






《A coarse-to-fine deformable transformation framework for unsupervised multi-contrast MR image registration with dual consistency constraint》由粗到细的可变形变换无监督多对比MR的双重一致性配准限制
创新点
1)提出了一个无监督的粗到细的注册框架。通过一个仿射变换网络获得一个粗略的注册,然后通过一个后续的可变形变换网络进行细化。这两个变换被整合,实现了端到端的图像注册。
2)设计了一个双重一致性约束来最大化多对比度MR图像的拓扑图的交叉相关性。反变形场由正变形场直接生成,以减少时间要求。设计的一致性约束在双向变形上被强制执行,以抑制像素的折叠。
3)设计了一个基于先验知识的损失函数,以提高相互信息(MI)的灵敏度,从而实现更准确的登记。具体来说,设计了一个负面积约束,以限制在固定图像背景中登记的信号。
4) 广泛的实验表明,与现有的广泛使用的方法相比,无论是否有第一步的物理空间对齐,所提出的登记方法都具有优越性。
对于多模态配准背景
随着深度学习领域的快速发展,一些基于深度学习的图像配准模型被提出。首先,利用深度学习增强迭代方法的配准性能。然后,引入深度强化学习来预测变换步骤,直到达到最优对齐。随着对配准速度要求的提高,提出了基于深度学习的配准方法。其中一个代表性的工作是STN(空间变换网络),它产生密集的可变形变换来对图像进行配准。此后,STN在各种情况下被改进和利用。Yoo等人成功地利用STN对电镜图像进行了配准。他们训练一个自动编码器来重建固定图像,并计算重建的固定图像和相应的移动图像之间的新损失。Krebs等人,提出了一种随机潜在空间学习方法来缓解对空间正则化的要求。
DeVos等人开发了一种多阶段和多尺度的方法来配准带有归一化互相关(NCC)损失和弯曲能量正则化的单峰图像。
然而,该方法将多个网络级联,严重增加了计算复杂度。Balakrishnan等人提出了著名的框架VoxelMorph及其导数版本,该框架计算了变换的梯度,以在优化过程中反向传播变形误差。但是,由于上述方法都着重于单模图像配准、多对比度图像配准仍有待探索。
