







A Coarse-to-Fine Deformable Transformation Framework for Unsupervised Multi-Contrast MR Image Registration With Dual Consistency Constraint, TMI2021
简介
本文提出了一种无监督的用于不同模态MRI(T1,T2,DWI等)图像的配准框架。
背景介绍
在诊断中综合不同模态的MRI数据是很常见的方式,但是由于成像环境、移动、电流等因素,不同模态的成像会存在misalignment的问题,需要采用方法进行配准。
传统的图像配准方法主要基于迭代的方式,缺点是效率低下,在实际诊断环境中不够实用。深度学习的方法在同模态图像配准上取得了一定研究,但是在不同模态的图像的配准上有很多困难。最主要的就是难以找到度量配准结果的方式,目前主要采用的是基于互信息(Mutual Information,MI)的评估方式。许多深度学习方法使用域到域转换模型将问题转变为同一个模态的配准,从而让模型受制于转换模型的效果。除此之外,深度学习方法的鲁棒性不够强。
网络结构
对于一个数据集 K K K,其中有fixed images表示为 F = { f 1 , f 2 , . . . f K } F=\{f^1,f^2,...f^K\} F={f1,f2,...fK},moving images表示为 M = { m 1 , m 2 , . . . m K } M=\{m^1,m^2,...m^K\} M={m1,m2,...mK}。所有公式都是二维的。
整体模型的结构如下:
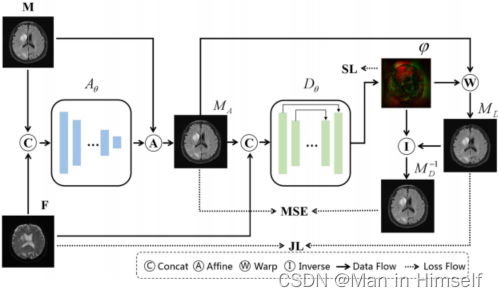
仿射变换网络ATNet
对于粗粒度配准,本文假设其进行了一个线性变换,参数如下:

并回归训练了一个浅层网络用于预测参数
θ
\theta
θ,该网络的输入是一对待配准图片,输出是moving image到fix image的仿射变换(也就是相同长宽的矩阵,通道为2即二维两个方向上的偏移)。变换后的图片可以表示为
M
A
=
{
m
A
1
,
m
A
2
,
.
.
.
m
A
k
}
M_A=\{m^1_A,m^2_A,...m^k_A\}
MA={mA1,mA2,...mAk}。
可变形变换网络DTNet
作者使用VoxelMorph作为可变形变换网络,用于更细粒度的结构调整。这一步就获得了变换场 ϕ \phi ϕ,其值为每一个像素的偏移,表示为: p ′ = p + ϕ ( p ) p'=p+\phi(p) p′=p+ϕ(p)。变换后的图片可以表示为 M A = { m D 1 , m D 2 , . . . m D k } M_A=\{m^1_D,m^2_D,...m^k_D\} MA={mD1,mD2,...mDk}。
之后还按照VoxelMorph进行了插值处理确保图像的平滑。
双重一致性约束下的双向变换
一般来说,配准的过程应该是对称的,即也可以完成从moving images到fixed images的配准。为了获得在前向变换中获得的逆变换 ϕ − 1 \phi^{-1} ϕ−1,作者没有从头训练一个变换函数(费时),也没有直接对 ϕ \phi ϕ的输出取负数(因为像素的位置发生了偏移),而是采用如下公式: ϕ − 1 = − ∑ x , y ( ϕ i ∘ ϕ ) \phi^{-1}=-\sum_{x,y}(\phi_i\circ\phi) ϕ−1=−x,y∑(ϕi∘ϕ)
该公式写的不是很好理解,我参考了作者代码后发现,其实是把形变场的两个通道(对应该位置像素点x和y方向上的位移)分别视为一张图像,然后经过变换后得到的新的变换场,这样就相当于把变换场也配准到了变换后的图像。

