









论文链接:[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
参考视频:
ViT论文逐段精读【论文精读】_哔哩哔哩_bilibili (刚入门可以先看这个,bryanyzhu大佬带读,讲的非常细致,沐神出品,必属精品)
ViT| Vision Transformer |理论 + 代码_哔哩哔哩_bilibili (代码部分解读)
一、提出背景
Vision Transformer (ViT) 的提出背景源于对传统计算机视觉模型(尤其是卷积神经网络,CNN)的局限性的重新思考,以及 Transformer 架构在自然语言处理(NLP)领域成功的启发。
Transformer 的核心特性:
- Transformer 架构基于注意力机制(self-attention),能够捕获输入序列中全局范围的关系,而无需依赖于固定的局部感受野。
- 它在 NLP 中已经成为事实上的标准架构,尤其是通过预训练与迁移学习(例如 BERT、GPT 系列),Transformer 在处理各种任务(如文本分类、翻译等)上表现出色。
CNN 的局限性:
尽管卷积神经网络(CNN)在计算机视觉领域长期占据主导地位,但其架构也存在一些局限性:
局部感受野:
- CNN 的核心卷积操作依赖于局部感受野,这使其在捕获全局上下文信息时并不高效。
- 尽管可以通过堆叠多层卷积或引入全局池化来扩大感受野,但这通常会增加计算复杂度。
固定的结构设计:
- CNN 的设计往往遵循固定的层次结构(如 VGG、ResNet 的层次堆叠),难以灵活地捕获不同尺度下的全局特征。
对大规模数据的依赖:
- CNN 在小规模数据集上的表现有限,往往需要借助大规模预训练数据(例如 ImageNet)来提升性能。
在 ViT 提出之前,注意力机制已经开始在视觉领域尝试与 CNN 进行结合:
结合 CNN 的注意力机制:
- 一些研究(例如 SENet、Non-Local Networks)尝试在 CNN 中引入注意力机制,以增强其对全局依赖关系的建模能力。
- 这些方法往往是对 CNN 的辅助增强,而非彻底摆脱卷积操作。
局部和全局感受野的折中:
- 视觉模型通常需要在捕获局部精细特征与全局特征之间取得平衡,这为纯注意力模型的应用创造了机会。
二、如何将2D图像转为1D序列?
简单想法:直接将2d图片按照像素拉直
存在问题:复杂度很高
解决方法:减少序列长度
相关工作:
- 《Non-local neural network》用特征图当作transformer的输入。
- 《Stand-alone self-attention in vision model》孤立自注意力。用局部的小窗口作为输入,通过控制窗口大小控制复杂度。
- 《Axial-deeplab》把2d矩阵拆分成两个1d向量,先在H高度方向做一个自注意力,再从W宽度方向做一个自注意力。
ViT作者认为上述这些自注意力操作虽然理论高效,但属于比较特殊的自注意力操作,没有在现在的硬件上加速,很难训练大模型。
三、ViT的提出
将图像划分为若干图像块(patch),并将这些图像块的线性嵌入序列作为 Transformer 的输入。图像块在这种方法中被视为与 NLP 应用中的标记(token,单词)相同。

存在问题:当在中等规模的数据集(例如 ImageNet)上训练且未使用强正则化时,这些模型的准确率比同等规模的 ResNet 低约几个百分点。这是因为:Transformer 缺乏 CNN 自带的一些归纳偏置(inductive bias),例如平移不变性和局部性,因此在训练数据不足的情况下泛化性能较差。
优势:如果模型在更大规模的数据集(1400 万到 3 亿张图像)上进行训练,情况会发生变化。实验证明,大规模训练可以超越归纳偏置的限制。当 Vision Transformer (ViT) 在足够规模的数据集上预训练并迁移到数据量较少的任务时,可以获得卓越的效果。
什么是归纳偏置 Inductive biases?
答:就是先验知识。平移不变性(Translation Invariance) 和 局部性(Locality) 是卷积神经网络(CNN)固有的归纳偏置。
什么是平移不变性和局部性?缺乏这些特性为什么会导致泛化性能差?