多模态配准更具挑战性,因为它难以定义有效的相似性度量来指导不同模态间的局部匹配。互信息(MI)是现有研究中使用频率最高的监督[47]。Li等人[48]通过使用平均相位图上的描述子匹配对多模态视网膜图像进行全局配准,并使用一种可变模态独立的邻域描述子方法对配准结果进行局部优化。遗憾的是,该方法基于人工设计的特征,鲁棒性有限。
Ceranka等人[49]提出了一种全身DWI和t1加权图像配准方法。该方法将两幅模态图像的骨盆区域大致对齐,然后利用MI指导全局配准。Cao等人开发了一种基于图像合成的方法。他们采用随机森林学习CT (computed tomography, CT)图像和MR图像之间的变换,合成了解剖结构相似的伪CT图像和伪MR图像。通过这种方式,他们将多模态图像配准任务转换为单模态图像配准任务。在[51]中还提出了对这个原始实现的改进模型。然而,这些方法需要一个鲁棒的域变换算法,其配准性能受到合成图像[50]质量的很大影响。
method
提出了一种简单的无监督多对比度MR图像配准算法。该方法在可变形网络中嵌入仿射变换网络,实现粗到精配准。
为了进一步提高配准性能,设计了双一致性约束。同时,实现了基于先验知识的引导函,这里,让K∈R代表多对比度数据集中的样本数,F ⊃f1,f2 ----fK和M ⊃m1,m2 ----mK指的是成对的固定图像集和移动图像集。
A.仿射变换网络—ATNet(仿射变换:旋转、平移、缩放、翻转等操作,用回归网络实现)
我们使用STN对运动图像进行仿射变换,公式: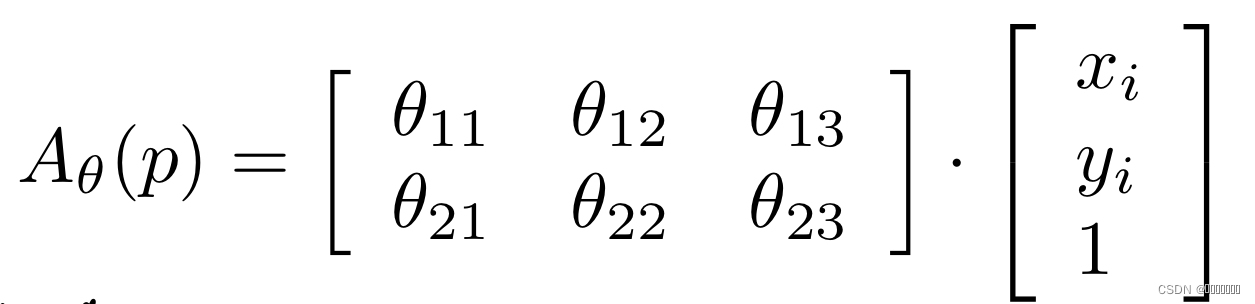
让p(xi,yi)代表从m中取样的像素,xi,yi表示对应像素的坐标,θ表示用于确定线性变换的参数。
我们预先训练一个浅层回归网络来预测这些参数。利用得到的参数,STN可以在无人参与的情况下自动进行仿射变换,将运动图像M大致对齐到对应的固定图像F上。这种回归网络在框架中被称为ATNet,通过此网络获得的原始预测图像被表示为MA ⊃mA1,mA2----mAK, 预测大致与F对齐,还需要密集的变形变换来对齐详细的局部结构。可以看出,仅仅进行线性变换并不能捕捉到多对比度图像之间的细微差别。此外,由于仿射变换是全局信息驱动的,在低信号区域注册时,性能可能会受到影响。因此,将仿射变换网络的预测结果视为粗配准图像,有待进一步改进。