由于没有参考图像用于评估配准的准确性(无监督),所以作者直接将上一步的输出 M D M_D MD经过逆变换后,与上一步的输入 M A M_A MA进行MSE或NCC的损失计算。
但是按照我的理解,之前的反转过程一定能够得到完美的逆变换,这一项应该始终都是0啊。
损失函数
配准损失
首先是经典的互信息(取负表明最大化),其中f和m代表了fix images和moving images。
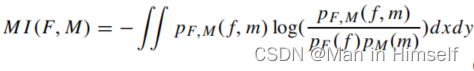
除此之外,作者基于磁共振背景的灰度信号接近于0提出了背景抑制损失函数,该函数将f中灰度值小于某个值
γ
\gamma
γ(由数据集据统计得到)的部分特别额外做一个MSE运算(其实也就是相当于让配准后图像对应位置也应该是0),joint-loss如下:
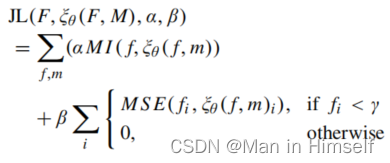
双重一致性损失
按照之前所述,就是通过对第二轮变形配准后的图像经过逆变换后和配准前的图像进行MSE或NCC的损失。
变换场约束损失
还有一项损失是为了防止变换场出现不规则的变化,对变换场做了额外的梯度惩罚损失:
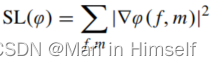
注意这里是gradient penalty类型的损失而不是类似总变差的损失。
最后整体的损失函数为:
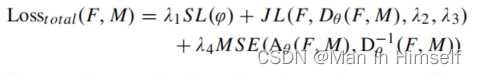
实验结果
作者在FLAIR和DWI的配准是做了实验。使用从贵州省人民医院的数据,作者在由扫描信息和没有扫描信息的情况下做了实现。(没有扫描信息指的是没有像素空间和FOV等,采集到的图像无法预先进行物理上的对齐)
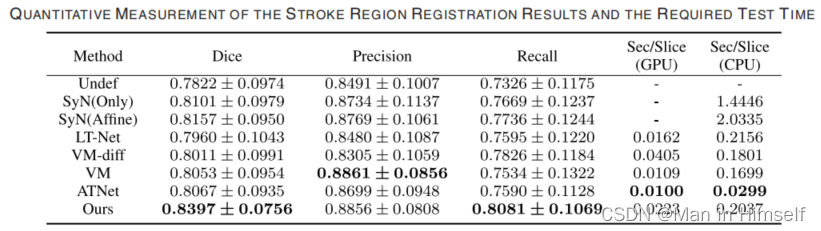
不同模态间的配准缺乏一些公认的评估方法,因此作者通过医生标注中风损伤区域的Dice相关损失来定量化衡量配准结果。并使用Jacobian determinant小于0的像素数量用来衡量形变场的folding情况。
部分实验结果如下:
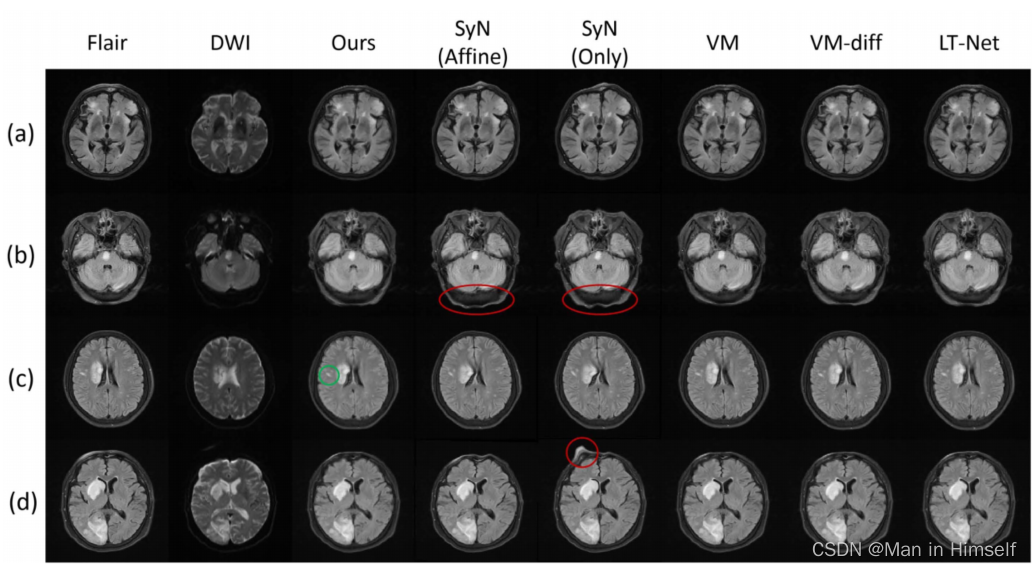
可以看到SyNzhe这种基于迭代的方法产生了一些意外的形变,在©中可以看到其它方法对于中风区域的配准略有不足。定量结果如下:
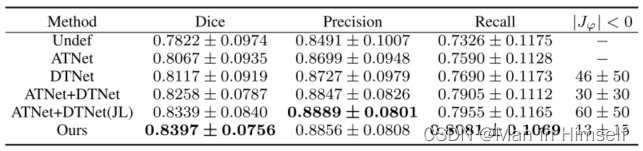
作者还进行了消融实验,证明了模型结构和JL损失的有效性。
最后,作者还验证发现模型在缺少扫描信息进行预先对齐的情况下的表现也令人满意。
















 9541
9541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