答:
1. 平移不变性 Translation Invariance
定义:指的是图像中的物体或特征,无论在图像中的位置如何变化,CNN 都能有效地识别它们。例如,一个物体出现在图像的左上角,还是出现在右下角,CNN 都能保持较高的识别能力。
CNN如何实现?:在卷积神经网络中,卷积层的滤波器(或称卷积核)在整个图像上滑动(或“卷积”),从而捕获图像中的局部特征。由于滤波器在图像的每个位置进行相同的计算,因此 CNN 对图像中物体的平移具有不变性。
2. 局部性 Locality
定义:局部性指的是图像中的信息通常是局部的,即相邻像素之间存在较强的相关性。例如,图像中的一只动物的眼睛和鼻子通常在空间上是相邻的,它们的特征也密切相关。
CNN如何利用?:卷积操作通过局部感受野(receptive field)来捕捉相邻像素之间的关系。每个卷积层的滤波器只作用于图像的一小块区域,能够捕获局部的特征(如边缘、角点、纹理等)。这种局部性结构使得 CNN 可以逐步构建出复杂的图像特征,同时保持对相邻区域信息的敏感性。
强正则化 Strong Regularization
正则化的目标是通过限制模型的复杂度或引入某种约束,提升模型的泛化能力,使其在未见过的数据上表现更稳定。
在 ViT 中,正则化起到补偿作用,因为 Transformer 缺乏 CNN 的内在归纳偏置(例如平移等变性和局部性),因此需要额外的方法来提升泛化能力,尤其是在数据量不足的情况下。
常用强正则化手段:
(1) 权重正则化
L1 正则化:通过在目标函数中加入权重绝对值的和(稀疏约束),鼓励部分权重为零。
L2 正则化:通过在目标函数中加入权重平方的和(也称为权重衰减),限制权重的增长,降低模型复杂度。
(2) Dropout
定义:在训练过程中随机丢弃部分神经元(置为 0),防止网络过度依赖某些特定的特征。
作用:提升模型的鲁棒性,广泛应用于像 ViT 这样的深度网络。
(3) 数据增强
定义:通过对训练数据施加某些变换(如翻转、旋转、裁剪、颜色调整等),生成更多样化的样本。
作用:模拟更多的训练样本,间接减少模型的过拟合。
在 ViT 中的应用:强数据增强(如 RandAugment 或 Mixup)在提升 Transformer 模型的泛化能力方面非常关键。
(4) Stochastic Depth(随机深度)
定义:在训练期间随机跳过一些网络层。
作用:提升深层网络的泛化性能,减少梯度消失问题。
在 ViT 中的应用:ViT 使用随机深度来应对其深层架构的潜在问题。
(5) Label Smoothing(标签平滑)
定义:将训练目标中的标签分布进行平滑处理(即使正确类别的标签概率低于 1,而其他类别概率略高于 0)。
作用:防止模型过度自信地预测特定类别,从而提升泛化性能。
(6) 知识蒸馏(Knowledge Distillation)
定义:通过使用一个预训练好的教师模型(通常更复杂或准确),引导学生模型学习软目标概率分布。
作用:提升学生模型的泛化能力,减轻训练数据不足的影响。
(7) 正则化训练技巧
Early Stopping(早停法):在模型性能不再提升时停止训练,避免模型过度拟合。
Gradient Clipping(梯度裁剪):限制梯度的最大值,防止梯度爆炸。
四、ViT模型结构
- 先将图片打成patch(这里是九宫格);
- 将这些patch变成序列;
- 每一个patch都会通过线性投射层操作得到一个特征,也就是patch embedding(注意图片是有顺序的,因此要加上位置编码);
- 因此一个token包含一个patch原本的图片信息+一个位置编码信息;
- 传入transformer encoder;
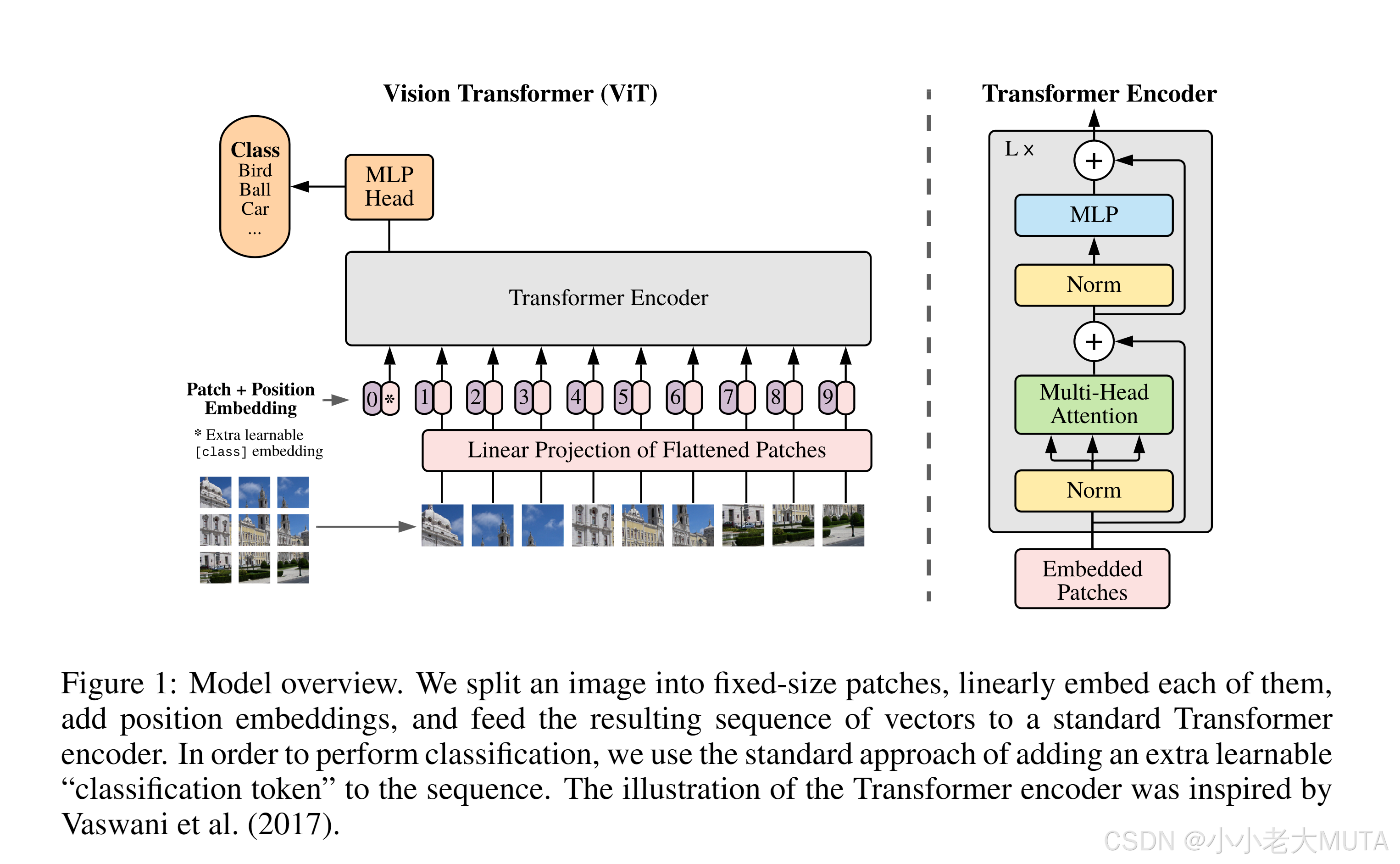
选择Encoder的哪一个输出表示类别分类?