B.可变形变换网络—DTNet(U-Net或其变体)
可变形变换对于图像的精细配准非常重要。VoxelMorph[2] -[5]对每个像素构造可微分运算,通过网络训练优化运算,实现图像配准。让我们定义φ为得到的变换场。φ中的每个值表示一个偏移距离,o指mk的变换算子,由像素移位和插值两部分组成。
对于mk变换到p’中的每一个像素p,可以定义为:p’=p+φ( p)
VoxelMorph在像素变换后对相邻像素进行额外的线性插值,以避免变换后图像的不连续: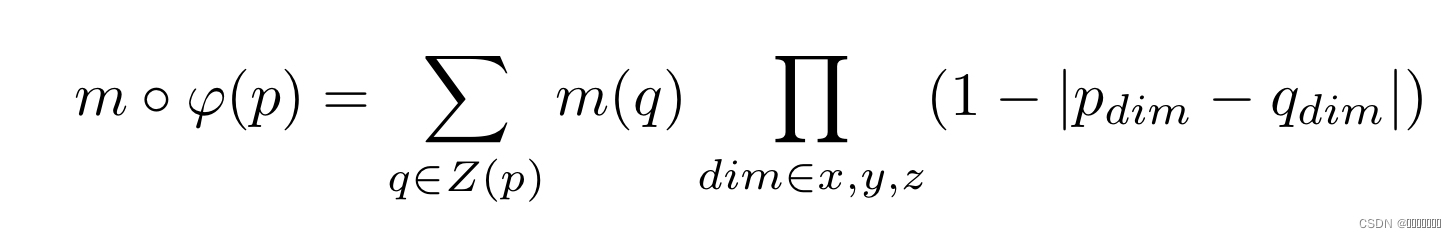
其中Z表示相邻像素组成的区域。
通过这种可微插值运算,预测结果更加平滑、真实。
使用VoxelMorph作为我们的可变形变换网络(DTNet)来进行精细的图像配准。对网络结构进行了一些修改。例如,我们采用了更深层次的卷积结构来完全提取特征。另外,将ReLu的激活功能替换为Leaky ReLu。
C.粗到细的多对比度图像配准框架
为了减少无监督多对比度图像变换的挑战,我们提出了一种粗到细的图像配准框架。具体来说,我们将预先训练好的带有冻结参数的ANet D (F, M)嵌入到TNet中。仿射变换预测MA可作为DTNet的输入。通过这种方式,DTNet接收到的图像大致与固定图像对齐,图像差异减少。与现有的使用仿射变换作为预处理来进行两步注册然后细化预测的方法不同,所提出的框架采用了在一个架构中进行这些操作的端到端方法。与现有的配准方法相比,该方法不需要迭代仿射变换和变形变换。同时,我们可以得到仿射变换预测和可变形变换预测作为框架的边输出。
D.双重一致性的双向图像变换
直观地说,配准过程应该是对称的,即运动图像和固定图像之间的双向变换。该假设在[35]中首次提出,采用欧拉拉格朗日方程进行迭代优化,在医学图像配准中取得了很大的成功。受此启发,我们提出了一种双向图像变换方法。
