







VLN算法学习:AZHP——自适应区域分层规划器Adaptive Zone-aware Hierarchical Planner for Vision-Language Navigation
【VLN入门介绍】
一文搞懂视觉语言导航,从任务介绍到基本算法讲解:https://blog.csdn.net/qq_50001789/article/details/144676313
【VLN算法笔记】
DUET(CVPR2022),首篇使用Transformer来建模全局图节点相关性的工作:https://blog.csdn.net/qq_50001789/article/details/144632851
AZHP(CVPR2023),使用自适应区域分层规划器来实现层次化导航的目的:https://blog.csdn.net/qq_50001789/article/details/144635128
GridMM(ICCV2023),使用网格记忆图来表征历史轨迹中的场景空间关系:https://blog.csdn.net/qq_50001789/article/details/144652403
【VLN辅助任务】
MLM、SAP、SAR、SPREL——预训练、微调中常用的提点策略:https://blog.csdn.net/qq_50001789/article/details/144633984
【VLN环境配置】
Matterport3DSimulator——用于视觉语言导航算法研发的仿真环境配置:https://blog.csdn.net/qq_50001789/article/details/142621259
综述
论文题目:《Adaptive Zone-aware Hierarchical Planner for Vision-Language Navigation》
源码链接:https://github.com/chengaopro/AZHP
论文出处:CVPR 2023、刘偲老师团队
关键词:分层导航
背景
VLN给定的指令往往具有层次性,比如一个指令“Bring me the white pillow"(给我一个白色枕头),这表明智能体需要完成几个潜在的子目标,例如:离开当前房间、找到卧室、找到白色枕头。因此,VLN任务本质上是一种分层导航的过程,我们可以在导航的过程中设置多个子目标,之后逐一完成所有的子目标导航任务,进一步完成整个导航任务,在本文中,子目标的划分称为高阶任务,子目标的执行称为低阶任务。其次,子目标是指一个子区域内的目标,因此需要智能体可以将场景划分为几个区域,并为当前的子目标选择合适的区域,在子区域中执行低阶的动作规划。注意:子目标的选择不仅取决于指令,还需要智能体根据当前的状态环境来设置合适的子目标,这意味着智能体在导航过程中需要自适应地进行区域的划分和选择。例如在下图中,当智能体在客厅时,子目标应该设置为:在出口区域(红色区域)找到出口。第三,由于子目标的设置是没有标签的(无法使用模范学习来优化这一过程),因此如何学习这一高阶策略网络也是一个值得研究的课题。
当前主流的VLN算法主要为单步规划方法本质上都是单步规划框架,每次根据动作空间和全局目标直接执行一步导航操作,这种范式没有明确地模拟VLN任务的分层规划特性,很大程度上限制了长期决策能力。
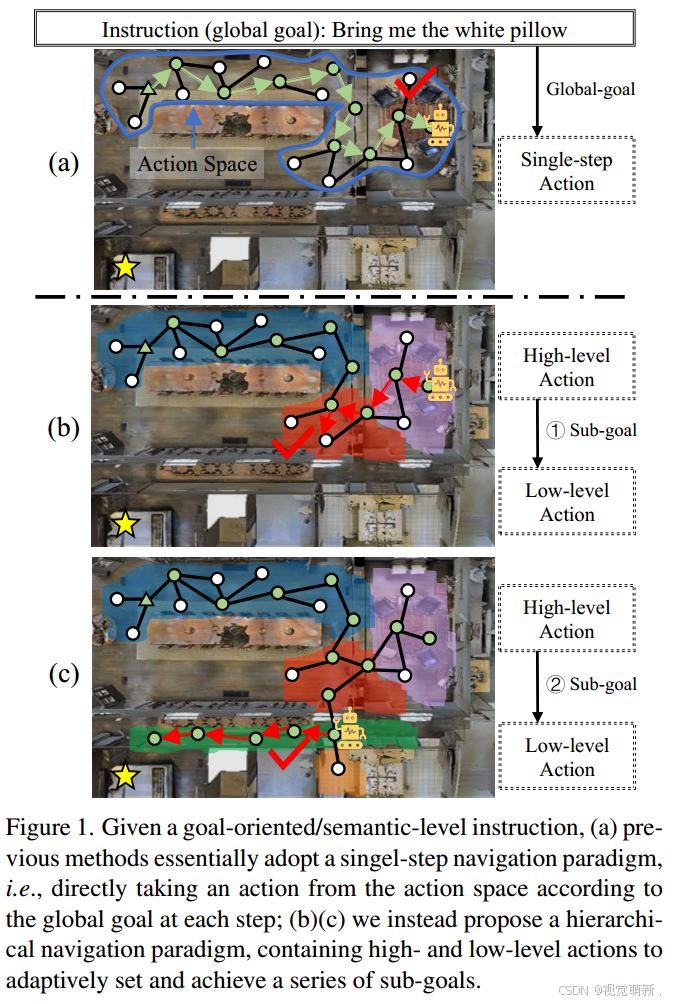
主要思想
