gt中每个节点
V
i
V_i
Vi的导航分数:
s
i
c
=
F
F
N
(
v
^
i
)
s^c_i=FFN(\hat{v}_i)
sic=FFN(v^i)
其中
F
F
N
FFN
FFN表示两侧前馈神经网络,需要注意的是,
s
0
c
s^c_0
s0c是停止分数(对应数组中第一个数),在大多数VLN任务中,智能体不需要重新访问已经访问过的节点,因此如果没有特别需求,本算法会掩盖访问节点的预测分数(直接加一个mask覆盖住节点分数)。
细尺度跨模态编码器
本模块用于关注图中的当前位置 V t V_t Vt,从而实现细尺度的跨模态推理,模块的输入是指令特征 W ^ t \hat {\mathcal W}_t W^t和当前节点的细粒度视觉特征 { R t , O t } \{\mathcal R_t, \mathcal O_t\} {Rt,Ot},用于预测局部动作空间中的导航节点。
视觉特征编码
本模块在 R t , O t \mathcal R_t, \mathcal O_t Rt,Ot中添加两种类型的位置编码,第一种类型是当前节点相对于开始节点的相对位置编码,有助于智能体理解指令中的绝对位置,例如:“去一楼的餐厅。之后,对于 V i ∈ N ( V t ) V_i\in\mathcal N(V_t) Vi∈N(Vt),本算法再添加一个相对位置编码,即每个相邻点与当前相邻点的相对位置关系,帮助编码器实现以自我为中心的相对方向感知,如理解”左转“,为停止动作添加一个特殊的”停止“token r 0 r_0 r0
细粒度跨模态推理
算法首先合并 [ r 0 ; R t ; O t ] [r_0;\mathcal R_t;\mathcal O_t] [r0;Rt;Ot]作为视觉特征token,并且利用标准的多层跨模态transformer来建模视觉和语言的关联关系(由交叉注意力、自注意力组成),输出的视觉编码特征分别被表示为 r ^ 0 , R ^ t , O ^ t \hat{r}_0,\hat{\mathcal R}_t,\hat{\mathcal O}_t r^0,R^t,O^t。
局部动作预测和对象定位
本方法预测了局部动作空间 A t \mathcal A_t At中的导航分数 s i f s^f_i sif(与全局动作预测公式类似),此外,由于面向目标的VLN任务需要定位对象(object grounding),因此本模块进一步使用FFN来生成基于 O ^ t \hat{\mathcal O}_t O^t的目标分数。
动态融合
本文动态地融合粗尺度和细尺度的动作预测,用于更好地得到全局动作的预测。然而,细尺度编码器在局部动作空间中预测节点,这与粗尺度编码器不匹配,因此本文首先将局部节点分数
s
i
f
∈
{
s
t
o
p
,
N
(
V
t
)
}
s^f_i\in\{stop, \mathcal N(V_t)\}
sif∈{stop,N(Vt)}转为全局动作空间中的节点分数,为了导航到其他未与当前节点连接的未探索节点,智能体需要通过其邻近的访问节点进行回溯,因此本文将局部节点分数
N
(
V
t
)
\mathcal N(V_t)
N(Vt)中访问节点的分数相加作为总体回溯分数
s
b
a
c
k
s_{back}
sback。我们保留
s
i
f
∈
{
s
t
o
p
,
N
(
V
t
)
}
s^f_i\in\{stop, \mathcal N(V_t)\}
sif∈{stop,N(Vt)}的值,并对其他值使用常数
s
b
a
c
k
s_{back}
sback,因此转换后的全局节点得分为:
s
i
f
′
=
{
s
back
,
if
V
i
∈
V
t
−
N
(
V
t
)
,
s
i
f
,
otherwise.
s_i^{f'}=\begin{cases}s_\text{back},\text{ if }V_i\in\mathcal{V}_t-\mathcal{N}(V_t),\\s_i^f,\text{ otherwise.}\end{cases}
sif′={sback, if Vi∈Vt−N(Vt),sif, otherwise.