φ是用于移动图像注册为固定图像的变形场,为了反转变换并恢复运动图像,简单将-φ应用于正向变换是行不通的,因为φ和图像像素之间的对应关系已经被破坏了。令φi,j为移动图像像素i,j的位移,在前向变换后像素(i,j)变成(i’,j’),-φi,j应该是(i’,j’)的反转位移,而不是(i,j),我们需要发现-φi,j与(i,j)的联系。因此,我们构建反转场φ-1去指导反向变换。对此,没有建立一个新网络无重新生成φ-1,而是通过φ推断φ-1来减少复杂操作。具体来说,由于φ有二维空间的水平和垂直偏移组成,首先对φ进行分解,得两个偏移场φx,φy,然后我们将原始的φ进行扭曲,形成变形的偏移场,产生一个新的变换场。最后通过乘以-1,得到反转场φ-1,通过这种方式我们成功地将变换场与注册图像中的像素对齐,公式表示如下: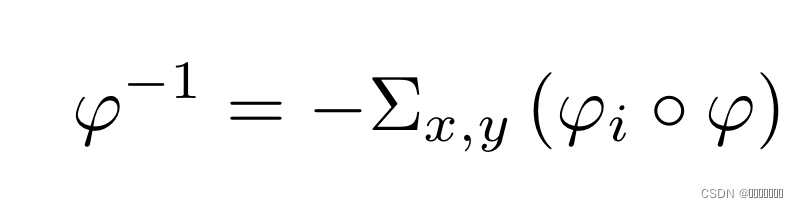
由于没有参考图像来评估多对比登录预测的准确性,所以很难同时从M到F、从F到M的双向配准。对此,提出了个折中的方法,即将多对比度的双向图像配准任务转换为单模图像配准任务,我们使用预测值MD⊃m1,m2 …mk,而不是固定的图像F来计算反变换后的图像,MD-1 = MD ◦φ-1。这里,假设MD-1仍应保持与MA相同的分布。在此基础上,我们使用一致性损失来精确约束MD-1和MA,它可以是MSE或NCC。然后得到我们的综合框架,即具有双重一致性约束的从粗到细的多对比度图像登记框架。
E.具有双重一致性约束的由粗到细的多对比度图像配准框架
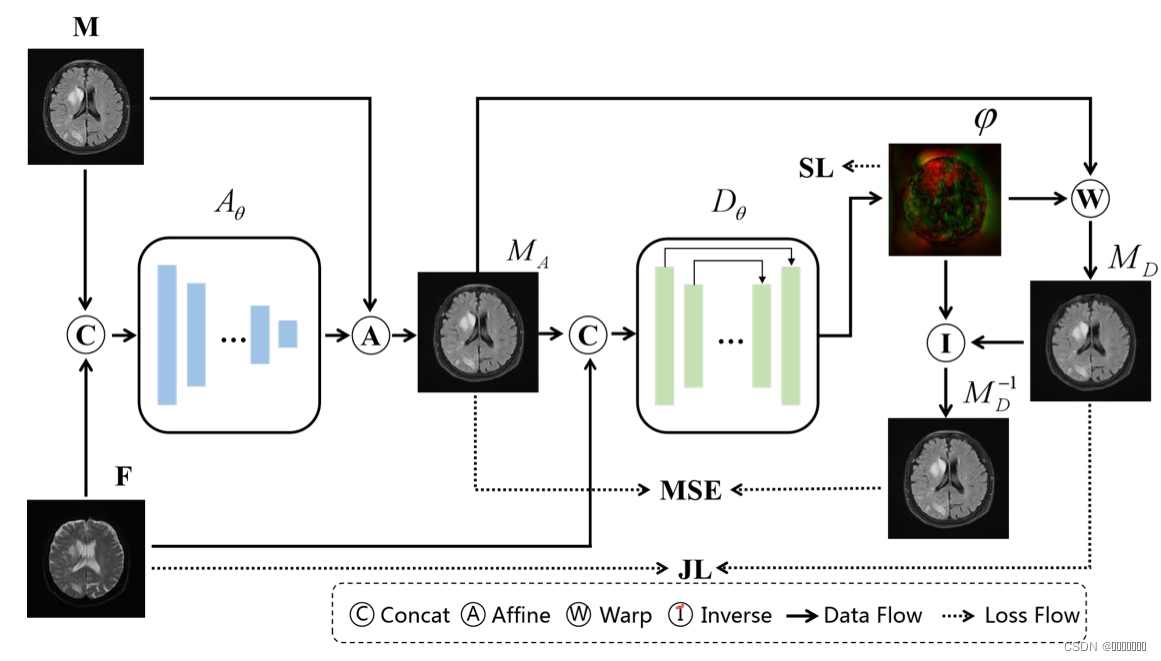
- 预先训练好的仿射变换网络ATNet用于粗配准,输入的是一对M和F的MR多对比配准图像,输出的是从M到F的粗略配准。一旦预训练完成,ATNet参数就被冻结;
- 可变形变换网络DTNet生成最终的预测结果,输入DTNet的是F和MA,输出的是一个密集的变形场φ,通过φ最终预测结果MD被生成;
- 双重一致性约束,提出一个新的从MD到MD-1的反变换场来进一步提高配准性能,计算了反转变换场φ-1并用来变形MD是得到MD-1。通过强制执行MD-1和MA之间的相似度测量实现了双重一致性约束。
有了双向配准策略,在图像处理过程中不希望出现的插值现象就会消失——why?
