









📢如何做好一个学术小裁缝?本篇文章是博主人工智能(AI)领域学习时,用于个人学习、研究或者欣赏使用,并基于博主的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在👉学术裁缝专栏:
【Academic tailor】(1)---《学术裁缝必备小知识:全局注意力机制(GAM)》
学术裁缝必备小知识:全局注意力机制(GAM)
目录
3. 多头注意力(Multi-Head Attention)
学术小裁缝精髓:
1.广泛阅读:从领域出发,关注方法
2.优化创新:有一个形象的比喻,比如一个大创新点是西红柿炒鸡蛋,问题领域是炒鸡蛋,方法是加西红柿。那么你可以把西红柿换成软西红柿,青西红柿,如果你换成了青椒/韭菜,偶买噶,你是天才。或者把鸡蛋换鸭蛋/鹅蛋(即新方法老问题,老方法新问题,如果是新方法新问题那就更好了)。如果有文章提出在鸡蛋里加味精更好吃,就把味精加到西红柿炒鸡蛋里。
3.内容美化:实验分析和公式要多,图要精致、漂亮,公式复杂化
4.投稿技术:做好期刊背调(领域,时间等),Coverletter好好写,写完了就投,拒了就换
5.保命方法:交流要礼貌,让你加参考文献你就加,实验让做就做,responese to reviewers要写的多,最好让审稿人看完就不用去翻你的修改稿了。

0 摘要
注意力机制是深度学习中的重要技术,尤其在序列到序列(sequence-to-sequence)任务中广泛应用,例如机器翻译、文本摘要和问答系统等。这一机制由 Bahdanau 等人在其论文《Neural Machine Translation by Jointly Learning to Align and Translate》中首次提出。以下将详细介绍这一机制的背景、核心原理及相关公式。
全局注意力机制(Global Attention Mechanism, GAM)由 《Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions》提出,是一篇针对计算机视觉任务提出的方法。这篇文章聚焦于增强深度神经网络中通道和空间维度之间的交互,以提高分类任务的性能。与最早由 Bahdanau 等人提出的用于序列到序列任务的注意力机制 不同,这篇文章的重点是针对图像分类任务,并未专注于序列任务或机器翻译问题。
1 注意力机制提出背景
传统的编码器-解码器(Encoder-Decoder)架构在神经机器翻译任务中依赖一个固定长度的向量表示输入序列。对于长句子,这种固定大小的表示无法有效捕获全部关键信息,导致翻译质量下降。
注意力机制通过动态计算上下文向量(context vector),结合解码器的当前状态,有效地解决了这一问题,使模型在解码过程中能够关注输入序列中最相关的部分。
2 注意力机制核心组成
1. 编码器-解码器框架
全局注意力机制嵌入于标准的编码器-解码器框架中:
编码器(Encoder):
将输入序列 编码为一组隐藏状态
。
解码器(Decoder):
逐步生成输出序列 ,同时动态关注编码器的隐藏状态。
2. 上下文向量(Context Vector)
解码器在每一步生成输出时,利用注意力机制动态计算一个上下文向量 ,该向量表示当前解码时最相关的编码器状态的加权和:
其中:
:编码器的第
个隐藏状态。
:第
步时与第
注意力权重的计算
3. 对齐模型(Alignment Model)
注意力权重 的计算依赖于一个对齐模型,用于评分解码器当前隐藏状态
与编码器隐藏状态
的相关性:
其中,是对齐分数:
4. 评分函数(Score Function)
论文中提出了多种评分函数,具体包括:
点积(Dot Product):
一般形式(General):
其中, 是一个可学习的权重矩阵。
拼接(Concatenation):
其中,和
是可学习参数,
表示向量拼接。
5.解码器与注意力的结合
上下文向量会与解码器当前的隐藏状态
结合,用于生成解码器的输出:
-
解码器的输入:
其中,
通常是一个前馈神经网络。
-
输出生成: 最终,解码器使用
预测当前步的输出
。
6.注意力机制的优点
- 动态聚焦: 模型能够在解码过程中灵活关注输入序列中最相关的部分。
- 性能提升: 对于长句子的处理效果显著优于传统方法。
- 可解释性: 注意力权重提供了模型在不同解码步骤中关注输入位置的直观解释。
变体与扩展
1. Luong 的注意力机制
Luong 等人提出了一个改进的注意力机制,包括:
- 全局注意力(Global Attention): 计算与整个输入序列的关系。
- 局部注意力(Local Attention): 仅关注输入序列中的某个局部窗口。
2. 自注意力(Self-Attention)
