







目录
推荐系统是为了解决数据量的激增导致信息过载提出来的,但是随着模型和技术的发展,会产生过拟合,导致形成过滤气泡、加大马太效应、加剧个人回音室、导致信息茧房、形成推荐过度专业化问题。【这类问题总结的来说就是推荐给用户的信息种类越来越少,使得用户很难接触到不一样的内容,比如现在很多网友都在吐槽的短视频推荐内容过于单一化】。为了解决这类问题,新的推荐方式逐渐被提出来,主要包括新颖性推荐【推荐新的东西】、多样化推荐【推荐不同种类的东西】、非预期推荐【推荐用户可能感兴趣但无法涉猎的东西】等方法。在调研时发现了下面这篇博客一文纵览多样化推荐的现状与发展 - 知乎觉得该篇博客对多样化推荐总结的内容很不错,在阅读时会增加一些自己的内容,与诸君共勉。这篇博客应该是写的一篇综述,但是不知道发表的时间和期刊。【有大佬有新的想法或者点子欢迎一起交流,调研阶段太漫长了o(╥﹏╥)o】
引言:推荐系统旨在挖掘用户兴趣并为用户提供个性化的推荐服务。然而,只关注准确性的推荐算法对用户、供应商和推荐平台都有一定的负面影响。为此,公平性、隐私性、多样性等准确性外的指标也引起了研究者们的关注。本文聚焦于推荐系统中的个体多样性,将推荐系统个体多样性的相关工作分为三类进行介绍:前处理方法、中处理方法和后处理方法。
如果要写其他主题的综述,我觉得也可以采取这种分类方式【处理阶段的划分】来进行分析和总结。但是需要先调研确定之前没有类似的综述使用同种方法,避免论文相似性太高。
1. 研究背景
1.1 推荐系统为什么需要多样性
其实这里前面解释差不多了。
研究表明,个性化推荐可以提高服务体验和客户留存率,从而提高供应商的盈利前景,促进平台的可持续发展。
在大多数情况下,工业推荐系统关注的是以 CTR/CVR 为代表的准确性指标。然而,以准确性为中心的推荐具有负面影响,例如加剧个人回音室 [65]、形成过滤气泡以及放大马太效应 [42]。【除了这三个,还有信息茧房和推荐过度专业化问题。】
CVR (Conversion Rate): 转化率。是一个衡量CPA广告效果的指标,CVR=(转化量/点击量)*100%。
CTR(Click-Through-Rate):点击率,它等于广告点击次数/展现量,这里的广告点击次数与展现量是在同一个时间维度内的数据,比如如果这个网页出现了一万次,而网页上的广告的点击次数为五百次,那么点击率即为5%。

【上图画得非常生动形象】
- Customer: 对于客户来说,用户本身可能有多方面的兴趣,但对不同领域/类型的偏好存在差异。然而,推荐算法端训练时只强调了用户的部分主流兴趣,导致头部过拟合、尾部欠拟合的问题。久而久之,过曝光效应导致了过滤气泡和信息茧房的问题,用户逐渐对推荐结果感到乏味,影响客户留存率和满意度。
- Provider: 对于商家而言,他们可能会面临曝光分布不均的问题,即优秀或受欢迎的供应商将占据市场的主导地位,威胁小商家或新供应商的生存,垄断的商家格局将影响推荐平台的长期发展。【长尾效应】
1.2 个体 vs 系统级别的多样性
在多样性方面,推荐系统的多样性可以追溯到信息检索领域的搜索结果多样性[11, 15, 16]。考虑到推荐的实际应用场景,研究者一般从两个角度对多样性进行定义 [68],即个体层面的多样性 和系统层面的多样性,后者也被称为聚合多样性 [59]。

- 个体层面的多样性:主要集中在为顾客提供多样化的推荐结果。以新闻推荐为例 [41],同质化新闻会强化用户已有的认知,产生极化和扩散效应。此外,奢侈品时尚等一般性推荐的研究 [53] 也表明发现独家和稀有商品对于提高用户粘性的重要性。因此,多样化推荐结果对用户自身有积极的影响,避免单调乏味的平台体验。
- 系统层面的多样性:指的是不同供应商之间的公平曝光 [59, 70]。在这种定义下,公平性和长尾推荐都可以表示为系统级的多样性。
本文将重点关注个人层面的多样性,即为了满足客户不同的兴趣和需求,以获得更好的用户体验。
据我目前所知,系统层面的多样性相关的研究还是比较少的。
1.3 多样性与相关概念的区别和联系
在推荐系统领域,多样性 (diversity) 的概念和公平性 (fairness)、惊喜性 (serendipity)、新颖性 (novelty) 等概念有一定的区别和联系:
- 多样性 (diversity):推荐结果的多样化程度,多样的推荐结果期望结果间的平均相似度低。而 coverage (覆盖度) 指的是推荐结果对物品集的覆盖程度,一般可以作为多样性的衡量指标。
- 公平性 (fairness):推荐系统中的公平性可以按照作用的对象分为个体公平和组公平。个体公平要求相似的个体应该得到相似的推荐结果,而组公平要求不同的群体应该得到平等的对待。当我们考虑组公平和系统级别的多样性时,公平性和多样性都涉及到对弱势组的考量,具有相似的目的。例如,在推荐的场景下,供应商的公平性可以视作系统级的多样性。
- 惊喜性 (serendipity):惊喜性有时也称作意外度 (unexpectedness),表示用户对于推荐物品的惊喜程度,可以用推荐物品与历史交互之间的距离来衡量。若算法给出的物品是用户可能感兴趣但之前未曾涉猎的范围,则惊喜性具有帮助用户跳出信息茧房的潜力。
- 新颖性 (novelty):新颖性指的是推荐结果中有新的物品,但对于新颖性的衡量和定义并没有统一的标准。新颖性与惊喜性有一定的相似之处,两者对提升多样性都有一定的帮助。相比之下,多样性是更通用、含义更丰富的概念。