F.损失函数
见框架可知,使用多个损失函数来优化多对比度MR图像配准,简单起见,使用ξθ(·)代表未定义的网络,可以是ATNet(Aθ)也可以是DTNet(Dθ)。
最重要的损失函数是MI,可以衡量两个随机变量的分布依赖性。这里,定义了两个边缘概率分布:pF(f)和pM(m)和一个联合分布pF,M(f,m)。MI(互信息)以Kullback-Leibler测量法,通过计算联合分布pF,M(f,m)和分布pF(f)pM(m)之间的距离来衡量F和M之间的依赖程度,MI损失公式可写为:

MI
基于互信息的图像配准算法以其较高的配准精度和广泛地实用性而成为图像配准领域的研究热点之一,而基于互信息的医学图像配准方法被认为是最好的配准方法之一。
在图像配准中,两幅图的互信息是通过他们的熵以及联合熵来反映他们之间的信息包含程度,对于M,F来说,其互信息表示为:MI(M,F)=H(M)+H(F)-H(M,F)
其中: 对于一幅图像来说,其熵的计算表达式如下:
hi表示图像Y中灰度值为i的像素点总数,N表示图像Y的灰度级数。显然Pi表示灰度i出现的概率,于是很自然的就会想到用直方图来计算。(对于单幅图像MATLAB中可由entropy()函数求得)
联合熵为:
对于两幅图像X、Y来说,利用联合直方图,显然可以计算出二者的联合熵
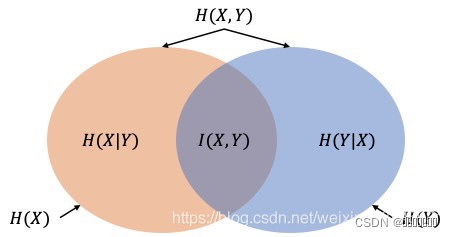
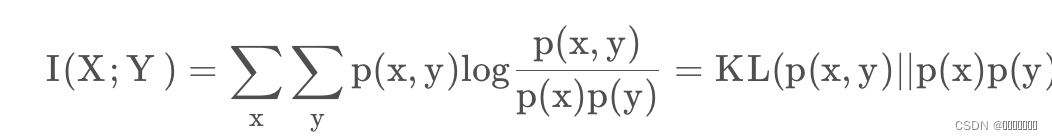
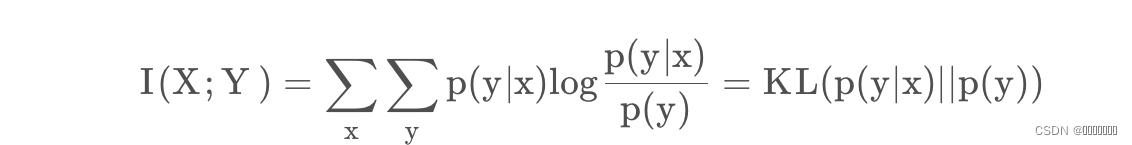
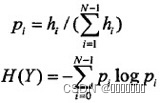

如果F和M是独立的,pF,M(f,m)等于pF(f)pM(m),MI(F,M)将为零,这意味着两个变量之间没有相互信息。MI的最大化是一个普遍而强大的标准,因为没有对这种依赖的性质作出假设,也没有对涉及的不同模式的图像内容施加限制。
所涉及的不同模式的图像内容[47]。由于MR图像通常是灰度的,背景值接近于0,建议注册图像的背景区域不应该出现信号。在此基础上,提出一个基于先验知识的背景抑制损失函数。当f为背景像素时,MSE(f,m)=(f-m)2 [MSE:均方误差计算]。结合MI损失函数和先验知识的,结合MI损失函数和基于先验知识的背景抑制损失函数,我们得到第一个损失函数,它被称为基于先验知识的联合损失函数(JL(F,ξθ(F,M),λ)),如公式6所示:first loss为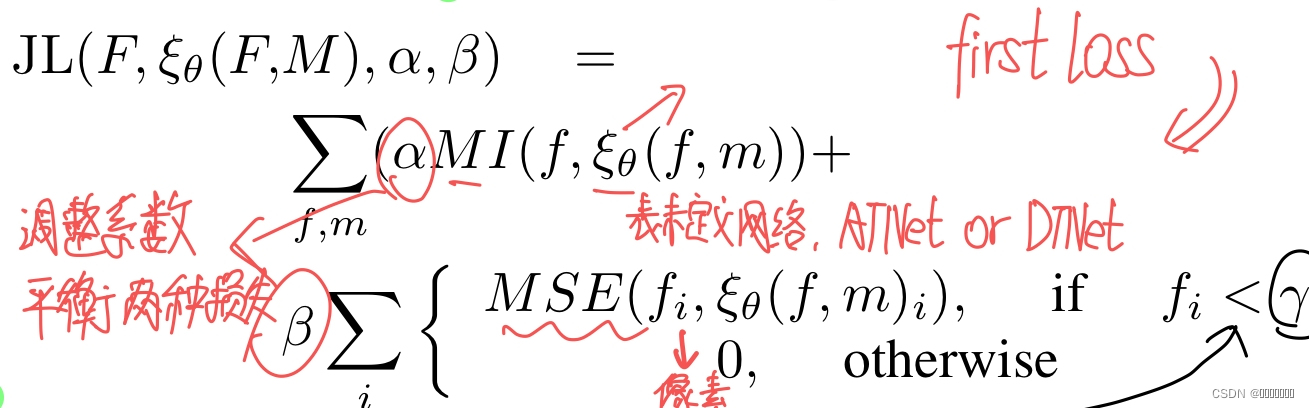
其中,i∈N代表图像中的像素,γ是从数据集中获得的阈值,用于判断像素是否为背景,α和β是调整因子,用于平衡两种损失。JL不仅可以通过最大化MI来约束全局图像对齐,而且还可以对定义区域内的错误预测进行惩罚。这使得预测更符合医学图像的性质。