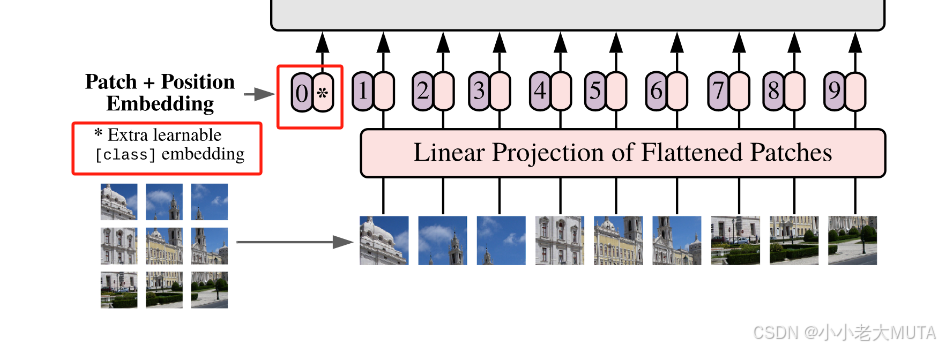
借鉴了BETR的extra learnable embedding,也就是特殊字符——分类字符cls;
- ViT也加了分类字符,用 * 代替,也有position embedding——0;
- 因为所有的token都在做交互信息,所有class embedding 也能从其他所有的embedding学到有用的信息,从而只用class embedding的输出做判断就可以;
- 最后用传统的分类头去做分类。
五、消融实验
5.1 Class Token
因为在NLP的分类任务中使用了class Token代表语句理解的一个全局特征,作者想和原始的Transformer保持尽可能的一致,所以也使用了class token。
在Transformer中,输入一维序列输出一维序列,代表着全局图片特征;
但其实在CNN的中,经过多层特征提取得到最后的特征图,经过Global Average Pooling全局池化最后也是一个一维向量,代表着全局的图片的特征;