2. 多样性的评测指标
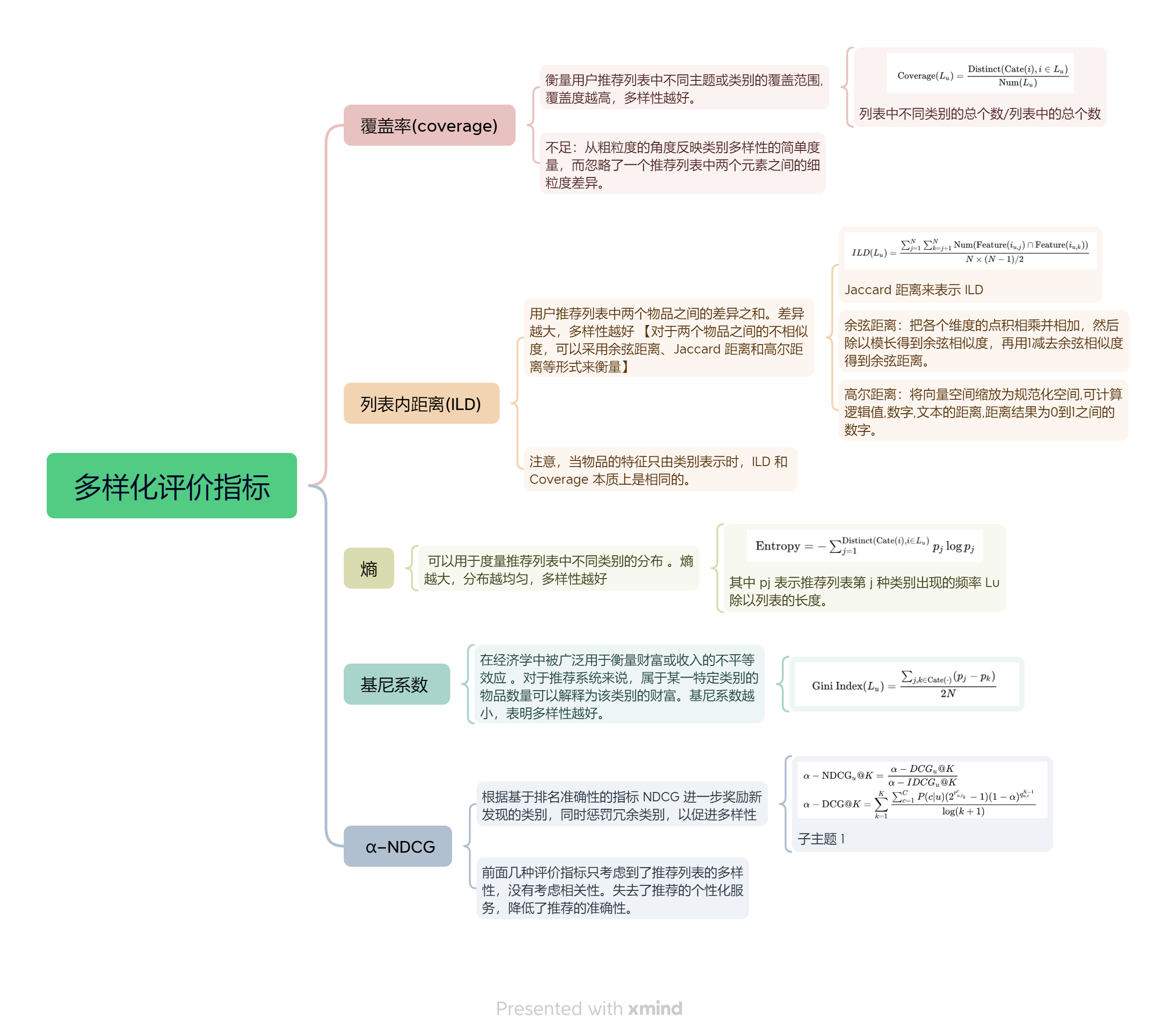
在介绍具体方法之前,本节先介绍多样化推荐的优化目的和评测指标。尽管学术界已经提出了多种衡量多样性的指标,但以下五种指标最常用并具有代表性,分别是:覆盖度、列表内距离、熵、基尼系数和 α-NDCG。
2.1 覆盖率
覆盖率 (coverage) [62] :衡量用户推荐列表中不同主题或类别的覆盖范围,如电影类型、视频标签等 [31, 40, 69, 76]。覆盖度越高,多样性越好,可形式化为:

其中 Lu 表示用户 u 的推荐列表,Cate(i) 表示物品 i对应的类别,可以是单个类别,也可以是多个类别的集合。Num表示列表或集合的个数,Distinct表示集合或列表中不同值的个数。
总结就是:列表中不同类别的总个数/列表中的总个数
覆盖率是从粗粒度的角度反映类别多样性的简单度量,而忽略了一个推荐列表中两个元素之间的细粒度差异。
2.2 列表内距离
为了考虑到成对的相似性,列表内距离 (intra-list distance, ILD) 度量指用户推荐列表中两个物品之间的差异之和[73, 77]。差异越大,多样性越好。对于两个物品之间的不相似度,可以采用余弦距离、Jaccard 距离和高尔距离等形式来衡量 [13, 39, 44, 54]。
Jaccard 距离来表示 ILD:
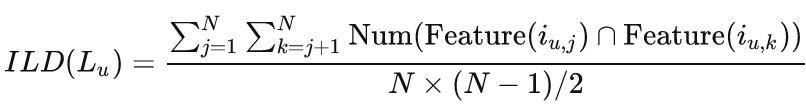
其中 N = Num(Lu),Feature表示物品的特征集。注意,当物品的特征只由类别表示时,ILD 和 Coverage 本质上是相同的。
余弦距离:把各个维度的点积相乘并相加,然后除以模长得到余弦相似度,再用1减去余弦相似度得到余弦距离。
高尔距离:将向量空间缩放为规范化空间,可计算逻辑值,数字,文本的距离,距离结果为0到1之间的数字。
2.3 熵
对于多样性,研究者不仅要考虑不同类别的数量,还要考虑每个类别的分布。在这种情况下,信息理论中的熵 (entropy) 可以用于度量推荐列表中不同类别的分布 [37, 41, 74]。熵越大,分布越均匀,多样性越好:
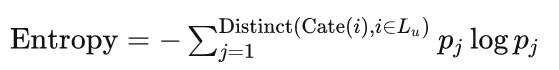
其中 pj 表示推荐列表第 j 种类别出现的频率 Lu除以列表的长度。
2.4 基尼系数
基尼系数 (gini index) 在经济学中被广泛用于衡量财富或收入的不平等效应 [34]。对于推荐系统来说,属于某一特定类别的物品数量可以解释为该类别的财富,基尼系数也是多样性 [20] 或公平性 [36] 的评价指标:
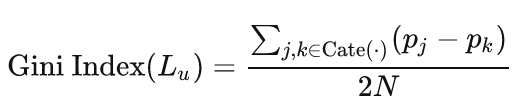
基尼系数越小,表明多样性越好。
以上四个指标只考虑了推荐列表的多样性,不考虑相关性,与用户的历史交互行为无关。向用户推荐所有类别的商品无疑是最多样化的,但它失去了推荐的个性化服务,大大降低了准确性。
2.5 α−NDCG
有必要综合考虑相关性和多样性。为此,信息检索领域常用的 α−NDCG 的指标 [15] 可以泛化到推荐系统领域 [19, 47]。α−NDCG 根据基于排名准确性的指标 NDCG 进一步奖励新发现的类别,同时惩罚冗余类别,以促进多样性,定义如下:
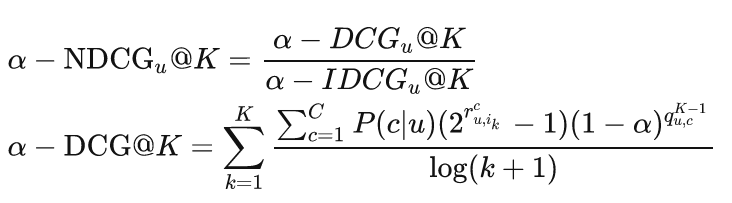
其中c表示不同类别的数量,我们还可以根据目标用户过去的历史交互来限制他们感兴趣的选择类别,以实现个性化的多样性。P(c|u) 表示类别 c 是否出现在用户 u的历史交互中,或者可以进一步表示为兴趣关于用户 u 的分布。 表示物品
是否属于类别 c,并出现在
中。
表示在
的前
个物品中,属于c类别的物品出现的频率,
表示惩罚冗余的衰减因子。信息检索领域的其他多样性指标,如 NRBP [16] 和 ERR-IA [11],同样可以泛化到推荐领域,这里不再讨论。
- NRBP (Novelty- and Rank-Biased Precision)
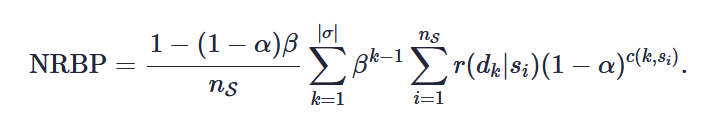
其中 β 是认为给定的超参数, 它衡量了在浏览了当前 item 会继续浏览下一个 item 的概率. 所以 NRBP 实际上是一个期望收益.
我将上面的内容总结如下图所示。
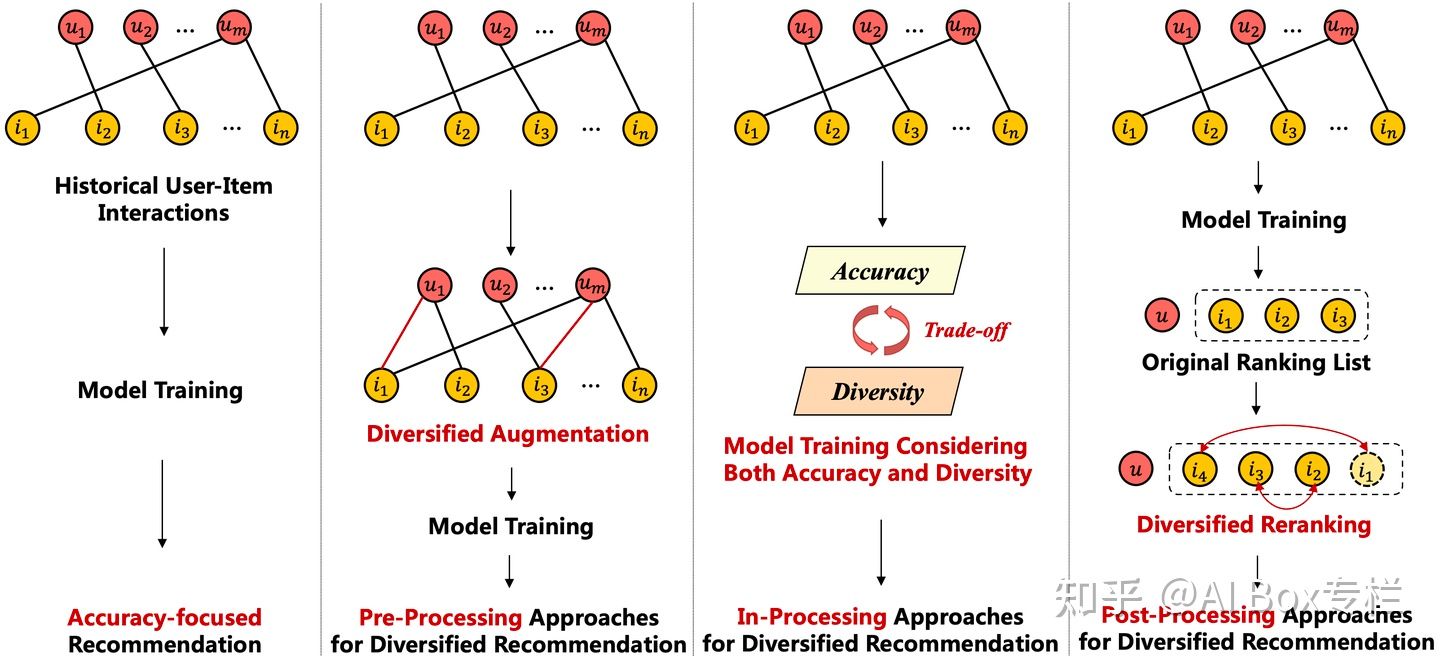
3. 前处理方法
在多样化推荐方面,一种启发式的直观思路是用面向多样性的目标来增广稀疏的用户-物品交互,从训练数据本身增强多样性。这种方法不涉及特定的训练过程,可以应用于任何下游模型。本节将介绍在模型训练之前通过预处理方法增强多样性的方法。根据现有文献的特点,将预处理方法分为三类,即 (1) 预先定义用户类型;(2) 基于相似用户的数据增广 (3) 基于图神经网络的数据增广。
| 类型 | 方法 |
|---|---|
| 预先定义用户类型 | Cluster [19] (2017)、ART [32] (2020) |
| 基于相似用户的数据增广 | FAT [45] (2021)、RW [48] (2021)、ReDA [6] (2022) |
