







 文章介绍了GhostConv,一种在卷积神经网络中通过低成本线性变换生成更多特征图的技术,旨在降低计算负担,提高资源利用率。GhostNet利用Ghost模块在嵌入式设备上展现优越性能,通过Ghostbottleneck结构进一步增强效率。文章还提供了计算流程、参数分析以及代码实现示例。
文章介绍了GhostConv,一种在卷积神经网络中通过低成本线性变换生成更多特征图的技术,旨在降低计算负担,提高资源利用率。GhostNet利用Ghost模块在嵌入式设备上展现优越性能,通过Ghostbottleneck结构进一步增强效率。文章还提供了计算流程、参数分析以及代码实现示例。
目录
前言
GhostNet: More Features from Cheap Operations
来源:CVPR2020
官方代码:https://github.com/huawei-noah/ghostnet
Ghost 模块是一种针对卷积神经网络(CNN)的创新设计,特别适用于嵌入式设备,这些设备通常具有有限的内存和计算资源。Ghost 模块的核心思想是利用已有的特征图(feature maps)通过低成本的线性变换生成更多的“幽灵”特征图(ghost feature maps),从而提高网络的计算效率。
一、GhostConv结构
GhostConv分为三步:常规卷积、Ghost生成和特征图拼接,GhostConv结构如图1所示,图中a图为常规卷积操作,而b为GhostConv模型操作。常规卷积操作,对输入特征图进行卷积,得到输出,与普通卷积神经网络相比,Ghost模块降低了所需的参数数量和计算复杂度。GhostNet先使用普通卷积(1*1*M),批量归一化和一个激活函数Relu,将输入图片进行通道数压缩,生成一些固有的特征映射,然后将特征图应用一系列简单的线性操作(单位映射与线性变换并行以保持固有的特征映射)φk![]() 获得更多特征图,增加特征。其中廉价操作φk
获得更多特征图,增加特征。其中廉价操作φk![]() 由Depthwise Convolution(Depthwise Convolution是一个卷积核负责一个通道,一个通道只被一个卷积核卷积)和批量归一化和一个激活函数Relu组合 ,然后将不同特征图,通过concat将获得的特征图和第一步中通过普通卷积,批量归一化和激活函数Relu组合,最终获得的特征图即为output。实验结果表明,提出的Ghost模块能够降低通用卷积层的计算成本,同时保持相似的识别性能,并且GhostNets可以在移动设备上快速推理的各种任务上超越最先进的高效深度模型。利用Ghost模块优势,设计Ghost bottleneck,结构如图2所示。Ghost bottleneck 主要由两个堆叠的ghost module组成,第一个ghost module作为扩展层增加通道数量,第二个ghost module减少了通道的数量以匹配第一步的输入,使两者可以进行元素加法。图中分成了两种,一种为步幅=1的,另一种为步幅=2的,第二种则在两个ghost module中间插入了一个步幅为2的深度卷积。
由Depthwise Convolution(Depthwise Convolution是一个卷积核负责一个通道,一个通道只被一个卷积核卷积)和批量归一化和一个激活函数Relu组合 ,然后将不同特征图,通过concat将获得的特征图和第一步中通过普通卷积,批量归一化和激活函数Relu组合,最终获得的特征图即为output。实验结果表明,提出的Ghost模块能够降低通用卷积层的计算成本,同时保持相似的识别性能,并且GhostNets可以在移动设备上快速推理的各种任务上超越最先进的高效深度模型。利用Ghost模块优势,设计Ghost bottleneck,结构如图2所示。Ghost bottleneck 主要由两个堆叠的ghost module组成,第一个ghost module作为扩展层增加通道数量,第二个ghost module减少了通道的数量以匹配第一步的输入,使两者可以进行元素加法。图中分成了两种,一种为步幅=1的,另一种为步幅=2的,第二种则在两个ghost module中间插入了一个步幅为2的深度卷积。