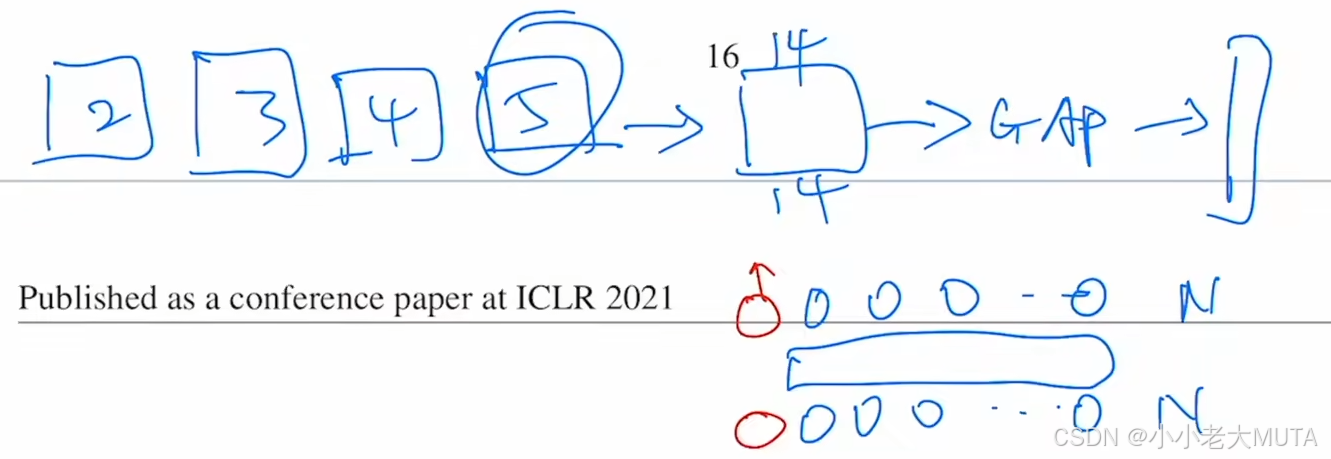
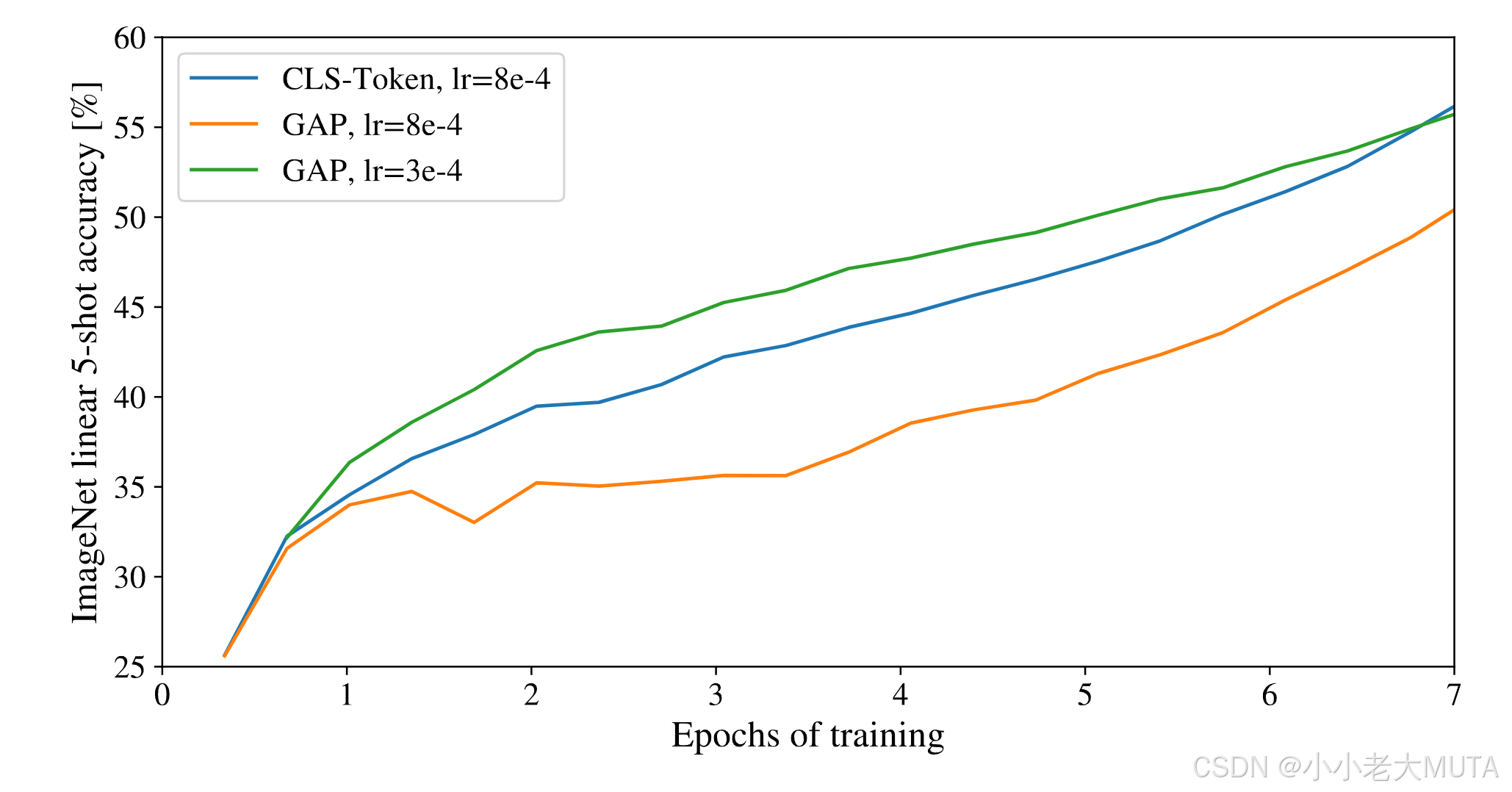
最后实验效果:
- 绿色是全局平均池化;
- 蓝线是class token;
- 黄线是用class token的相同学习率的平均池化;(黄线是告诉我们得好好调参)
结论:全局平均池化方法和class token 效果都差不多;作者选择使用NLP 中的class token是想表明传统的Transformer也能做视觉任务,而不是因为使用了cv的一些小技巧。
5.2 Position Embedding
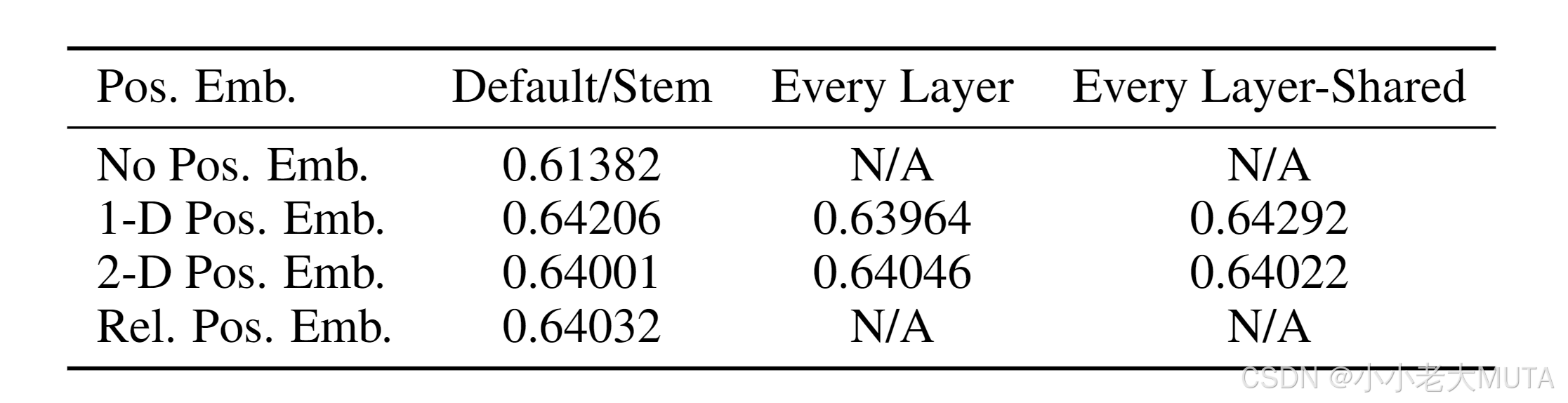
有三种位置编码方式:
1. 一维坐标表示(1-2-3-4-...-9)
2. 二维的坐标表示(11,12,13,21,22,23,...)