| 基于图神经网络的数据增广 | BGCN [60] (2020)、DGCN [76] (2021)、DDGraph [72] (2021)、RGCF [61] (2022)、AdjNorm [75] (2022) |
3.1 预先定义用户类型
推荐兴趣的多样性是因人而异的。也就是说,有些用户更喜欢专注于几个特定方面的个性化推荐,而有些客户更倾向于发现新奇和意外的新事物。考虑到每个用户对多样性的容忍度不同,[19] 从用户的角度考虑用户兴趣的多样性,设计了一种基于用户配置文件的预过滤聚类方法。根据对多样性的容忍度,对不同的用户群体进行独立训练,以捕捉不同的偏好。这篇工作是基于用户行为和特征的预聚类方法,而另一篇文章 [32] 则是通过对时尚公司的实际调查,考虑到实际的商业应用场景,对客户进行分组。研究者将用户行为特征分为四种类型,即 (1) 礼品购买者,(2) 老顾客,(3) 同类商品购买者以及 (4) 潮流引领者。对于每种类型的客户,他们使用混合过滤方法来预测用户的偏好。真实用户实验证明了该方法在提高多样性和准确性方面的有效性,表明了结合真实工业场景特征的重要作用。
3.2 基于相似用户的数据增广
除了预先对用户进行分组外,还可以通过用户的交互行为或画像特征来衡量用户之间的相似性。相似用户的交互序列提供了通过数据增广来增加多样性的可能。对于序列推荐模型,推荐系统的目标是基于历史用户交互预测下一个物品。在这种情况下,FAT [45] 计算当前用户的嵌入向量与其他所有用户之间的 Pearson 系数作为相似性信息,然后选择一些相邻用户用于增广未来的交互序列。同样,ReDA [6] (下图) 利用相关用户的信息生成具有相关性和多样性的增强序列数据。他们首先通过表示检索相似的用户,然后设计两种类型的数据增强方法。除了序列推荐,RW [48] 基于用户-物品交互的二部图属性提出了一个新的推荐框架,并在构建的图上使用改进的随机游走策略增强了多样性,以隐式的方式利用了来自相似用户的信息。

3.3 基于图神经网络的数据增广
图卷积网络中对高阶邻居的探索和利用聚集了邻域节点信息,为促进多样性提供了可能。基于图协同过滤的架构,BGCN [60] 引入了一种利用贝叶斯图卷积神经网络框架对交互图中的不确定性进行建模的方法,结合了基于节点复制的随机图生成策略,用于生成与观测图相似且具有足够多样性的样本图。为了动态更新图结构,DDGraph [60] 基于 BGCN [60] 的方法,进一步设计了 QPCS 算子来建立用户和物品之间的联系。为了实现品类多样性,DGCN [76] 为图卷积网络设计了一种平衡邻域类别的方法,更多地保留了不受欢迎品类中的物品信息。他们还调整了负采样过程,以增加流行类别中的物品被采样为负例的概率。此外,DGCN [76] 使用对抗学习来提取嵌入空间中的隐式类别偏好。另一方面,RGCF [61] (下图) 和 r-AdjNorm [75] 分别从去噪和去偏的角度对 GCN 的图结构进行了修改,兼顾了准确性和多样性。

3.4 前处理方法小结
无论采用何种方法对交互数据进行预处理,其核心思想都是通过分组或增强来增强数据分布的多样性。前处理方法的优点是,转换后的数据可以用来训练任何下游算法,而不需要做一定的假设。然而,它可能会有难以估量的的准确性损失,并且可能无法提高测试数据的多样性。此外,预处理方法只能在技术和法律上允许对训练数据进行修改的情况下应用。从训练过程解耦的前处理想法具有 model-agnostic 的优势,但它也限制了与推荐结果的相关性,两阶段的过程可能导致次优的性能取舍。
4. 中处理方法
中处理方法也被称为端到端的训练方法,将对多样性的考虑融入到推荐模型的训练过程中,而不是在训练过程之前对数据进行预处理。下表根据不同方法的处理框架将中处理方法分为四类,即 (1) 基于正则化的方法,将多样性损失作为额外的正则化约束添加到优化过程中;(2) 基于模型框架的方法,修改推荐模型的训练框架以适应多样性的要求;(3) 基于强化学习的方法,将推荐系统建模为强化学习的架构,并将多样性视为奖励之一;(4) 基于因果的方法,从因果关系的角度进行推理或推断来增强多样性。
| 类别 | 方法 |
|---|---|
| 基于正则化的方法 | IDSR [13] (2020)、EDUA [39] (2021)、Div&Explain [71] (2021)、DSL [43] (2022) |
| 基于模型框架的方法 | DCF [14] (2017)、PDGAN [69] (2019)、ComiRec [10] (2020)、P-companion [26] (2020)、PURS [38] (2020)、PNN [24] (2022)、TDVAE-CF [22] (2022)、TempRec [67] (2022)、DCRS [74] (2023) |
| 基于强化学习的方法 | CascadeHybrid [35] (2020)、LMDB [18] (2021)、DivMAB [46] (2021)、SMORL [58] (2022) |
| 基于因果的方法 | DecRS [64] (2021)、UCRS [65] (2022) |
4.1 基于正则化的方法
