







目录
前言
在SENet中的通道注意模块。具体来说,在给定输入特征的情况下,SE块首先对每个通道单独使用全局平均池化,然后使用两个两个全连接和一个ReLU激活函数,先进行降维在升维,然后使用一个Sigmoid函数来生成通道权值。
与SENet相似,但ECANet为了克服性能和复杂性权衡的矛盾,ECANet提出来通过不降维(不降低通道维度)的方法做到只涉及少量参数,但能带来明显的性能增益。
在通道上先降维后升维对深度学习模型的作用是什么?
通过先降维再升维的操作,来调整模型复杂度和特征表示能力。但我们的实证研究表明,降维会对渠道注意力预测产生副作用,并且捕获所有渠道的依赖关系是低效和不必要的。
一、ECANet结构
ECANet是一种高效通道注意力模块,结构如图1所示。GAP:对输入的特征图进行不降低维数的全局平均池化,将通道维度的维度数量保持不变,而空间维度压缩为大小为1的维度。压缩y的最后一个维度(去除单维度)并将维度重新排列。ECA通过考虑每个通道及其k个邻居来捕获局部跨通道交互信息,ECA可以通过大小为k的快速1D卷积来有效实现,以完成一种不降维的局部跨通道交互策略(我们通过经验证明避免降维对于学习通道注意非常重要,适当的跨通道交互可以在显著降低模型复杂性的同时保持性能。)其中卷积核大小为k代表了局部跨信道交互的覆盖率,即,该通道附近有多少邻居参与了这个通道的注意力预测,为了避免通过交叉验证对k进行手动调优,本文提出了一种方法来自适应地确定k,其中交互的覆盖率(即卷积核大小 k)与通道维数成正比。这个机制有助于在保持通道间关联性的同时,更有效地进行通道间的交互,从而提高网络的表达能力和性能。再将输出经过sigmoid激活函数,保证输出在0-1之间,然后对标准化后的输出进行维度变换,将其形状还原,最后将上一步得到的通道注意力权重乘以输入的原始特征图。
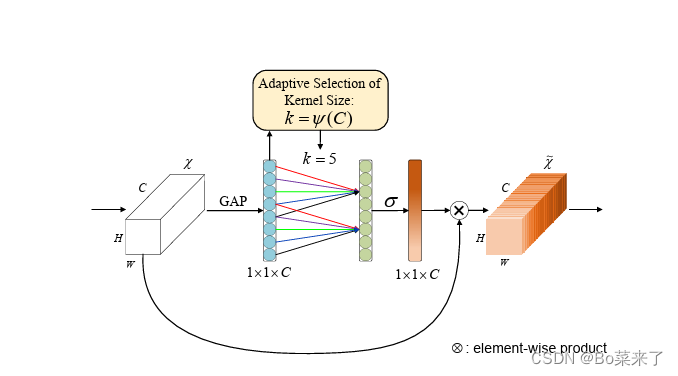
图1 ECANet结构
二、ECANet计算流程
给定一个输入![]() ,通过一个全局平均池化,变成
,通过一个全局平均池化,变成![]() ,为了将得到的特征图y调整为符合后续卷积操作需要的形状,变成
,为了将得到的特征图y调整为符合后续卷积操作需要的形状,变成![]() ,在经过一维卷积,一维卷积的权重为:
,在经过一维卷积,一维卷积的权重为:
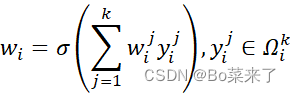
其中![]() 表示
表示![]() 的k个相邻通道的集合,通过卷积大小k的一维卷积来实现通道之间的信息交互:
的k个相邻通道的集合,通过卷积大小k的一维卷积来实现通道之间的信息交互:
![]()
其中C1D代表一维卷积,其中k的大小与通道维数C成正比k和C之间存在映射![]() :
:
![]()
如果采用以2为底的指数函数来表示非线性映射关系:
![]()
可得:
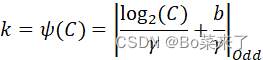
其中![]() ,表示最接近t的奇数,
,表示最接近t的奇数,
再将输出经过sigmoid激活函数,最后对标准化后的输出进行维度变换,将其形状还原,变成![]() 最后将上一步得到的通道注意力权重乘以输入的原始特征图。以获得最终结果。
最后将上一步得到的通道注意力权重乘以输入的原始特征图。以获得最终结果。
三、ECANet参数
利用thop库的profile函数计算FLOPs和Param。Input:(512,7,7)
| Module | FL0Ps | Param |
| ECANet | 27136.0 | 4.0 |
| SEAttention | 91136 | 65536 |
对比两种模型,可得出ECANet计算量,计算资源使用相对于SEAttention较小,硬件需求更小,过拟合风险更低,优化困难程度更低。
四、代码讲解
import torch
from torch import nn
from torch.nn import init
class ECAAttention(nn.Module):
def __init__(self, kernel_size=3):
super().__init__()
self.gap = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2)
self.sigmoid = nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
y = self.gap(x) # (B, C, H, W) -> (B, C, 1, 1)
y = y.squeeze(-1).permute(0, 2, 1) #squeeze(-1)去掉最后一个维度,permute(0, 2, 1)交换维度,(B, C, 1, 1) -> (B, C, 1) -> (B, 1, C)
y = self.conv(y) # (B, 1, C) -> (B, 1, C)
y = self.sigmoid(y)
y = y.permute(0, 2, 1).unsqueeze(-1) # (B, 1, C) -> (B, C, 1) -> (B, C, 1, 1)
return x * y.expand_as(x) # (B, C, H, W) * (B, C, H, W)
if __name__ == '__main__':
from torchsummary import summary
from thop import profile
model = ECAAttention(kernel_size=3)
summary(model, (512, 7, 7), device='cpu')
flops, params = profile(model, inputs=(torch.randn(1, 512, 7, 7),))
print(f"FLOPs: {flops}, Params: {params}")















 2044
2044

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