在每一步中,我们将来自粗尺度编码器的
v
^
0
\hat{v}_0
v^0和来自细尺度编码器的
r
^
0
\hat{r}_0
r^0连接起来,用于预测融合权重:
σ
t
=
Sigmoid
(
F
F
N
(
[
v
^
0
;
r
^
0
]
)
)
\sigma_t=\text{Sigmoid}(FFN([\hat{v}_0;\hat{r}_0]))
σt=Sigmoid(FFN([v^0;r^0]))
对于节点
V
i
V_i
Vi最终的导航分数为:
s
i
=
σ
t
s
i
c
+
(
1
−
σ
t
)
s
i
f
′
s_i=\sigma_ts^c_i+(1-\sigma_t)s^{f'}_i
si=σtsic+(1−σt)sif′
训练与测试
预训练策略:在正式训练模型导航能力之前,首先采用相关的辅助任务来提升模型对导航任务的理解,也就是对模型参数做一个预训练。本文采用MLM(masked language modeling)、MRC(masked region classification)、SPA(single-step action prediction)来实现模型参数的预训练,在目标导航中还使用OG(object grounding)损失来优化模型的参数。
微调策略:通过交互式策略进行策略学习,由于行为克隆(模仿学习)受到训练和测试之间分布变化的影响,因此作者在这里使用类似于DAgger算法的伪交互演示器(PID)
π
∗
\pi_*
π∗的监督下进一步训练策略,在训练过程中,作者可以访问环境图
G
\mathcal G
G,因此
π
∗
\pi_*
π∗可以利用
G
\mathcal G
G来选择下一个目标节点,即从当前节点到最终目的地的总距离最短的可导航节点,在每次迭代中,作者使用当前策略对轨迹
P
\mathcal P
P进行采样,并使用
π
∗
\pi_*
π∗获得伪监督:
L
P
I
D
=
∑
t
=
1
T
−
log
p
(
a
t
π
∗
∣
W
,
P
<
t
)
L_{PID}=\sum^T_{t=1}-\log p(a^{\pi^*}_t|\mathcal W,\mathcal P_{<t})
LPID=t=1∑T−logp(atπ∗∣W,P<t)
其中
a
t
π
∗
a^{\pi^*}_t
atπ∗是步骤
t
t
t的伪目标,作者在这里将原始专家演示与策略学习中的伪演示结合起来,并且使用平衡因子
λ
\lambda
λ计算总损失:
L
=
λ
L
S
A
P
+
L
P
I
D
+
L
O
G
L=\lambda L_{SAP}+L_{PID}+L_{OG}
L=λLSAP+LPID+LOG
推理过程:在测试期间的每个时间步中,我们都会更新一次全局拓扑映射,之后预测一次全局动作,如果是导航动作,则最短路径模块采用Floyd算法,在给定地图的情况下,获取当前节点到预测节点的最短路径,否则智能体停在当前位置。如果超过了最大步骤,智能体将被迫停止,在这种情况下,它将返回到具有最大停止概率的节点作为其最终预测,在停止位置,智能体选择一个对象预测得分最高的对象。
动作,则最短路径模块采用Floyd算法,在给定地图的情况下,获取当前节点到预测节点的最短路径,否则智能体停在当前位置。如果超过了最大步骤,智能体将被迫停止,在这种情况下,它将返回到具有最大停止概率的节点作为其最终预测,在停止位置,智能体选择一个对象预测得分最高的对象。
实验结果
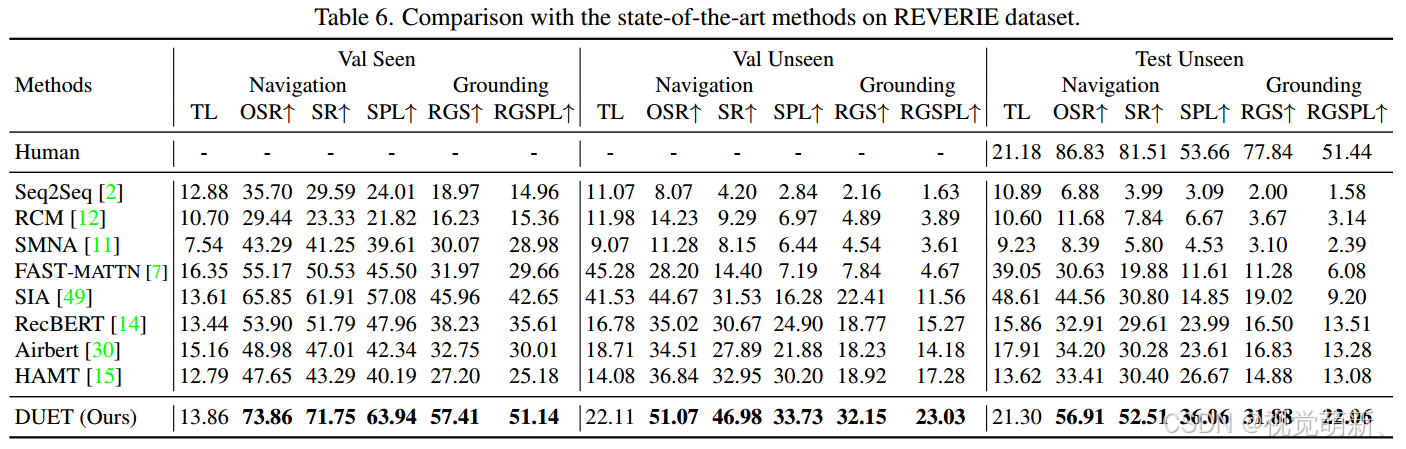
REVERIE
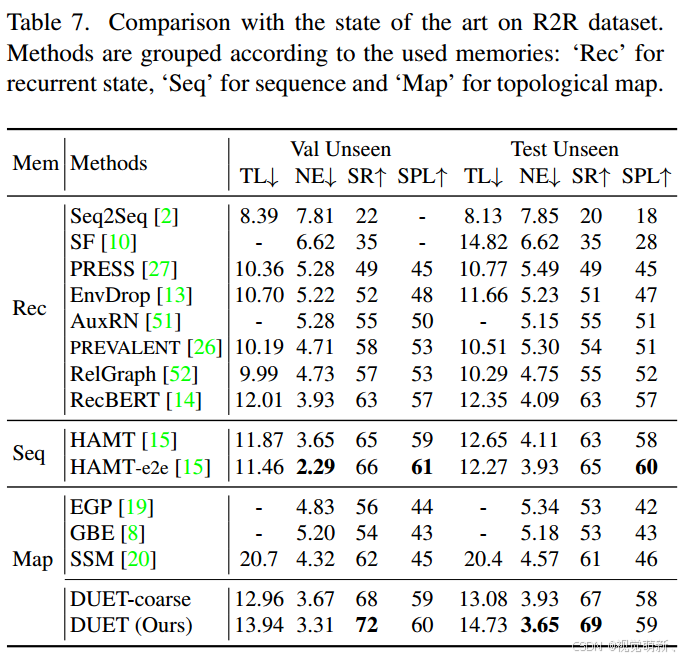
R2R
以上仅是笔者的个人见解,若有问题,欢迎指正。



















 3014
3014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