为了提高多样性,将多样性建模为多任务训练的一种正则化损失是一种直观的想法。为了促进意图感知多样化,IDSR [13] 在序列推荐中引入了隐式意图挖掘模块,以捕获行为序列中的不同用户意图。然后,以用户、物品和子主题的表示作为相似度计算的基础,构造可学习的意图感知多样性损失作为正则化条件。EDUA [39] 考虑了用户在不同领域中,对多样性的不同兴趣水平,并利用总体偏好分布来确定准确率和多样性各自的比例。同时,将用户历史交互的跨类别分布也编码为向量,加入到损失计算中,通过平衡权重实现多样化推荐。此外,基于正则化的方法也可以应用于企业的 App 推荐等工业场景 [71],将用户在所有物品上的分布简化为高斯分布,并通过 KL 散度损失限制每个用户对应的高斯分布与标准高斯分布之间的距离。为了通过正则化损失函数进一步捕获自然时间依赖性,DSL [43] 将多样性嵌入到基于集合似然的损失函数中,利用决策点过程核的质量(准确性或相关性)和多样性分解来结合序列推荐的集合特征。
4.2 基于模型框架的方法
除了在损失函数中加入正则化约束外,研究人员还探索了通过模型框架本身提升多样性的策略。对于传统的矩阵分解算法,DCF [14] 提出了多元化协同过滤方法来解决与支持向量机的耦合优化问题。PDGAN [69] 不局限于基本的协同过滤模型,提出通过对抗学习过程学习用户的个人偏好和物品的多样性,并使用 DPP 模型作为生成器生成相关且多样化的结果。此外,ComiRec [10] 利用贪心推理算法的多兴趣提取模块来平衡训练和搜索的准确性和多样性。TDVAE-CF [22] 调整了基于变分自动编码器的推荐系统中用户偏好的潜在嵌入,使其在目标维度上多样化,同时在正交维度上保持主题相关性。针对不同品类间多样化推荐的分布需求,P-companion [26] 针对互补产品推荐问题,提出了一种分层推荐模型。在 P-companion 中,编码器模块预测输入物品的类别,然后将输出类别和产品一起放入预测模块,确保了类别的严格多样性。DCRS [74] 将推荐模块中学习到的用户表示分解为类别独立和类别依赖的组件,从两个正交的角度区分用户对物品的偏好,也关注了对物品类别定义的多样性。此外,在新闻推荐中,通过正反馈、负反馈和中性反馈的用户行为被考虑到基于会话的推荐建模中 [24],并通过对多个行为的细粒度挖掘来增强多样性。同时,TempRec [67] 也使用基于 Transformer 的注意力机制来增强新闻序列推荐的多样性。
4.3 基于强化学习的方法
在线推荐的应用场景中,用户当前的兴趣感知和对多样性的需求会对后续推荐列表产生一定的影响,并且目前推荐系统的多样性指标还不能直接优化。因此,强化学习通过多样性的奖励反馈为上述两个问题提供了解决方案。基于强化学习方法经典的探索-开发框架,上下文 Bandit 方法如多臂老虎机 (Multi-Armed Bandits, MAB) 可以同时从用户的点击反馈中学习准确性和多样性函数。例如,CascadeHybrid [35] 和 LMDB [18] 都使用混合上下文 Bandit 方法来建模物品相关性和主题多样性,CascadeHybrid [35] 考虑了级联用户行为,而 LMDB [18] 使用分散函数来描述物品集的多样性属性。DivMAB 还使用 MAB 使偏好多样化,MAB 可以在诱导时直接应用,而不是事后的去偏校正。基于强化学习的框架,SMORL [58] 通过额外的强化学习层来增强标准的推荐模型,以同时满足三个主要目标:准确性、多样性和新颖性。
4.4 基于因果的方法
传统的推荐系统专注于提高准确率,忽略了用户行为和特征之间的内在关系。为了更好地理解用户的推理过程,因果推理已经成为推荐系统中一种新兴的重要手段。DecRS [64] 研究了偏差放大的因果效应,发现其主要原因是物品分布不均衡对用户表征和预测分数的混淆效应。因此,DecRS 通过后门调整的近似算子来模拟用户表示的因果效应,这为减轻过滤气泡和回波室问题提供了指导。此外,UCRS [65] (图 6) 从因果角度考察了推荐生成过程,利用反事实推理来减轻过时用户表征的影响,并采用用户可控排名策略来调整推荐多样性,表明使用因果推理来消除偏见以增强多样性的可能性。

4.5 中处理方法小结
端到端的中处理方法在训练过程中考虑多样性的目标,而不是将建模准确性和多样性分开两个阶段,从而无缝地集成了这两个属性之间的权衡。此外,在端到端的训练阶段结合多样性,也缓解了以准确性为中心的推荐模型在训练过程中的偏差放大效应。然而,中处理方法的缺点是推荐模型的优化不能直接反映在用户的排名结果中,这可能会偏离模型设计的初衷。此外,在训练过程中对多样性的考虑往往会导致一定程度的精度损失,甚至严重影响以准确性为中心的优化过程,这在工业应用中是难以接受的。
5. 后处理方法
在实际应用场景中,推荐系统通常分为召回、排序和重排三个阶段。由于前处理和中处理方法对推荐结果的影响是间接的,而根据多样化目标直接对模型结果进行重新排序就成为了一种直观而高效的方法,本文将其归类为后处理方法。本节将后处理方法分为三类,即 (1) 基于最大边际相关性 (MMR) 的方法;(2) 基于确定性点过程 (DPP)的方法;(3) 基于精炼的方法。
| 类别 | 方法 |
|---|---|