本文提出了一种自适应区域感知分层规划器(Adaptive Zone-aware Hierarchical Planner, AZHP),为VLN任务构建一种新的分层规划框架。AZHP将导航过程建模为包含高阶动作和低阶动作的分层动作制定过程,在导航过程中,高阶动作的目标是设置子目标,低阶动作的目标是完成相应的子目标。具体地来说,高阶动作将整个场景划分为不同的区域,并根据当前状态选择合适的区域进行导航,例如图1©中的绿色区域(走廊),之后应用低阶动作在选定的区域内多步执行特定的导航决策,直至到达子目标。
针对高阶动作的预测,作者提出了一种场景自适应感知区域划分方法(Scene-aware adaptive Zone Partition, SZP)。本文的方法是基于DUET算法来实现的,在该算法中,每执行一步动作,都会更新一次全局拓扑图,全局拓扑图记录了历史轨迹和观测结果,在此基础上,作者根据每个视点的位置和观测值,动态地将全局拓扑图自适应地划分为多个区域。同时,作者设计了一种目标导向的区域选择方法(Goal-oriented Zone Selection, GZS),根据指令和区域属性来选择特定的区域当做下一个子目标区域。此外,作者还设计了状态切换模块(State-Switcher Module, SSM)来判断当前子目标是否已经实现,如果已经实现就切换到下一个子目标。
由于高阶动作的训练没有直接的标签进行监督,作者提出了分层强化学习(Hierarchical Reinforcement Learning, HRL)来优化这一高阶过程。
补充:本文的分层导航相当于对整个导航任务做一个解耦,想要直接完成整个导航任务是比较困难的,因为一条完整的路径比较长,中途的噪声干扰会给整个导航任务带来非常大的不确定性。对导航任务做解耦,将一个复杂的任务拆解成多个简单的子任务,逐一完成简单的子任务,最终实现复杂的导航目标,是VLN任务中非常常见的算法优化策略,而本文中是在轨迹区域层面实现解耦目的。
方法
分层规划概述
VLN任务具有分层特性,它由一个高阶过程(即子目标的设置)和一个低阶过程(即子目标的执行)组成,子目标(sub-goal)是指到达一个子区域(sub-region)的目标。本文提出了一个自适应区域感知的分层规划器(Adaptive Zone-aware Hierarchical Planner, AZHP)来建模这一分层规划的过程,具体地来说,AZHP由两个策略网络组成,具体如下图所示。其中,高阶策略 π H ( ⋅ ) \pi^H(\cdot) πH(⋅)学习设置子目标 g H g^H gH,低阶策略 π L ( ⋅ ) \pi^L(\cdot) πL(⋅)相应地学习实现 g H g^H gH。在导航过程中,每执行一步观测,都会利用DUET算法中的策略来记录历史轨迹和当前观测值,生成全局的拓扑图 G t G_t Gt。
具体地来说,在时间步 t t t时,利用学习到的高阶策略网络 π H ( a t H ∣ G t ; θ H ) \pi^H(a^H_t|G_t;\theta^H) πH(atH∣Gt;θH)来获得 a t H a^H_t atH(例如区域划分、区域选择),其中 θ H \theta^H θH为网络的参数。经过区域划分和选择后,会得到一组选定的区域 G t ∗ G^*_t Gt∗,其中 G t ∗ G^*_t Gt∗为 G t G_t Gt的子图。之后分多步利用低阶策略网络 π L ( a t L ∣ G t ∗ ; θ L ) \pi^L(a^L_t|G^*_t;\theta^L) πL(atL∣Gt∗;θL)得到低阶动作 a t L a^L_t atL,也就是导航决策,智能体只在子图 G t ∗ G^*_t Gt∗中导航决策,最后,作者提出了一个状态切换模型(State-Switcher Module, SSM)来学习子目标 g H g^H gH是否达到,并且在导航中是否切换到下一个子目标。
