







【万字解读、通用灵巧手抓取】UniDexGrasp算法学习——王鹤老师首篇通用灵巧手抓取算法Universal Robotic Dexterous Grasping
基本信息
论文题目:《UniDexGrasp: Universal Robotic Dexterous Grasping via Learning Diverse Proposal Generation and Goal-Conditioned Policy》
论文出处:CVPR23、王鹤老师团队
背景
机器人抓取是智能体与环境交互的基本能力,也是进行操作的先决条件。近年来,平行夹持器抓取算法的开发取得了很大的进展,在抓取未知物体时的成功率很好,然而平行抓取的一个基本限制是它的低灵活性,限制了他在复杂任务场景中的应用。灵巧手抓取具有高维的动作空间,提供了一种多样化的物体抓取方式,对于机器人的功能性和细粒度物体操作至关重要。然而,动作空间的高维性同样为实现准确的物体抓取带来了较大的挑战,作为一种广泛使用的五指机器人灵巧手,ShadowHand的自由度高(Degrees of Freedom, DoF)达26个,而典型的并联抓取器只有7个自由度,这种高维度特性增加了产生有效抓取姿态和规划执行轨迹的难度,这也是灵巧手抓取任务与平行抓取任务最大的区别。
一些工作已经解决了抓取姿态合成的问题,然而他们都假设输入为oracle state输入(例如给定物体完整的几何形状和状态),很少有工作聚焦于在现实的机器人环境中解决灵巧抓取问题(例如以物体的点云分布为输入、或者相机捕获的图像为输入),同时现有的工作并没有展示出通用的和多样化的灵巧抓取策略,模型很难在unseen物体上完成抓握。
注:unseen object表示在训练过程中未见过的物体,类似的表述还有unseen scene、unseen task,unseen性能的好坏很大程度上反应了物体在实际应用中的泛化能力,与之对应的表述为seen,也就是在训练过程中见过的物体\场景\任务等等。
主要思想
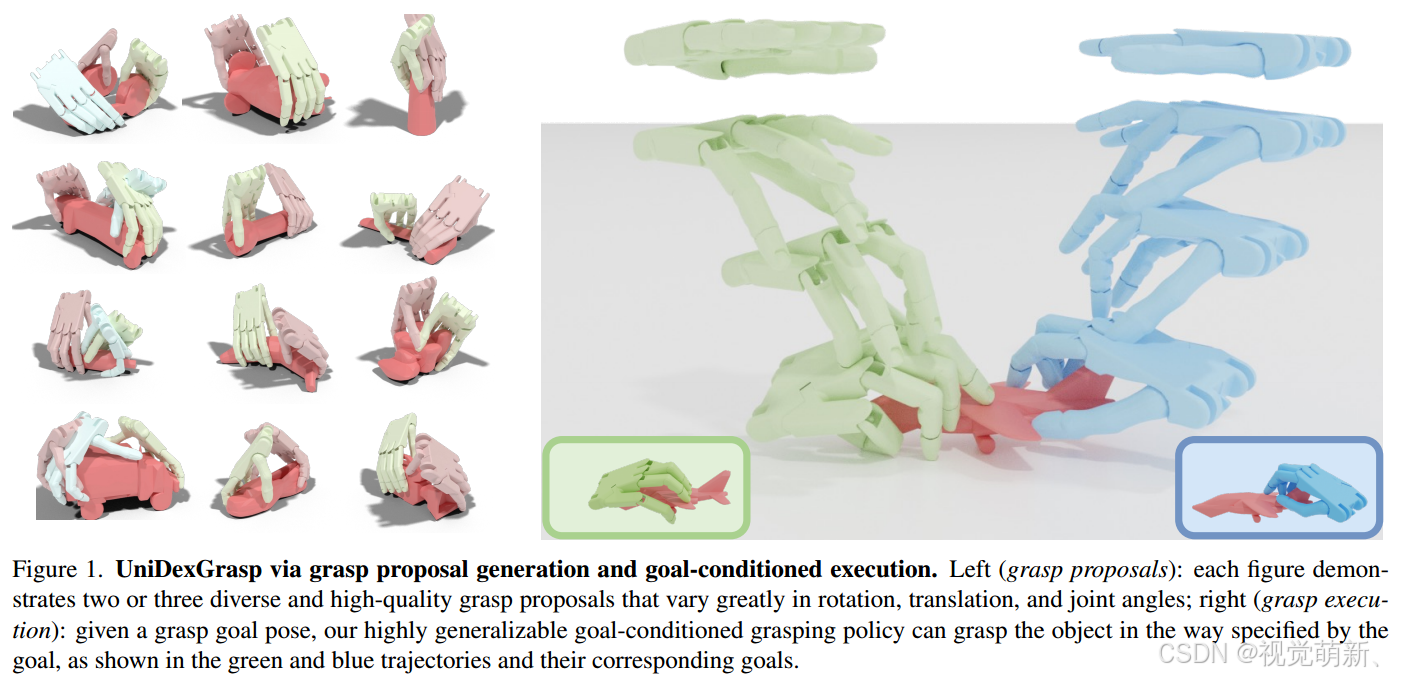
在本工作中,作者提出了一种可以实现通用灵巧手抓取的算法,算法可以在现实的机器人设置中完成数百中物体类别的抓握(包括seen和unseen物体类别),并且模型只需要输入深度观测数据和机器人本体的感觉信息(depth observation and robot proprioception information)。同时为了验证算法的有效性,作者利用DexGraspNet算法构建了一组灵巧手抓取数据集,数据集中含有超过100万次的抓取,其中包含来自133个目标类别的5519个目标实例。
受平行抓取器的成功pipeline启发,作者将这一任务分解为两个阶段:①灵巧抓取建议生成阶段(dexterous grasp proposal generation),在此过程中,根据点云观测预测不同的抓取姿态;②目标条件抓取执行(goal-conditioned grasp execution),以阶段1预测的抓取目标姿态为条件,生成符合目标姿态并且物理正确的动作轨迹。