| 基于最大边际相关性的方法 | MMR [9] (1998)、Sim-Div [56] (2001)、TempDiv [33] (2010)、Intent-oriented [63] (2011)、LFP [55] (2012)、ER [52] (2013)、DivRank [29] (2013)、adaptiveMMR [17] (2014)、DUM [4] (2015)、Cov-Interest [54] (2016)、Airbnb [1] (2020)、FDSB [40] (2022)、RL-prop [50] (2022) |
| 基于行列式点过程的方法 | DPP [66] (2018)、FastDPP [12] (2018)、DC2B [44] (2020)、DivKG [21] (2020)、CB2CF [28] (2021) |
| 基于精炼的方法 | DiRec [8] (2011)、Graph-theoretic [2] (2011)、SimGraph [51] (2016)、PostDiv [3] (2017)、Transformer-based [49] (2019)、k-MIPS [27] (2022)、DAWAR [25] (2022) |
5.1 基于最大边际相关性的方法
在信息检索领域,对检索结果进行重新排序以增强多样性的贪心策略可以追溯到 1998 年 [9],文档检索提出了最大边际相关性 (maximum marginal relevance, MMR) 的准则,在保持查询相关性的同时减少冗余。MMR 的关键思想可以概括为:
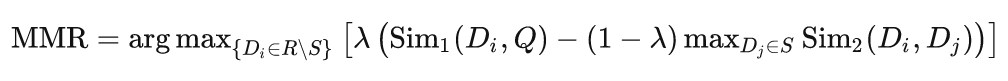
基于 MMR 的思想,后续的一系列工作围绕着重新排序阶段的多样性评分方法和优化策略展开[4, 17, 29, 33, 52, 54, 55, 56, 63]。在业务场景的多样性优化策略中,[1] 比较了各种后处理方法在租赁住宿在线平台 Airbnb 上的应用,然后利用深度神经网络设计多样化算法。从产品的角度来看,为用户提供多种选择有助于改善用户体验和业务指标。短视频 APP 快手提出了 FDSB [40] (下图),一种特征感知多样性重排算法来研究如何去平衡“相关推荐”中的相关性及多样性。RL-prop [50] 专注于重新排序过程中每个物品的多样性边际收益,通过考虑效用和多样性的指标配额来约束每类选择的物品。

5.2 基于行列式点过程的方法
除了 MMR 之外,另一种流行的后处理策略是基于确定性点过程 (DPP) 的方法。早在 2018 年 [66],谷歌公司就利用 YouTube 上的视频推荐场景证明了 DPP 在丰富多样性方面的关键作用。结合重新排序算法,DPP 在短期和长期增加用户参与度方面都显示出巨大的潜力。然而,DPP 后验推理的计算成本是 NP-hard 的,即使采用贪心策略,计算成本也很高,限制了该算法的实际应用。为了解决这一限制,FastDPP [12] 加速了 DPP 的贪心推理过程,可以适应大规模的实时场景,具有更好的相关性-多样性权衡。阿里巴巴集团进一步提出了基于变分贝叶斯推理的 Thompson 采样算法,加速了 DPP 在多样化推荐中的应用 [44]。小红书公司设计了滑动频谱分解 (SSD) 方法,在浏览长物品序列时拓宽了DPP 的应用场景。为了进一步利用知识图谱中的信息辅助多样性,DivKG [21] 结合 DPP 和 TransE 等图嵌入方法,实现相关性与多样性的权衡。
5.3 基于精炼的方法
还有一类后处理方法,其利用数学策略在模型给出推荐结果之后进行改进,这被归类为基于精炼的方法。DiRec [8] 是一种通过构建优先级覆盖树来提高多样性的代表性方法,而 Graph-theoretical [2] 则利用最大流或最大二部匹配问题作用于用户-物品交互图,从而提高推荐多样性。SimGraph [51] 将覆盖度的度量指标建模为相似图上的子模块函数,并利用 Frank-Wolfe 的贪心算法迭代推荐列表。基于 Transformer 的强大作用,[49] 应用了一种自调整机制,直接对整个列表中任意对物品之间的全局关系进行建模。
5.4 后处理方法小结
作为增强多样性的经典策略,后处理方法直观高效,已成功应用于多种实际的业务推荐场景。后处理方法通常将底层模型视为黑盒,并提供与模型无关的灵活性。这种方法不需要修改模型和训练数据,可以达到比较好的性能和多样性。然而,推荐的准确性和重新排名的多样性被人为地分为两个阶段,这不可避免地导致了两个目标的跷跷板效应。此外,重新排序阶段考虑的多样性是基于训练模型得到的结果,这必然会继承已有的偏差,甚至放大了某些影响,导致多样性的次优结果。因此,后处理方法的设计需要仔细考虑推荐模型的初始结果和重排阶段的策略选择。
6. 总结与未来展望
从信息检索领域的搜索结果多样化到推荐系统领域的用户需求多样化,搜索和推荐的多样性是一个值得学术研究的问题,同时与工业应用密切相关。本文回顾了二十多年来从经典到最新的多样化推荐的代表性方法。无论是前处理、中处理还是后处理方法,都有其各自的优点和局限性。未来工作中,推荐系统中多样性这一主题仍有后续研究和探索的可能性。
6.1 不同方法的全面评测
从系统的角度来看,虽然本文总结了多样化推荐的多种方法,但对推荐系统多样性的研究仍然是一个相对小众的方向,缺乏对现有方法优缺点进行综合评价的指导性工作。研究人员往往将多样性视为次要贡献,而不是主要目的,因此在比较基线时,他们往往比较一些以准确性为中心的模型 [6, 61],然后多样性指标在一定程度上有所改进,而不考虑与其他多样性方法进行比较。在这种情况下,推荐多样性要求后续研究者规范基线模型的选择,统一指标进行公平衡量,从而促进该领域的成熟发展。
