







写在前面
最近在学习场景图生成SGG,看了2020 CVPR oral 《 Unbiased Scene Graph Generation from Biased Training 》,打算复现这篇论文。论文基于mask-rcnn论文算法,相比yolo,在配置环境的时候,多了编译环境这一步,因为涉及C++,所以可能会出现一些难题,在复现的过程中,也学习了很多有用的知识,所以准备记录一下。
github链接点这里
环境配置
我的配置以及工具: uabntu16.04 2080Ti pycharm notepad++,下载工程解压后,cd到工程下,主要根据INSTALL.md配置,第一次在配置这里的时候可能没问题,但是在后续就会有问题,所以根据我自己配置的过程,从一开始就修改相应的地方,这样快一些。
编译(INSTALL.md)
conda create --name SGG python=3.7
conda activate SGG
conda install ipython
conda install scipy
conda install h5py
pip install ninja yacs cython matplotlib tqdm opencv-python overrides
# -c pytorch 我去了,从官网下貌似有点慢,还是添加镜像源吧
conda install pytorch==1.4.0 torchvision==0.5.0 cudatoolkit=10.1
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
python setup.py build_ext install
git clone https://github.com/NVIDIA/apex.git
cd apex
# WARNING if you use older Versions of Pytorch (anything below 1.7), you will need a hard reset,
# as the newer version of apex does require newer pytorch versions. Ignore the hard reset otherwise.
git reset --hard 3fe10b5597ba14a748ebb271a6ab97c09c5701ac
python setup.py install --cuda_ext --cpp_ext
执行python setup.py install --cuda_ext --cpp_ext,如果nvcc -V显示的版本不是10.1就会报错:cuda和代码编译使用的cuda版本不一样,网上的方法有两种:(1)修改语句python setup.py install --cuda_ext --cpp_ext(2)修改setup.py.我也尝试了第一种方法,后来训练时遇到了一些问题,不知道是不是这个引起的,所以打算编译这里,即安装cuda10.1,但是服务器上已经安装了cuda10,这样就需要考虑cuda版本切换的问题,查了很多资料,最后成功了。
cuda版本切换
下载安装cuda10.1
wget https://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run
sudo sh cuda_10.1.243_418.87.00_linux.run
查看本地安装的cuda版本:

有10.0和10.1两个版本的CUDA,其中靓色的cuda是一个软链接,它指向我们指定的cuda版本。
查看软链接指向的是哪一个版本:
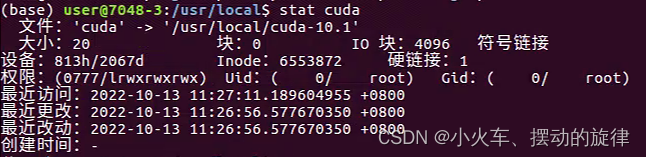
软连接可以帮助我们选择用哪个版本的cuda,这里我已经修改指向cuda10.1了.在此之前,还要修改环境变量中的已经指定了版本的cuda路径。总的来说,切换版本的步骤如下:
sudo gedit ~/.bashrc #打开环境文件
(一般在文件末尾)将许多/usr/local/cuda-10.0/...这样的路径中的-10.0去掉,变为/usr/local/cuda/...
这里不指定版本后面就可以进行cuda版本的切换
修改好之后,保存并关闭文件,执行命令source ~/.bashrc使环境变量的修改生效
# 切换版本
sudo rm -rf /usr/local/cuda #删除之前创建的软链接
sudo ln -s /usr/local/cuda-10.1 /usr/local/cuda #创建链接到cuda10.1的软链接
nvcc --version #查看当前cuda版本
执行nvcc --version后,看显示的版本是不是和软链接指定的一样,如果是则没问题了。如果不是,则还需要修改环境变量PATH,输入
echo $PATH
查看环境变量,会发现/usr/local/cuda/bin这个在最后,前面还有其他的路径,也就是说在寻找cuda时,如果在前面的路径中找到了cuda,就不会去后面的路径中找了,为了提高优先级,执行:
export PATH=/usr/local/cuda/bin:$PATH
后就可以把/usr/local/cuda/bin优先级提前了,再nvcc --version查看cuda版本,应该就切换过来了(当时忘记截图了~~)。参考:
ubuntu下安装多版本cuda及版本切换教程
linux上多个CUDA切换使用(小白教程)
2.多个cuda共存,解决nvcc –V查看的cuda版本不是软链接的cuda对应的
完成版本切换之后,再执行编译:
python setup.py install --cuda_ext --cpp_ext # 记得在apex路径下哈
#cd .. 退出apex,
python setup.py build develop
在执行 python setup.py build develop之前还需要修改一些参数,加入不修改,后面训练会报错:RuntimeError: cuda runtime error : invalid device function…,我在网上找了好久才找到解决方法,即要改计算机计算能力的参数:
arch=compute_37,code=sm_37
参数里边的37指的是 GPU 显卡的计算能力,出现这种错误一般是计算能力与 GPU 显卡不符造成的,可以网上查询一下自己 GPU 显卡的计算能力,把这个数值改成自己 GPU 显卡的计算能力,重新编译。修改文件为Setup.ipynb,搜索 arch=compute可以定位到。查看显卡的计算能力值
修改完后,执行
python setup.py build develop
至此,编译结束。
执行requirements.txt
pip install -r requirements.txt
一些可能遇到的问题
(1)VG_stanford_filtered_with_attribute_train_statistics.cache文件名字好像有问题,下载下来的文件名with少了个i,当时调试好久才发现~ ~
(2)路径问题中,会报错找不到文件 /media/…,这个路径是作者加上去的,需要改为自己的路径,但是有个问题就是报错里没有显示在哪个py中,找起来太麻烦,可以用notepad++搜索文件夹下所有文件的内容进行查找哈,直接搜索报错内容中路径的关键词。
(3)训练到时候出现 NO-MATCHING,作者在issue上说了不影响。
(4)assert len(fns) == 108073 AssertionError,合并数据集时需要用语句:cp -rf --link VG_100K_2/* VG_100K/。














 2002
2002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