在灵巧抓取建议生成阶段,作者设计了一种新的条件抓取姿态生成模型,该模型采用点云观测并在合成的大规模table-top数据集上进行训练,在这里,本方法强调抓取姿态生成的多样性,在实际应用中,抓取一个物体会有多种可能的方式,因此会对应许多不同的抓取姿态。在实际应用中,执行一个任务可能由多种动作组合完成,这一现象又称为动作的多峰分布现象(每种动作组合对应的概率可以视为一个概率峰值,因此成为多峰分布),传统的模仿学习大多利用分类损失来优化模型的动作预测能力,也就是以“非此即彼”的方式约束模型的动作预测,这一过程难以建模动作的多样性,也就是难以建模动作概率的多峰分布特性。对此,我们常用生成式损失来优化模型的动作预测能力,例如CVAE(GraspCVAE、GR2)、diffusion(diffusion policy、RDT)、flow(本算法、 π 0 \pi_0 π0)等算法。
GraspCVAE算法利用条件变分自编码器CVAE来联合建模手的旋转(rotation)、平移(translation)和关节(articulation),但是相比于条件归一化流(conditional normalizing flow)和条件扩散模型(conditional diffusion models)这种较为先进的生成式模型,CVAE的表达能力有限,存在严重的模式崩溃问题(mode collapse),难以生成多种抓取姿态。抓取姿态空间是由手旋转(SO(3)笛卡尔积)、手平移量(欧式空间距离)、关节夹角组成。因此,作者将该条件生成模型解耦成两个条件生成模型:①利用ImplicitPDF(IPDF)的条件旋转生成模型(GraspIPDF);②利用Glow的条件归一化流(flow)GraspGlow。并且再利用ContactNet算法对生成的抓握姿态进行优化,使其在物理上更为可信。
对于抓取的执行阶段,算法以真实场景下的点云观测和机器人本体的感觉信息做为输入,以抓握姿态做为条件,来生成可以实现物体抓握的轨迹,从而完成抓握任务。对于此类无真实标签的学习任务,通常使用强化学习来优化模型的参数,但是灵巧手抓握任务的复杂度非常高,并且通用抓取任务对算法的泛化能力要求很高,强化学习算法通常难以学习出一组性能良好的模型参数,特别是当输入为vision输入,而非state输入时,这种现象尤为明显,所设计的算法通常难以收敛。为了应对这一问题,作者利用蒸馏损失来优化模型参数,设计了师生学习框架(teacher-student learning framework),首先以oracle state为输入的模型称为教师模型、以vision为输入的模型称为学生模型,以标签动作为优化目标来优化教师模型,以教师动作为优化目标来优化学生模型,将教师模型的动作预测能力蒸馏到学生模型中,加快了模型的收敛速度。尽管教师模型获得了物体oracle状态信息的获取权,但对于强化学习来说,让教师模型结合不同的抓取目标(第一阶段的输出)成功地抓取数千个不同的对象是比较困难的。【需要修改】对此,作者在这里引入了两个较为关键的创新:①确保SO(2)等方差(equivariance)的标准化步骤(canonicalization),以简化策略学习;②对象课程学习(object curriculum learning),首先学会用不同的目标(goal,第一阶段的输出)抓取一个对象,然后是一个类别,然后是多个类别,最后是所有类别,该学习方式又称为渐进学习策略。
注:
- 视觉输入相比于状态输入,含有大量的噪声,需要有一个较大的backbone来提取图像特征,较难训练;