相比于 GAM 关注编码器与解码器间的交互,自注意力机制(Transformer 中的核心)将注意力扩展到输入和输出序列中的所有令牌之间。
3. 多头注意力(Multi-Head Attention)
通过多头机制,允许模型从不同的角度关注输入序列的不同特征。
3 全局注意力机制
1. 背景与动机
- 注意力机制(Attention Mechanism)在计算机视觉领域表现优异,尤其在图像分类任务中。
- 现有挑战:传统注意力机制(如SENet、CBAM等)虽然优化了通道或空间维度,但忽略了跨维度(通道-空间)全局交互的信息,导致信息损失。
- 核心目标:通过全局注意力机制(Global Attention Mechanism, GAM),保留信息并放大跨维度全局交互,提升网络性能。
2. 方法创新点
-
全局注意力机制架构
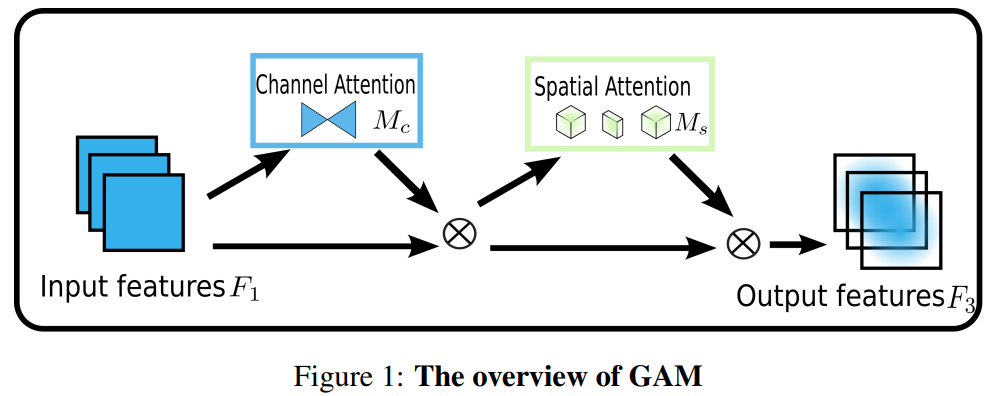
- GAM由通道注意力子模块和空间注意力子模块串联构成。
- 公式:
其中,Mc和Ms分别为通道与空间注意力映射,⊗表示逐元素乘法。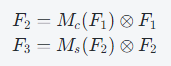
- 通道注意力子模块:引入3D排列和两层多层感知机(MLP),放大通道间全局交互。
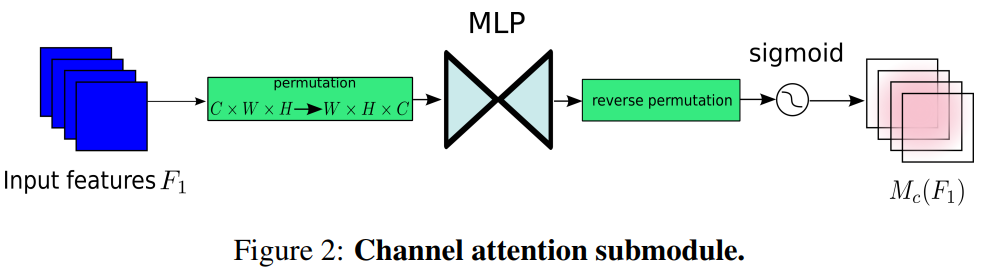
-
- 空间注意力子模块:去除池化操作,使用卷积网络加强空间信息融合,避免信息丢失。
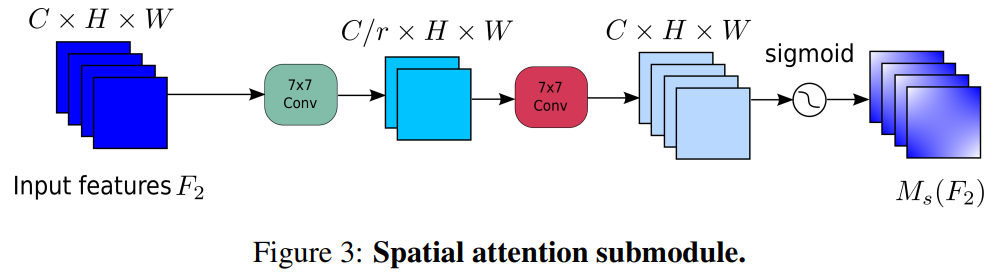
-
核心优化:
- 避免池化损失:去除空间池化操作(如最大池化),保持特征完整性。
- 参数优化:在ResNet50中使用分组卷积和通道混洗,控制参数量。
3. 实验验证
数据集
- CIFAR-100和ImageNet-1K:
- CIFAR-100用于小规模验证,ImageNet-1K则验证实际应用中的泛化能力。
实验结果
-
在CIFAR-100上的性能
- GAM在ResNet50上将Top-1错误率降低至18.67%,明显优于SE、CBAM等。
- 使用分组卷积(group convolution, gc)时,性能稍降但参数量显著减少。
-
在ImageNet-1K上的性能
- GAM在ResNet18和ResNet50上均实现了稳定的性能提升。
- 与其他注意力机制相比(如CBAM、TAM),GAM在参数量较少的情况下取得更低的错误率。
消融实验
- 单独评估通道和空间注意力
- **通道注意力(ch)和空间注意力(sp)**单独使用均有提升,但两者结合时性能最佳。
- 去除池化的影响
- 在ResNet18中去除池化操作,Top-1错误率从29.89%进一步降低至28.57%。
4. 对比分析
- 现有方法的不足:
- SENet:只考虑通道维度,忽略空间信息。
- CBAM和BAM:分别采用串联和并联方式结合通道与空间注意力,但缺乏跨维度交互。
- TAM:改进为三维交互,但每次仅涉及两个维度,未实现全局维度交互。
- GAM的优势:
- 强调全局跨维度交互。
- 在多个数据集和架构上都表现出良好的鲁棒性和泛化能力。
5. 未来展望
- 优化方向:
- 减少GAM的参数量以适应更深层次模型(如ResNet101)。
- 探索结合参数优化的其他跨维度注意力机制。
- 研究意义:
- GAM展示了在大规模数据集上的应用潜力,为未来注意力机制的发展提供了新方向。
[Python] GAM代码实现
🔥若是下面代码复现困难或者有问题,欢迎评论区留言;需要以整个项目形式的代码,请在评论区留下您的邮箱📌,以便于及时分享给您(私信难以及时回复)。
1. GAM代码TensorFlow实现
"""《GAM 项目》tensorflow
时间:2024.11
作者:不去幼儿园
"""
import tensorflow as tf
from keras import layers,Sequential
from keras.layers import Conv2D
from keras.layers import BatchNormalization, Dropout, Dense
from keras.layers import ReLU
class GAM(layers.Layer):
def __init__(self, in_channels, out_channels, rate=4):
super().__init__()
inchannel_rate = int(int(in_channels)/rate)
self.channel_attention = Sequential()
self.channel_attention.add(Dense(inchannel_rate))
self.channel_attention.add(ReLU())