6.2 多兴趣建模中的多样性
在前面的章节中已经介绍了 ComiRec 通过多兴趣建模来增强多样性。实际上,历史用户行为的交互顺序是建模用户多兴趣的基础,也是在增强多样性的过程中考虑用户偏好的基础。一般来说,多兴趣建模有两种结构,一种是基于 Transformer 的注意力机制,另一种是胶囊网络,这两种结构都可以用来纳入多样性指标。因此,在未来的工作中,考虑将多样性整合到多兴趣建模中是一个很有前景的方向。
6.3 可微的多样性评测指标
在推荐系统中,提高多样性所面临的挑战之一是评价指标难以直接优化。大多数指标,如基于覆盖率的度量和列表内距离,很难被直接优化。因此,不可微指标阻碍了中处理方法在多样性和其他指标之间进行端到端权衡的能力。探索一种更通用的可微多样性评测指标作用于端到端训练可能是一个有趣的研究方向。同时,在实际工业应用中,多样性指标也可以作为系统业务的有效度量,具有实际应用价值。
6.4 准确性和多样性的权衡
推荐系统的核心目的是满足用户的个性化需求,即提高推荐的准确性。然而,除了准确性之外的一些考虑,如公平性和多样性,往往会对准确性产生负面影响。因此,对推荐系统多样性的研究应该关注准确度和多样性之间的权衡,定义综合考虑准确度和多样性的指标。目前,一些工作定义了一个 F-score 来同时考虑两个指标的平衡 [14, 39, 43],应用改进的 α−NDCG 来考虑推荐的相关性和冗余性。然而,他们不能完全实现到两者之间的权衡。理想情况下,促进多样性是基于用户的不同兴趣。换句话说,多样化的推荐服务应该增强用户体验,保证推荐的准确性和用户的留存率。然而,很少有研究能够做到这一点。在未来的研究中,如何平衡多样性和准确性之间的关系,同时促进两者的提高,是学术界和工业界都应该考虑的重点。
6.5 可解释的多样化推荐方法
大多数关于多样化推荐的研究都集中在向用户展示不同的物品列表上。然而,多样性也可以指其他维度,例如可解释性,但可解释多样性这个研究方向受到的关注有限 [5, 71]。研究用户和物品的哪些特征导致了推荐列表中不同程度的多样性是有趣的,因为这将有助于开发人员更好地理解多样性的原因,并指导推荐系统在推荐时为用户生成多样化的解释。
6.6 考虑多方的多样化推荐
本文关注的是个体层面的多样性。但是,推荐的多样性也可以在系统级别考虑,即系统级别的多样性或聚合多样性。个体层面的多样性侧重于客户体验,而系统层面的多样性则来自于另一个利益相关者,即物品供应商的视角。然而,个体和系统的多样性并不是一个可以转换的概念,它们都有自己的特点。目前的研究一般侧重于单方面的多样性,较少考虑到客户和供应商的多样化需求。因此,双方甚至多方的多样性也是未来值得研究的方向。
参考文献
- [1] M. Abdool et al. Managing Diversity in Airbnb Search. SIGKDD 2020.
- [2] G. Adomavicius et al. Maximizing Aggregate Recommendation Diversity: A graph Theoretic Approach. DiveRS 2011.
- [3] A. Antikacioglu et al. Post Processing Recommender Systems for Diversity. SIGKDD 2017.
- [4] A. Ashkan et al. Optimal Greedy Diversity for Recommendation. IJCAI 2015.
- [5] G. Balloccu et al. Post Processing Recommender Systems with Knowledge Graphs for Recency, Popularity, and Diversity of Explanations. SIGIR 2022.
- [6] S. Bian et al. A Relevant and Diverse Retrieval-enhanced Data Augmentation Framework for Sequential Recommendation. CIKM 2022.
- [7] M. Boeker et al. An Empirical Investigation of Personalization Factors on TikTok. WWW 2022.
- [8] R. Boim et al. Diversification and Refinement in Collaborative Filtering Recommender. CIKM 2011
- [9] J. Carbonell et al. The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries. SIGIR 1998.
- [10] Y. Cen et al. Controllable Multi-Interest Framework for Recommendation. SIGKDD 2020.