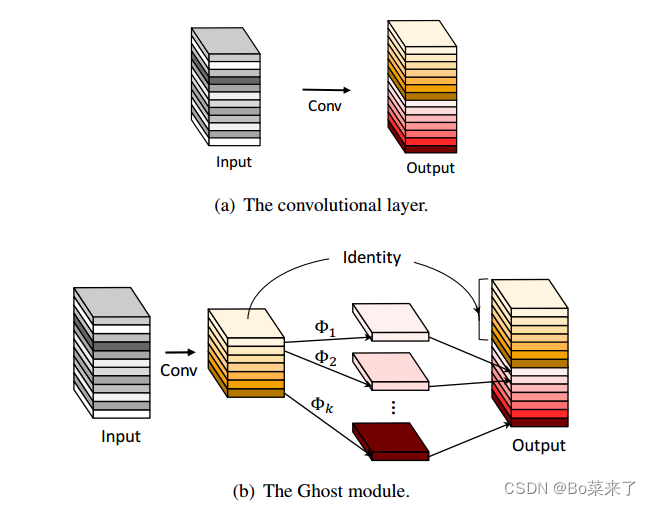
图1:GhostNet结构图
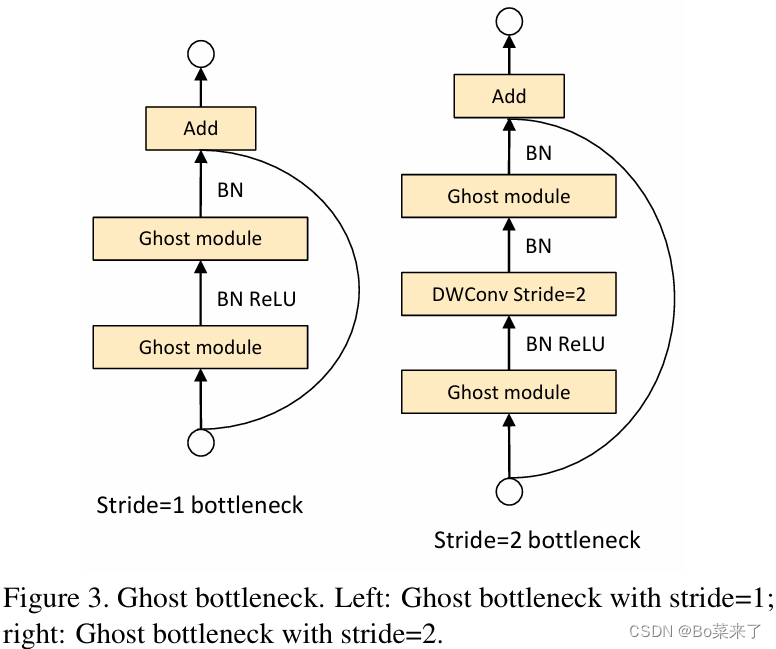
图2 Ghost bottleneck结构
使用 GhostConv模块的主要优势包括:
降低计算负载:通过使用线性变换从现有特征图生成更多特征图,相较于依赖额外的卷积层,大大减少了所需的计算量。
高效利用资源:这种方法最大限度地利用了可用的计算和内存资源,特别适合资源有限的嵌入式系统。
易于适应:由于其模块化设计,Ghost 模块可以无缝集成到现有的 CNN 架构中,使其成为提高效率的通用解决方案。
二、GhostConv计算流程
给定一个输入![]() (其中c为通道数,h为高度,w为宽度),经过
(其中c为通道数,h为高度,w为宽度),经过![]() 的卷积核,得到特征图
的卷积核,得到特征图![]() 。
。
普通卷积的参数量为:![]() ,计算量为:
,计算量为:![]()
GhostConv的参数量为: ![]() ,计算量为:
,计算量为: ![]()
其中d⋅d为线性运算的卷积核大小,s为线性变换次数,s<<c。![]() 是第一次变换时的输出通道数目,s-1是因为恒等映射不需要进行计算,但它也算做第二变换中的一部分,因此Ghost 模块之所以能省计算量。
是第一次变换时的输出通道数目,s-1是因为恒等映射不需要进行计算,但它也算做第二变换中的一部分,因此Ghost 模块之所以能省计算量。![]() 为普通卷积与GhostConv卷积计算量比,
为普通卷积与GhostConv卷积计算量比,![]() 为参数之比。
为参数之比。
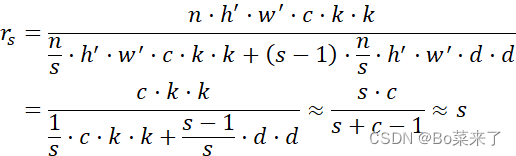
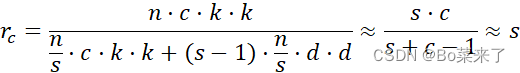
三、GhostConv参数
利用thop库的profile函数计算FLOPs和Param。Input:(64,32,32),卷积核(128,3,3)
| Module | FLOPs | Param |
| GhostConv | 38862848 | 37696 |
| 标准卷积 | 75497472 | 73856 |
四、代码详解
import torch.nn as nn
import torch
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
hidden_channels = oup // ratio
new_channels = hidden_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, hidden_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(hidden_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(hidden_channels, new_channels, dw_size, 1, dw_size//2, groups=hidden_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out
if __name__ == '__main__':
from torchsummary import summary
from thop import profile
model = GhostModule(64, 128, 3, 2, 3, 1, True)
summary(model, (64, 32, 32), device='cpu')
flops, params = profile(model, inputs=(torch.randn(1, 64, 32, 32),))
print(f"FLOPs: {flops}, Params: {params}")

















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