3. 相对位置编码:既可以用绝对距离表示又可以用相对距离表示
实验结果:
不同的位置表示的结果没有区别。
但其实这里是做的分类任务,对目标位置没有要求,在后面研究目标检测等任务时,大多使用的是2D位置编码。
六、代码实现
6.1 patch embedding
在 Vision Transformer 中,输入是一张图片,需要将其转化为 一维嵌入向量序列,类似于自然语言处理任务中处理文本的 token 序列。ViT 的做法是:
- 将输入图像划分成固定大小的图像块(patch)。
- 将每个 patch 展平(flatten),然后通过一个线性变换(或者卷积操作)投射到固定的嵌入维度,形成每个 patch 对应的嵌入。
- 最后,将嵌入向量序列输入到 Transformer 编码器中。
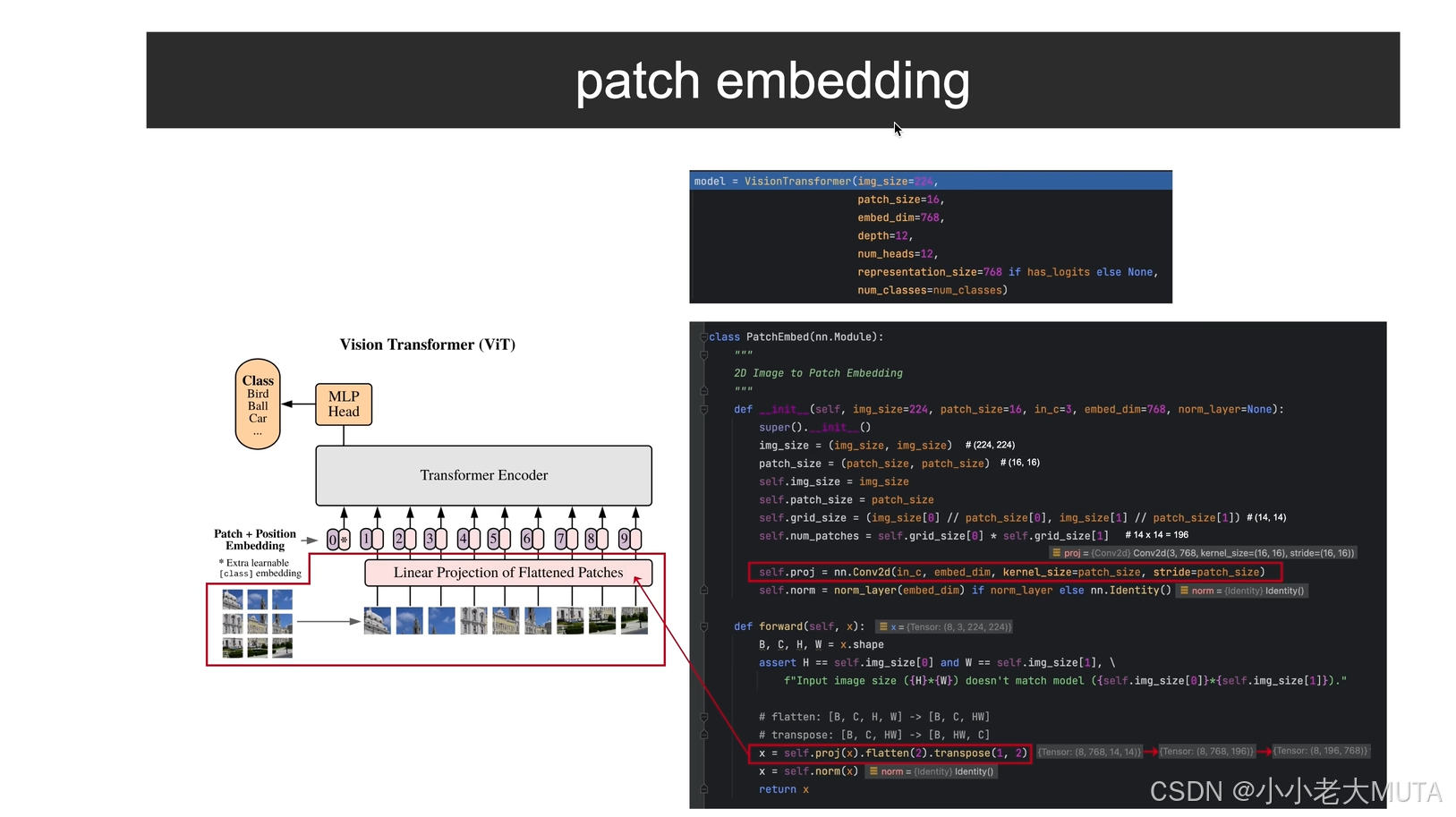
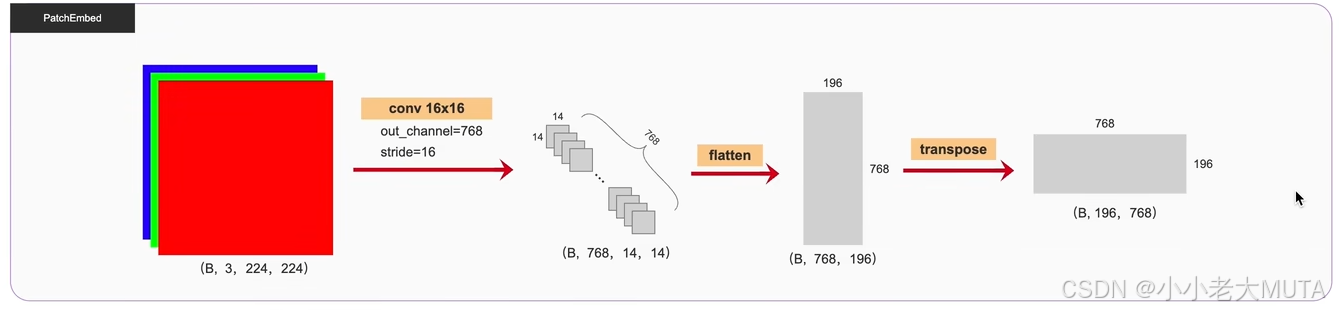
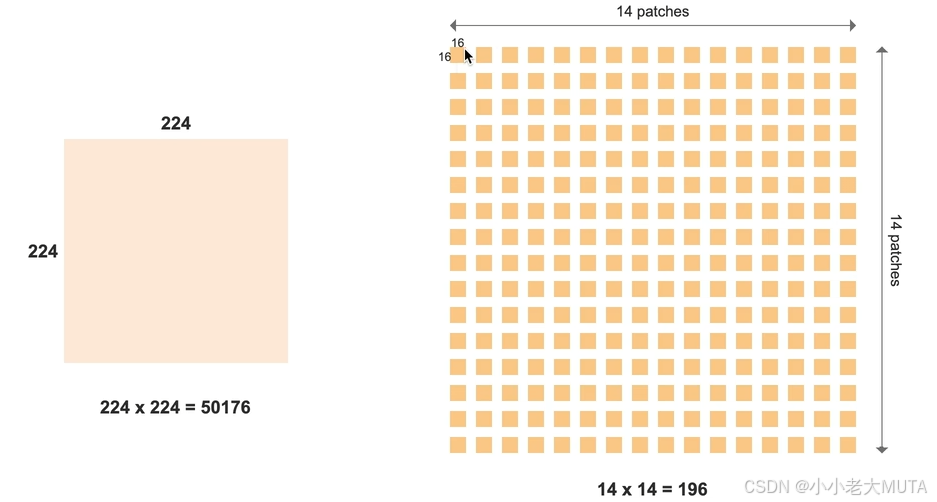