- [11] O. Chapelle et al. Expected Reciprocal Rank for Graded Relevance. CIKM 2009.
- [12] L. Chen et al. Fast Greedy MAP Inference for Determinantal Point Process to Improve Recommendation Diversity. NeurIPS 2018.
- [13] W. Chen et al. Improving End-to-End Sequential Recommendations with Intent-aware Diversification. CIKM 2020.
- [14] P. Cheng et al. Learning to Recommend Accurate and Diverse Items. WWW 2017.
- [15] C. L. Clarke et al. Novelty and Diversity in Information Retrieval Evaluation. SIGIR 2008.
- [16] C. L. Clarke et al. An Effectiveness Measure for Ambiguous and Underspecified Queries. ICTIR 2009.
- [17] T. Di Noia et al. An Analysis of Users' Propensity Toward Diversity in Recommendations. RecSys 2014.
- [18] Q. Ding et al. A Hybrid Bandit Framework for Diversified Recommendation. AAAI 2021.
- [19] F. Eskandanian et al. A Clustering Approach for Personalizing Diversity in Collaborative Recommender Systems. UMAP 2017.
- [20] D. M. Fleder et al. Recommender Systems and Their Impact on Sales Diversity. EC 2007.
- [21] L. Gan et al. Enhancing Recommendation Diversity using Determinantal Point Processes on Knowledge Graphs. SIGIR 2020.
- [22] Z. Gao et al. Mitigating the Filter Bubble While Maintaining Relevance: Targeted Diversification with VAE-based Recommender Systems. SIGIR 2022.
- [23] Y. Ge et al. Understanding Echo Chambers in E-commerce Recommender Systems. SIGIR 2020.
- [24] S. Gong et al. Positive, Negative and Neutral: Modeling Implicit Feedback in Session-based News Recommendation. SIGIR 2022.
- [25] W. Gong et al. DAWAR: Diversity-aware Web APIs Recommendation for Mashup Creation based on Correlation Graph. SIGIR 2022.
- [26] J. Hao et al. P-Companion: A Principled Framework for Diversified Complementary Product Recommendation. CIKM 2020.
- [27] K. Hirata et al. Solving Diversity-Aware Maximum Inner Product Search Efficiently and Effectively. RecSys 2022.
- [28] Y. Huang et al. Sliding Spectrum Decomposition for Diversified Recommendation. SIGKDD 2021.
- [29] N. J. Hurley. Personalised Ranking with Diversity. RecSys 2013.
- [30] K. Järvelin et al. Cumulated Gain-based Evaluation of IR Techniques. TOIS 2002.
- [31] Y. Kim et al. Sequential and Diverse Recommendation with Long Tail. IJCAI 2019.