- SO(3)表示三维空间中的旋转矩阵集合,其中每个矩阵都表示一个旋转操作,满足 R T R = I , d e t ( R ) = 1 R^TR=I,det(R)=1 RTR=I,det(R)=1;旋转矩阵可以描述物体或坐标系相对于某个固定坐标系的旋转,给定一个三维向量 v = [ v x , v y , v z ] T v=[v_x,v_y,v_z]^T v=[vx,vy,vz]T,旋转矩阵 R ∈ S O ( 3 ) R\in SO(3) R∈SO(3)将该向量旋转为新的向量: v ′ = R v v'=Rv v′=Rv;
方法
问题设置
抓取建议生成模块以物体和桌子的点云 X 0 ∈ R N × 3 X_0\in\mathbb R^{N\times3} X0∈RN×3为输入,从一个分布中采样抓取提议 g = ( R , t , q ) g=(R,t,q) g=(R,t,q),其中 R ∈ S O ( 3 ) , t ∈ R 3 , q ∈ R K R\in SO(3),t\in\mathbb R^3,q\in\mathbb R^K R∈SO(3),t∈R3,q∈RK分别表示灵巧手的手腕旋转(root rotation)、手腕平移(root translation)和关节角度, K K K表示手关节的总自由度数,所提出的抓取提议 g g g是下一个模块的目标姿态。
最后一个目标条件抓取执行模块是一个基于视觉输入的抓取策略,在IsaacGym物理模拟器中运行。在每个时间步 t t t中,策略以前一个模块的目标位姿 g g g、物体和场景的点云 X t X_t Xt、机器人本体感觉(proprioception) s t r s^r_t str作为输入,输出一个动作 a t a_t at。为了简化问题,作者用一个初始平移 t 0 = ( 0 , 0 , h 0 ) t_0=(0,0,h_0) t0=(0,0,h0)和一个初始旋转 R 0 = ( π 2 , 0 , ϕ 0 ) R_0=(\frac\pi2,0,\phi_0) R0=(2π,0,ϕ0)来初始化手腕的状态,其中 h 0 h_0 h0为固定的高度,手部旋转初始化为手掌朝下,其中 ϕ 0 = ϕ \phi_0=\phi ϕ0=ϕ,手的关节角度初始化为0,这一阶段的任务是按照目标抓握姿态 g g g去抓取指定的物体,并将其提升到一定的高度,当物体点(object)与目标点(target)的位置差小于阈值 t 0 t_0 t0时,表示抓取任务完成成功。
使用强化学习直接训练vision-base抓取策略具有挑战性,作者在这里采用了师生学习的思想,利用强化学习训练state-base的模型,之后利用蒸馏学习来训练vision-base模型的参数。强化学习采用PPO算法,结合所提出的对象课程学习和状态标准化方法,来学习一个oracle-state教师策略,该策略可以访问环境的真实状态(例如对象姿势、速度和对象点云),这些信息对任务非常有用,在模拟器中可用,但在现实世界中不可用。一旦教师策略完成训练,我们再使用模仿学习算法DAgger,利用教师策略的输出来训练vision-base学生策略的模型参数。
灵巧抓取建议生成
在本节中,主要介绍如何建模条件概率分布:
p ( g ∣ X 0 ) : S O ( 3 ) × R 3 + K → R p(g|X_0):SO(3)\times \mathbb R^{3+K}\rightarrow\mathbb R p(g∣X0):SO(3)×R3+K→R