self.channel_attention.add(Dense(in_channels))
self.spatial_attention = Sequential()
self.spatial_attention.add(Conv2D(inchannel_rate,kernel_size=(7,7),padding='same'))
self.spatial_attention.add(BatchNormalization())
self.spatial_attention.add(ReLU())
self.spatial_attention.add(Conv2D(out_channels,kernel_size=(7,7),padding='same'))
self.spatial_attention.add(BatchNormalization())
def forward(self,x):
b, c, h, w = x.shape
# B,C,H,W ==> B,H*W,C
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
# B,H*W,C ==> B,H,W,C
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
# B,H,W,C ==> B,C,H,W
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
out = x * x_spatial_att
return out
if __name__ == '__main__':
img = tf.random.normal([1,64,32,48])
b, c, h, w = img.shape
net = GAM(in_channels=c, out_channels=c)
output = net(img)
print(output.shape)
"""《GAM 项目》tensorflow
时间:2024.11
作者:不去幼儿园
"""
import tensorflow as tf
from keras import layers
from keras.layers import Conv2D
from keras.layers import BatchNormalization, Dense
from keras.activations import relu
#tensorflow 1.4.0
#Keras 2.0.8
class GAM(layers.Layer):
def __init__(self, in_channels, out_channels, rate=4):
super().__init__()
in_channels = int(in_channels)
out_channels = int(out_channels)
inchannel_rate = int(in_channels/rate)
self.dense1 = Dense(inchannel_rate,input_shape=(in_channels,),activation='relu')
self.dense2 = Dense(in_channels)
self.conv1=Conv2D(inchannel_rate,kernel_size=(7,7),padding='same')
self.conv2=Conv2D(out_channels,kernel_size=(7,7),padding='same')
def forward(self,x):
b, c, h, w = x.shape
# B,C,H,W ==> B,H*W,C
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
# B,H*W,C ==> B,H,W,C
print('x_permute',x_permute.shape)
x_att_permute = self.dense2(self.dense1(x_permute)).view(b, h, w, c)
# B,H,W,C ==> B,C,H,W
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
x = x * x_channel_att
x_spatial_att = relu(BatchNormalization(self.conv1(x)))
x_spatial_att = BatchNormalization(self.conv2(x)).sigmoid()
out = x * x_spatial_att
return out