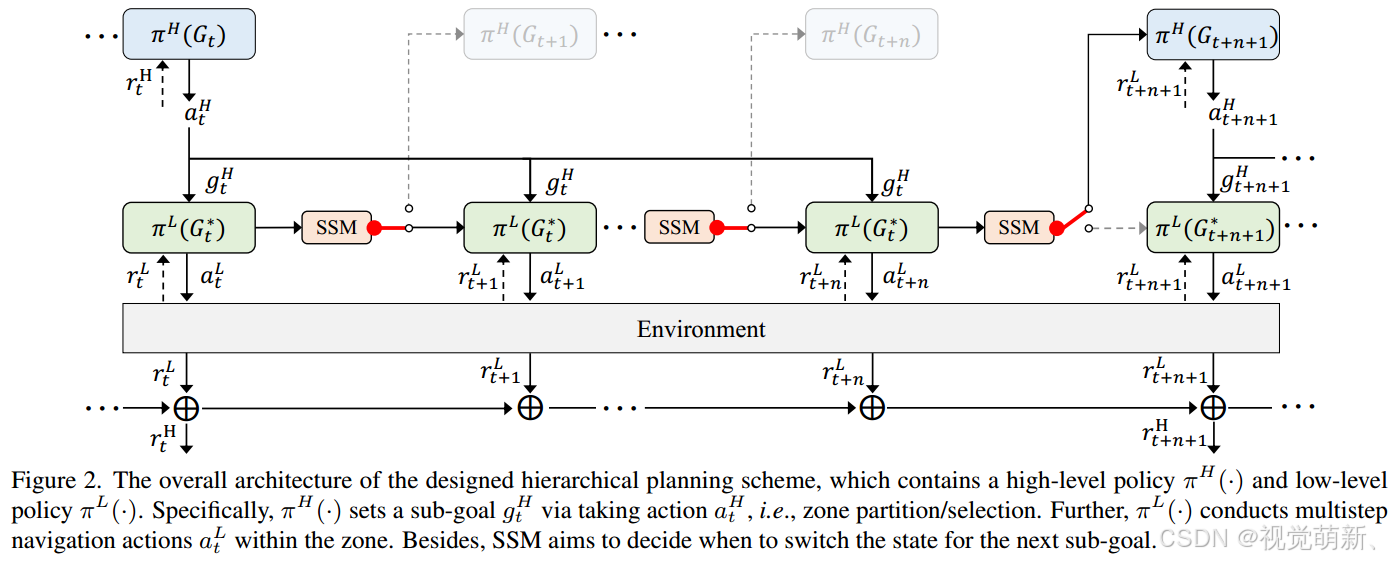
分层强化学习
由于没有用于训练高阶策略 π H ( ⋅ ) \pi^H(\cdot) πH(⋅)的专家演示(标签),作者在这里提出了一种分层强化学习策略来优化该网络。首先,作者设计了一个低阶策略的奖励函数 π L ( ⋅ ) \pi^L(\cdot) πL(⋅),在第 t t t步导航中,智能体会执行一个低阶动作 a t L a^L_t atL,奖励 r t L r^L_t rtL定义为:
- 当离目标位置的距离 d i s t dis_t dist发生变化时,当前步骤的奖励为: r t L = − ( d i s t − d i s t − 1 ) r^L_t=-(dis_t-dis_{t-1}) rtL=−(dist−dist−1);
- 当智能体停在目标位置时,当前步骤的奖励为: r t = 10 r_t=10 rt=10,否则为 − 10 -10 −10;
- 当智能体路过目标位置但是不停止时,当前步骤的奖励为: r t = − 10 r_t=-10 rt=−10;
之后通过累加所有的奖励,得到高阶策略的奖励:
r
t
H
=
∑
t
=
s
t
a
r
t
e
n
d
r
t
L
r^H_t=\sum^{end}_{t=start}r^L_t
rtH=t=start∑endrtL
其中,
[
s
t
a
r
t
,
e
n
d
]
[start,end]
[start,end]是当前子目标的时间段。
之后采用时序差分算法(Temporal Difference algorithm, TD)来优化两个策略网络(基于
r
t
H
r^H_t
rtH和
r
t
L
r^L_t
rtL),以高阶策略的优化过程为例。技术上,利用MLP网络来构建状态价值评估函数
v
H
(
G
t
;
W
H
)
v^H(G_t;W^H)
vH(Gt;WH),用于预测每个状态的价值量
v
H
v^H
vH,其中
W
H
W^H
WH是可学习的参数。状态价值函数用于评估当前状态的好坏,之后计算TD目标
y
t
H
y^H_t
ytH和误差
δ
t
H
\delta^H_t
δtH:
y
t
H
=
r
t
H
+
γ
⋅
v
H
(
G
t
+
1
;
W
H
)
δ
t
H
=
v
H
(
G
t
;
W
H
)
−
y
t
H
y^H_t = r^H_t+\gamma\cdot v^H(G_{t+1};W^H)\\ \delta^H_t=v^H(G_t;W^H)-y^H_t
ytH=rtH+γ⋅vH(Gt+1;WH)δtH=vH(Gt;WH)−ytH
其中
γ
\gamma
γ为收益因子,最后
π
H
(
⋅
)
\pi^H(\cdot)
πH(⋅)和
v
H
(
⋅
)
v^H(\cdot)
vH(⋅)可以通过梯度下降法来优化:
θ
H
←
θ
H
−
β
⋅
δ
t
H
⋅
∂
∂
θ
H
ln
(
π
H
(
a
t
H
∣
G
t
;
θ
H
)
)
,
W
H
←
W
H
−
α
⋅
δ
t
H
⋅
∂
∂
W
H
ln
(
v
H
(
G
t
;
W
H
)
)
,