- 输入图片224*224
- 每一个patch大小16*16
- 所以一共有14*14 196个patch ( 224/16=14)
通过卷积实现线性嵌入 并 展平:
self.proj是一个 2D 卷积层,作用是将输入图像投影到嵌入空间中。
这里使用了大小为 16×16 的卷积核,步长也为 16,相当于对每个 patch 进行卷积操作,最终将每个 patch 转换为一个固定长度的特征向量。
- 768为超参数。图片原本是3通道,一个 16×16 × 3 的patch 会被展平成一个长度为 768 的向量。输出为
(Batch_size, 768, 14, 14)。
通过展平(flatten)和转置操作,最终将结果变为
(B, 196, 768),其中 196是 patch 数量,768是嵌入维度。
归一化:
默认是none,使用nn.Identity()即不进行归一化。
6.2 Class Embedding + Position Embedding
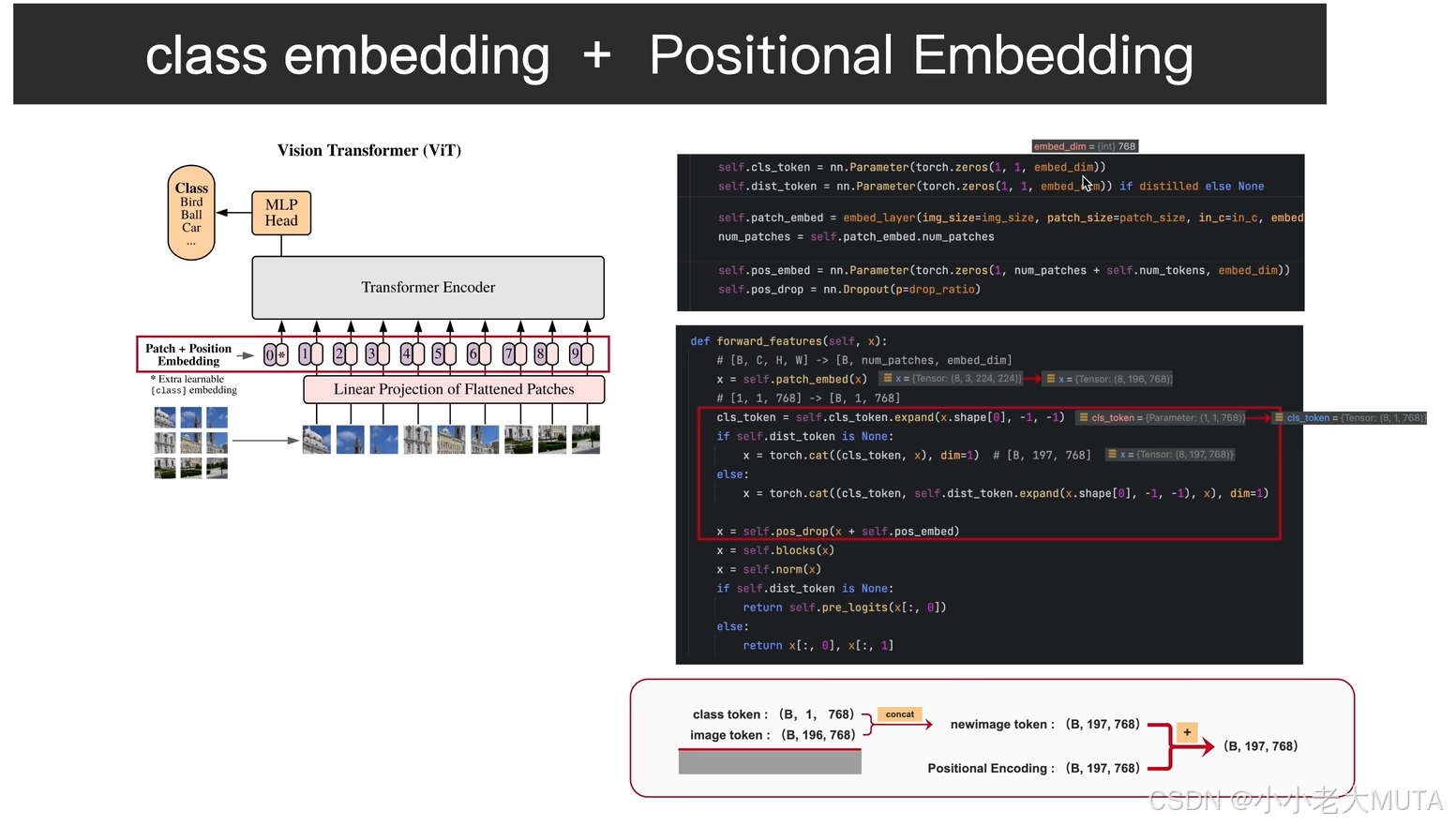
Patch + class token
- 先生成一个可学习的参数矩阵[1,1,768]表示class token,然后在第0维扩展成[batch_size,1,768]
- 然后在第一维将class token 和 6.1生成的patch embedding[batch_size,196,768] Concat 拼接,成为[batch_size, 197, 768];
Patch + Position Embedding
- 位置编码是一个可学习的参数矩阵,形状为[1,197,768]
- 将位置编码 和 含class token的patch 相加,这里是[1,197,768] + [batch_size,197,768],过程会有触发广播机制,位置编码会自动广播为[batch_szie,197,768]再和patch逐元素相加。
- 最后会根据超参数drop_ratio随机dropout,结果为[batch_szie,197,768]