if __name__ == '__main__':
img = tf.random_normal([1,64,32,48])
b, c, h, w = img.shape
net = GAM(in_channels=c, out_channels=c)
output = net(img)
print(output.shape)
2. GAM代码Pytorch实现
"""《GAM 项目》pytorch
时间:2024.11
作者:不去幼儿园
"""
import torch
import torch.nn as nn
class GAM(nn.Module):
def __init__(self, in_channels, out_channels, rate=4):
super().__init__()
in_channels = int(in_channels)
out_channels = int(out_channels)
inchannel_rate = int(in_channels/rate)
self.linear1 = nn.Linear(in_channels, inchannel_rate)
self.relu = nn.ReLU(inplace=True)
self.linear2 = nn.Linear(inchannel_rate, in_channels)
self.conv1=nn.Conv2d(in_channels, inchannel_rate,kernel_size=7,padding=3,padding_mode='replicate')
self.conv2=nn.Conv2d(inchannel_rate, out_channels,kernel_size=7,padding=3,padding_mode='replicate')
self.norm1 = nn.BatchNorm2d(inchannel_rate)
self.norm2 = nn.BatchNorm2d(out_channels)
self.sigmoid = nn.Sigmoid()
def forward(self,x):
b, c, h, w = x.shape
# B,C,H,W ==> B,H*W,C
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
# B,H*W,C ==> B,H,W,C
x_att_permute = self.linear2(self.relu(self.linear1(x_permute))).view(b, h, w, c)
# B,H,W,C ==> B,C,H,W
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
x = x * x_channel_att
x_spatial_att = self.relu(self.norm1(self.conv1(x)))
x_spatial_att = self.sigmoid(self.norm2(self.conv2(x_spatial_att)))
out = x * x_spatial_att
return out
if __name__ == '__main__':
img = torch.rand(1,64,32,48)
b, c, h, w = img.shape
net = GAM(in_channels=c, out_channels=c)
output = net(img)
print(output.shape)[Notice] 注意事项
由于博文主要为了介绍相关算法的原理和应用的方法,缺乏对于实际效果的关注,算法可能在上述环境中的效果不佳或者无法运行,一是算法不适配上述环境,二是算法未调参和优化,三是没有呈现完整的代码,四是等等。上述代码用于了解和学习算法足够了,但若是想直接将上面代码应用于实际项目中,还需要进行修改。
4 总结
Bahdanau 等人提出的全局注意力机制是现代深度学习中的一个基础性概念。它通过动态对齐和翻译输入序列,为复杂的序列生成任务提供了更强大的能力。同时,它也为后续更高级的架构(如 Transformer)奠定了理论基础。
参考文献:
Neural Machine Translation by Jointly Learning to Align and Translate
Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者关注VX公众号:Rain21321,联系作者。✨



















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