{\theta}^H\leftarrow{\theta}^H-\beta\cdot\delta_t^H\cdot\frac{\partial}{\partial{\theta}^H}\ln(\pi^H(a_t^H|G_t;{\theta}^H)),\\{W}^H\leftarrow{W}^H-\alpha\cdot\delta_t^H\cdot\frac{\partial}{\partial{W}^H}\ln(v^H(G_t;{W}^H)),
θH←θH−β⋅δtH⋅∂θH∂ln(πH(atH∣Gt;θH)),WH←WH−α⋅δtH⋅∂WH∂ln(vH(Gt;WH)),
其中
α
\alpha
α和
β
\beta
β是超参数。对于优化
W
H
W^H
WH,是朝着降低误差
δ
t
H
\delta^H_t
δtH的方向进行,也就是让状态价值评估函数在评估状态价值方面越来越准。
![[外链图片转存中...(img-M39QHdHr-1734781155547)]](https://i-blog.csdnimg.cn/direct/bdf2309bfb3f44eebdb66472cc650cea.png)
高阶策略
为了自适应地为子目标设置子区域,作者提出了一种高阶策略网络,该网络包括场景感知的自适应区域划分(Scene-aware adaptive Zone Partition, SZP)和目标导向的区域选择(Goal-oriented Zone Selection, GZS)。
场景感知的自适应区域划分(SZP)
在时间步长
t
t
t处,作者在当前的视角图中应用目标检测器来提取目标级别的视觉特征,之后参考DUET算法,采用跨模态Transformer来将当前视角/目标的视觉语言特征融入拓扑图
G
t
=
(
H
t
,
E
t
)
G_t=(H_t,E_t)
Gt=(Ht,Et)中,
G
t
G_t
Gt包括
N
t
v
N_t^v
Ntv个节点,其中
H
t
∈
R
N
t
v
×
D
h
,
E
t
∈
R
N
t
v
×
N
t
v
H_t\in \mathbb R^{N_t^v\times D_h}, E_t\in\mathbb R^{N^v_t\times N^v_t}
Ht∈RNtv×Dh,Et∈RNtv×Ntv分别表示节点特征矩阵和加权邻接矩阵,
E
t
E_t
Et初始化为相应视点之间的距离。SZP的目标是在
G
t
G_t
Gt上进行分区,得到一组子视图
G
t
i
i
=
1
N
t
z
{G^i_t}^{N^z_t}_{i=1}
Gtii=1Ntz,其中
N
t
z
N^z_t
Ntz表示分区序号。本算法在导航过程中自适应设置
N
t
z
N^z_t
Ntz,
G
t
G_t
Gt越大,对应划分的区域就应该越多,计算公式为:
N
t
z
=
⌈
v
i
s
i
t
_
l
e
n
t
×
r
a
t
i
o
⌉
N_t^z=\lceil visit\_len_t\times ratio\rceil
Ntz=⌈visit_lent×ratio⌉
其中
v
i
s
i
t
_
l
e
n
t
visit\_len_t
visit_lent表示当前轨迹的长度,
r
a
t
i
o
∈
(
0
,
1
)
ratio\in(0,1)
ratio∈(0,1)为超参数。
对于区域的划分,首先将所有的节点视为区域中心(zone centre),目标是为每个节点生成对应区域的特征
Z
t
=
{
z
t
i
}
i
=
1
N
t
v
Z_t=\{z^i_t\}_{i=1}^{N^v_t}
Zt={zti}i=1Ntv(具体见图3中的(a)子图),考虑到
z
t
i
z^i_t
zti应该代表其周围的状态,本算法以一种自适应的方式融合领域特征,具体地来说,我们计算节点特征
h
t
j
∈
R
1
×