- [32] H. Kwon et al. ART (Attractive Recommendation Tailor): How the Diversity of Product Recommendations Affects Customer Purchase Preference in Fashion Industry? CIKM 2020.
- [33] N. Lathia et al. Temporal Diversity in Recommender Systems. SIGIR 2010.
- [34] R. I. Lerman et al. A Note on the Calculation and Interpretation of the Gini Index. Economics Letters 1984.
- [35] C. Li et al. Cascading Hybrid Bandits: Online Learning to Rank for Relevance and Diversity. RecSys 2020.
- [36] J. Li et al. FairGAN: GANs-based Fairness-aware Learning for Recommendations with Implicit Feedback. WWW 2022.
- [37] N. Li et al. An Exploratory Study of Information Cocoon on Short-form Video Platform. CIKM 2022.
- [38] P. Li et al. PURS: Personalized Unexpected Recommender System for Improving User Satisfaction. RecSys 2020.
- [39] Y. Liang et al. Enhancing Domain-Level and User-Level Adaptivity in Diversified Recommendation. SIGIR 2021.
- [40] Z. Lin et al. Feature-aware Diversified Re-ranking with Disentangled Representations for Relevant Recommendation. SIGKDD 2022.
- [41] P. Liu et al. The Interaction between Political Typology and Filter Bubbles in News Recommendation Algorithms. WWW 2021.
- [42] S. Liu et al. Long-tail Session-based Recommendation. RecSys 2020.
- [43] Y. Liu et al. Determinantal Point Process Likelihoods for Sequential Recommendation. SIGIR 2022.
- [44] Y. Liu et al. Diversified Interactive Recommendation with Implicit Feedback. AAAI 2020.
- [45] Y. Lu et al. Future-Aware Diverse Trends Framework for Recommendation. WWW 2021.
- [46] J. Parapar et al. Diverse User Preference Elicitation with Multi-Armed Bandits. WSDM 2021.
- [47] J. Parapar et al. Towards Unified Metrics for Accuracy and Diversity for Recommender Systems. RecSys 2021.
- [48] B. Paudel et al. Random Walks with Erasure: Diversifying Personalized Recommendations on Social and Information Networks. WWW 2021.
- [49] C. Pei et al. Personalized Re-ranking for Recommendation. RecSys 2019.
- [50] L. Peska et al. Towards Results-level Proportionality for Multi-objective Recommender Systems. SIGIR 2022.
- [51] S. A. Puthiya Parambath. A Coverage-Based Approach to Recommendation Diversity On Similarity Graph. RecSys 2016.
- [52] L. Qin et al. Promoting Diversity in Recommendation by Entropy Regularizer. IJCAI 2013.
- [53] J. Sá et al. Diversity Vs Relevance: A Practical Multi-objective Study in Luxury Fashion Recommendations. SIGIR 2022.
- [54] C. Sha et al. A Framework for Recommending Relevant and Diverse Items. IJCAI 2016.
- [55] Y. Shi et al. Adaptive Diversification of Recommendation Results via Latent Factor Portfolio. SIGIR 2012.
- [56] B. Smyth et al. Similarity vs. Diversity. LNAI 2001.
- [57] I. Srba et al. Auditing YouTube’s Recommendation Algorithm for Misinformation Filter Bubbles. TOIS 2023.
- [58] D. Stamenkovic et al. Choosing the Best of Both Worlds: Diverse and Novel Recommendations through Multi-Objective Reinforcement Learning. WSDM 2022.
- [59] H. Steck. Item Popularity and Recommendation Accuracy. RecSys 2011.
- [60] J. Sun et al. A Framework for Recommending Accurate and Diverse Items Using Bayesian Graph Convolutional Neural Networks. SIGKDD 2020.
- [61] C. Tian et al. Learning to Denoise Unreliable Interactions for Graph Collaborative Filtering. SIGIR 2022.
- [62] S. Vargas et al. Coverage, Redundancy and Size-awareness in Genre Diversity for Recommender Systems. RecSys 2014.
- [63] S. Vargas et al. Intent-oriented Diversity in Recommender Systems. SIGIR 2011.
- [64] W. Wang et al. Deconfounded Recommendation for Alleviating Bias Amplification. SIGKDD 2021.
- [65] W. Wang et al. User-controllable Recommendation Against Filter Bubbles. SIGIR 2022.
- [66] M. Wilhelm et al. Practical Diversified Recommendations on YouTube with Determinantal Point Processes. CIKM 2018.
- [67] C. Wu et al. Is News Recommendation a Sequential Recommendation Task? SIGIR 2022.
- [68] H. Wu et al. A Survey of Diversification Techniques in Search and Recommendation. arxiv 2022.
- [69] Q. Wu et al. PD-GAN: Adversarial Learning for Personalized Diversity-Promoting Recommendation. IJCAI 2019.
- [70] Y. Wu et al. TFROM: A Two-sided Fairness-Aware Recommendation Model for Both Customers and Providers. SIGIR 2021.
- [71] W. Yang et al. On the Diversity and Explainability of Recommender Systems: A Practical Framework for Enterprise App Recommendation. CIKM 2021.
- [72] R. Ye et al. Dynamic Graph Construction for Improving Diversity of Recommendation. RecSys 2021.
- [73] M. Zhang et al. Avoiding Monotony: Improving the Diversity of Recommendation Lists. RecSys 2008.
- [74] X. Zhang et al. Disentangled Representation for Diversified Recommendations. arxiv 2023.
- [75] M. Zhao et al. Investigating Accuracy-Novelty Performance for Graph-based Collaborative Filtering. SIGIR 2022.
- [76] Y. Zheng et al. DGCN: Diversified Recommendation with Graph Convolutional Networks. WWW 2021.
- [77] C.-N. Ziegler et al. Improving Recommendation Lists through Topic Diversification. WWW 2005.
- [78] S. Yang et al. Graph Exploration Matters: Improving both individual-level and system-level diversity in WeChat Feed Recommender. arxiv 2023.

















 798
798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