通过将这一步骤进行解耦,可以得到两部分:
p ( g ∣ X 0 ) = p ( R ∣ X 0 ) ⋅ p ( t , q ∣ X 0 , R ) p(g|X_0)=p(R|X_0)\cdotp p(t,q|X_0,R) p(g∣X0)=p(R∣X0)⋅p(t,q∣X0,R)
在论文DexGraspNet2.0中提到了解耦的原因,在灵巧手抓取中以 X 0 X_0 X0为条件的 ( T , R ) (T,R) (T,R)的分布是多模态且复杂的(手腕姿态),而以 X 0 X_0 X0和 ( T , R ) (T,R) (T,R)为条件的 θ \theta θ的分布是单模态的(确定了手腕姿态条件下的手指姿态),因此,经常先预测条件分布 p ( T , R ∣ X 0 ) p(T,R|X_0) p(T,R∣X0),之后再利用 X 0 X_0 X0和 ( T , R ) (T,R) (T,R)预测 θ \theta θ。换个思路来想这件事,如果我们想要抓取一个物体,我们有多种抓握姿态,每种抓握姿态有不同的手腕姿势(包括三维位置、朝向等),每个手腕的姿态大多只对应一种手指的角度组合,也就是手腕姿态确定以后,手指的关节角度标签就会随之确定,因此在这里经常先预测手腕姿态,再预测手指姿态。
对此,作者提出了三阶段预测方法:
- 第一阶段,给定点云观测,利用GraspIPDF预测手腕旋转(hand root rotation)的条件概率分布 p ( R ∣ X 0 ) p(R|X_0) p(R∣X0),之后得到旋转提议;
- 第二阶段,给定点云观测和手腕旋转角度,使用GraspGlow预测手腕平移和关节角度 p ( t , q ∣ X 0 , R ) = p ( t ~ , q ∣ X ~ ) p(t,q|X_0,R)=p(\widetilde t,q|\widetilde X) p(t,q∣X0,R)=p(t ,q∣X ),之后得到对应的提议;
- 第三阶段,使用ContactNet来优化得到的抓握姿势 g g g,用于提高物理可行性。
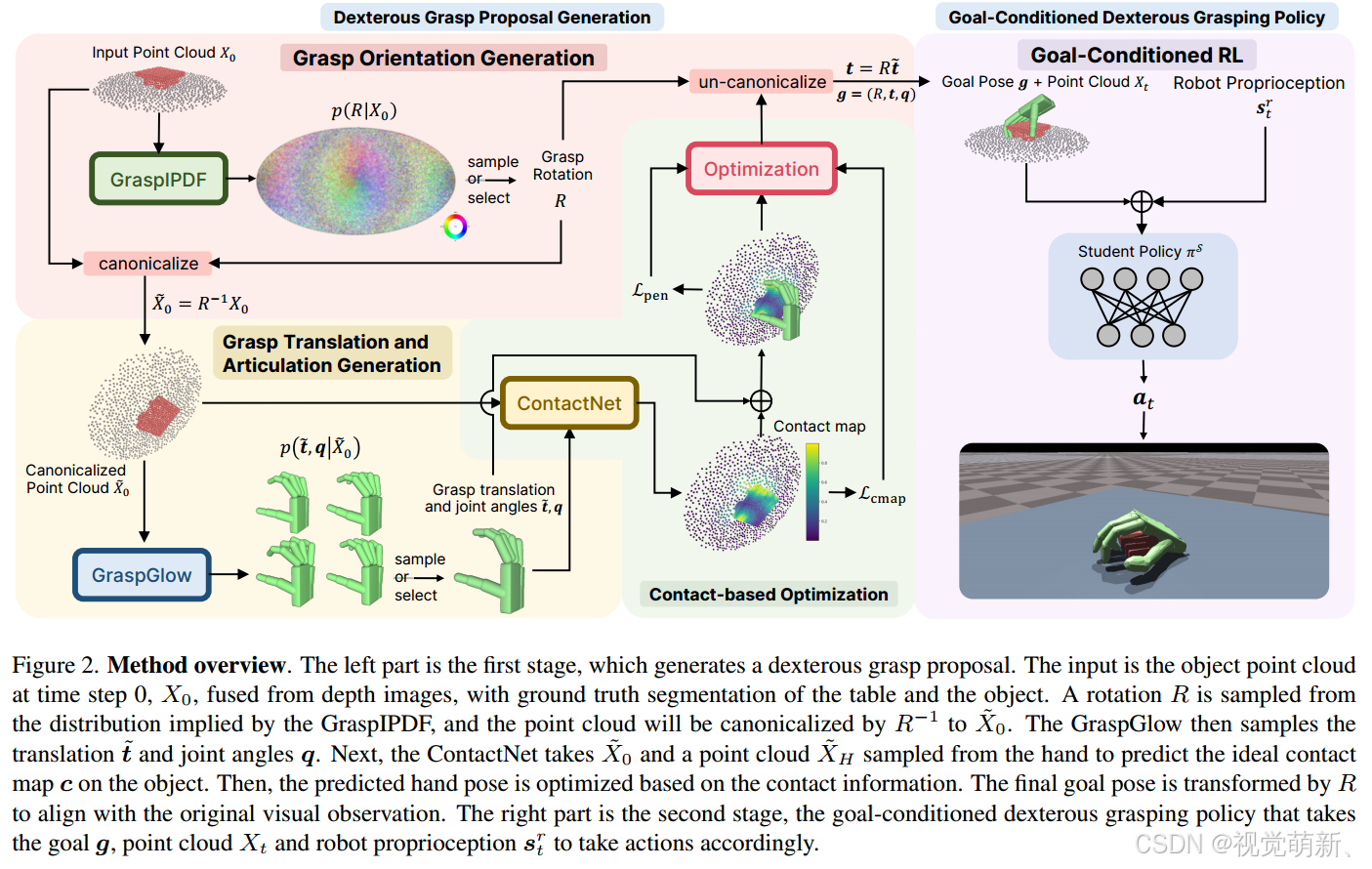
GraspIPDF:抓取方向生成
受IPDF(一个SO(3)上的概率模型)启发,作者提出了GraspIPDF f ( X 0 , R ) f(X_0,R) f(X0,R)来预测给定点云观测 X 0 X_0 X0的手腕旋转 R R R的条件概率分布 p ( R ∣ X 0 ) p(R|X_0) p(R∣X0),该模型以 X 0 X_0 X0和 R R R作为输入,使用PointNet++的backbone提取物体的几何特征,并输出一个非归一化的联合对数概率密度 f ( X 0 , R ) = α log ( p ( X 0 , R ) ) f(X_0,R)=\alpha \log(p(X_0,R)) f(X0,R)=αlog(p(X0,R)),其中 α \alpha α为归一化常数,之后利用如下公式归一化概率密度:
p ( R ∣ X 0 ) = p ( X 0 , R ) p ( X 0 ) ≈ 1 V exp ( f ( X 0 , R ) ) ∑ i M exp ( f ( X 0 , R i ) ) p(R|X_0)=\frac{p(X_0,R)}{p(X_0)}\approx\frac{1}{V}\frac{\exp(f(X_0,R))}{\sum_i^M\exp(f(X_0,R_i))} p(R∣X0)=p(X0)p(X0,R)≈V1∑iMexp(f(X0,Ri))exp(f(X0,R))