D
h
h^j_t\in\mathbb R^{1\times D_h}
htj∈R1×Dh对节点特征
h
t
i
∈
R
1
×
D
h
h^i_t\in\mathbb R^{1\times D_h}
hti∈R1×Dh,的关系分数
s
t
i
,
j
s^{i,j}_t
sti,j:
s
t
i
,
j
=
{
σ
(
[
h
t
i
W
H
,
h
t
j
]
W
S
)
e
t
i
,
j
<
T
H
R
d
−
inf
else
s_t^{i,j}=\begin{cases}\sigma([h_t^iW_H,h_t^j]W_S)&e_t^{i,j}<THR_d\\-\inf&\text{else}\end{cases}
sti,j={σ([htiWH,htj]WS)−infeti,j<THRdelse
其中
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)为激活函数,
[
,
]
[,]
[,]为拼接操作,
W
H
∈
R
D
h
×
D
h
W_H\in\mathbb R^{D_h\times D_h}
WH∈RDh×Dh和
W
S
∈
R
2
D
h
×
1
W_S\in\mathbb R^{2D_h\times1}
WS∈R2Dh×1分别为可学习的参数,
e
t
i
,
j
e^{i,j}_t
eti,j为节点
i
i
i和节点
j
j
j之间的距离,预设一个距离阈值
T
H
R
d
THR_d
THRd,当节点之间的距离超过阈值时,我们认为该节点不是相邻关系,经过上述运算之后,会得到关系分数矩阵
S
t
∈
R
N
t
v
×
N
t
v
S_t\in\mathbb R^{N^v_t\times N^v_t}
St∈RNtv×Ntv,之后再经过softmax运算对关系分数矩阵做标准化操作,具体过程可以表示为
S
t
←
s
o
f
t
m
a
x
(
S
t
)
S_t\leftarrow softmax(S_t)
St←softmax(St),之后通过
Z
t
=
S
t
H
t
Z_t=S_tH_t
Zt=StHt得到区域特征,即关系分数矩阵和节点特征矩阵相乘。
其次,如图3(b)所示,通过计算节点
i
i
i的代表性得分
ϕ
t
i
\phi^i_t
ϕti,我们对区域特征
z
t
i
z^i_t
zti进行分级:
ϕ
t
i
=
σ
(
z
t
i
W
1
+
∑
(
z
t
i
W
2
−
z
t
j
W
3
)
)
,
e
t
i
,
j
<
T
H
R
d
\phi_t^i=\sigma(z_t^iW_1+\sum(z_t^iW_2-z_t^jW_3)),e_t^{i,j}<THR_d
ϕti=σ(ztiW1+∑(ztiW2−ztjW3)),eti,j<THRd
其中
W
1
,
W
2
,
W
3
∈
R
D
h
×
1
W_1,W_2,W_3\in\mathbb R^{D_h\times 1}
W1,W2,W3∈RDh×1为可学习的参数,
(
z
t
i
W
2
−
z
t
j
W
3
)
(z^i_tW_2-z^j_tW_3)
(ztiW2−ztjW3)表示两个区域之间的差异线索,由于我们预计将
G
t
G_t
Gt划分为
N
t
z
N^z_t
Ntz个子区域,因此我们根据
ϕ
t
\phi_t
ϕt选择分数最高的前
N
t
z
N^z_t
Ntz个区域中心,我们将区域中心的索引表示为
i
^
t
\hat{i}_t
i^t,因此区域内节点的概率分布为
P
t
=
s
o
f
t
m
a
x
i
^
t
(
S
t
)