6.3 Transformer Encoder

Transformer Encoder整个操作是打包在blocks中。
blocks里面是一个for循环,depth=3即表示encoder重复执行了三次。
Block的forward函数只有两部分,第一行表示图中下面框选部分;第二行表示上面框选部分。
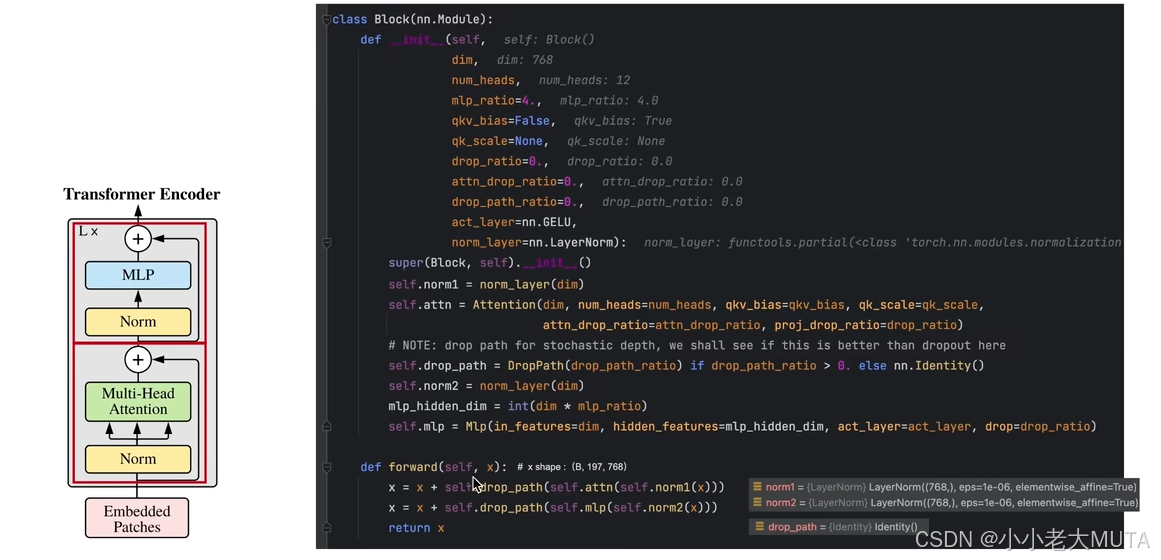

Encoder中的Multi-Head Attention

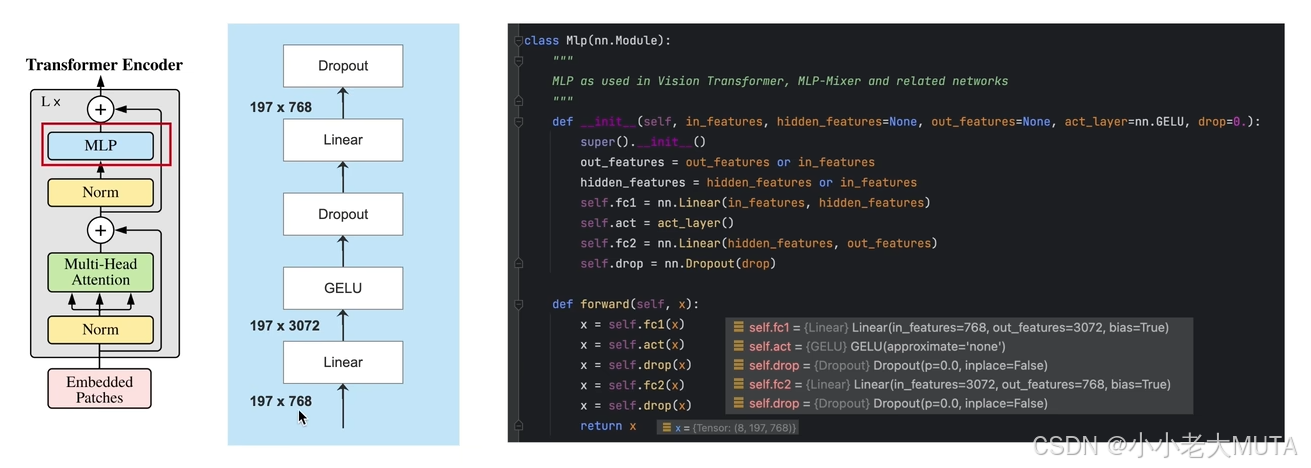
Encoder中的MLP
6.4 Classifier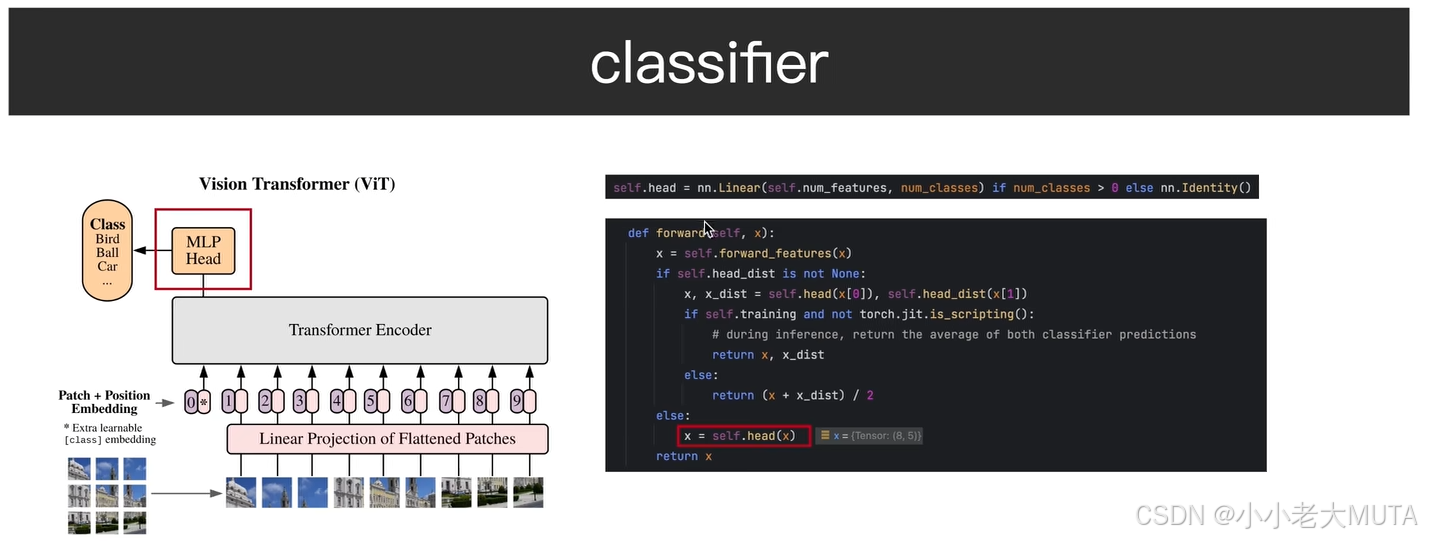

分类头是一个全连接层,输入维度是768,输出维度是num_classes


















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