second loss:第二个损失函数是为了满足双重一致性约束,一个简单的MSE损失被计算出来,而不是MD-1和MA之间的MI损失。对MSE损失的利用不是固定的,可以用类似的损失来代替,如NCC或L1-norm。
last loss:最后一个损失函数的计算是为了约束变换场φ。变换可能在没有约束的情况下发生不规则的位移,而通过插值算法,上述两个损失仍然可以很小。为了防止这种情况,我们设计了一个空间平滑的损失函数来细化变换场φ:
 其中∇(·)代表梯度的计算。通过限制变形场的梯度,我们确保变形场是平滑的,并且可以避免极端的像素位移。
其中∇(·)代表梯度的计算。通过限制变形场的梯度,我们确保变形场是平滑的,并且可以避免极端的像素位移。
total loss: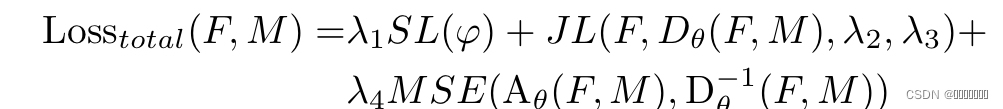
实验细节
关于数据:将所有数据集分成两组,一组根据提供的扫描信息进行物理空间排列,另一组没有。分为两组实验,在第一组实验中,只利用有扫描信息的案例,选择426个例子作为训练集,剩余40作为测试集;第二组实验中,将包含没有扫描信息的案例都作为训练集。
实验细节:ATNet网络倾向于选择见到的网络结构来降低计算的复杂度,是用一个回归网络实现的,包含五个下采样块和两个全连接层,五个下采样块由两个3x3卷积核2x2最大集合组成。左后附加两个全连接层以产生6个转换参数。通道数分别为16、32、32、64、64、128、32、6。DTNet采用了多种网络,包括VoxelMorph(VM),
VoxelMorph-diff(VM-diff),LT-Net以及Symmetric Normalization(SyN),对于VM进行微调(使用MI损失);对于LT-Net,舍弃标签转移部分,保留主要配准框架和逆向部模块;对于SyN有两方面设计,一:移动图像经过基于ANTs的仿射变换和SyN,二:移动图像只经过SyN。
学习率设置为0.01,批量大小被设置为32,损失函数四个参数根据经验设置为1,4,100,100,JL的阈值因子被设置为0.1。
评价结果:使用Dice = 2TP/(2TP + FP + FN), Recall = TP/(TP + FN), and Precision = TP/(TP + FP)
实验结果
参考:
MI互信息
基于互信息图像配准含代码
论文:DOI 10.1109/TMI.2021.3059282















 693
693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