∈
R
N
t
v
×
N
t
z
P_t=softmax_{\hat{i}_t}(S_t)\in\mathbb R^{N^v_t\times N^z_t}
Pt=softmaxi^t(St)∈RNtv×Ntz(每个区域在内部做一次归一化操作),之后根据
P
t
P_t
Pt和距离将其他节点分配到选定的区域中心(具体如图3©所示)。因此,我们将
G
t
G_t
Gt划分为
N
t
z
N_t^z
Ntz个子区域
{
G
t
i
}
i
=
1
N
t
z
\{G^i_t\}^{N^z_t}_{i=1}
{Gti}i=1Ntz,其中
G
t
i
=
(
H
t
i
,
E
t
i
)
G^i_t=(H^i_t,E^i_t)
Gti=(Hti,Eti),
H
t
i
H^i_t
Hti和
E
t
i
E^i_t
Eti分别表示第
i
i
i个区域内的节点特征和邻接矩阵。
目标导向的区域选择(GZS)
本模块用于从
{
G
t
i
}
i
=
1
N
t
z
\{G^i_t\}^{N^z_t}_{i=1}
{Gti}i=1Ntz中选择一个区域
G
t
∗
G^*_t
Gt∗来进行进一步的低阶导航操作。首先,利用文本编码器对语言指令进行编码,得到文本编码特征
I
∈
R
L
×
D
h
I\in\mathbb R^{L\times D_h}
I∈RL×Dh,其中
L
L
L为语言指令长度。我们将生成的指令的句子级特征表示为
I
^
∈
R
1
×
D
h
\hat I\in\mathbb R^{1\times D_h}
I^∈R1×Dh(这是什么意思?加个上标是什么意思,再看一下论文)。从本质上来说,我们希望所筛选的子目标区域是以指令为导向的,因此,如图3(d)所示,我们通过内部生产函数为每个区域计算一个区域分数:
z
o
n
e
_
s
c
o
r
e
i
=
σ
(
I
^
W
I
)
⋅
σ
(
z
t
i
W
Z
)
T
zone\_score_i=\sigma(\hat{I}W_I)\cdot\sigma(z^i_tW_Z)^T
zone_scorei=σ(I^WI)⋅σ(ztiWZ)T
其中,
W
I
,
W
Z
∈
R
D
h
×
D
w
W_I,W_Z\in\mathbb R^{D_h\times D_w}
WI,WZ∈RDh×Dw为可学习的参数。因此,我们选择得分最高的区域
G
t
∗
=
(
H
t
∗
,
E
t
∗
)
G^*_t=(H^*_t,E^*_t)
Gt∗=(Ht∗,Et∗)当做当前子目标的导航区域,其中
N
t
∗
N^*_t
Nt∗为节点数,
H
t
∗
H^*_t
Ht∗和
E
t
∗
E^*_t
Et∗分别为节点特征和邻接矩阵。选择完子区域之后,智能体沿着最短的路径移动到选定的区域中心,并在区域内执行后续的低阶动作预测。
低阶策略
导航决策
在时间步长为
t
t
t时,低阶策略网络
π
L
(
⋅
)
\pi^L(\cdot)
πL(⋅)产生低阶动作
a
t
L
a^L_t
atL(即导航决策)。具体地来说,只有当前区域
G
t
∗
=
(
H
t
∗
,
E
t
∗
)
G^*_t=(H^*_t,E^*_t)
Gt∗=(Ht∗,Et∗)中的视点才能作为导航动作。我们采用多层交叉注意力来对
G
t
∗
G^*_t
Gt∗中的每个节点特征
h
t
∗
i
h^{*i}_t
ht∗i进行评估,并选择得分最高的视点
a
t
L
a^L_t
atL作为导航目标,过程可以表示为:
a
t
L
=
a
r
g
max
i
∈
G
t
∗
C
o
r
s
s
A
t
t
e
n
t
i
o