其中 M M M表示分区(volume partition)数量, V = π 2 M V=\frac{\pi^2}{M} V=Mπ2为分区体积。
在训练期间,GraspIPDF由NLL损失监督:
L = − log ( p ( R 0 ∣ X 0 ) ) \mathcal L=-\log(p(R_0|X_0)) L=−log(p(R0∣X0))
其中 R 0 R_0 R0为手腕旋转角度的标签。在测试阶段,我们在SO(3)上生成一个等体积网格,并根据查询的概率进行旋转角度采样,将所有的采样点对应的旋转角度 R i R_i Ri与当前的点云观测 X 0 X_0 X0同时传入模型中预测条件概率分布,概率最大的情况对应的旋转角度即为预测的旋转角度,相当于变成分类任务。
补充
IPDF(Implicit-PDF,PDF全称probability density function)出自《Implicit-pdf: Nonparametric representation of probability distributions on the rotation manifold》,ICML2021。该文章用于解决姿态估计问题,模型给定一个输入 x x x(例如图像),得到一个条件概率分布 p ( ⋅ ∣ x ) : S O ( 3 ) → R + p(\cdot|x):SO(3)\rightarrow \mathbb R^+ p(⋅∣x):SO(3)→R+(该方程表示,在给定 x x x为输入的条件下,旋转流形SO(3)上每个旋转 R R R的概率值),用于表示输入 x x x姿态的概率分布(概率值最大的 R R R可以认为是 x x x的姿态)。
换个角度思考,我们要求的是条件概率 p ( R ∣ x ) p(R|x) p(R∣x),通过条件概率分解,我们可以得到:
p ( R ∣ x ) = p ( x , R ) p ( x ) p(R|x)=\frac{p(x,R)}{p(x)} p(R∣x)=p(x)p(x,R)
我们可以利用模型来预测 p ( x , R ) p(x,R) p(x,R),也就是输入 x x x的姿态为 R R R的概率,因为是概率,所以模型的输出需要经过归一化,假设模型为 f ( ⋅ , ⋅ ) f(\cdot,\cdot) f(⋅,⋅),我们可以得到 p ( x , R ) = α exp ( f ( x , R ) ) p(x,R)=\alpha \exp(f(x,R)) p(x,R)=αexp(f(x,R)),其中 α \alpha α为正则化项,用于归一化操作。剩下要求的就是 p ( x ) p(x) p(x),我们可以对 p ( x , R ) p(x,R) p(x,R)求积分得到:
p ( x ) = ∫ R ∈ S O ( 3 ) p ( x , R ) d R = α ∫ R ∈ S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2083
2083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