n
(
h
t
∗
i
,
I
)
a^L_t=arg\max_{i\in G^*_t}CorssAttention(h^{*i}_t,I)
atL=argi∈Gt∗maxCorssAttention(ht∗i,I)
这里具体的节点动作预测过程可以参考DUET算法。
状态切换模块(SSM)
为了确定是否将当前状态切换到下一个子目标,即应用另一组高阶和低阶动作,作者在这里提出了SSM。具体地来说,我们对时间步
t
t
t处的状态分数做评估:
s
t
a
t
e
_
s
c
o
r
e
t
=
sigmoid
(
σ
(
I
^
W
I
′
)
⋅
σ
(
h
t
c
W
S
)
)
state\_score_t=\text{sigmoid}(\sigma(\hat IW'_I)\cdot\sigma(h^c_tW_S))
state_scoret=sigmoid(σ(I^WI′)⋅σ(htcWS))
其中
h
i
c
∈
R
1
×
D
h
h^c_i\in\mathbb R^{1\times D_h}
hic∈R1×Dh为当前视点的特征,
W
I
′
,
W
S
∈
R
D
h
×
D
w
W_I',W_S\in\mathbb R^{D_h\times D_w}
WI′,WS∈RDh×Dw为可学习的参数。然后,我们为状态分数设置阈值
T
H
R
S
∈
[
0
,
1
]
THR_S\in[0,1]
THRS∈[0,1],用于判断是否切换到下一个子目标,即是否重新划分整个图
G
G
G并重新选择
G
∗
G^*
G∗进行导航,如果智能体保持当前子目标,它将通过低级动作继续在当前区域中进行导航,并将新观察到的视点添加到当前区域的图结构
G
t
∗
G^*_t
Gt∗以进行更新。
训练目标
训练损失主要包括两部分:高阶策略网络的辅助损失和低阶策略网络的行动损失。
辅助损失
对于高阶动作,作者采用分层强化学习和辅助损失来训练高阶策略网络,辅助损失包括区域划分损失
L
z
p
L_{zp}
Lzp和区域选择损失
L
z
s
L_{zs}
Lzs。对于
L
z
p
L_{zp}
Lzp,我们用启发式的方法划分
G
t
G_t
Gt,并将结果作为分区标签,具体地来说,作者通过公式得到
N
t
z
N^z_t
Ntz区域的中心索引
i
‾
t
\overline{i}_t
it:
i
‾
t
=
{
r
o
u
n
d
(
1
+
(
k
−
0.5
)
×
s
t
e
p
t
)
∣
k
=
1
,
…
,
N
t
z
}
\overline{i}_t=\{round(1+(k-0.5)\times step_t)|k=1,\dots,N^z_t\}
it={round(1+(k−0.5)×stept)∣k=1,…,Ntz}
其中,
r
o
u
n
d
(
⋅
)
round(\cdot)
round(⋅)表示四舍五入函数,
s
t
e
p
t
=
(
v
i
s
i
t
_
l
e
n
t
−
1
)
/
N
t
z
step_t=(visit\_len_t-1)/N^z_t
stept=(visit_lent−1)/Ntz,
i
‾
t
k
\overline{i}_t^k
itk表示第
k
k
k个区域中心的索引,该运算过程会使区域中心分布均匀。之后通过最近邻搜索算法来计算节点
j
j
j的区域标签
z
‾
t
j
\overline{z}_t^j
ztj:
z
‾
t
j
=
arg
min
i
∈
i
‾
t
e
t
i
,
j
\overline{z}^j_t=\arg\min_{i\in\overline{i}_t}e^{i,j}_t
ztj=argi∈itmineti,j
此外,节点属于该分区的概率分布为
P
t
P_t
Pt,其中
P
t
(
i
,
j
)
P_t(i,j)
Pt(i,j)为节点
j
j
j属于分区
i
i
i的可能性,
L
z
p
L_{zp}
Lzp的计算过程可以表示为:
L
z
p
=
∑
t
=
1
T
∑
j
=
1
N
t
v
−
log
P
t
(
j
,
z
‾
t
j
)
L_{zp}=\sum^T_{t=1}\sum^{N^v_t}_{j=1}-\log P_t(j,\overline{z}^j_t)
Lzp=t=1∑Tj=1∑Ntv−logPt(j,ztj)
对于
L
z
s
L_{zs}
Lzs,在时间步
t
t
t时,我们取
i
‾
t
∗
\overline{i}^*_t
it∗为标签,其中
i
‾
t
∗
\overline{i}^*_t
it∗为标签GT视点所在区域的索引号:
L
z
s
=
∑
t
=
1
T
−
log
[
s
o
f
t
m
a
x
(
z
o
n
e
_
s
c
o
r
e
)
]
i
‾
t
∗
L_{zs}=\sum^T_{t=1}-\log[softmax(zone\_score)]_{\overline{i}^*_t}
Lzs=t=1∑T−log[softmax(zone_score)]it∗
课程学习策略:由于所提出的
L
z
p
L_{zp}
Lzp和
L
z
s
L_{zs}
Lzs不基于GT标签,仅提供启发式监督,因此,我们在训练阶段开始时应用它们以提高初始学习的鲁棒性。之后,我们利用HRL对网络进行训练,旨在获得更灵活的高层策略。
行动损失:这一模块主要用低阶的导航动作损失来计算:
L
n
a
v
=
−
∑
t
=
1
T
[
log
p
(
a
‾
t
)
+
log
p
(
a
‾
t
π
)
]
L_{nav}=-\sum^T_{t=1}[\log p(\overline{a}_t)+\log p(\overline a^{\pi}_t)]
Lnav=−t=1∑T[logp(at)+logp(atπ)]
其中
a
‾
t
\overline{a}_t
at为教师动作,
a
‾
t
π
\overline{a}^{\pi}_t
atπ为启发式动作标签(例如:从当前节点到目标节点的最短路径)。另外再采用
L
o
g
=
−
log
p
(
o
‾
)
L_{og}=-\log p(\overline o)
Log=−logp(o)作为object grounding损失,其中
o
‾
\overline o
o为真实的对象。因此,总损失可以表示为:
L
=
λ
1
L
z
p
+
λ
2
L
z
s
+
λ
3
L
n
a
v
+
L
o
g
L=\lambda_1L_{zp}+\lambda_2L_{zs}+\lambda_3L_{nav}+L_{og}
L=λ1Lzp+λ2Lzs+λ3Lnav+Log
补充:该算法同样分为预训练和微调两个阶段,具体用到的辅助损失与DUET中使用的相同。
实验结果
REVERIE数据集
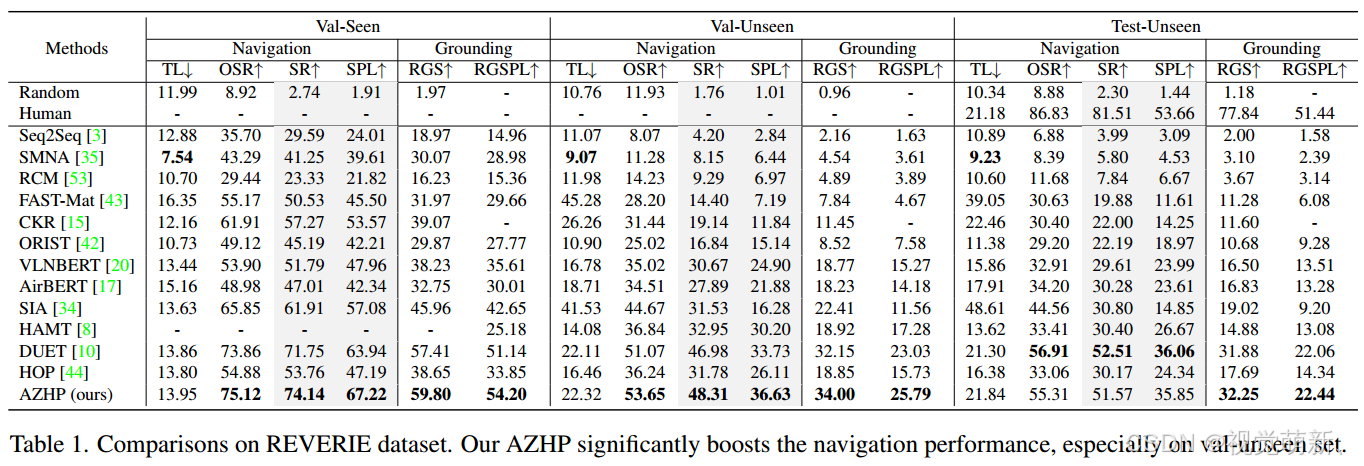
R2R数据集
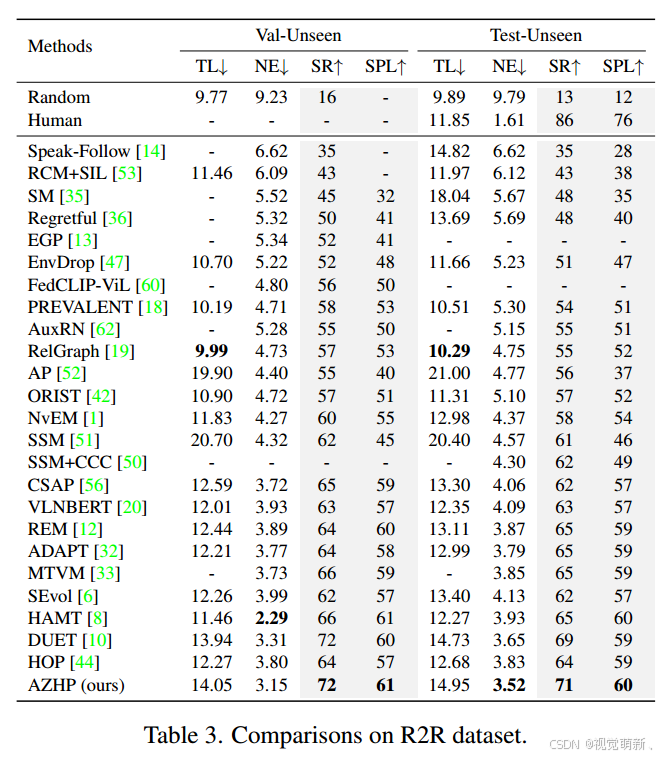
以上仅是笔者个人见解,若有问题,欢迎指正。



















 3089
3089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











